点击下面卡片,关注我呀,每天给你送来AI技术干货!
报道
来源:Google AI blog
编辑:LRS
来自:新智元
【导读】谷歌的搜索引擎需要很多标注数据吗?NO!半监督学习才是他的核心训练方式!卡内基梅隆华人博士提出的Noisy Student在ImageNet夺冠后又在谷歌搜索中大展身手,本文将带你揭秘知识蒸馏的正确打开方式。
监督学习是机器学习界最常用的一种方法,只需要根据已有的数据点和标注数据即可用来训练预测模型。
在工业界,由于监督学习的实现比较简单,所以通常是首选方案。
然而,监督式学习需要精确标记的数据,收集这些数据通常是劳动密集型的任务。
此外,随着更强大的计算机体系结构设计、算法和硬件(gpu/tpu)可以提高模型的训练效率,训练大型模型来实现更高的质量的模型也变得更容易,这反过来又需要更多标记数据来继续训练更大的模型。
为了减少对有标签数据的需求,一个重要的机器学习领域:半监督学习被提出来,它能够结合少量的有标签数据和大量的无标签的数据来预测,最近许多模型如UDA,SimCLR都已经证明了半监督学习的有效性。
受到之前模型的启发,Google 提出了一个全新的半监督蒸馏模型SSD(semi-supervised distillation),是2019年提出的Noisy Student模型的简化版本,这个模型在自然语言处理领域取得了巨大的成功。
目前SSD模型已经应用在了Google搜索中的上下文语言理解中,并且性能强劲。
这是半监督学习在大规模应用的首个成功案例,论文中还说明了这个模型对生产规模较大系统的潜在影响。
Noisy Student提出于2019年,是一个有效的半监督学习方法,即使在有标签数据很多的情况下,依然能够取得稳定的效果。
在Noisy Student之前,有大量关于半监督学习的研究。尽管进行了如此广泛的研究,但这样的半监督模型系统通常只能在低数据(low-data)环境下运行良好,例如,CIFAR、 SVHN 和10% 的 ImageNet。

Noisy Student的第一作者是谢其哲,是卡内基梅隆大学的博士生,本科毕业于上海交通大学,曾在Google Brain, 微软亚洲研究院实习。

随着标记数据的增加时,这些模型便无法与完全监督式学习系统竞争,这是影响半监督方法应用于生产中的重要应用,如搜索引擎和自动驾驶汽车领域急需一个可靠的半监督系统模型。
这一缺陷促使Google 开发了Noisy Student,这是一种在高数据量情况下依然能够运行良好的半监督学习方法,同时在 ImageNet 上使用130M 额外的未标记图像实现了最高的准确度。
它在ImageNet上达到88.4%的top-1准确率,相比ImageNet上需要35亿弱标注Instagram图像的sota模型来说,Noisy Student要好2.0%。
在鲁邦性测试集上,它将ImageNet-A-top-1的准确率从61.0%提高到83.7%,将ImageNet-C的平均错误率从45.7降低到28.3,并将ImageNet-P的平均翻转率从27.8降低到12.2。

Noisy Student的训练方式为使用相等或更大的学生模型,并在学习过程中向学生添加噪声,这扩展了自我训练和蒸馏的概念。

在ImageNet上,首先训练了一个有效的标记图像的网络模型,并用它作为teacher为300M的无标签图像生成伪标记。然后训练一个更大的EfficientNet作为学生模型上的组合标记和伪标记图像。
通过让student重新成为teacher来重复这个过程。在student的学习过程中,通过RandAugment向student注入dropout、随机深度、数据增强等噪声,使student的泛化能力强于teacher。
Noisy Student的训练有四个简单的步骤:
1、训练一个分类器(teacher)处理有标签的数据
2、teacher在一个更大的未标记数据集上推导出伪标签
3、训练一个更大的分类器对组合标记和伪标记数据,同时也增加噪声(成为Noisy Student)
4、(可选)回到第二步,student可以被当作一个新teacher重新标注数据并训练
因为Noisy Student模型可以生成伪标签,所以可以将它看作是一种自我训练的形式,通过重新训练自己以提高性能。
Noisy Student训练后的模型有一个令人惊讶的特性是,训练好的模型在鲁棒性(robustness)测试集上运行得非常好,这些测试集没有对它进行优化,包括 ImageNet-A、 ImageNet-C 和 ImageNet-P。在训练过程中加入的噪声不仅有助于学习,而且使模型更加健壮。

Noisy Student与知识蒸馏(knowledge distillation)类似,知识蒸馏一个将知识从大型模型(即teacher)转移到小型模型(即student)的过程。
蒸馏的目标是建立一个小模型提高预测速度,能够在生产环境中,以不牺牲太多准确率的情况下提升效率。
最简单的蒸馏装置包括一个teacher和使用相同的数据,但在实际使用中,可以使用多个teacher或为student预留一个单独的数据集。

与Noisy Student不同的是,知识蒸馏不会在训练过程中增加噪声(例如,数据增强或模型正则化) ,通常只包含一个较小的sutdent模型。相比之下,可以把Noisy Student看作是知识蒸馏的扩展过程。
训练半监督蒸馏生产模型的另一个策略是应用Noisy Student训练两次: 首先得到一个较大的teacher模型 t’,然后得到一个较小的student s。这种方法产生的模型比单独使用监督式学习或Noisy Student训练都要好。
具体来说,当应用于一系列 EfficientNet 模型的视觉领域时,从有5.3 m 参数的 EfficientNet-b0到有66M 参数的 EfficientNet-b7,这种策略对于每个给定的模型大小都能获得更好的性能。

Noisy Student的训练需要数据增强,例如 RandAugment (用于视觉)或 SpecAugment (用于语音) ,以便更好地工作。
但在某些确定的应用中,例如自然语言处理,这种类型的输入噪声是不容易获得的。对于这些的应用场景,Noisy Student的训练可以简化为无噪音。
在这种情况下,上述两阶段过程合并为一个更简单的方法,则称之为半监督蒸馏(SSD)。首先,teacher模型在未标记的数据集上推导出伪标签,然后训练一个新的teacher模型(t’) ,其大小与原来的teacher模型相同或更大。这一步本质上是自我训练,然后通过知识提炼,生成一个用于生产的较小的student模型。
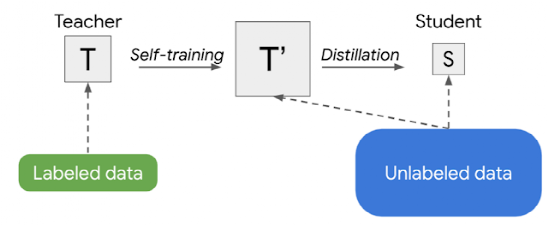
半监督学习在视觉领域取得成功之后,很自然地就把这种技术引入到语言理解领域的应用中,例如谷歌搜索,将成为下一步具有更广泛用户影响力的合乎逻辑的举措。
在这种情况下,使用SSD在搜索引擎中的关键排序组件上。模型基于BERT ,以便更好地理解语言。
这项任务被证明非常适合于 SSD,事实上,将 SSD 应用到排名组件中,以更好地理解候选搜索结果与查询的相关性,也是在2020年搜索引擎的顶级启动中取得了最高的性能收益之一。
下面是一个查询示例,其中改进的模型展示了SSD能帮助模型金星更好的语言理解。

SSD 将继续改变机器学习在工业中的应用,从主流的监督式学习学习到半监督学习学习。
参考资料:
https://ai.googleblog.com/2021/07/from-vision-to-language-semi-supervised.html
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!