欢迎访问我的博客首页。
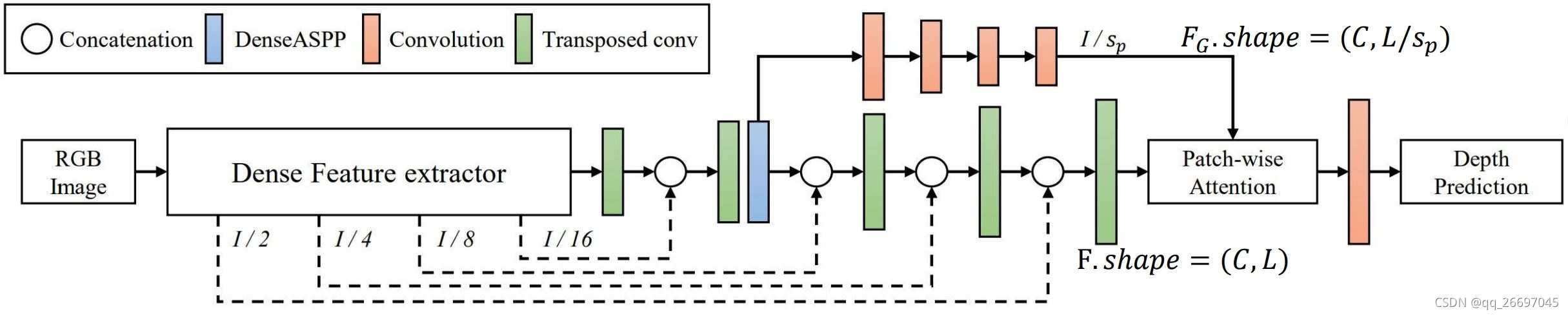
这篇文章来自韩国科学技术院 KAIST,所提方法称为 PWA。PWA 基于编解码器结构,主要创新是提出了局部注意力。注意力机制增加的参数量是可接受的,它可以提供综合性能,且容易整合进 CNN 框架。
1. 整体结构
PWA 的注意力是针对块的,即,每个块有一个注意力。
s
p
s_p
sp 是块的边长,共有
L
/
s
p
×
L
/
s
p
L/s_p \times L/s_p
L/sp×L/sp 个块。
图 1 是整体架构。解码器输出的局部上下文特征
F
.
s
h
a
p
e
=
(
C
,
L
)
F.shape=(C, L)
F.shape=(C,L) 和 DenseASPP 输出的全局上下文特征
F
G
.
s
h
a
p
e
=
(
C
,
L
/
s
p
)
F_G.shape=(C, L/s_p)
FG.shape=(C,L/sp) 都被送入 PWA。PWA 的输出经过卷积层、激活函数层,再乘一个最大深度值,得到最终的深度图。
图
1
整
体
结
构
图\ 1\quad 整体结构
图 1整体结构
2. 块级注意力
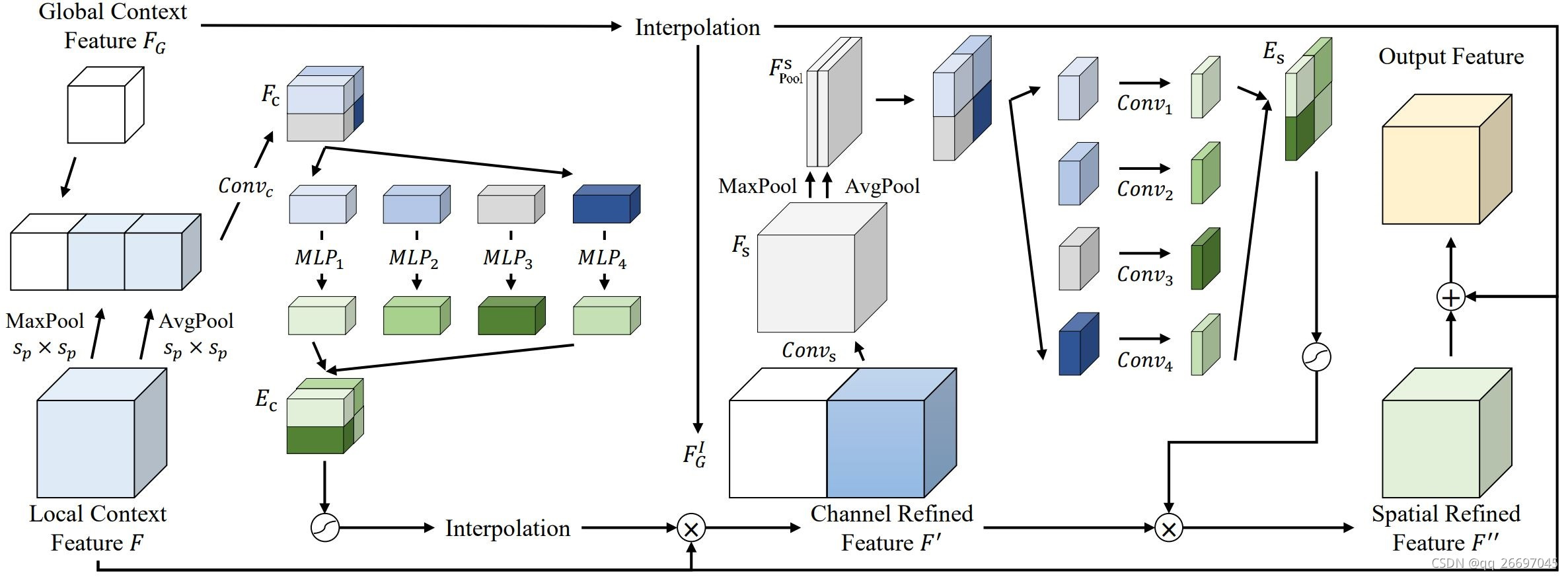
PWA 的块级注意力包括块级通道注意力和块级空间注意力,图 2 是块级注意力结构。
图
2
块
级
注
意
力
图\ 2\quad 块级注意力
图 2块级注意力
2.1 块级通道注意力
块级通道注意力
- 局部上下文特征 F F F 分别经过 k e r n e l _ s i z e = s p kernel\_size=s_p kernel_size=sp 的最大池化、平均池化得到 F m a x c . s h a p e = ( C , L / s p ) F_{max}^c.shape=(C, L/s_p) Fmaxc.shape=(C,L/sp)、 F a v g c . s h a p e = ( C , L / s p ) F_{avg}^c.shape=(C, L/s_p) Favgc.shape=(C,L/sp)。
- 全局上下文特征 F G F_G FG 和来自局部上下文特征的 F m a x c F_{max}^c Fmaxc、 F a v g c F_{avg}^c Favgc 沿通道叠加,经过一个 k e r n e l _ s i z e = 3 kernel\_size=3 kernel_size=3 的卷积 C o n v c Conv_c Convc 得到 F c . s h a p e = ( C , L / s p ) F_c.shape=(C, L/s_p) Fc.shape=(C,L/sp)。 F c F_c Fc 的每个像素 i . s h a p e = ( C , 1 ) i.shape=(C, 1) i.shape=(C,1) 代表原图上一个边长为 s p s_p sp 的块。它即包含局部上下文特征 F F F,又包含全局上下文特征 F G F_G FG。
- 把 F c F_c Fc 的每个像素经过一个感知机,得到 E i c . s h a p e = ( C , 1 ) E_i^c.shape=(C, 1) Eic.shape=(C,1)。把 L / s p × L / s p L/s_p \times L/s_p L/sp×L/sp 个 E i c E_i^c Eic 按 i i i 的原位置拼接,得到通道注意力 E c . s h a p e = ( C , L / s p ) E_c.shape=(C, L/s_p) Ec.shape=(C,L/sp)。
- E c E_c Ec 上采样后与 F F F 相乘得到沿通道精炼过的特征 F ′ . s h a p e = ( C , L ) F'.shape=(C, L) F′.shape=(C,L)。
F c F_c Fc 的每个通道被输入一个感知机,所以感知机总数是 b a t c h _ s i z e × ( L / s p × L / s p ) batch\_size \times (L/s_p \times L/s_p) batch_size×(L/sp×L/sp)。每个感知机的输入是一个 C × 1 × 1 C \times 1 \times 1 C×1×1 的向量。每个感知机含有一个通道数是 C/8 的隐藏层和一个 sigmoid 激活函数。具体实现参考下面的代码:
class MPL(torch.nn.Module):
def __init__(self, in_features, hidden_features):
super().__init__()
self.net = torch.nn.Sequential(
torch.nn.Linear(in_features, hidden_features),
torch.nn.Linear(hidden_features, 1),
torch.nn.ReLU()
)
self.init()
def init(self):
for m in self.net.modules():
if isinstance(m, torch.nn.Linear):
torch.nn.init.normal_(m.weight)
def forward(self, input):
return self.net(input)
def pixelwise_mpl(input, hidden_features=None):
if hidden_features is None:
hidden_features = input.size(1) // 8
batch_size = input.size(0)
in_features = input.size(1)
h = input.size(2)
w = input.size(3)
output = torch.zeros(size=(batch_size, 1, h, w))
for y in range(h):
for x in range(w):
net = MPL(in_features, hidden_features)
output[:, :, y, x] = net(input[:, :, y, x])
return output
if __name__ == '__main__':
input = torch.tensor(np.random.random(size=(8, 64, 32, 32)), dtype=torch.float32)
output = pixelwise_mpl(input)
print(output.shape)
2.2 块级空间注意力
块级空间注意力
- 全局上下文特征 F G F_G FG 上采样得到 F G I . s h a p e = ( C , L ) F_G^I.shape=(C, L) FGI.shape=(C,L)。
- 把 F G I F_G^I FGI 和沿通道精炼过的特征 F ′ F' F′ 沿通道维度叠加,经过 k e r n e l _ s i z e = 3 kernel\_size=3 kernel_size=3 的卷积 C o n v s Conv_s Convs 得到 F s . s h a p e = ( C , L ) F_s.shape=(C, L) Fs.shape=(C,L)。
- 沿着 F s F_s Fs 通道分别进行最大池化、平均池化得到 F m a x s . s h a p e = ( 1 , L ) F_{max}^s.shape=(1, L) Fmaxs.shape=(1,L)、 F a v g s . s h a p e = ( 1 , L ) F_{avg}^s.shape=(1, L) Favgs.shape=(1,L)。这里是对每个 C × 1 × 1 C \times 1 \times 1 C×1×1 的像素池化,池化后的像素维度是 ( 1 × 1 × 1 ) (1 \times 1 \times 1) (1×1×1)。
- 把 F m a x s F_{max}^s Fmaxs 和 F a v g s F_{avg}^s Favgs 沿通道维度叠加,得到特征 F P o o l s . s h a p e = ( 2 , L ) F_{Pool}^s.shape=(2, L) FPools.shape=(2,L)。
- 把 F P o o l s F_{Pool}^s FPools 拆分成 L / s p × L / s p L/s_p \times L/s_p L/sp×L/sp 个边长为 s p s_p sp 的块。每一个块 j . s h a p e = ( 2 , s p ) j.shape=(2, s_p) j.shape=(2,sp) 经过一个 k e r n e l _ s i z e = 7 kernel\_size=7 kernel_size=7、步长为 1 1 1 的卷积 C o n v j Conv_j Convj 和 s i g m o i d sigmoid sigmoid 激活函数,得到一个空间注意力 E j s . s h a p e = ( 1 , s p ) E_j^s.shape=(1, s_p) Ejs.shape=(1,sp)。
- 把 L / s p × L / s p L/s_p \times L/s_p L/sp×L/sp 个 E s j E_s^j Esj 按 j j j 的原位置拼接,得到空间注意力 E s . s h a p e = ( 1 , L ) E_s.shape=(1, L) Es.shape=(1,L)。
- 增加 E s E_s Es 的通道,然后与 F ′ F' F′ 相乘,得到 F ′ ′ . s h a p e = ( C , L ) F''.shape=(C, L) F′′.shape=(C,L)。
- 把 F ′ ′ F'' F′′、 F F F、 F G I F_G^I FGI 相加得到 Output Feature。
def pixelwise_pooling(input, pool=torch.nn.AdaptiveMaxPool1d):
batch_size = input.size(0)
h = input.size(2)
w = input.size(3)
output = torch.zeros(size=(batch_size, 1, h, w))
for y in range(h):
for x in range(w):
pooling = pool(output_size=1)
output[:, :, y, x] = pooling(input[:, :, y, x])
return output
if __name__ == '__main__':
input = torch.tensor(np.random.random(size=(8, 64, 32, 32)), dtype=torch.float32)
output = pixelwise_pooling(input)
print(output.shape)