Kafka消息队列
章节一.kafka入门
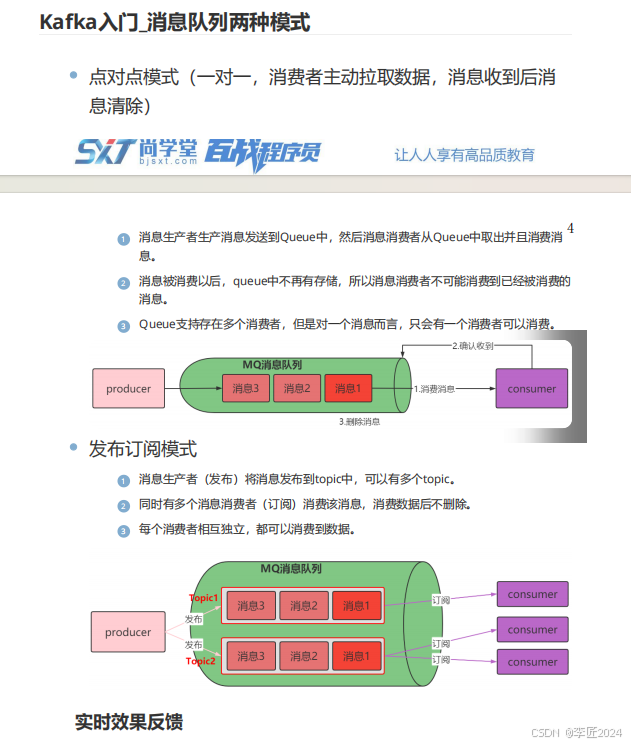
4.kafka入门_消息队列两种模式
5.kafka入门_架构相关名词
Kafka
入门
_
架构相关名词
事件
记录了世界或您的业务中
“
发生了某事
”
的事实。在文档中
也称为记录或消息。当您向
Kafka
读取或写入数据时,您以事件的
形式执行此操作。从概念上讲,事件具有键、值、时间戳和可选的
元数据标头。这是一个示例事件:
事件键:
“
白富美
”
事件的值:
“
向土豪 支付了
520
元
”
事件时间戳:
“yyyy
年
05
月
20
日
13:14”
生产者
是那些向
Kafka
发布(写入)事件的客户端应用程序。
消费者
是订阅(读取和处理)这些事件的那些客户端应用程
序。在
Kafka
中,生产者和消费者完全解耦并且彼此不可知,这是
实现
Kafka
众所周知的高可扩展性的关键设计元素。例如,生产者
永远不需要等待消费者。
Kafka
提供了各种
保证
,例如一次性处理
事件的能力。
主题
:事件被组织并持久地存储在
主题
中。
Kafka
中的主题始
终是多生产者和多订阅者:一个主题可以
N(N>=0)
个向其写入事件
的生产者,以及订阅这些事件的
N(N>=0)
个消费者。主题中的事件
可以根据需要随时读取
——
与传统的消息传递系统不同,事件在消
费后不会被删除。相反,您可以通过每个主题的配置设置来定义
Kafka
应该将您的事件保留多长时间,之后旧事件将被丢弃。
Kafka
的性能在数据大小方面实际上是恒定的,因此长时间存储数据是非
常好的
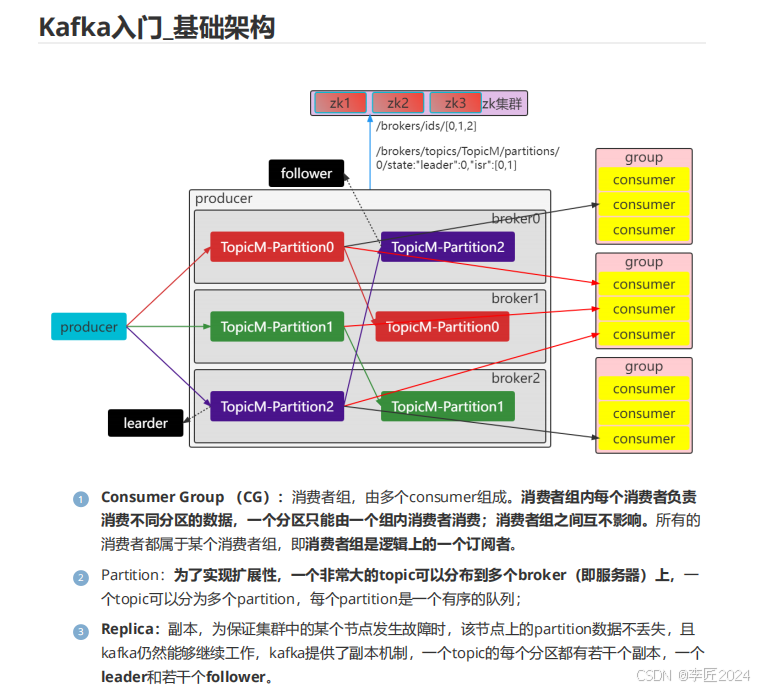
6.kafka入门_基础架构

7.kafka入门_下载安装一

8.kafka入门_下载安装二


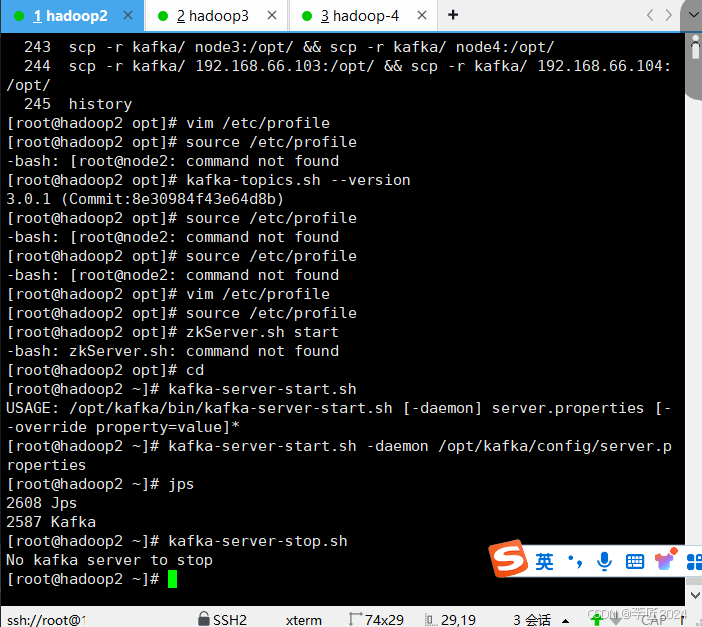
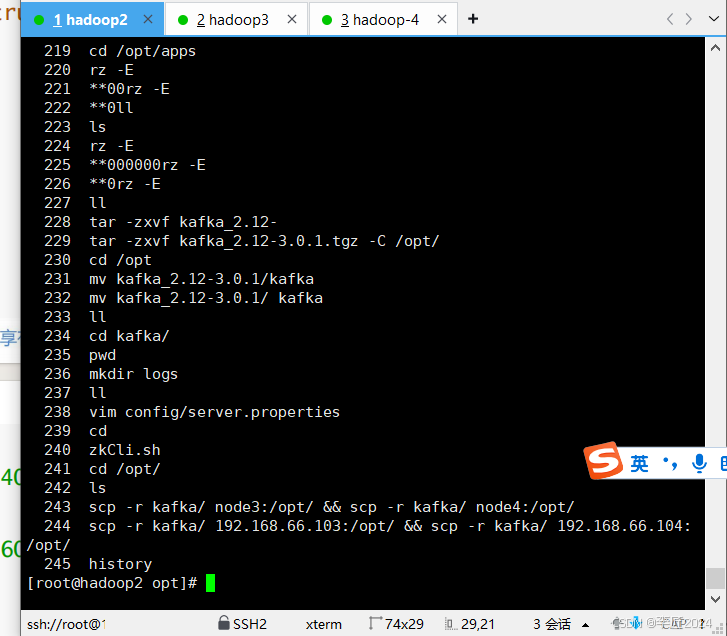
9.kafka入门_集群启停脚本
Kafka
入门
_
集群启停脚本
[root@node2 opt]
# vim /etc/profile
# kafka
的环境变量
export
KAFKA_HOME
=
/opt/kafka
export
PATH
=
$PATH
:
$KAFKA_HOME
/bin
[root@node2 opt]
# source /etc/profile
[root@node2 ~]
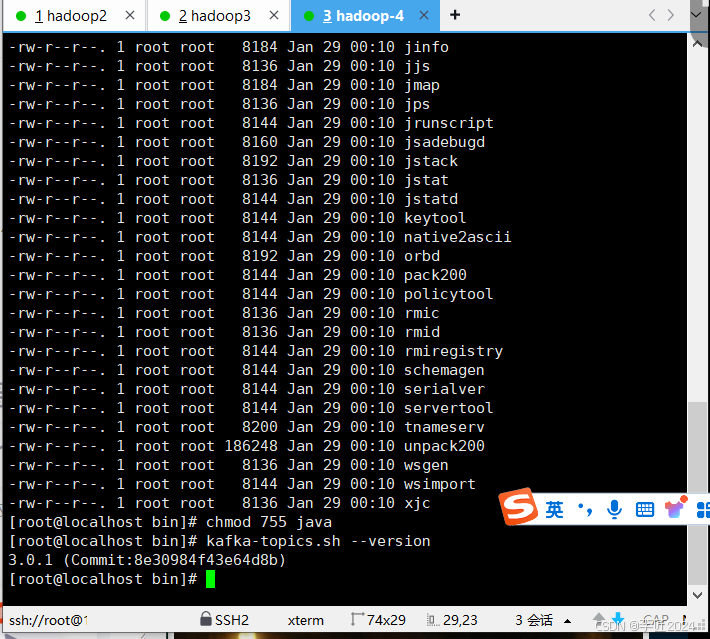
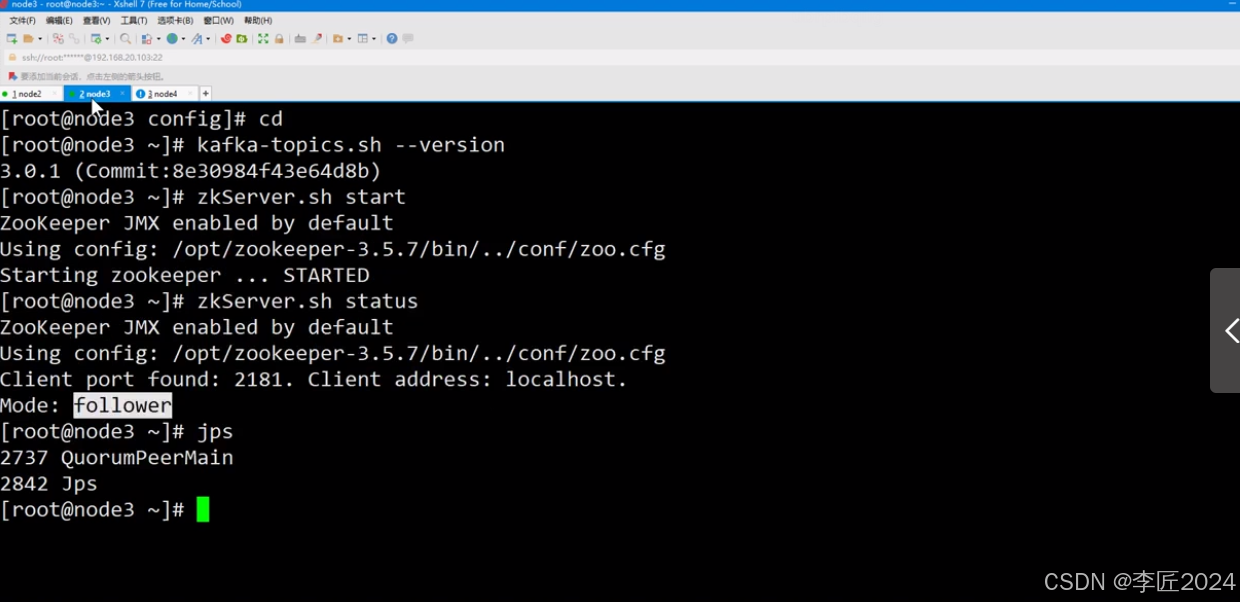
# kafka-topics.sh --version
3
.0.1 (Commit:8e30984f43e64d8b)
kafka-server-start.sh
-daemon
/opt/kafka/config/server.properties
[root@node2 opt]
# jps
3248
QuorumPeerMain
3761
Jps
3736
Kafka
kafka-server-stop.sh
[root@node2 opt]
# cd /root/
11
[root@node2 ~]
# mkdir bin/
[root@node2 ~]
# cd bin/
[root@node2 bin]
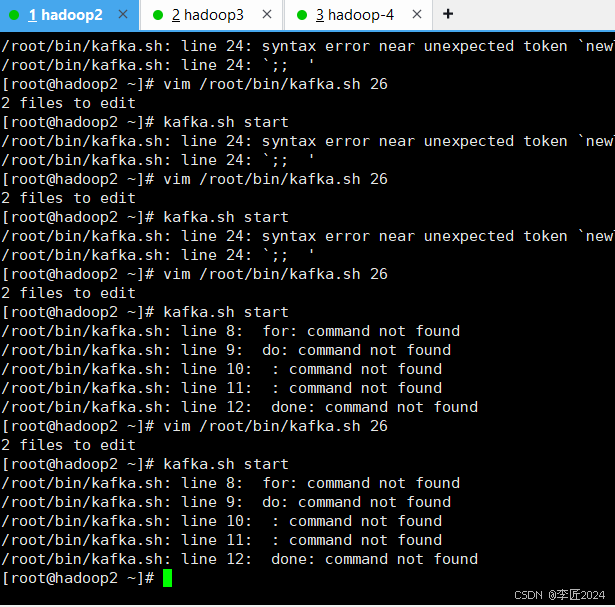
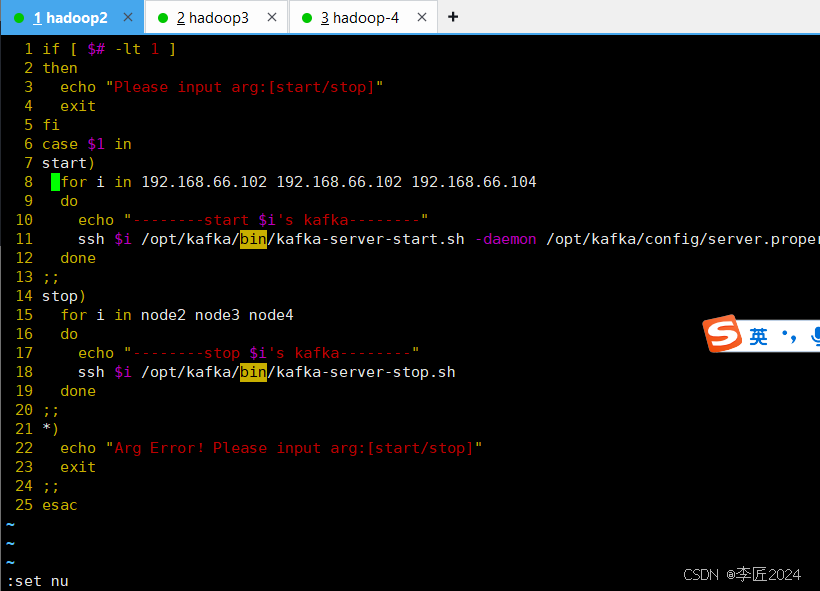
# vim kafka.sh
#!/bin/bash
if
[
$#
-lt
1
]
then
echo
"Please input arg:[start/stop]"
exit
fi
case
$1
in
start
)
for
i
in
node2 node3 node4
do
echo
"--------start
$i
's kafka--------"
ssh
$i
/opt/kafka/bin/kafka-server-start.sh
-daemon
/opt/kafka/config/server.properties
done
;;
stop
)
for
i
in
node2 node3 node4
do
echo
"--------stop
$i
's kafka--------"
ssh
$i
/opt/kafka/bin/kafka-server-stop.sh
done
;;
*)
echo
"Arg Error
!
Please input arg:
[start/stop]"
exit
;;
esac
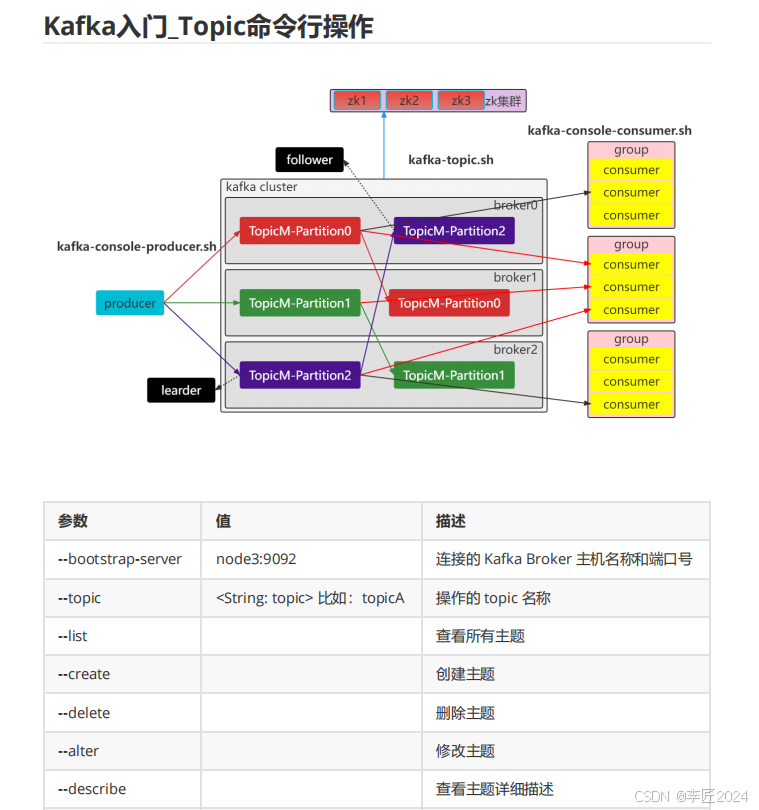
参数 值 描述
--bootstrap-server
node3:9092
连接的
Kafka Broker
主机名称和端口号
--topic
<String: topic>
比如:
topicA
操作的
topic
名称
--list
查看所有主题
--create
创建主题
--delete
删除主题
--alter
修改主题
--describe
查看主题详细描述
--partitions
<Integer: # of partitions>
设置分区数
--replication-factor
<Integer: replication factor>
设置分区副本
--config
<String: name=value>
更新系统默认的配置
--version
查看当前系统
kafka
的版本
添加可执行权限:
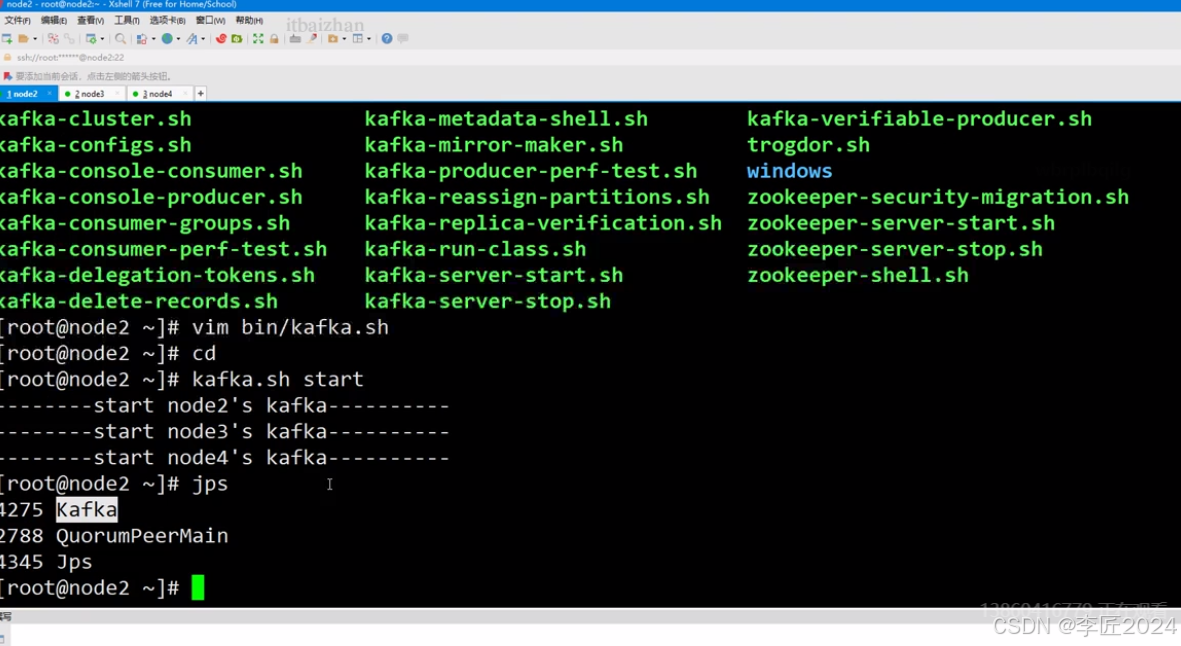
[root@node2 bin]# chmod +x kafka.sh
启动测试:
kafka.sh start
注意:提前启动
zk
集群。
关闭测试:
kafka.sh stop
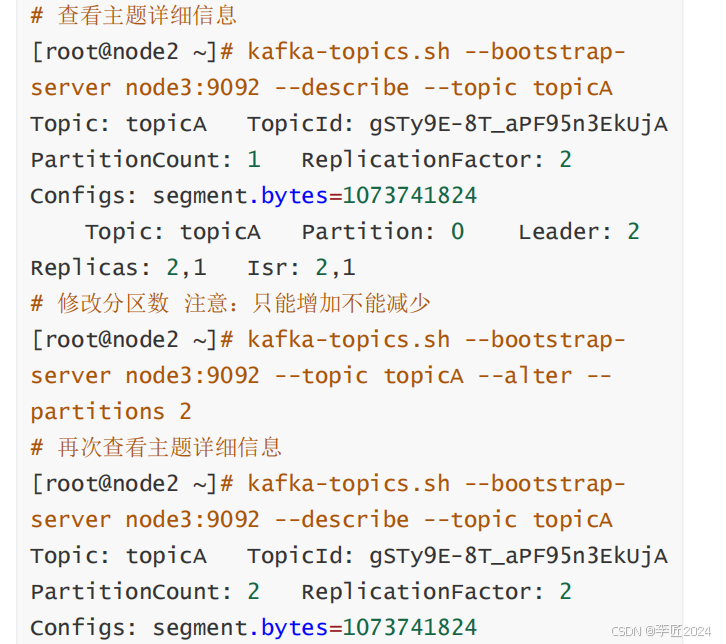
10.kafka入门_Topic命令行操作

11.kafka入门_消息发送和接收

章节二.生产者
12.生产者_发送数据原理剖析一
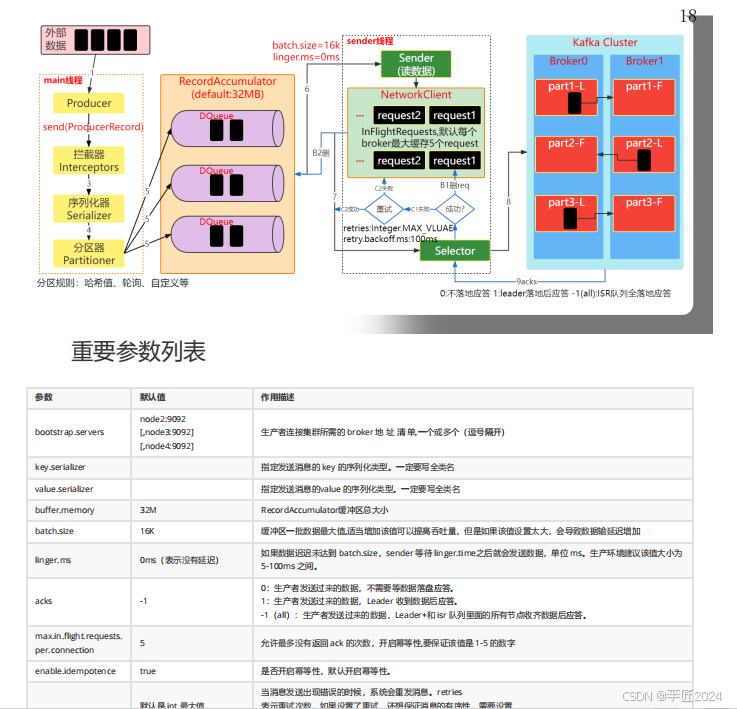
13.生产者_发送数据原理剖析二

14.生产者_同步发送数据一
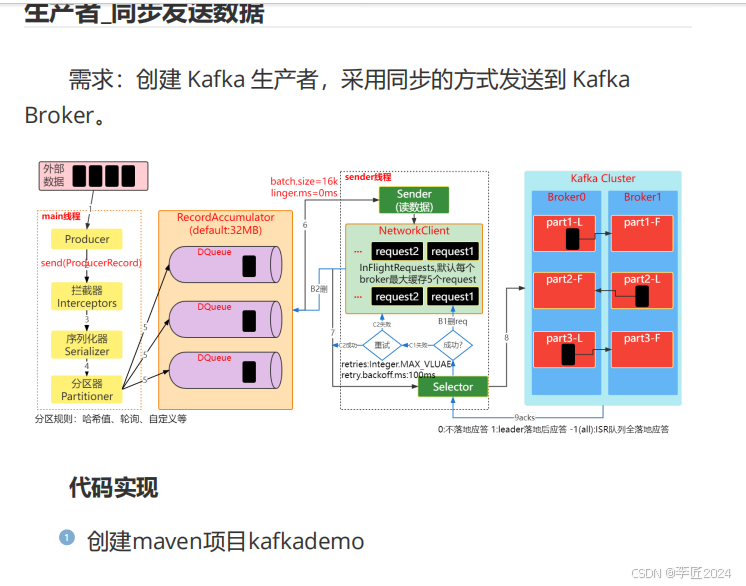
15.生产者_同步发送数据二

在
node2
上开启
Kafka
消费者进行消费
7
运行
SyncCustomProducer
类
prop
.
put
(
ProducerConfig
.
KEY_SERIALIZER_CL
ASS_CONFIG
,
StringSerializer
.
class
.
getName
());
prop
.
put
(
ProducerConfig
.
VALUE_SERIALIZER_
CLASS_CONFIG
,
StringSerializer
.
class
.
getName
());
//TODO 3.
声明并实例化生产者对象
KafkaProducer
<
String
,
String
>
producer
=
new
KafkaProducer
<
String
,
String
>
(
prop
);
//TODO 4.
发送消息
for
(
int
i
=
0
;
i
<
5
;
i
++
){
//
同步发送消息
producer
.
send
(
new
ProducerRecord
<>
(
"topicA"
,
"sync_msg"
+
i
)).
get
();
}
//TODO 5.
关闭生产者
producer
.
close
();
}
}
[root@node2 ~]
# kafka-console-consumer.sh
--bootstrap-server node2:9092 --topic
topicA
22
8
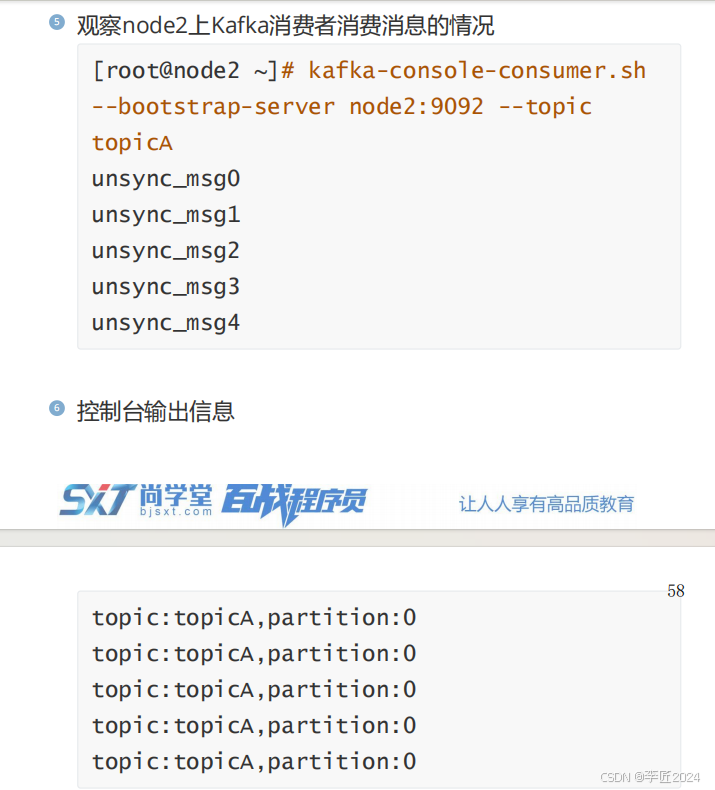
观察
node2
上
Kafka
消费者消费消息的情况
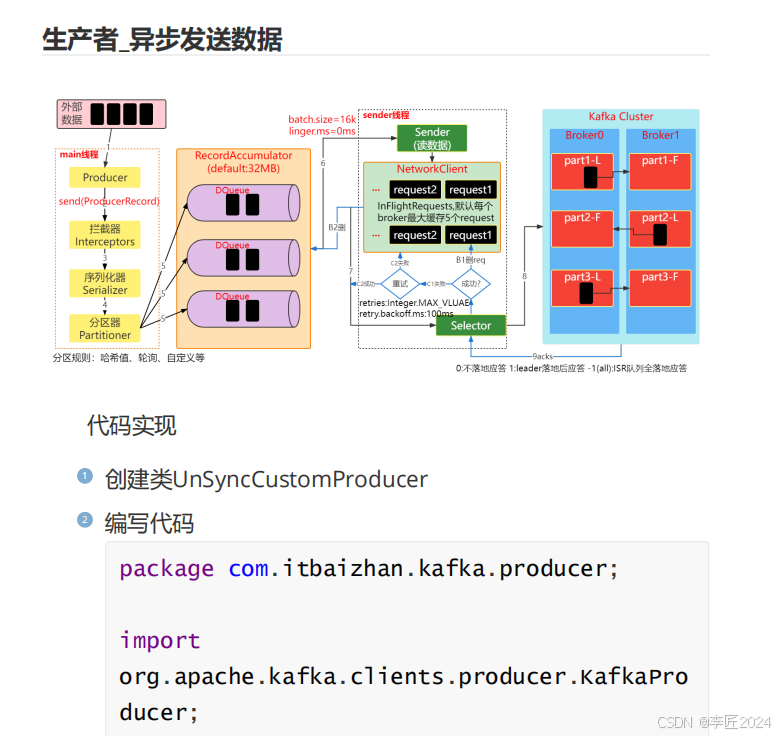
生产者
_
异步发送数据
代码实现
1
创建类
UnSyncCustomProducer
2
编写代码
[root@node2 ~]# kafka-console-consumer.sh
--bootstrap-server node2:9092 --topic
topicA
sync_msg0
sync_msg1
sync_msg2
sync_msg3
sync_msg4
16.生产者_异步发送数据
17.生产者_异步回调发送数据
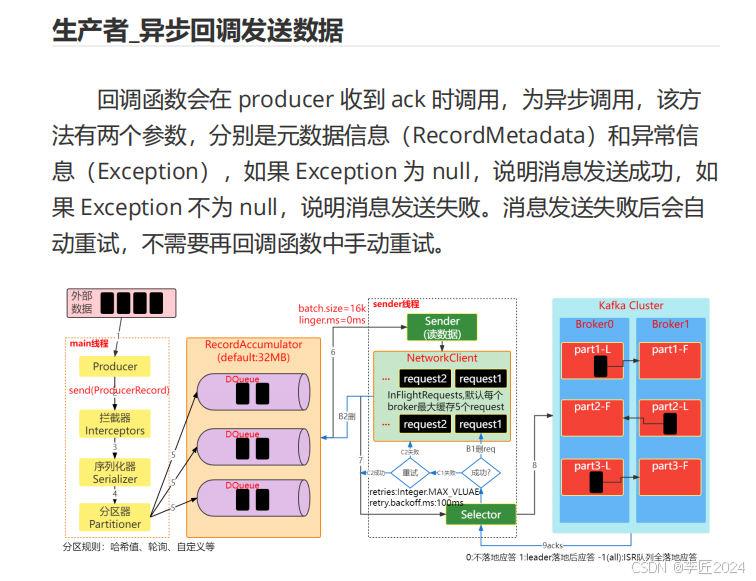
代码实现
1
创建类
UnSyncCallBackCustomProducer
2
编写代码
[root@node2 ~]
# kafka-console-consumer.sh
--bootstrap-server node2:9092 --topic
topicA
unsync_msg0
unsync_msg1
unsync_msg2
unsync_msg3
unsync_msg4
package
com
.
itbaizhan
.
kafka
.
producer
;
26
import
org
.
apache
.
kafka
.
clients
.
producer
.
*
;
import
org
.
apache
.
kafka
.
common
.
serialization
.
Stri
ngSerializer
;
import
java
.
util
.
Properties
;
import
java
.
util
.
concurrent
.
ExecutionException
;
public class
UnSyncCallBackCustomProducer
{
public static
void
main
(
String
[]
args
)
throws
ExecutionException
,
InterruptedException
{
//TODO 1.
声明并实例化
Kafka Producer
的
配置文件对象
Properties prop
=
new
Properties
();
//TODO 2.
为配置文件对象设置参数
// 2.1
配置
bootstrap_servers
prop
.
put
(
ProducerConfig
.
BOOTSTRAP_SERVERS
_CONFIG
,
"node2:9092,node3:9092,node4:9092"
);
// 2.2
配置
key
和
value
的序列化类
prop
.
put
(
ProducerConfig
.
KEY_SERIALIZER_CL
ASS_CONFIG
,
StringSerializer
.
class
.
getName
());
27
prop
.
put
(
ProducerConfig
.
VALUE_SERIALIZER_
CLASS_CONFIG
,
StringSerializer
.
class
.
getName
());
//TODO 3.
声明并实例化生产者对象
KafkaProducer
<
String
,
String
>
producer
=
new
KafkaProducer
<
String
,
String
>
(
prop
);
//TODO 4.
发送消息
for
(
int
i
=
0
;
i
<
5
;
i
++
){
//
异步发送消息 不调用
get()
方法
producer
.
send
(
new
ProducerRecord
<>
(
"topicA"
,
"unsync_msg"
+
i
),
new
Callback
() {
//
如下方法在生产者收到
acks
确认时异步调用
@Override
public
void
onCompletion
(
RecordMetadata
recordMetadata
,
Exception e
) {
if
(
e
==
null
){
//
无异常信息,输
出主题和分区信息到控制台
System
.
out
.
println
(
"topic:"
+
recordMetadat
a
.
topic
()
+
",partition:"
+
recordMetadata
.
partition
()
);
}
else
{
//
打印异常信息
28
3
在
node2
上开启
Kafka
消费者进行消费
4
运行
UnSyncCallBackCustomProducer
类
5
观察
node2
上
Kafka
消费者消费消息的情况
6
控制台输出信息
System
.
out
.
println
(
e
.
getMessage
());
}
}
});
Thread
.
sleep
(
5
);
}
//TODO 5.
关闭生产者
producer
.
close
();
}
}
[root@node2 ~]
# kafka-console-consumer.sh
--bootstrap-server node2:9092 --topic
topicA
[root@node2 ~]
# kafka-console-consumer.sh
--bootstrap-server node2:9092 --topic
topicA
unsync_msg0
unsync_msg1
unsync_msg2
unsync_msg3
unsync_msg4
29
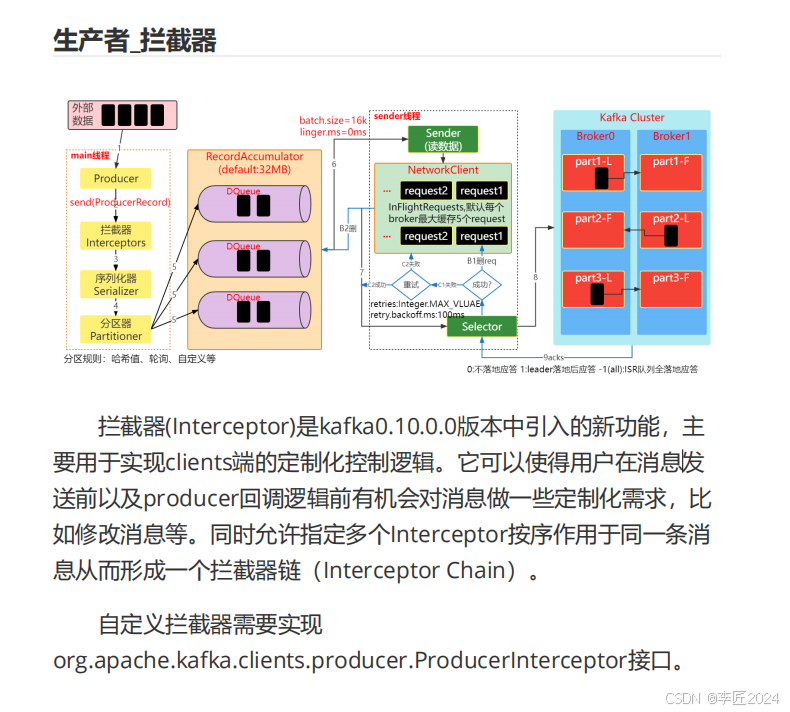
生产者
_
拦截器
拦截器
(Interceptor)
是
kafka0.10.0.0
版本中引入的新功能,主
要用于实现
clients
端的定制化控制逻辑。它可以使得用户在消息发
送前以及
producer
回调逻辑前有机会对消息做一些定制化需求,比
如修改消息等。同时允许指定多个
Interceptor
按序作用于同一条消
息从而形成一个拦截器链(
Interceptor Chain
)。
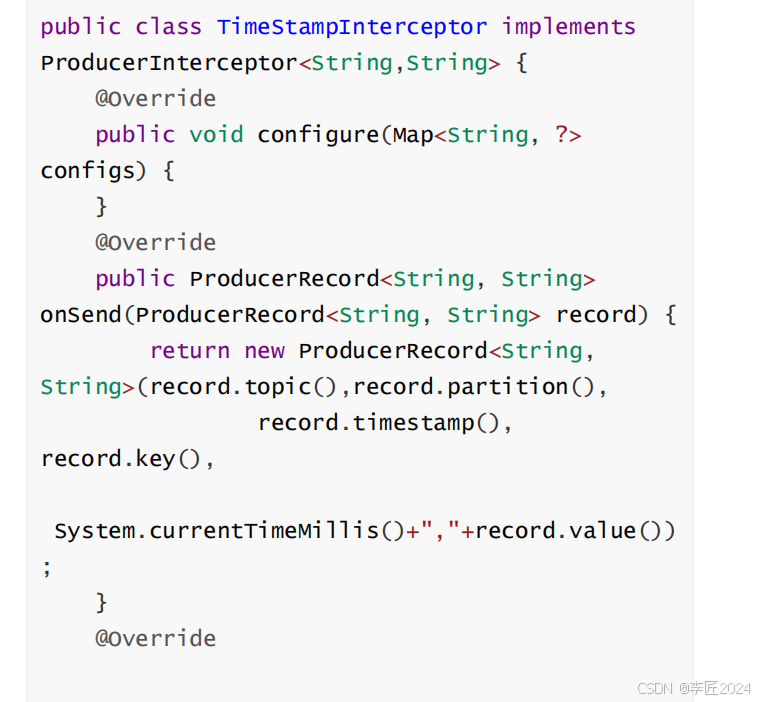
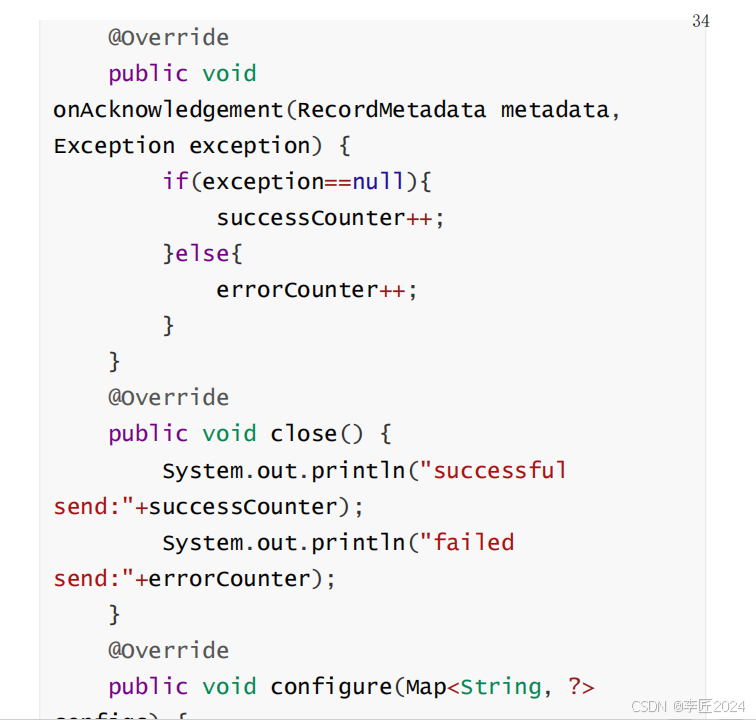
自定义拦截器需要实现
org.apache.kafka.clients.producer.ProducerInterceptor
接口。
topic:topicA,partition:1
topic:topicA,partition:1
topic:topicA,partition:0
topic:topicA,partition:0
topic:topicA,partition:0
18.生产者_拦截器

19.生产者_拦截器二
20.生产者_消息序列化一



21.生产者_消息序列化二
添加依赖
}
public
void
setName
(
String
name
) {
this
.
name
=
name
;
}
public
int
getAge
() {
return
age
;
}
public
void
setAge
(
int
age
) {
this
.
age
=
age
;
}
public
String
getAddress
() {
return
address
;
}
public
void
setAddress
(
String
address
)
{
this
.
address
=
address
;
}
}
39
3
编写自定义序列化类
<dependency>
<groupId>
org.codehaus.jackson
</groupId>
<artifactId>
jackson-mapper
asl
</artifactId>
<version>
1.9.13
</version>
</dependency>
package
com
.
itbaizhan
.
kafka
.
producer
;
import
org
.
apache
.
kafka
.
common
.
serialization
.
Seri
alizer
;
import
org
.
codehaus
.
jackson
.
map
.
ObjectMapper
;
import
java
.
io
.
IOException
;
import
java
.
nio
.
charset
.
StandardCharsets
;
import
java
.
util
.
Map
;
public class
UserSerializer
implements
Serializer
<
UserVo
>
{
private
ObjectMapper objectMapper
;
@Override
public
void
configure
(
Map
<
String
,
?>
configs
,
boolean
isKey
) {
objectMapper
=
new
ObjectMapper
();
//Serializer.super.configure(configs,
isKey);
}
40
4
编写生产者程序
@Override
public
byte
[]
serialize
(
String
topic
,
UserVo data
) {
byte
[]
ret
=
null
;
try
{
ret
=
objectMapper
.
writeValueAsString
(
data
)
.
getBytes
(
StandardCharsets
.
UTF_8
);
}
catch
(
IOException e
) {
throw new
SerializationException
(
"Error when
serializing UserVo to byte[],exception is
"
+
e
.
getMessage
());
}
return
ret
;
}
@Override
public
void
close
() {
objectMapper
=
null
;
//Serializer.super.close();
}
}
package
com
.
itbaizhan
.
kafka
.
producer
;
import
org
.
apache
.
kafka
.
clients
.
producer
.
*
;
41
import
org
.
apache
.
kafka
.
common
.
serialization
.
Stri
ngSerializer
;
import
java
.
util
.
Properties
;
import
java
.
util
.
concurrent
.
ExecutionException
;
public class
UserSerProducer
{
public static
void
main
(
String
[]
args
)
throws
ExecutionException
,
InterruptedException
{
//TODO 1.
声明并实例化
Kafka Producer
的
配置文件对象
Properties prop
=
new
Properties
();
//TODO 2.
为配置文件对象设置参数
// 2.1
配置
bootstrap_servers
prop
.
put
(
ProducerConfig
.
BOOTSTRAP_SERVERS
_CONFIG
,
"node2:9092,node3:9092,node4:9092"
);
// 2.2
配置
key
和
value
的序列化类
prop
.
put
(
ProducerConfig
.
KEY_SERIALIZER_CL
ASS_CONFIG
,
StringSerializer
.
class
.
getName
());
prop
.
put
(
ProducerConfig
.
VALUE_SERIALIZER_
CLASS_CONFIG
,
UserSerializer
.
class
.
getName
());
42
//TODO 3.
声明并实例化生产者对象 注意
value
的泛型类型
KafkaProducer
<
String
,
UserVo
>
producer
=
new
KafkaProducer
<
String
,
UserVo
>
(
prop
);
//TODO 4.
发送消息
UserVo userVo
=
new
UserVo
(
"tuhao"
,
18
,
"
北京
"
);
producer
.
send
(
new
ProducerRecord
<
String
,
UserVo
>
(
"topicA"
,
userVo
),
new
Callback
() {
//
如下方法在生产者收到
acks
确认
时异步调用
@Override
public
void
onCompletion
(
RecordMetadata
recordMetadata
,
Exception e
) {
if
(
e
==
null
){
//
无异常信息,输出主题
和分区信息到控制台
System
.
out
.
println
(
"topic:"
+
recordMetadat
a
.
topic
()
+
",partition:"
+
recordMetadata
.
partition
()
);
}
else
{
//
打印异常信息
System
.
out
.
println
(
e
.
getMessage
());
}
}
43
5
在
node2
上开启
Kafka
消费者进行消费
6
运行
UserSerProducer
类
7
观察
node2
上
Kafka
消费者消费消息的情况
实时效果反馈
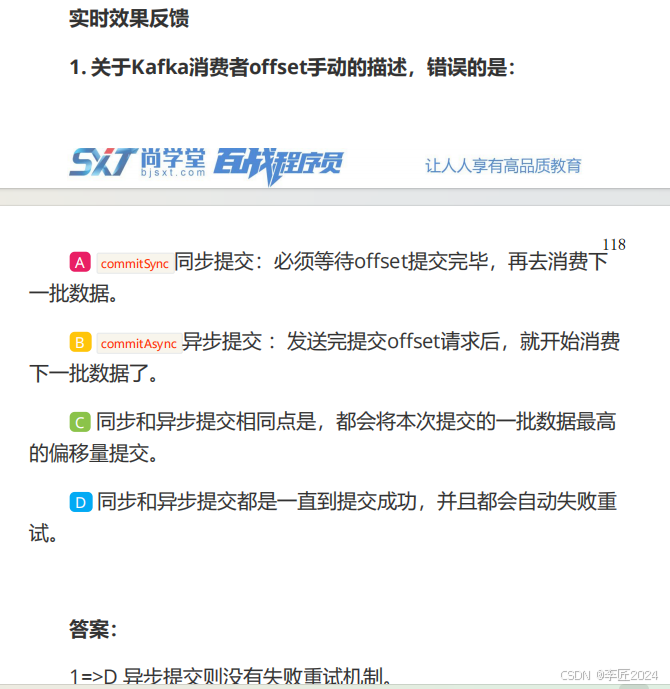
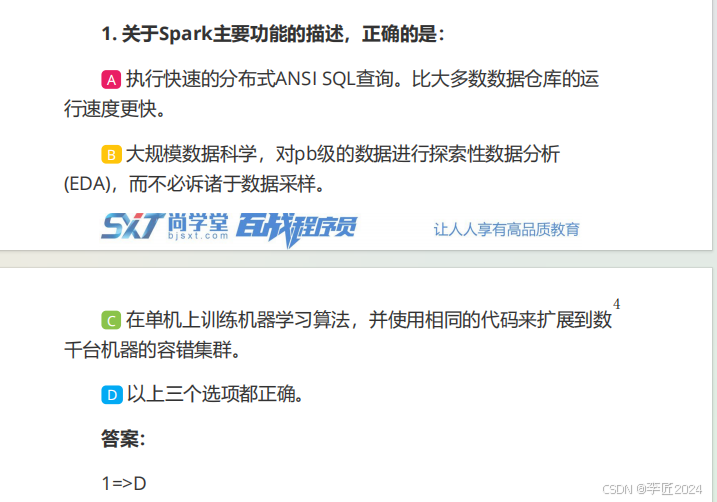
1.
关于
Kafka
生产者消息序列化的描述,正确的是:
A
默认提供了序列化类,如
BytesSerializer
、
IntegerSerializer
、
StringSerializer
等。
B
自定义序列化类需要实现
org.apache.kafka.common.serialization.Serializer
。
C
生产者序列化机制使用起来比较简单,需要在构造
producer
对象之前指定参数
key.serializer
和
value.serializer
。
});
Thread
.
sleep
(
50
);
//TODO 5.
关闭生产者
producer
.
close
();
}
}

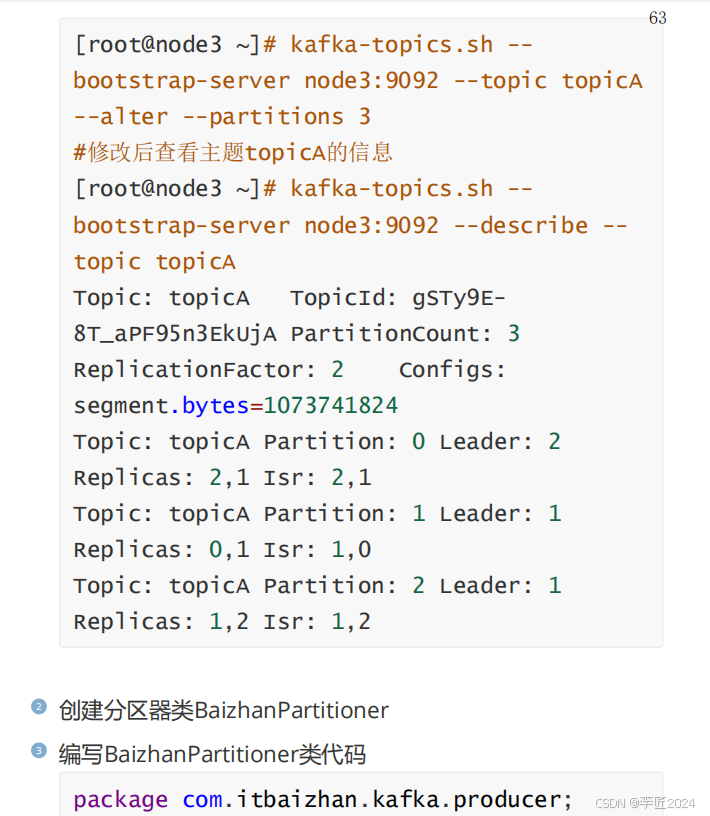
22.生产者_分区的优势
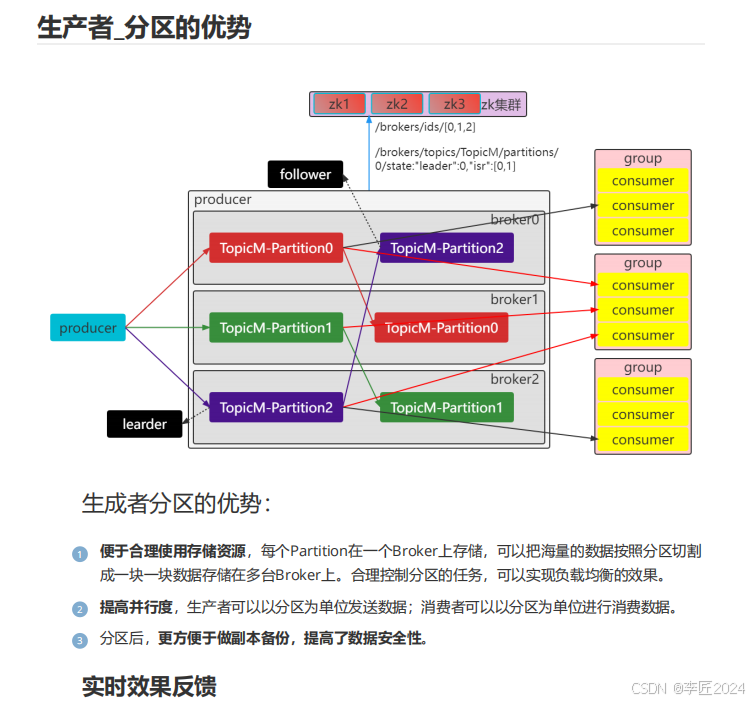

23.生产者_分区策略
24.生产者_分区实战一

25.生产者_分区实战二

26.生产者_自定义分区机制一

27.生产者_自定义分区机制二


28.生产者_消息无丢失
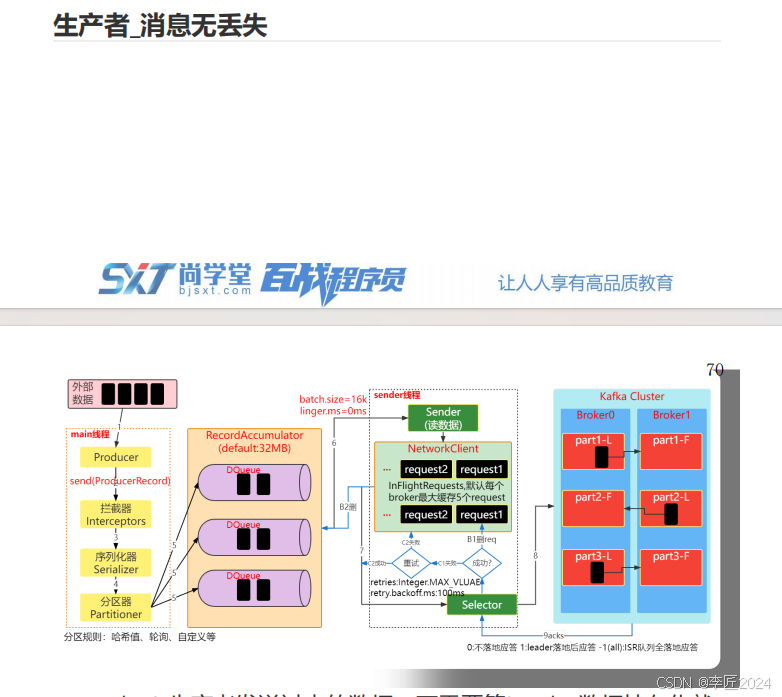
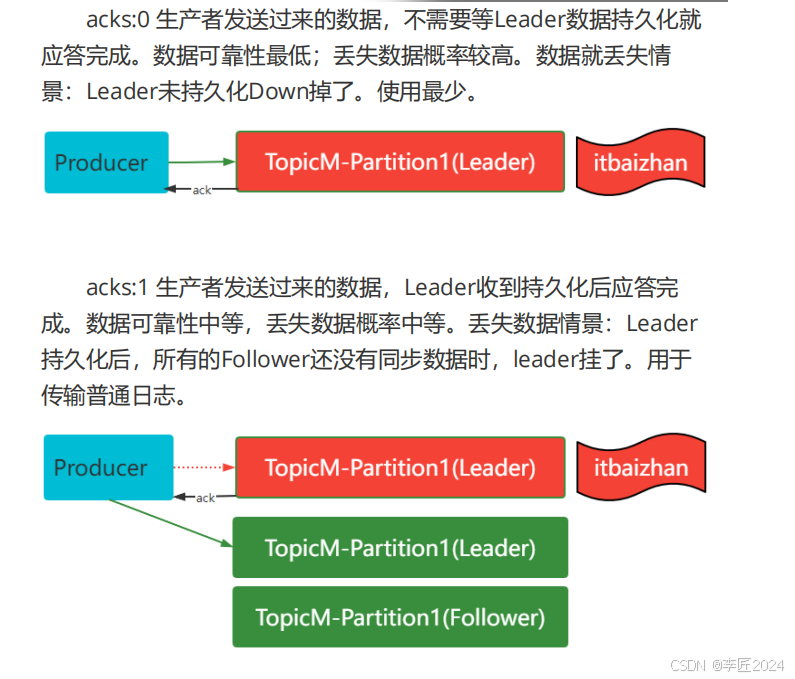
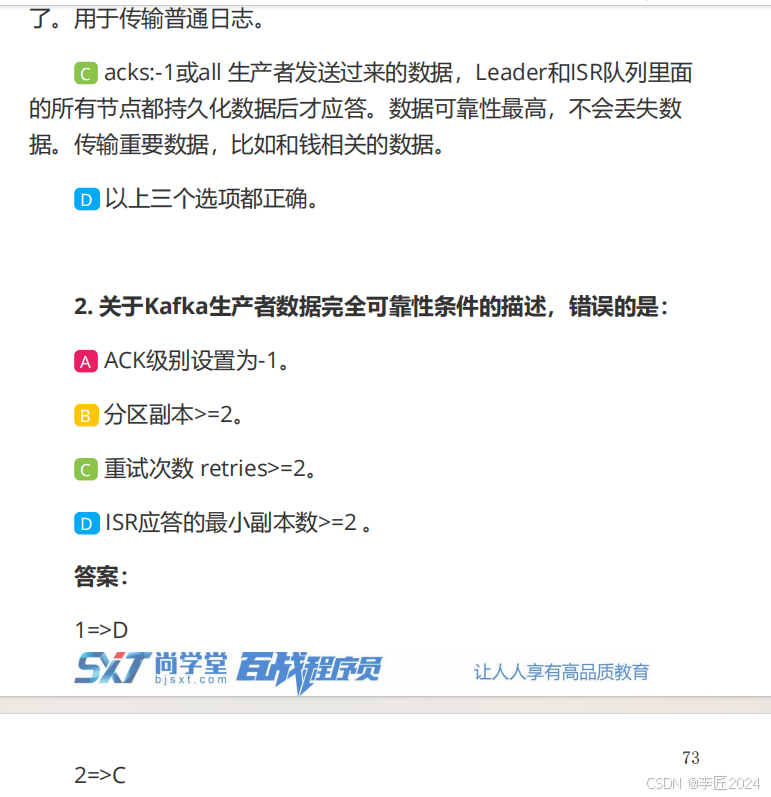
29.生产者_数据去重

30.生产者_数据去重_幂等性


31.生产者_数据去重_事务原理分析

32.生产者_数据去重_事务代码实现



章节三.BROKER
33.BROKER_ZOOKEEPER存储信息
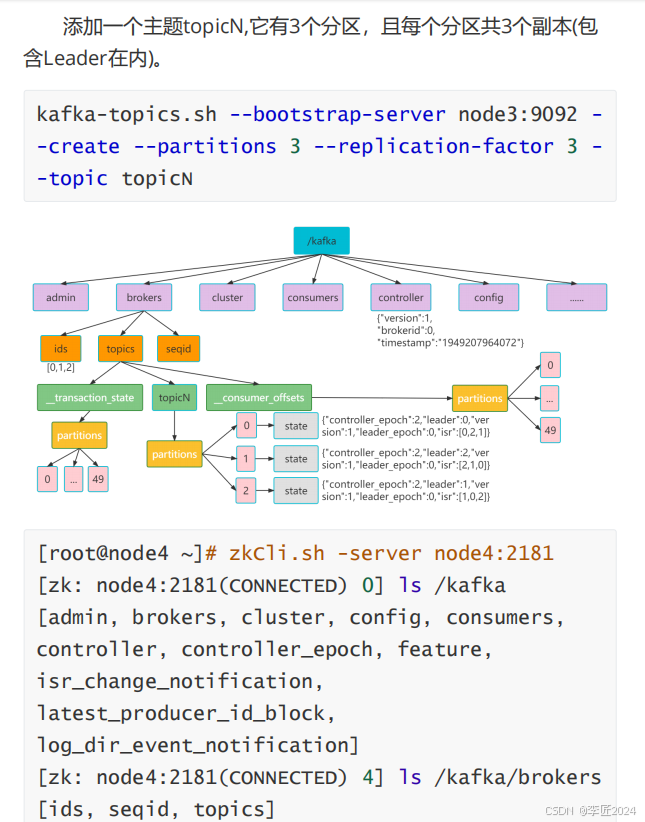
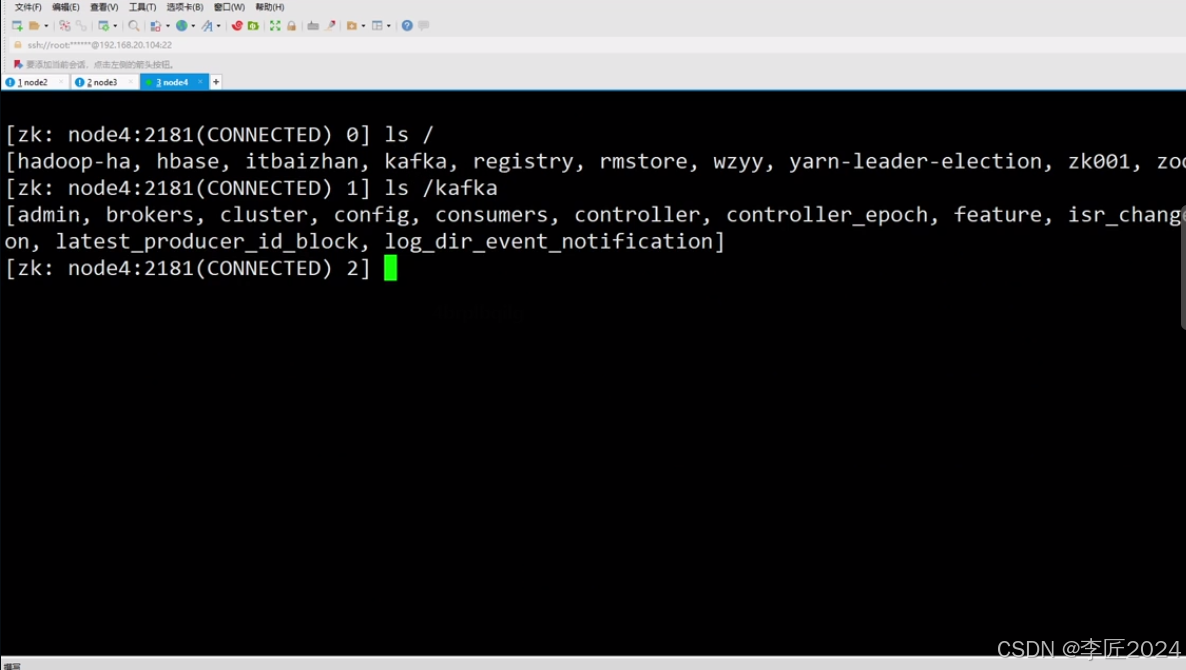
34.BROKER_工作流程

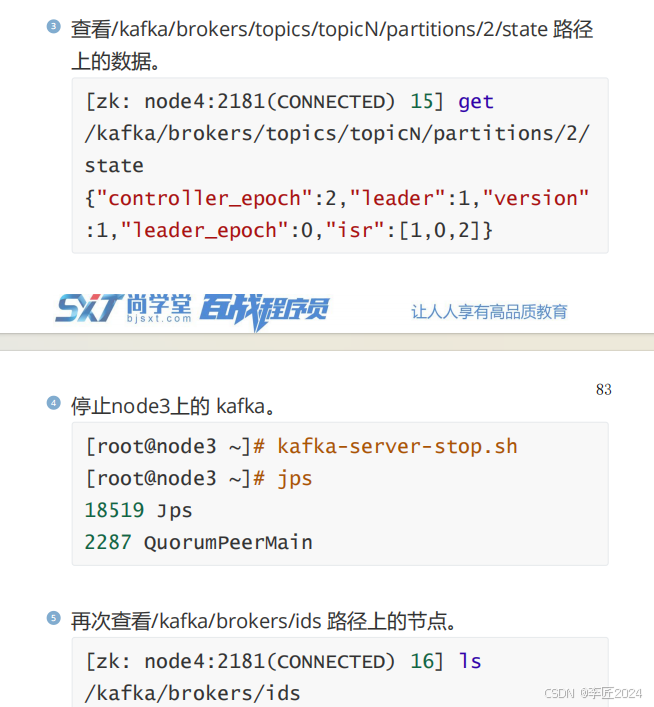

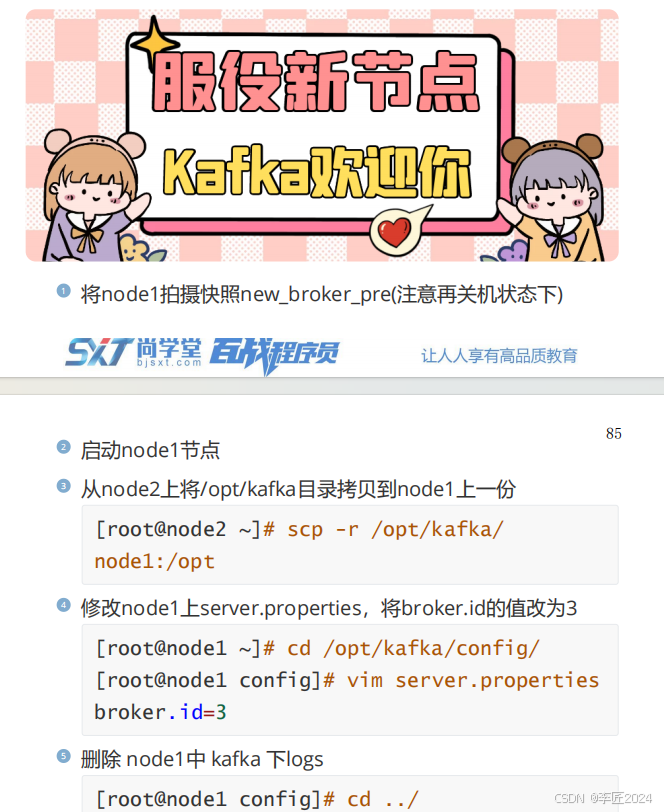
35.BROKER_服役新节点

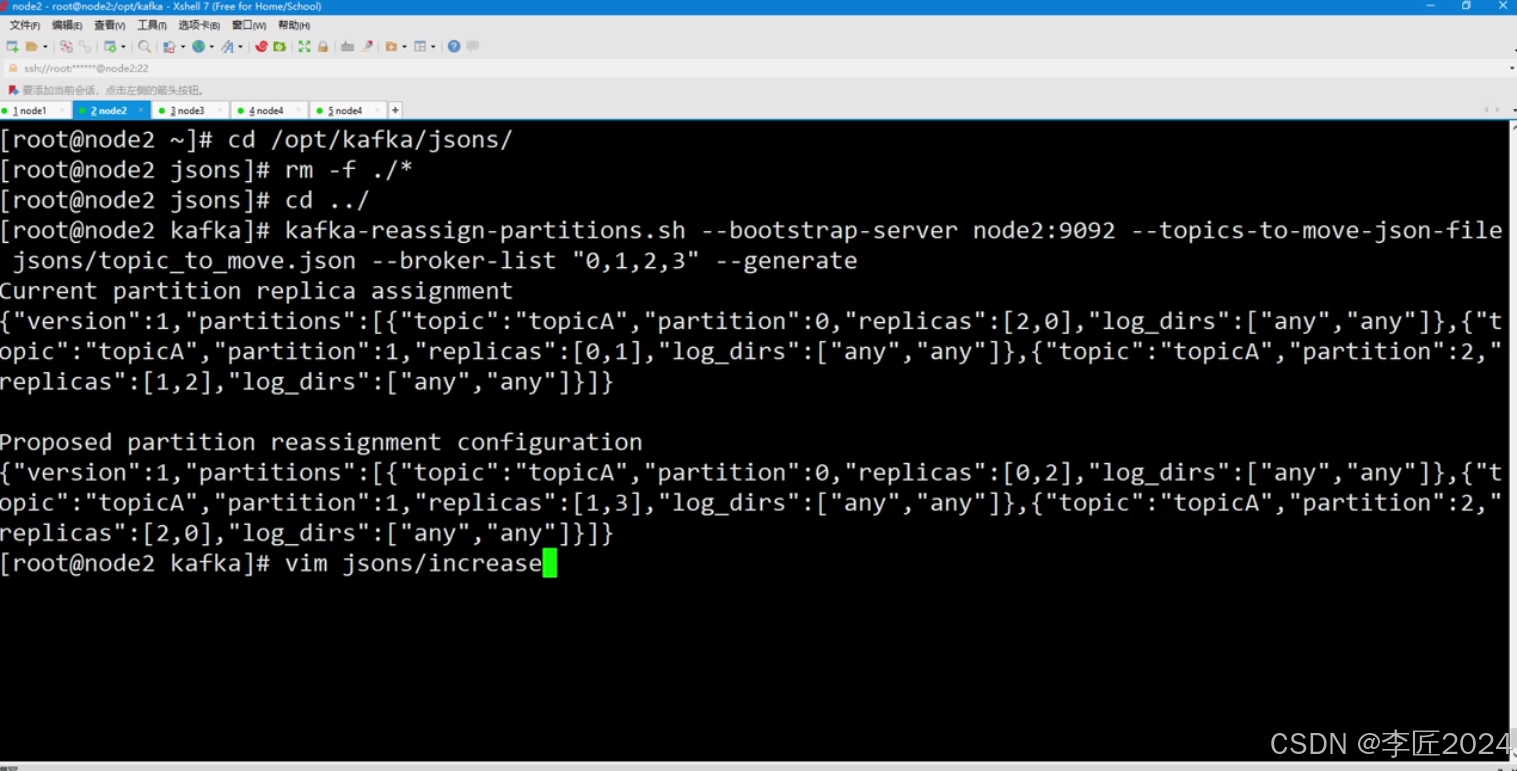
36.BROKER_退役节点


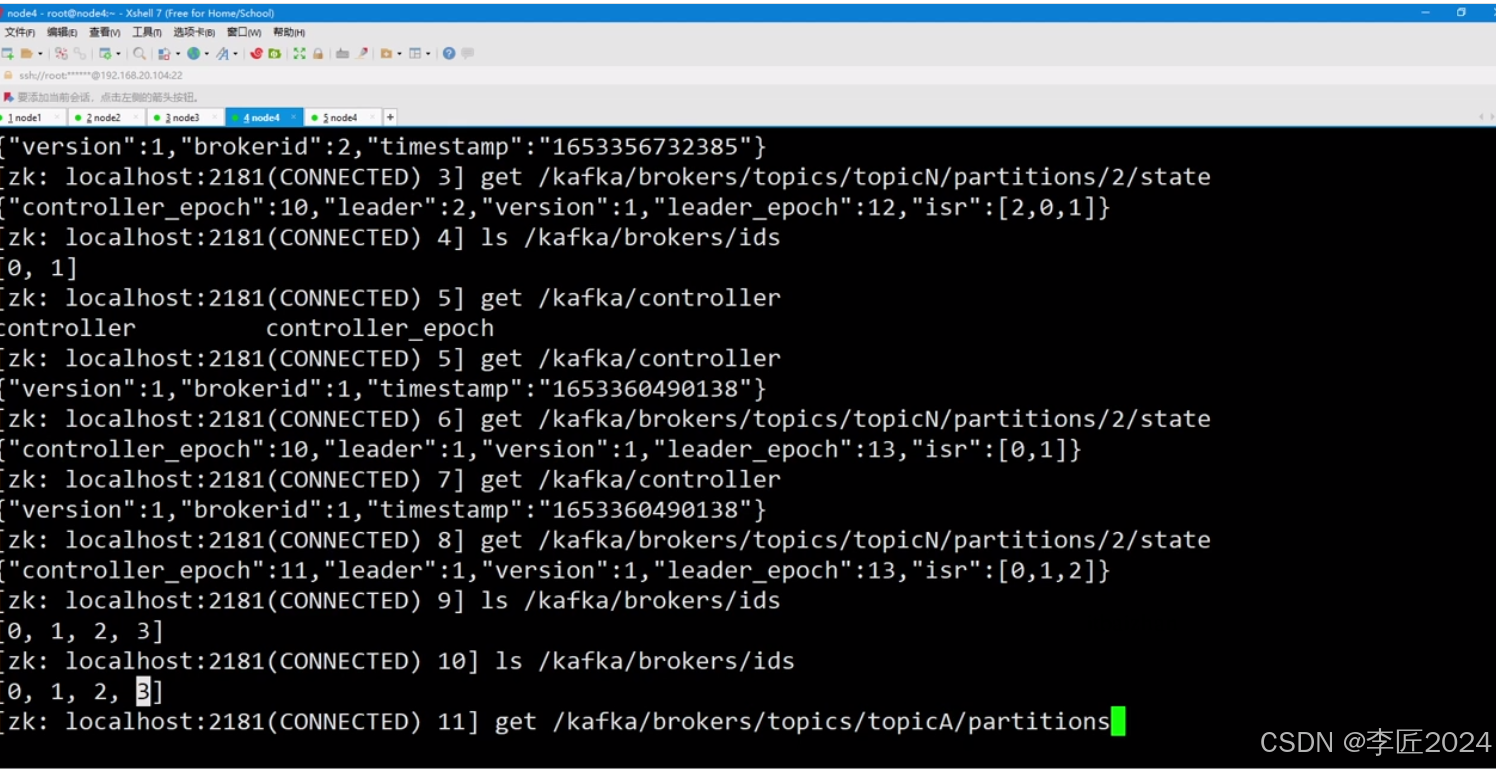
37.BROKER_replica


章节四.消费者
38.消费者_消费方式
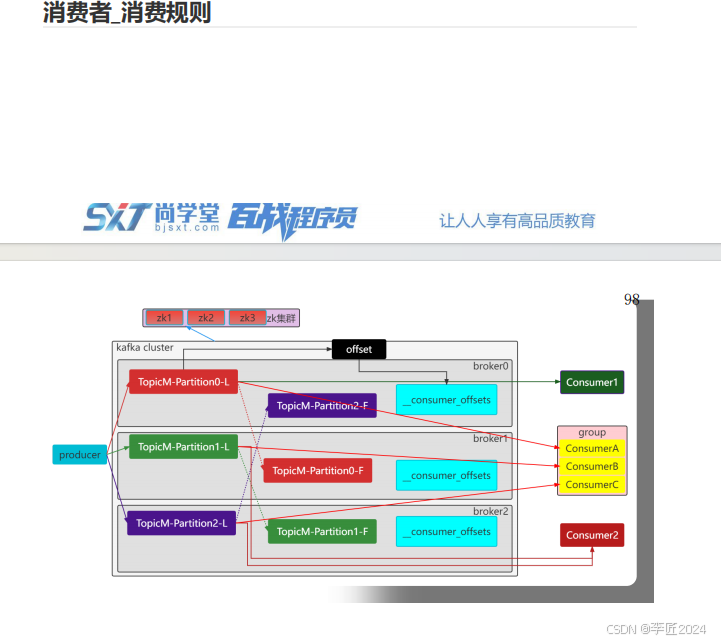

39.消费者_消费规则


40.消费者_独立消费主题实战
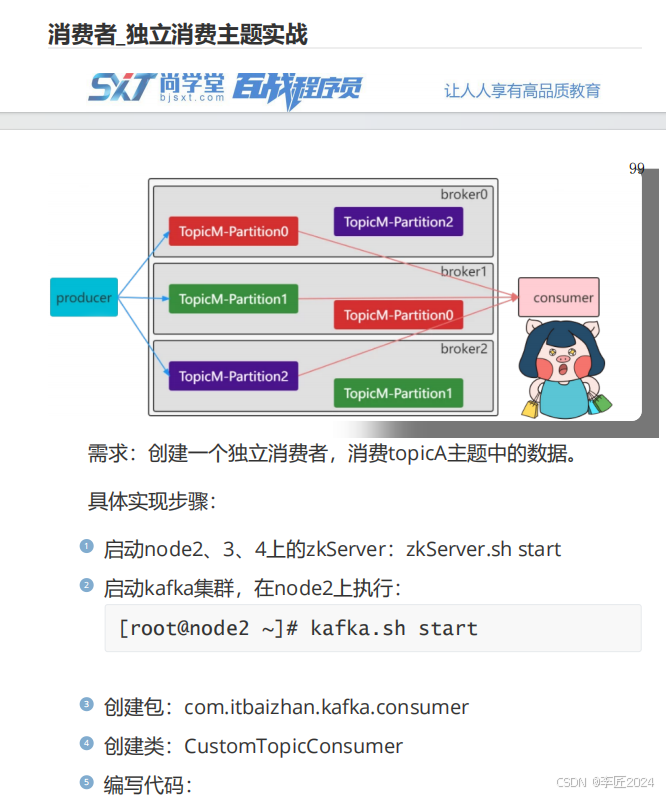
41.消费者_独立消费主题实战一
package
com
.
itbaizhan
.
kafka
.
consumer
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
Consumer
Config
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
Consumer
Record
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
Consumer
Records
;
99
import
org
.
apache
.
kafka
.
clients
.
consumer
.
KafkaCon
sumer
;
import
org
.
apache
.
kafka
.
common
.
serialization
.
Stri
ngDeserializer
;
import
java
.
time
.
Duration
;
import
java
.
util
.
ArrayList
;
import
java
.
util
.
Arrays
;
import
java
.
util
.
Properties
;
//
创建一个独立消费者,消费
topicA
主题下的数据
public class
CustomTopicConsumer
{
public static
void
main
(
String
[]
args
)
{
//1.
创建消费者属性文件对象
Properties prop
=
new
Properties
();
//2.
为属性对象设置相关参数
//
设置
kafka
服务器
prop
.
put
(
ConsumerConfig
.
BOOTSTRAP_SERVERS
_CONFIG
,
"node2:9092"
);
//
设置
key
和
value
的序列化类
prop
.
put
(
ConsumerConfig
.
KEY_DESERIALIZER_
CLASS_CONFIG
,
StringDeserializer
.
class
.
getName
());
100
prop
.
put
(
ConsumerConfig
.
VALUE_DESERIALIZE
R_CLASS_CONFIG
,
StringDeserializer
.
class
.
getName
());
//
设置消费者的消费者组的名称
prop
.
put
(
ConsumerConfig
.
GROUP_ID_CONFIG
,
"
testCg"
);
//3.
创建消费者对象
KafkaConsumer
<
String
,
String
>
kafkaConsumer
=
new
KafkaConsumer
<
String
,
String
>
(
prop
);
//4.
注册要消费的主题
/*ArrayList<String> topics = new
ArrayList<>();
topics.add("topicA");
kafkaConsumer.subscribe(topics);*/
kafkaConsumer
.
subscribe
(
Arrays
.
asList
(
"to
picA"
));
//5.
拉取数据并打印输出
while
(
true
){
//6.
设置
1s
消费一批数据
ConsumerRecords
<
String
,
String
>
consumerRecords
=
kafkaConsumer
.
poll
(
Duration
.
ofSeconds
(
1
))
;
//7.
打印输出消费到的数据
101
6
运行
CustomTopicConsumer
类
7
在
Kafka
集群控制台,创建
Kafka
生产者,并输入数据。
8
在
IDEA
控制台观察接收到的数据。
9
Ctrl+C
关闭生产者
10
消费者程序
42.消费者_独立消费主题实战二

43.消费者_消费者组概述


44.消费者_消费者组实战
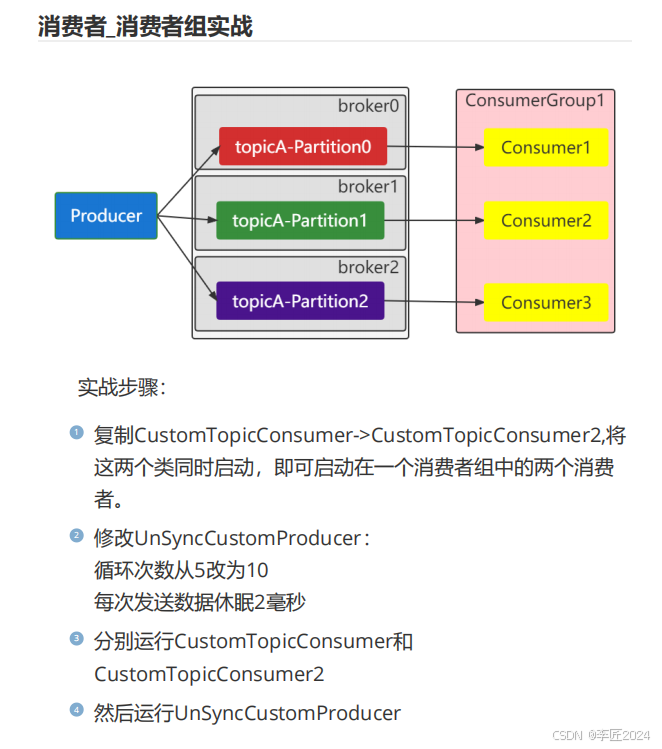

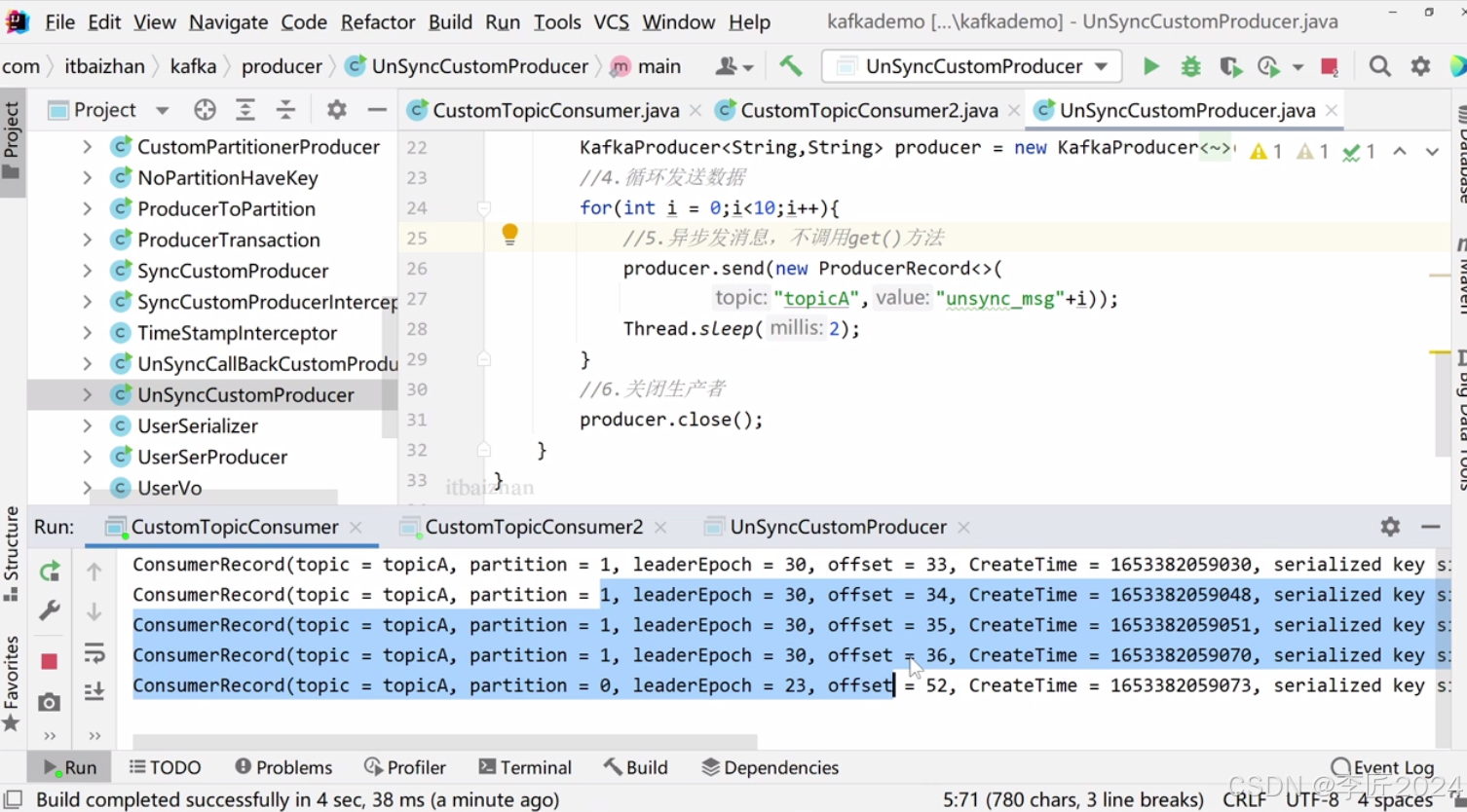
45.消费者_offset剖析
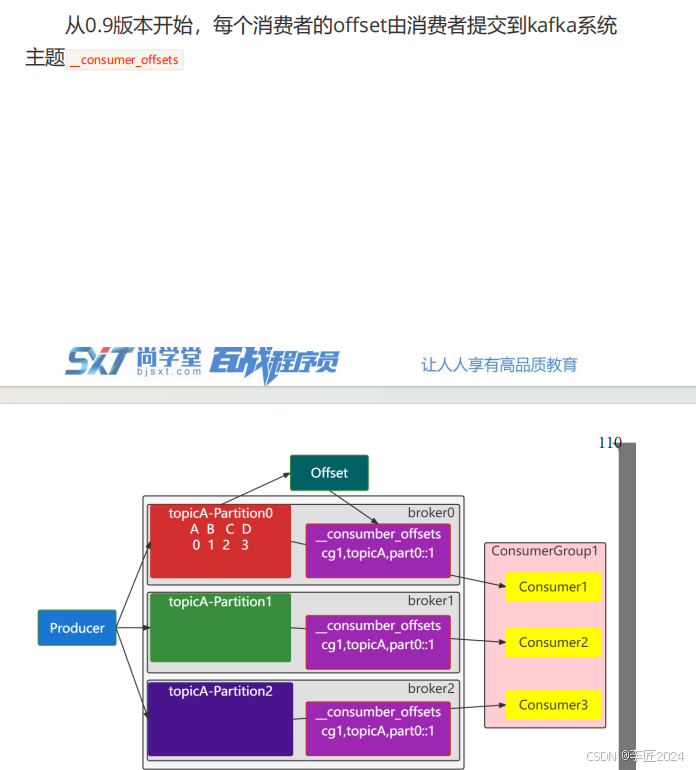

46.消费者_offset自动提交



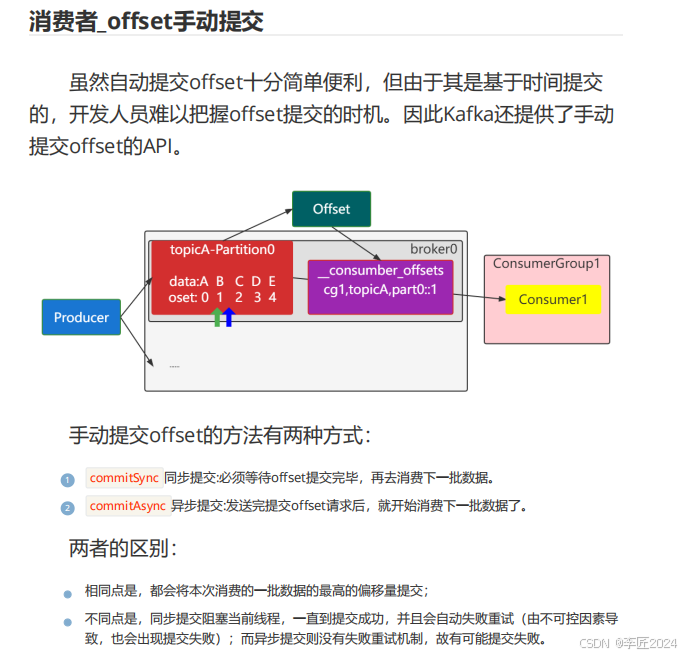
47.消费者_offset手动提交
48.消费者_offset手动提交实战
同步提交:
package
com
.
itbaizhan
.
kafka
.
consumer
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
ConsumerConfi
g
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
ConsumerRecor
d
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
ConsumerRecor
ds
;
118
import
org
.
apache
.
kafka
.
clients
.
consumer
.
KafkaConsumer
;
import
org
.
apache
.
kafka
.
common
.
serialization
.
StringDes
erializer
;
import
java
.
time
.
Duration
;
import
java
.
util
.
Arrays
;
import
java
.
util
.
Properties
;
public class
ConsumerHandSyncCommit
{
public static
void
main
(
String
[]
args
) {
//1.
创建属性对象
Properties prop
=
new
Properties
();
//2.
设置相关参数
prop
.
put
(
ConsumerConfig
.
BOOTSTRAP_SERVERS_CONF
IG
,
"node2:9092,node3:9092,node4:9092"
);
prop
.
put
(
ConsumerConfig
.
KEY_DESERIALIZER_CLASS
_CONFIG
,
StringDeserializer
.
class
.
getName
());
prop
.
put
(
ConsumerConfig
.
VALUE_DESERIALIZER_CLA
SS_CONFIG
,
StringDeserializer
.
class
.
getName
());
//
配置消费者组
119
异步提交:
prop
.
put
(
ConsumerConfig
.
GROUP_ID_CONFIG
,
"cghan
dSyncCommit"
);
//
设置为非自动提交
prop
.
put
(
ConsumerConfig
.
ENABLE_AUTO_COMMIT_CON
FIG
,
false
);
//3.
创建消费者对象
KafkaConsumer
<
String
,
String
>
consumer
=
new
KafkaConsumer
<
String
,
String
>
(
prop
);
//4.
注册消费主题
consumer
.
subscribe
(
Arrays
.
asList
(
"topicA"
));
//5.
消费数据
while
(
true
){
ConsumerRecords
<
String
,
String
>
records
=
consumer
.
poll
(
Duration
.
ofSeconds
(
1
));
for
(
ConsumerRecord record
:
records
){
System
.
out
.
println
(
record
.
value
());
}
//6.
同步提交
offset
consumer
.
commitSync
();
}
}
}
package
com
.
itbaizhan
.
kafka
.
consumer
;
120
import
org
.
apache
.
kafka
.
clients
.
consumer
.
ConsumerConfi
g
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
ConsumerRecor
d
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
ConsumerRecor
ds
;
import
org
.
apache
.
kafka
.
clients
.
consumer
.
KafkaConsumer
;
import
org
.
apache
.
kafka
.
common
.
serialization
.
StringDes
erializer
;
import
java
.
time
.
Duration
;
import
java
.
util
.
Arrays
;
import
java
.
util
.
Properties
;
public class
ConsumerHandASyncCommit
{
public static
void
main
(
String
[]
args
) {
//1.
创建属性对象
Properties prop
=
new
Properties
();
//2.
设置相关参数
prop
.
put
(
ConsumerConfig
.
BOOTSTRAP_SERVERS_CONF
IG
,
"node2:9092,node3:9092,node4:9092"
);
121
prop
.
put
(
ConsumerConfig
.
KEY_DESERIALIZER_CLASS
_CONFIG
,
StringDeserializer
.
class
.
getName
());
prop
.
put
(
ConsumerConfig
.
VALUE_DESERIALIZER_CLA
SS_CONFIG
,
StringDeserializer
.
class
.
getName
());
//
配置消费者组
prop
.
put
(
ConsumerConfig
.
GROUP_ID_CONFIG
,
"cghan
dAsyncCommit"
);
//
设置为非自动提交
prop
.
put
(
ConsumerConfig
.
ENABLE_AUTO_COMMIT_CON
FIG
,
false
);
//3.
创建消费者对象
KafkaConsumer
<
String
,
String
>
consumer
=
new
KafkaConsumer
<
String
,
String
>
(
prop
);
//4.
注册消费主题
consumer
.
subscribe
(
Arrays
.
asList
(
"topicA"
));
//5.
消费数据
while
(
true
){
ConsumerRecords
<
String
,
String
>
records
=
consumer
.
poll
(
Duration
.
ofSeconds
(
1
));
for
(
ConsumerRecord record
:
records
){
122
System
.
out
.
println
(
record
.
value
());
}
//6.
同步提交
offset
consumer
.
commitAsync
();
}
}
}
Spark分布式计算框架一
章节一.概述
1.课程介绍

2.概述_什么是Spark?


3.概述_Spark主要功能

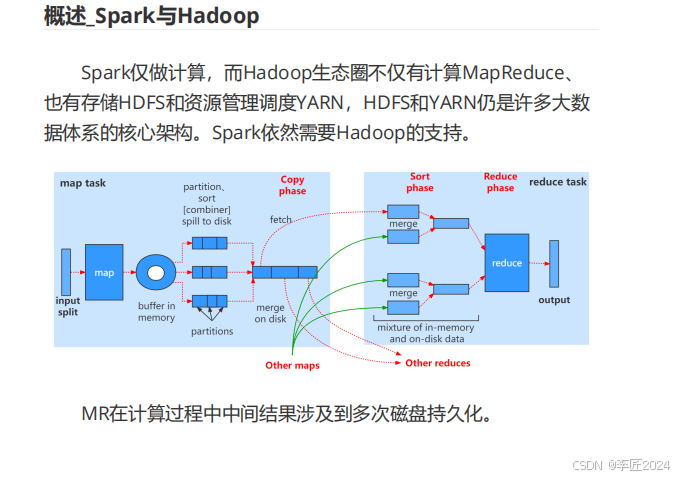
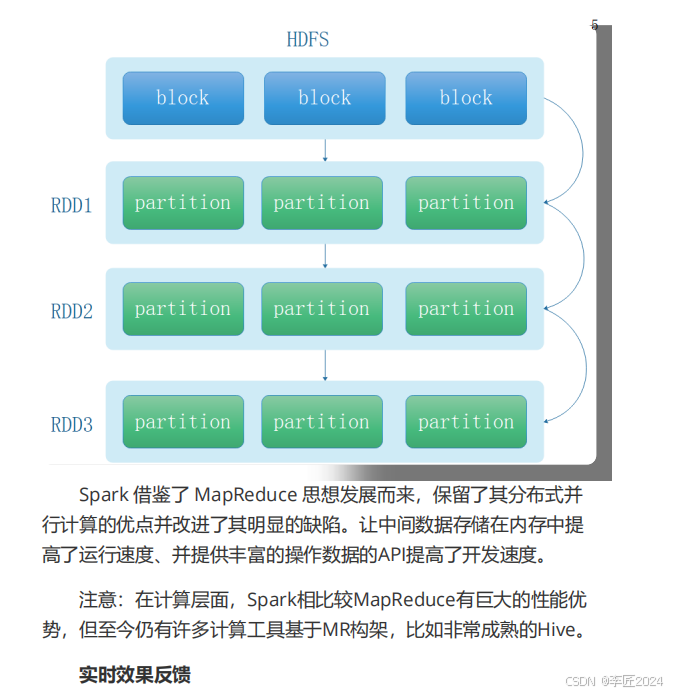
4.概述_SPARK与hadoop
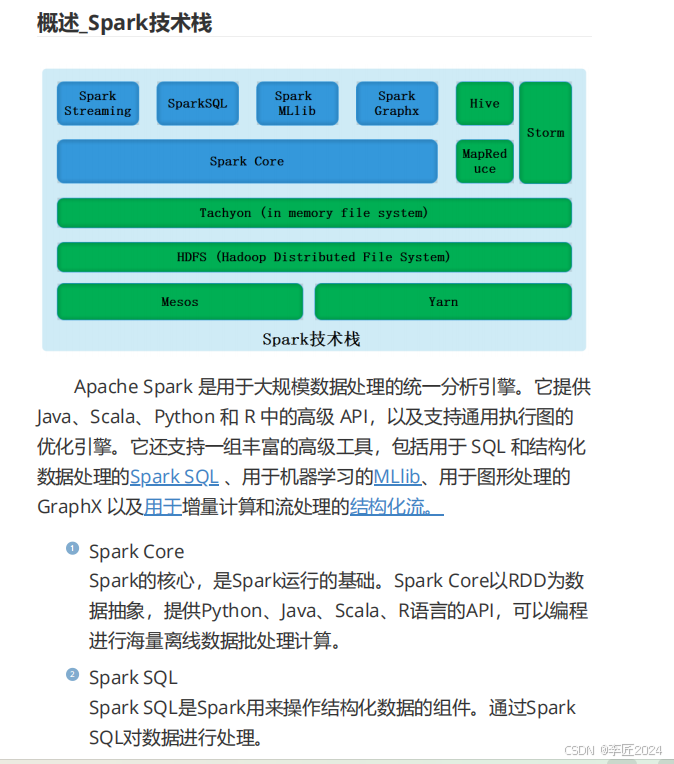
5.概述_spark技术栈

6.概述_PYSPARK VS SPARK


章节二.运行模式
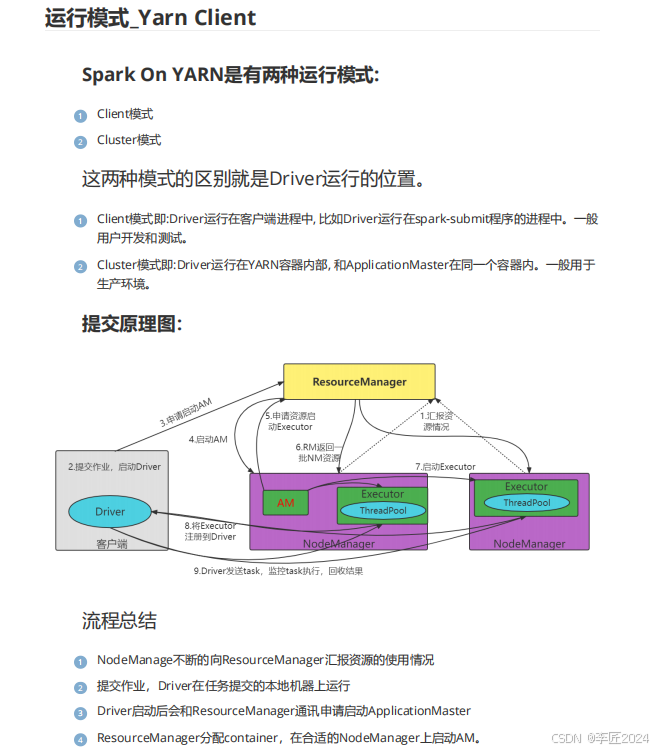
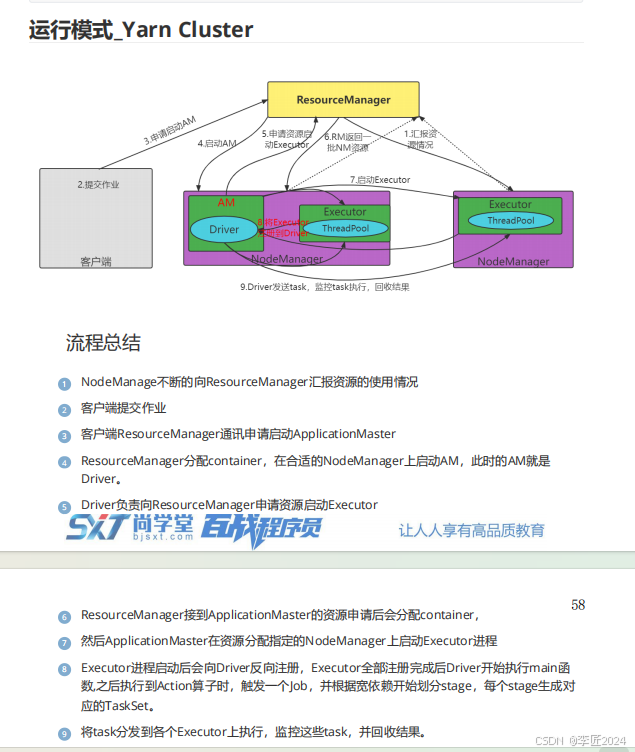
7.运行模式_概述


8.运行模式_WORDCOUNT一


9.运行模式_WORDCOUNT二
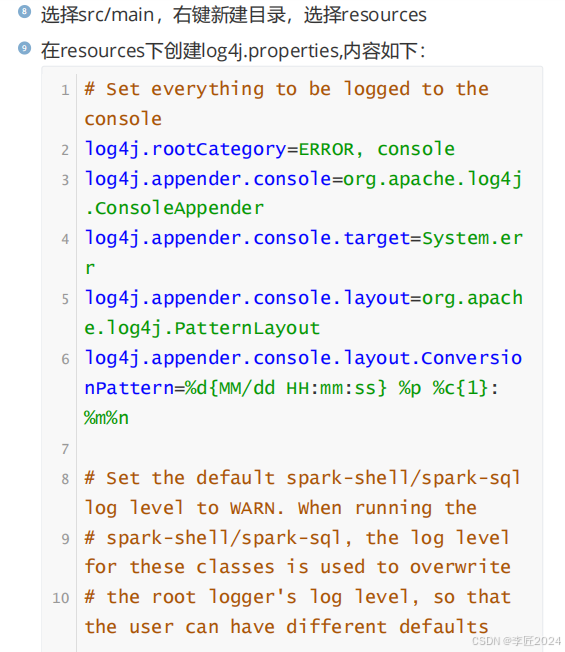
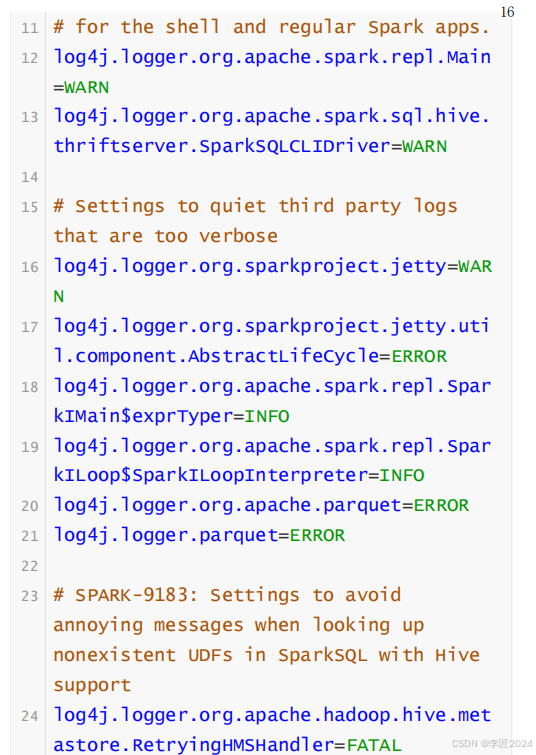
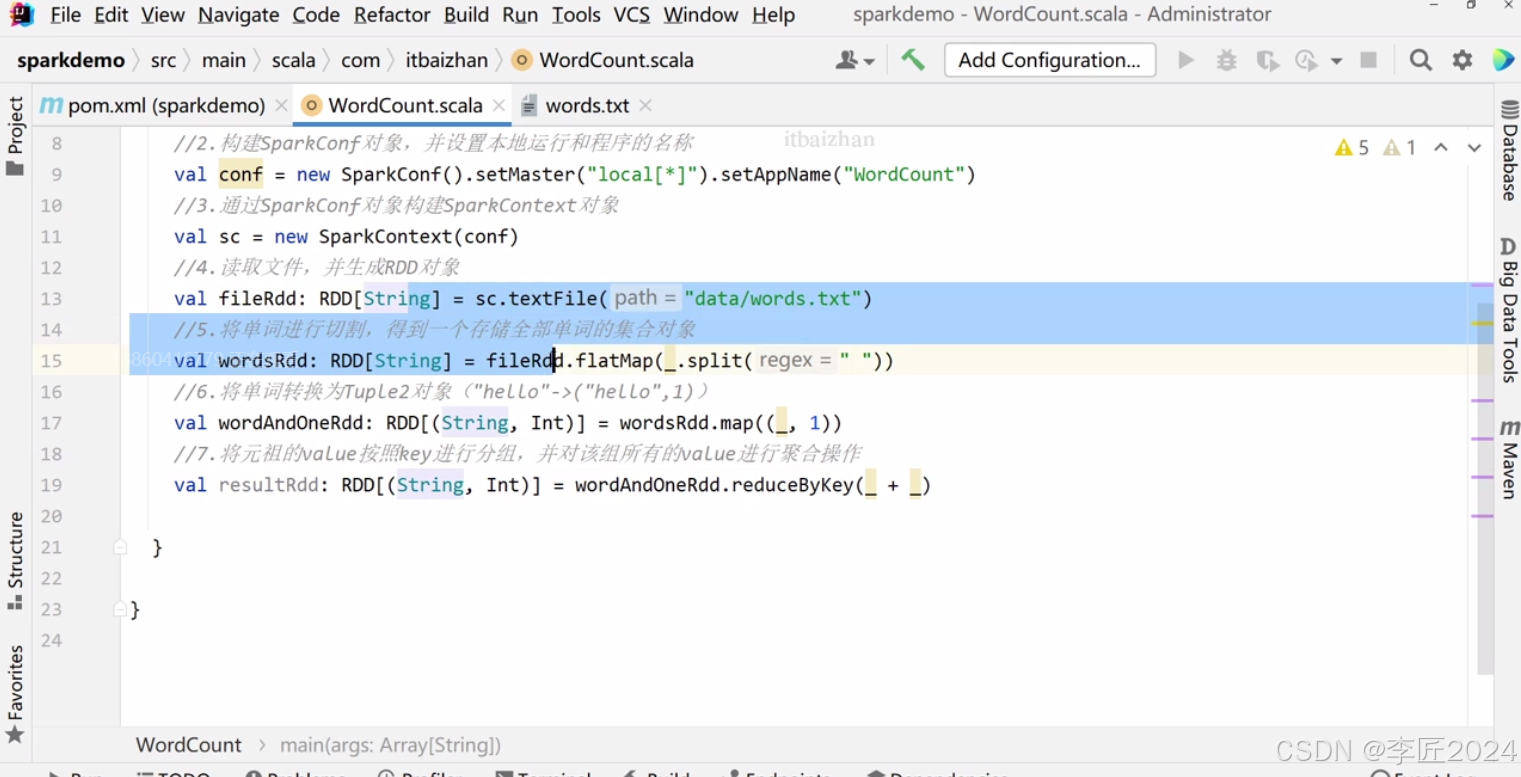
10.运行模式_local模式安装

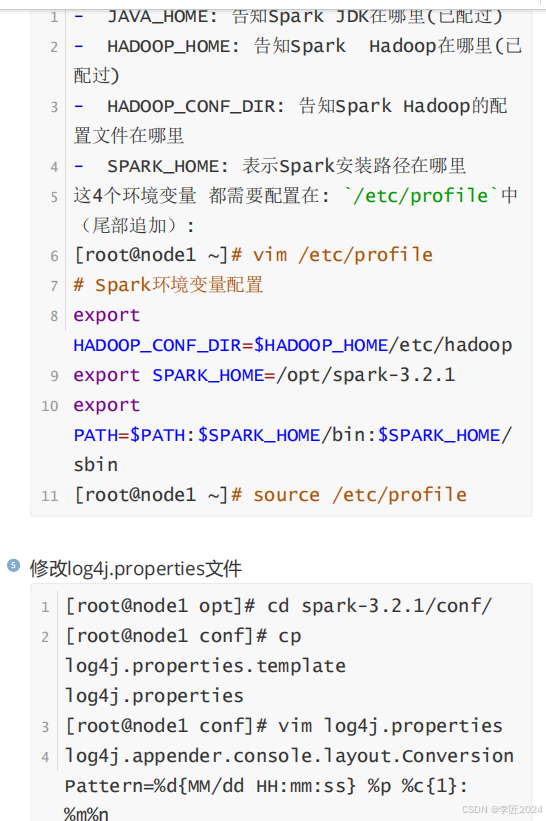
11.运行模式_local模式webui

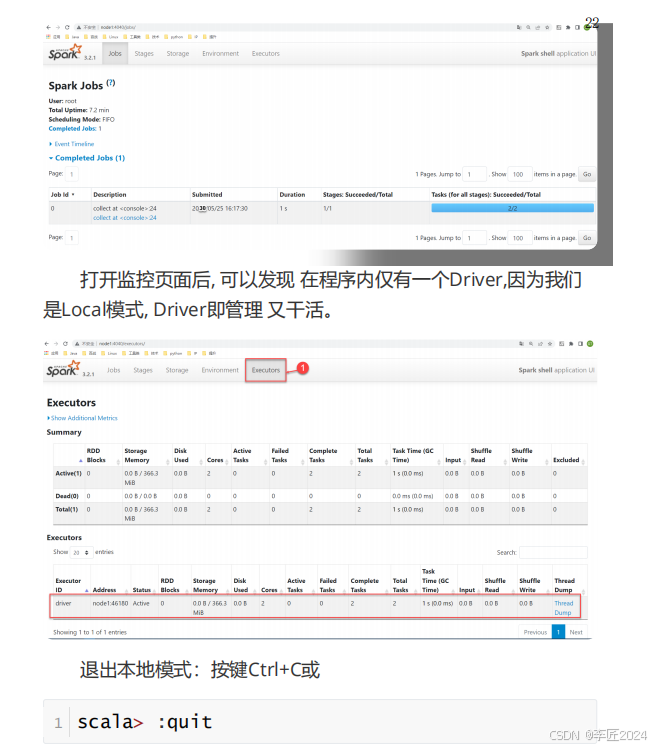
12.运行模式_Spark目录介绍
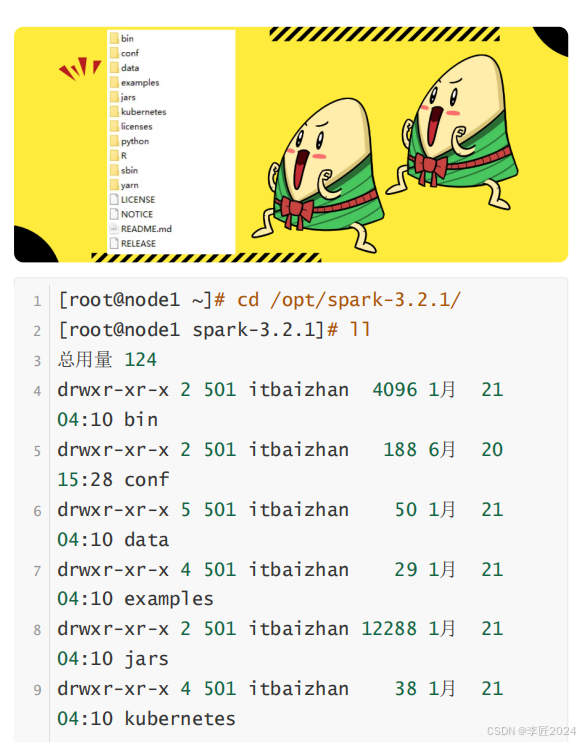
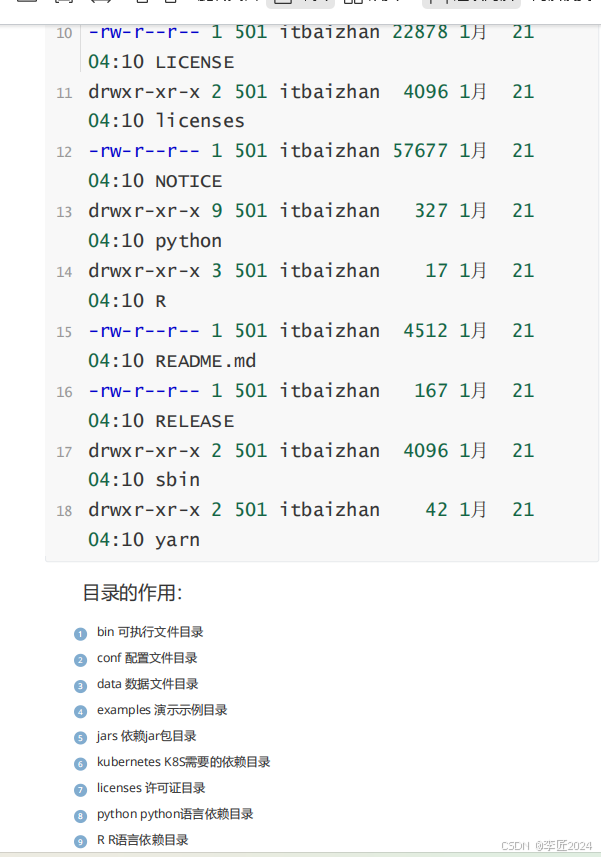
13.运行模式_spark源码解析

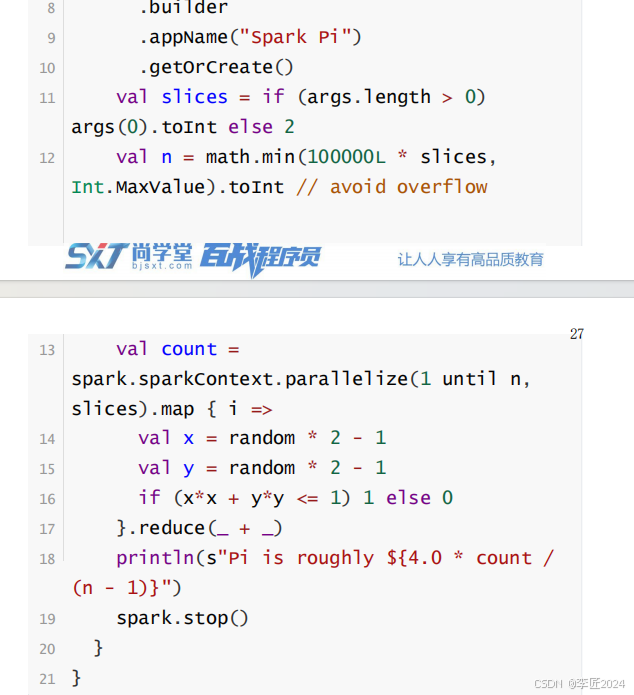
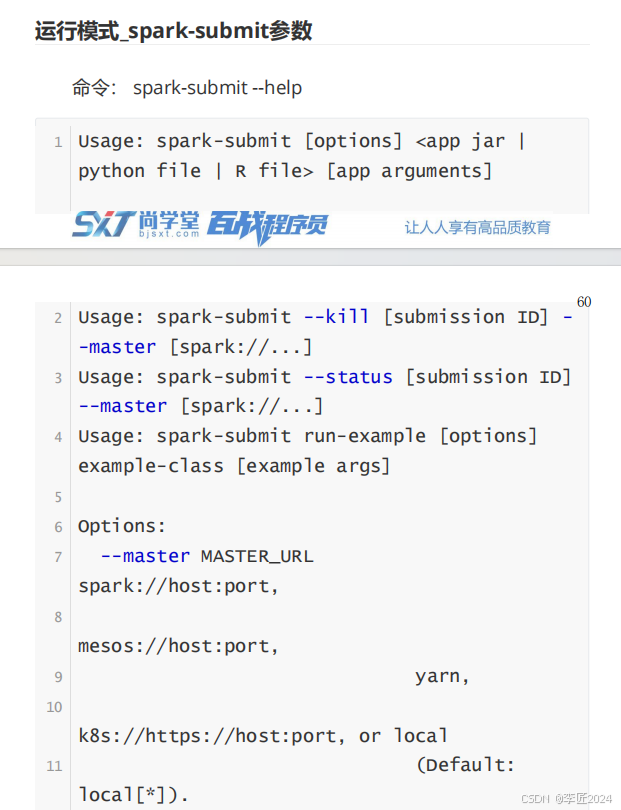
14.运行模式_spark-submit

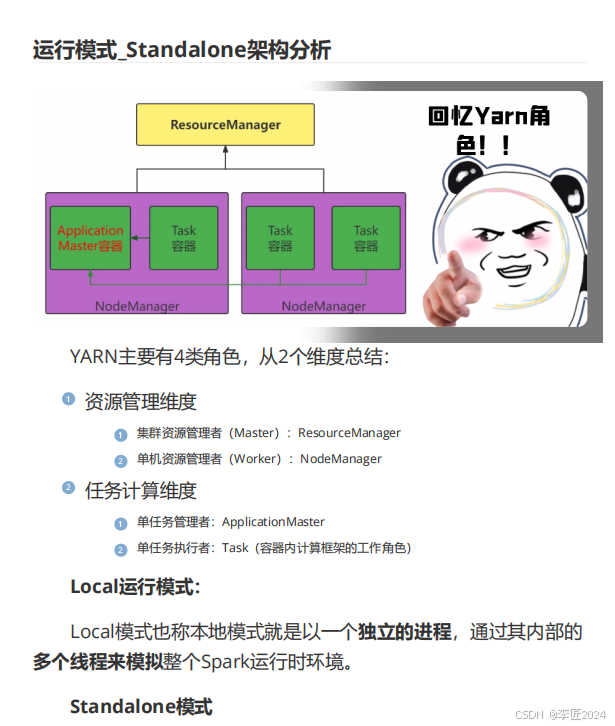
15.运行模式_standalone架构分析
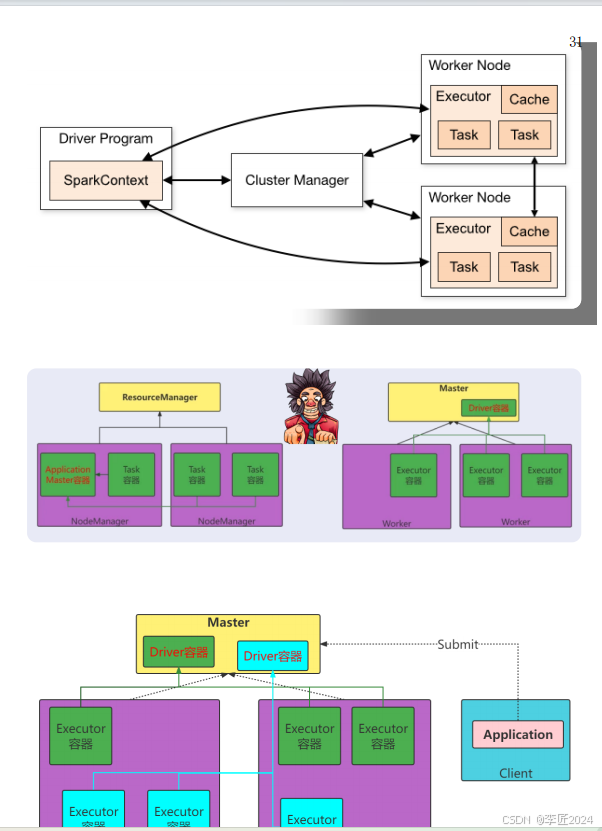
16.运行模式_standalone模式安装一

17.运行模式_standalone模式安装二
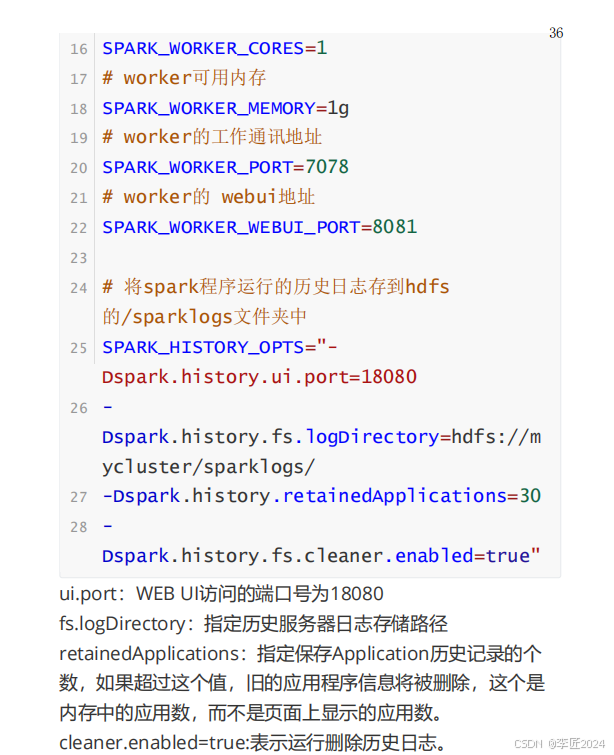

18.运行模式_standalone启动测试
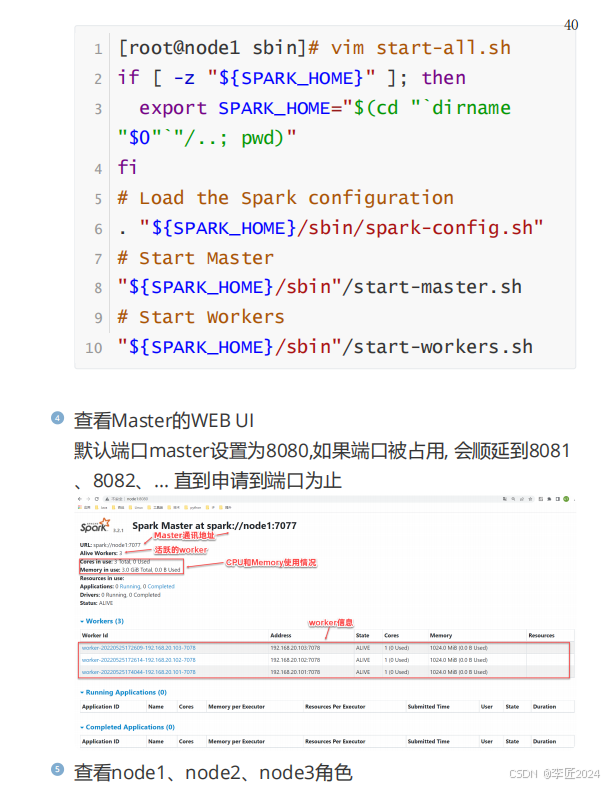
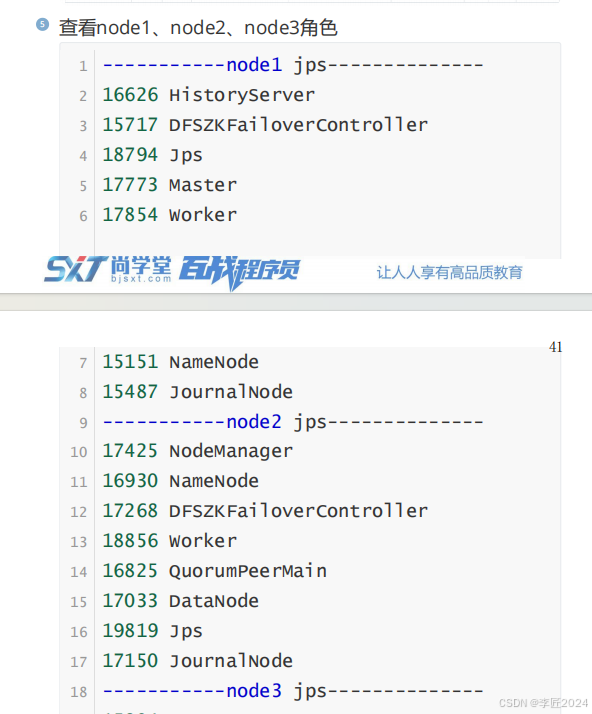
19.运行模式_standalone执行任务
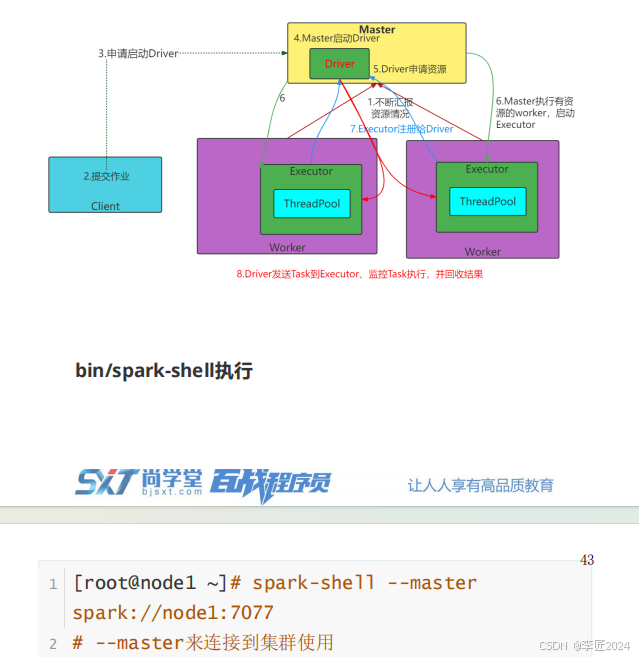
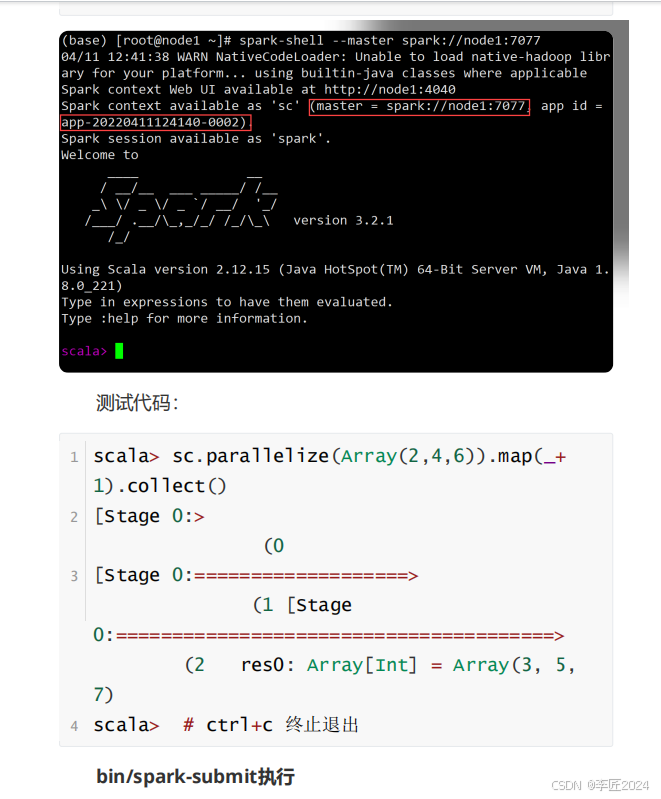
20.运行模式_查看历史日志webui
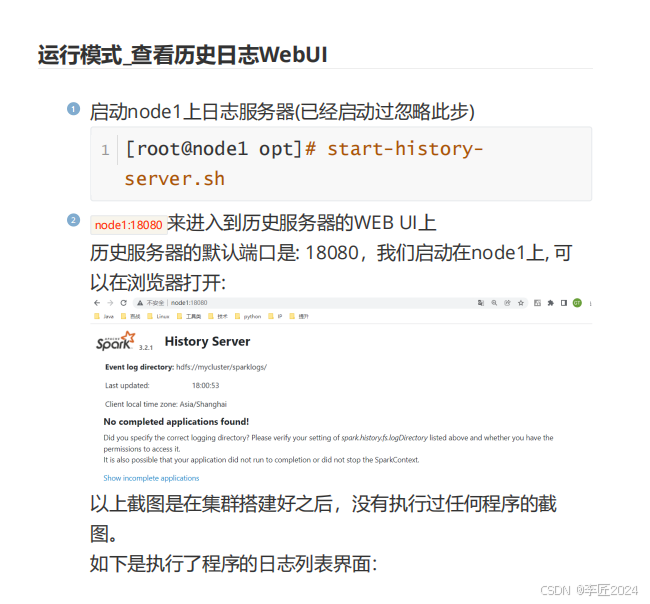
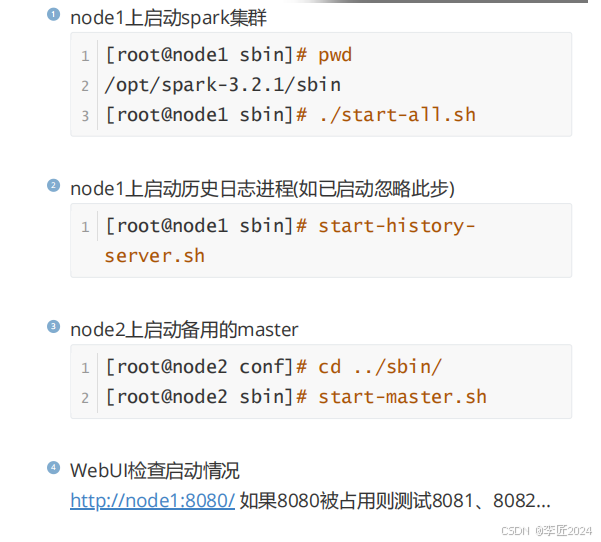
21.运行模式_standaloneHA安装

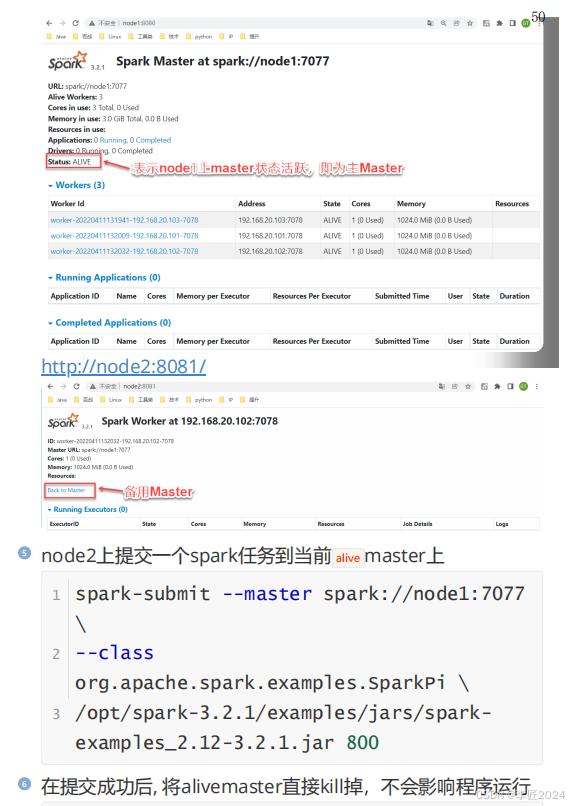
22.运行模式_standalone测试
23.运行模式_YARN模式概述