CodeFormer
论文
Towards Robust Blind Face Restoration with Codebook Lookup Transformer
模型结构
如图所示,该方法分为(a)、(b)两个阶段,每个阶段的模型有所不同。其中(a)阶段包含,𝐼ℎ(高质量图像),𝐸ℎ(高质量图像编码器),𝑍ℎ(编码后得到的特征),𝐶(编码本,存储量化的特征),𝑆(最近邻匹配后得到的索引),𝑍𝑐(𝑍ℎ量化后的特征),𝐷𝐻(解码器,从特征重构原始高质量图像),𝐼𝑟𝑒𝑐(重构得到的高质量图像);(b)阶段包含,𝐼𝑙(待修复的低质量图像),𝐸𝐿(低质量图像编码器,在𝐷𝐻基础上微调),𝑍𝑙(编码后得到的特征),𝑇(Transform模块,对全局特征建模并预测每个特征对应的索引),𝐶(固定的预训练编码本),𝑍^𝑐(量化后的特征),𝐷𝐻(固定的预训练解码器),𝐿𝑟𝑒𝑠(重构得到的高质量图像),此外,𝐹𝑒(低质量图像特征),𝐶𝐹𝑇(可控特征变换),𝐹𝑑(解码特征)。
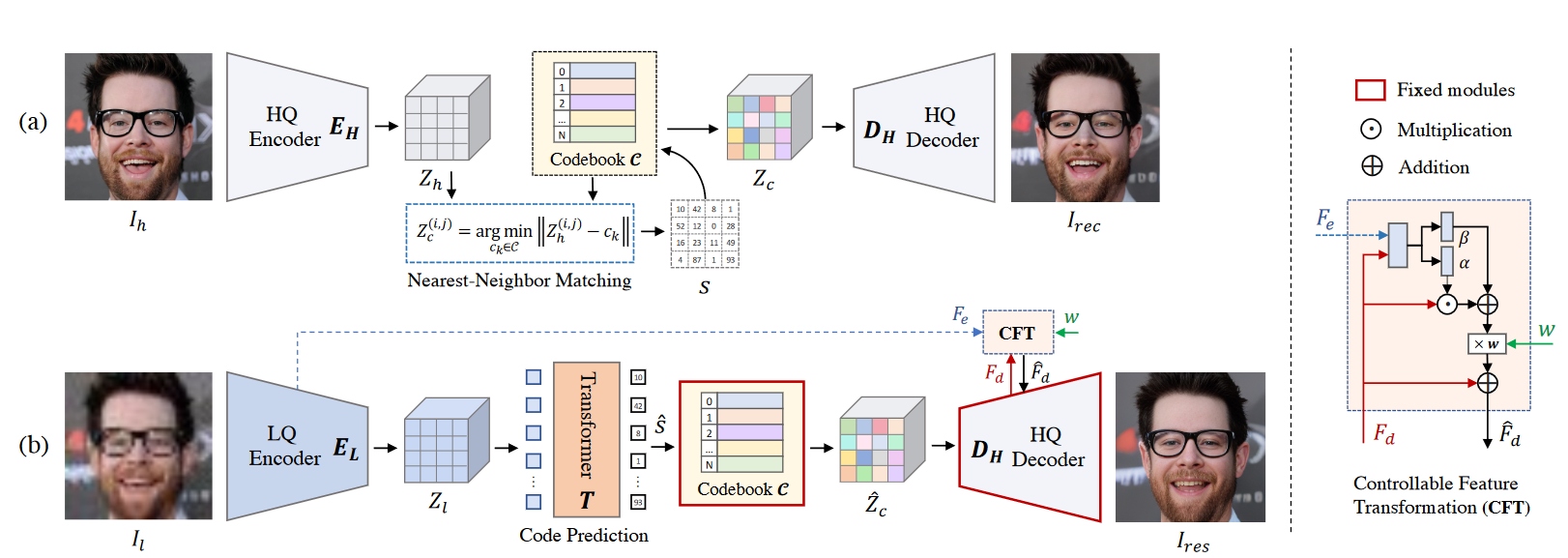
算法原理
该算法结合了编码本(codebook)以及Transformer的思想,可以将低质量的人脸图像恢复为高质量的人脸图像,具体如下,
1.编码本
将海量的先验知识以离散化的方式存储。
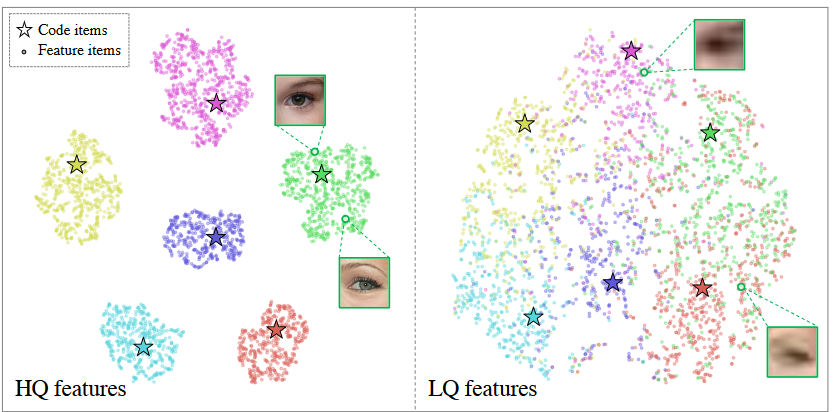
2.Transfomer
低质量图像特征在存在多样化退化的情况下,可能会偏离正确的索引,并被归为附近的聚类,导致不理想的恢复结果。使用Transformer模块对全局关系建模可以消除该问题。
环境配置
Docker
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04.1-py39-latest
docker run --shm-size 10g --network=host --name=codeformer --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -it <your IMAGE ID> bash
pip install -r requirements.txt
pip install cython
python basicsr/setup.py develop
# 以下内容可选,仅在视频增强时需要
yum install epel-release -y
yum localinstall --nogpgcheck https://download1.rpmfusion.org/free/el/rpmfusion-free-release-7.noarch.rpm -y
yum install ffmpeg ffmpeg-devel -y
Dockerfile
# 需要在对应的目录下
docker build -t <IMAGE_NAME>:<TAG> .
# <your IMAGE ID>用以上拉取的docker的镜像ID替换
docker run -it --shm-size 10g --network=host --name=codeformer --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined <your IMAGE ID> bash
pip install -r requirements.txt
pip install cython
python basicsr/setup.py develop
# 以下内容可选,仅在视频增强时需要
yum install epel-release -y
yum localinstall --nogpgcheck https://download1.rpmfusion.org/free/el/rpmfusion-free-release-7.noarch.rpm -y
yum install ffmpeg ffmpeg-devel -y
数据集
链接: GitHub - NVlabs/ffhq-dataset: Flickr-Faces-HQ Dataset (FFHQ)
注意:原始数据为1024x1024需要处理为512x512,可运行data_process.py对数据进行处理。
python data_process.py --zip_dir <path/to/zipdir> --output_dir <dataset/ffhq_512>
本项目也提供了mini数据集(链接:百度网盘 请输入提取码 提取码:kwai),可用于验证程序是否可以正常运行。
dataset
|—— ffhq_512
├── 00522.png
├── 01459.png
├── 02090.png
├── xxx.png
训练
阶段一 - 训练VQGAN
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/VQGAN_512_ds32_nearest_stage1.yml --launcher pytorch
获取训练数据的码本序列,可以加速后续训练
python scripts/generate_latent_gt.py
阶段二 - 训练Transformer (w = 0)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4322 basicsr/train.py -opt options/CodeFormer_stage2.yml --launcher pytorch
阶段三 - 训练可控特征Transformer (w = 1)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4323 basicsr/train.py -opt options/CodeFormer_stage3.yml --launcher pytorch
注意:vqgan为net_g_xxx.pth,net_d为第一阶段生成。
推理
模型下载
Github:Release CodeFormer V0.1.0 Release · sczhou/CodeFormer · GitHub
weights
├── CodeFormer
│ ├── codeformer_colorization.pth
│ ├── codeformer_inpainting.pth
│ └── codeformer.pth
├── dlib
│ ├── mmod_human_face_detector-4cb19393.dat
│ ├── shape_predictor_5_face_landmarks-c4b1e980.dat
│ └── shape_predictor_68_face_landmarks-fbdc2cb8.dat
├── facelib
│ ├── detection_Resnet50_Final.pth
│ └── parsing_parsenet.pth
├── README.md
└── realesrgan
└── RealESRGAN_x2plus.pth
也可以使用脚本下载模型
python scripts/download_pretrained_models.py facelib
python scripts/download_pretrained_models.py dlib (only for dlib face detector)
python scripts/download_pretrained_models.py CodeFormer
脸部修复
# 获取图像中人脸部分
python scripts/crop_align_face.py -i [input folder] -o [output folder]
# 对人脸部分进行修复
python inference_codeformer.py -w 0.5 --has_aligned --input_path [image folder]|[image path]
注意:参数-w为保真度权重,取值范围为0-1,通常,较小的w倾向于产生更高质量的结果,而较大的w则产生更高保真度的结果。
整图增强
# For whole image
# Add '--bg_upsampler realesrgan' to enhance the background regions with Real-ESRGAN
# Add '--face_upsample' to further upsample restorated face with Real-ESRGAN
python inference_codeformer.py -w 0.7 --input_path [image folder]|[image path]
视频增强
# For video clips
# Video path should end with '.mp4'|'.mov'|'.avi'
python inference_codeformer.py --bg_upsampler realesrgan --face_upsample -w 1.0 --input_path [video path]
脸部着色
# For cropped and aligned faces (512x512)
# Colorize black and white or faded photo
python inference_colorization.py --input_path [image folder]|[image path]
脸部修复(脸部遮挡修复)
# For cropped and aligned faces (512x512)
# Inputs could be masked by white brush using an image editing app (e.g., Photoshop)
# (check out the examples in inputs/masked_faces)
python inference_inpainting.py --input_path [image folder]|[image path]
result

精度
| LPIPS | PSNR | SSIM | FID | |
|---|---|---|---|---|
| DCU | 0.306 | 8.639 | 0.636 | 123.14 |
| GPU | 0.312 | 8.694 | 0.635 | 124.7 |
注意:该数据仅用于对比DCU与GPU之间的指标差异。
应用场景
算法类别
图像超分
热点应用行业
媒体,科研,教育
源码仓库及问题反馈
参考资料