目录
1.1 什么是MPI(Message Passing Interface)消息传递接口
一、MPI基本概念
1.1 什么是MPI(Message Passing Interface)消息传递接口
-- 是一种消息传递编程模型,最终服务于进程间的通信
-- 是函数库规范,而不是并行语言;操作如同库函数调用。
-- 是一种编程接口标准和规范,不特指某一个对它的具体实现。
1.2 MPI的发展历程
| 版本 | 说明 |
| MPI 1.0 | 1992-1994年MPI1.1版本问世 |
| MPI 2.0 | 扩充并行I/O、远程访问存储、动态进程管理等 |
| MPI 3.0 | 新增了非阻塞集合通信、新的单边通信模式、辅助性能调试工具集以及对Fortran2008支持 |
| MPI 4.0 | 2021.6月 |
| MPI 4.1-5.0 | https://www.mpi-forum.org/ |
1.3 MPI的标准实现
| MPICH | MVAPICH | OpenMPI | Intel MPI | HPC-X | |
| 开发者 | Argonne National Lab | Ohio State University | OpenMPI development Team | Intel | Mellanox |
| 是否开源 | 是 | 是 | 是 | 是 | 是 |
| 支持的网络 | 以太网 | InfiniBand 以太网 | InfiniBand 以太网 | InfiniBand 以太网 | InfiniBand 以太网 |
| MPI标准 | 2.2 3.0 | 2.2 | 2.2 | 3.1 | 3.0 |
| 前身 | MPICH | MVAPICH | LAM-MPI | / | / |
1.4 进程与消息传递
进程:进程与程序相联,程序一旦在操作系统中运行即成为进程。
消息传递:消息数据从一个处理器的内存拷贝到另一个处理器内存的方法。

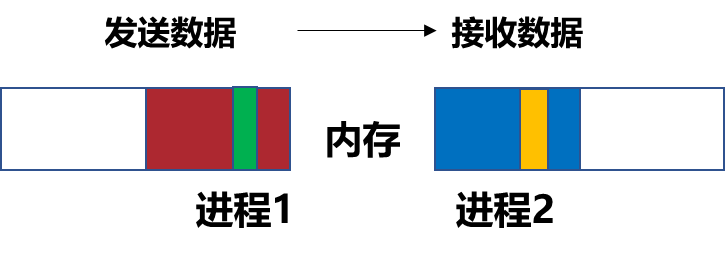
•缓冲区(buffer) 在用户应用程序中定义的用于保存发送和接收数据的地址空间。
二、MPI程序的基本结构
2.1 MPI程序的编译与运行
#include "mpi.h"
#include <stdio.h>
#include <math.h>
void main(argc,argv)
int argc;
char *argv[];
{
int myid, numprocs;
int namelen;
char processor_name[MPI_MAX_PROCESSOR_NAME];
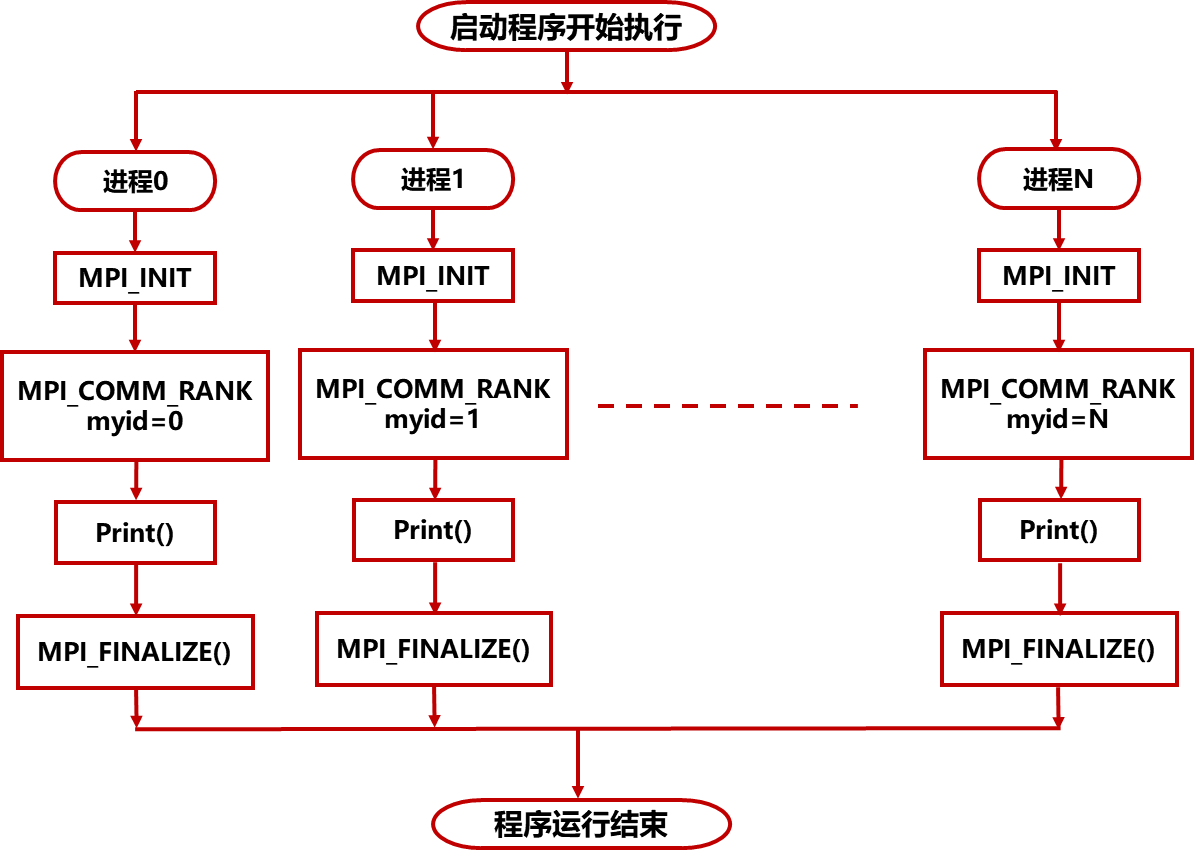
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Get_processor_name(processor_name,&namelen);
fprintf(stderr,"Hello World! Process %d of %d on %s\n",
myid, numprocs, processor_name);
MPI_Finalize();
} 程序编译
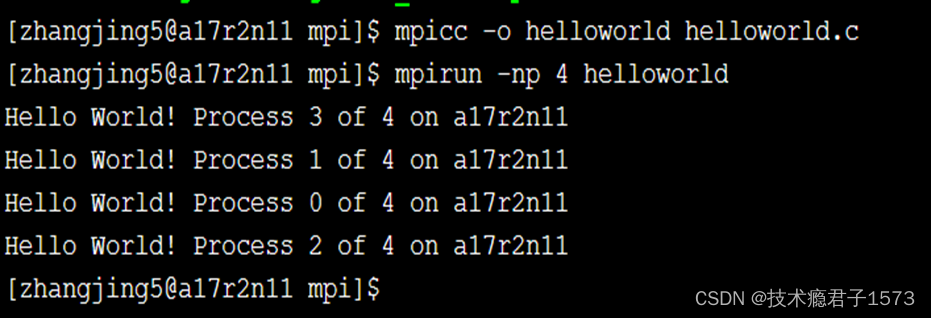
C: mpicc -o helloworld helloworld.c
Fortran :mpif90 -o helloworld helloworld.f
程序运行
mpirun -np 进程数 helloworld
运行结果
2.2 MPI的基本结构

#include "mpi.h"
#include <stdio.h>
#include <math.h>
void main(argc,argv)
int argc;
char *argv[];
{
int myid, numprocs;
int namelen;
char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc,&argv);
//得到当前正在运行的进程的标识号,放在myid
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
//得到所有参加运算的进程个数,放在numprocs中
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
//得到本进程运行的机器的名称。放在processor_name字符串中,长度放在namelen中
MPI_Get_processor_name(processor_name,&namelen);
fprintf(stderr,"Hello World! Process %d of %d on %s\n",
myid, numprocs, processor_name);
MPI_Finalize();
}三、MPI程序的函数
3.1 C和Fortran中MPI函数的约定
C
必须包含mpi.h: #include ”mpi.h”
Error = MPI_Xxxxx(parameter,…);
MPI_Xxxx(parameter,…)
MPI 函数返回出错代码或 MPI_SUCCESS成功标志
MPI_前缀,且只有MPI以及MPI_标志后的第一个字母大写,其余小写
Fortran
必须包含mpif.h :“include mpif.h” or “use mpi” or “use mpi_f08”
CALL MPI_XXXXX(parameter,…,IERROR)
通过子函数形式调用MPI,函数最后一个参数为返回值
3.2 启动、结束MPI环境
C MPI_Init(int *argc,char ***argv)
Fortran MPI_INIT(IERROR)
INTEGER IERROR完成MPI程序初始化,通过获取main函数的参数(argc,argv),让每个MPI进程都能获取到main函数。
C MPI_Finalize(void)
Fortran MPI_FINALIZE(IERROR)
INTEGER IERROR
MPI程序最后一个调用,清除全部MPI环境。
3.3 基本的MPI通信域函数
C MPI_Comm_rank(MPI_Comm comm,int *rank)
Fortran MPI_COMM_RANK(COMM,RANK,IERROR)
INTEGER COMM, RANK, IERROR
用于获取调用进程在给定的通信域comm/COMM中的进程序号,保存于rank/RANK中
C MPI_Comm_size(MPI_Comm comm,int *size)
Fortran MPI_COMM_SIZE(COMM,SIZE,IERROR)
INTEGER COMM, SIZE, IERROR
用于获取调用进程在给定的通信域comm/COMM中的进程数目,保存于size/SIZE中
3.4 消息发送与接受函数
C int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag,
MPI_Comm comm)
Fortran MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
将发送缓冲区中的count个datatype数据类型的数据发送到目的进程
C int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm)
Fortran MPI_RECV(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
从指定的进程source接收消息,发送进程的消息与接收进程指定的datatype和tag相一致。
3.5 send与recv函数示例
MPI_Recv(message, 20, MPI_CHAR, 0, 99, MPI_COMM_WORLD, &status);//接收缓冲区,数据最大长度,数据类型,源进程号,进程标识,通信域,状态信息
printf("received :%s\n", message); * 接收完成后 它直接将接收到的字符串打印在屏幕上 */
}
MPI_Finalize();
return 0;
/*MPI程序结束*/
}#include <stdio.h>
#include "mpi.h"
int main( int argc, char* argv[] )
{
char message[100];
int myrank;
MPI_Status status;
MPI_Init( &argc, &argv );
/* MPI程序的初始化*/
MPI_Comm_rank( MPI_COMM_WORLD, &myrank );
/* 得到当前进程的标识*/
if (myrank == 0) /* 若是 0 进程*/
{
strcpy(message,"Hello, process 1");//字符串拷贝到发送缓冲区message中
MPI_Send(message, strlen(message), MPI_CHAR, 1, 99,MPI_COMM_WORLD);
}//数据地址,消息长度,数据类型,目的进程号,进程标识,通信域
if(myrank==1) /* 若是进程 1 */
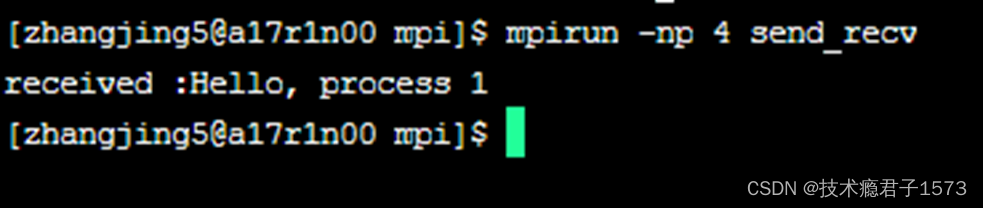
3.6 MPI消息
Message=Message Buffer(消息缓冲)+Message Envelop(消息信封)
消息缓冲由三元组<起始地址,数据个数,数据类型>标识
消息信封由三元组<源/目标进程,消息标签,通信域>标识
MPI_Send(buf, count, datatype, dest , tag, comm)


3.7 MPI原生数据类型

四、MPI程序的通讯

4.1 点对点通讯
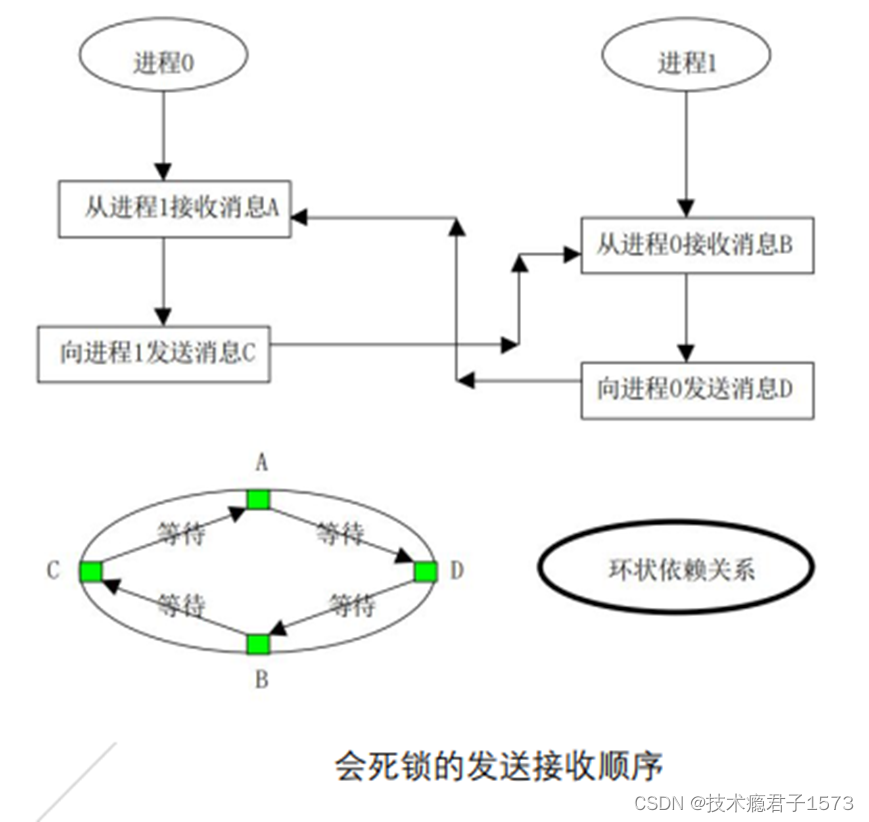
MPI 的点对点通信 (Point-to-Point Communication) 同时提供了阻塞和非阻塞两种 通信机制 同时支持多种 通信模式 (缓冲管理,以及发送方和接收方之间的同步方式)不同通信模式和不同通信机制的结合,便产生丰富的点对点通信函数
四种通讯模式
| 通信模式 | 发送 | 接收 |
| 标准(standard)通信模式 | MPI_SEND | MPI_RECV |
| 缓存(buffered)通信模式 | MPI_BSEND | |
| 同步(synchronous)通信模式 | MPI_SSEND | |
| 就绪(ready)通信模式 | MPI_RSEND |
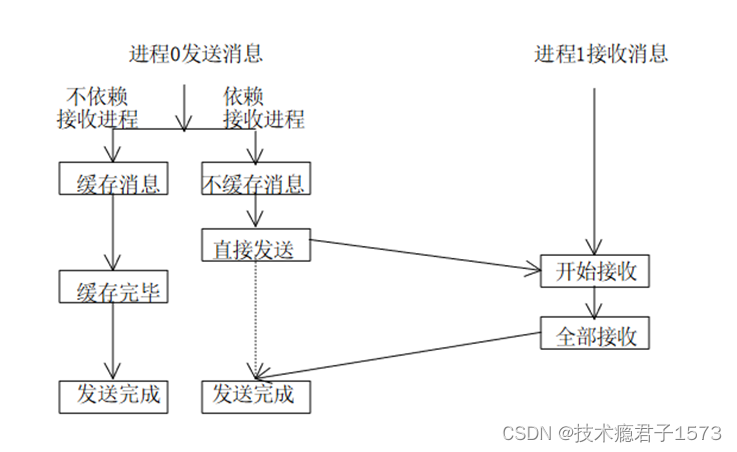
- 标准通信模式:是否对发送的数据进行缓冲由MPI的实现来决定,而不是由用户程序来控制
- 发送可以是同步的或缓冲的,取决于实现
MPI_COMM_RANK(comm.rank)
if(rank==0)
MPI_Recv((sendbuf,count,datatype,1,tag,comm)
MPI_Send(recvdbuf,count,datatype,1,tag,comm)
if(rank==1)
MPI_Recv(sendbuf,count,datatype,0,tag,comm)
MPI_Send(recvdbuf,count,datatype,0,tag,comm)
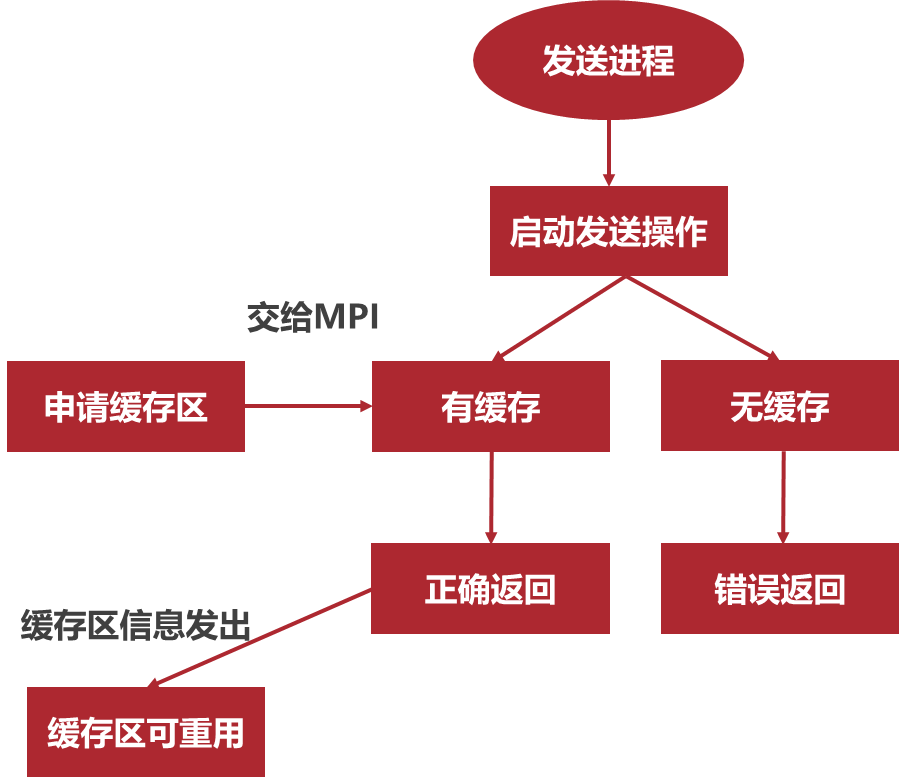
- 缓存通信模式:缓冲通信模式的发送不管接收操作是否已经启动都可以执行
- 程序通过MPI_Buffer_attch申请缓冲区,MPI_Buffer_detach回收申请的缓冲区
MPI_BUFFER_ATTACH(buffer,size)
IN buffer 初始缓存地址(可选数据类型)
IN size 按字节计数的缓存跨度(整型)
MPI_
if(rank==0)
MPI_BSend(sendbuf,count,datatype,1,tag,comm)
MPI_Recv(recvdbuf,count,datatype,1,tag,comm)
if(rank==1)
MPI_BSend(sendbuf,count,datatype,0,tag,comm)
MPI_Recv(recvdbuf,count,datatype,0,tag,comm)
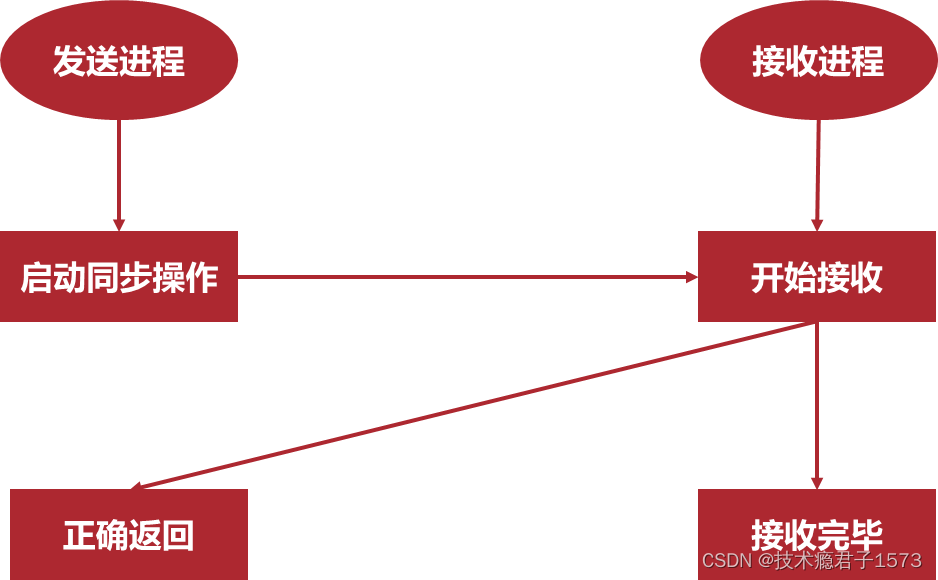
- 同步通信模式:只有相应的接收过程已经启动,发送过程才能正确返回。
- 同步发送返回后,表示发送缓冲区中的数据已经全部被系统缓冲区缓存,并且已经开始发送。同步发送返回后,发送缓冲区可以被释放或者重新使用。
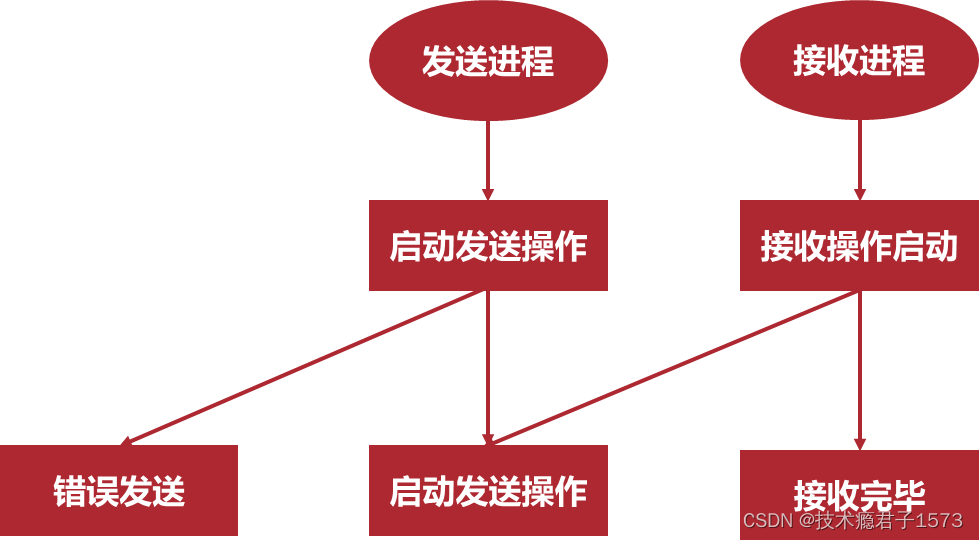
- 就绪通信模式:发送操作只有在接收进程相应的接收操作已经开始才进行发送。
- 发送操作启动而相应的接收还没有启动,发送操作将出错。接收操作必须先于发送操作启动。
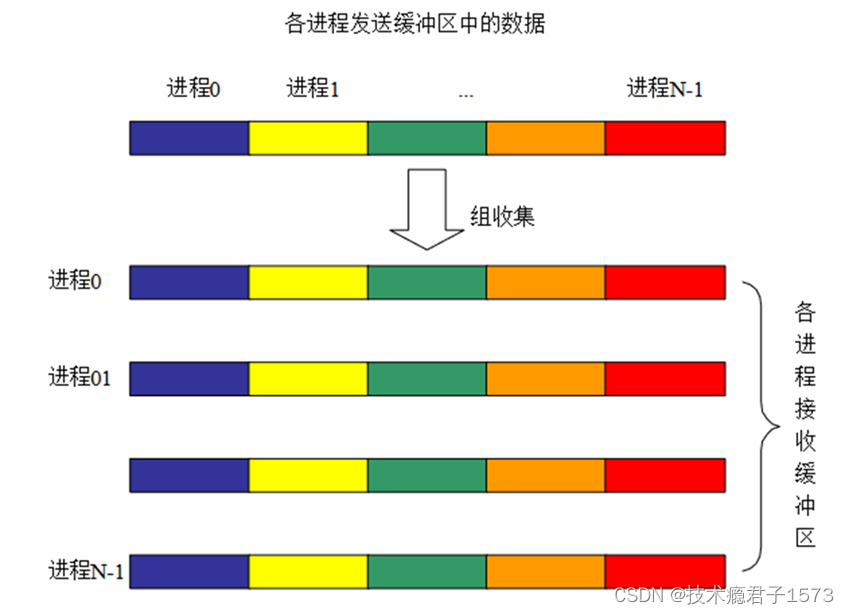
 4.2 集合通讯
4.2 集合通讯
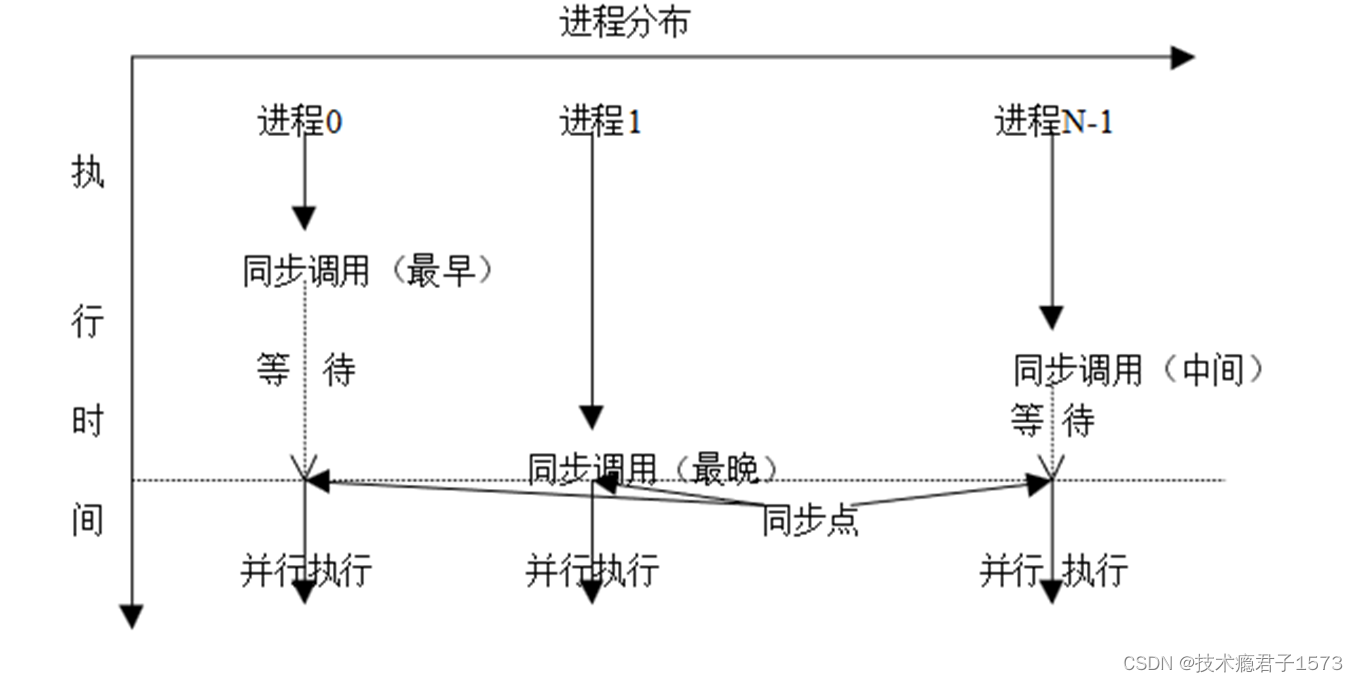
- 集合通信(Collective Communications)是一个进程组中的所有进程都参加的全局通信操作。
- 集合通信一般实现三个功能:通信、同步和计算。
- 通信功能主要完成组内数据的传输
- 同步功能实现组内所有进程在执行进度上取得一致
- 计算功能在通信的基础上对给定的数据完成一定的操作
- 对于集合通信,按通信的方向的不同,又分为三种:
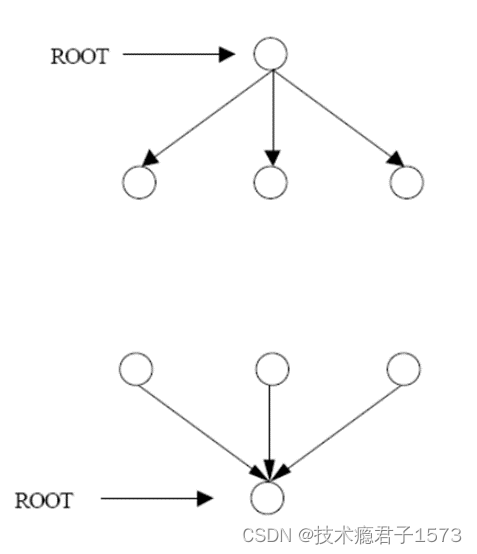
- 一对多通信:一个进程向其它所有的进程发送消息,这个负责发送消息的进程叫做ROOT进程
- 多对一通信:一个进程负责从其它所有的进程接收消息,这个接收的进程也叫做ROOT进程
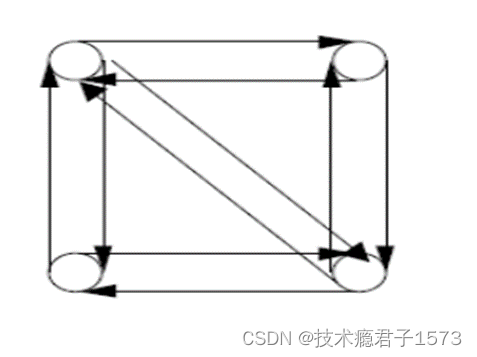
- 多对多通信:每一个进程都向其它所有的进程发送或者接收消息
同步是许多应用中必须提供的功能,组通信的还提供专门的调用以完成各个进程之间的同步,从而协调各个进程的进度和步伐。
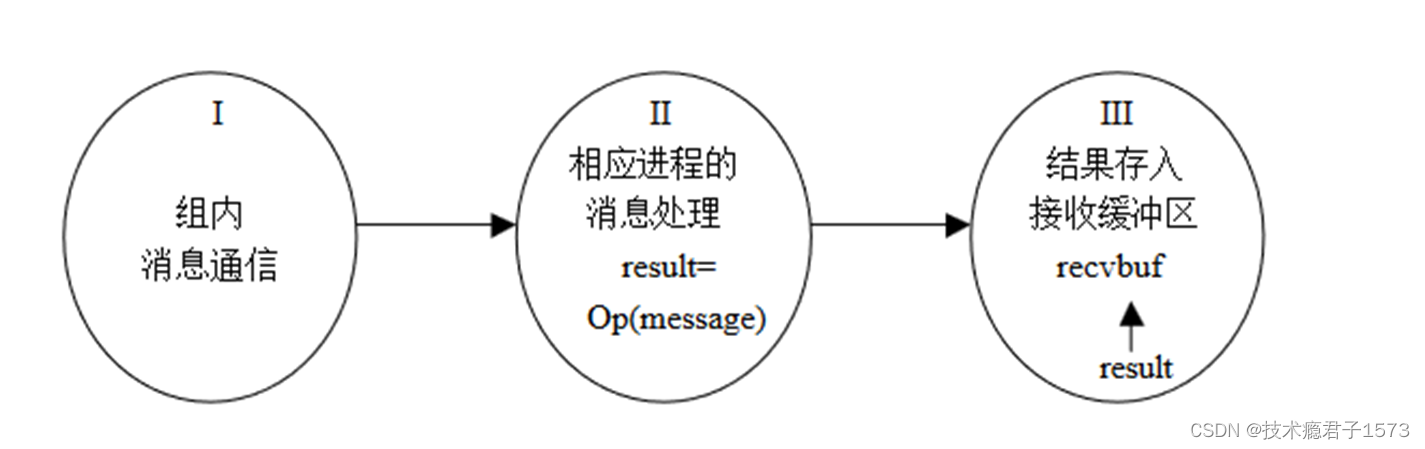
从效果上看是分三步实现:
1、通信的功能,即消息要求发送到目的进程,目的进程也已经接收到各自所需要的信息。完成组内消息通信
2、消息的处理,即计算部分,MPI组通信有计算功能的调用都指定了计算操作,用给定的计算操作对接收到的数据进行处理
3、最后一步是将处理结果放入指定的接收缓冲区
广播是一对多通信的典型例子。其调用格式如下:
int MPI_Bcast (
void *buffer, /*发送/接收buf*/
int count, /*元素个数*/
MPI_Datatype datatype,
int root, /*指定根进程*/
MPI_Comm comm)
根进程既是发送缓冲区也是接收缓冲区
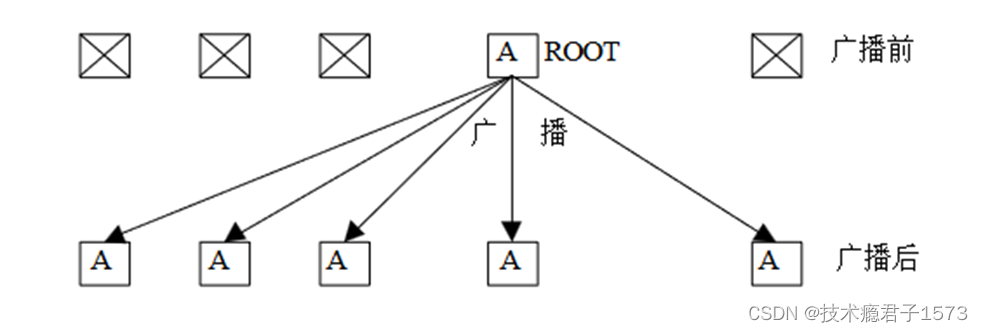
将根进程通信消息缓冲区消息拷贝到其他所有进程中去
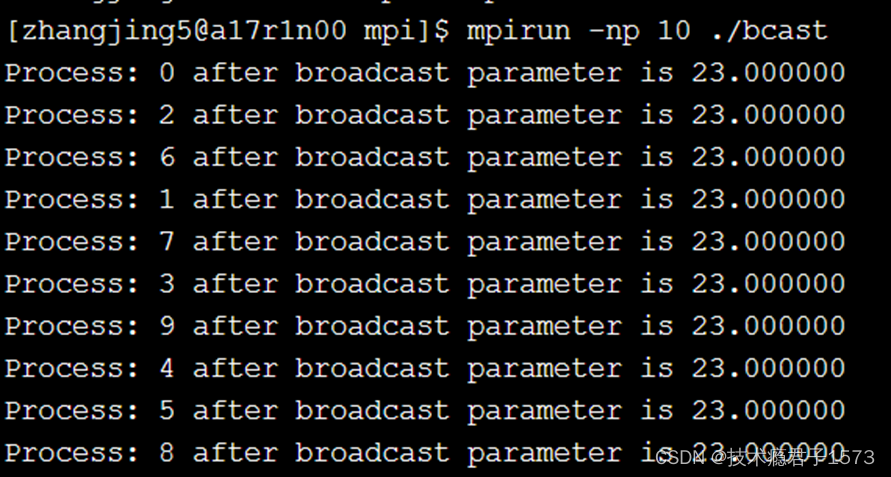
Bcast示例 将进程0的数据广播到其他所有进程
#include<stdio.h>
#include"mpi.h"
int main(argc, argv)
int argc;
char **argv;
{
int rank;
double param;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank==0)param=23.0;
MPI_Bcast(¶m,1,MPI_DOUBLE,0, MPI_COMM_WORLD); 进程0为根进程
printf("Process: %d after broadcast parameter is %f\n",rank,param);
MPI_Finalize( );
return 0;
}
收集是多对一通信的典型例子。其调用格式如下:
int MPI_Gather(void* sendbuf, int sendcount,MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
sendcount,sendtype和recvcount,recvtype都相同
int MPI_Gatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf,int *recvcounts, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm)

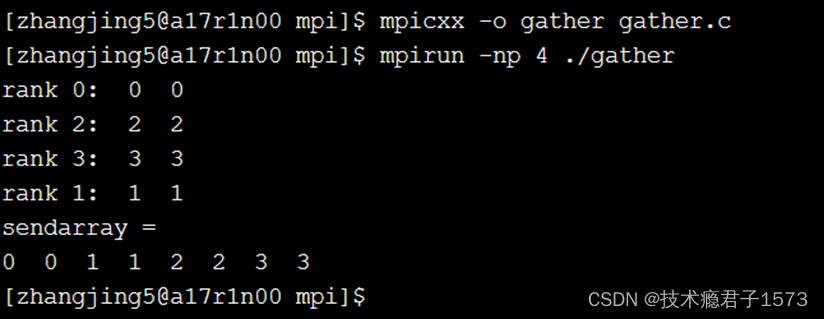
Gather示例
#include<iostream>
#include"mpi.h"
using namespace std;
int main(int argc, char **argv)
{
MPI_Init(&argc, &argv);
int myrank, gsize;
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &gsize);
int sendarray[2];
sendarray[0] = sendarray[1] = myrank;
cout << "rank " << myrank << ": " ;
cout << sendarray[0] << " " << sendarray[1] << endl;
int root = 0;
int *rbuf;
if(myrank == root) rbuf = new int[gsize*2];
MPI_Gather(sendarray, 2, MPI_INT, rbuf, 2, MPI_INT, root, MPI_COMM_WORLD);
if(myrank == root)
{
cout << "sendarray = " << endl;
for(int i=0; i < gsize; i++)
cout << rbuf[i*2] << " " << rbuf[i*2 +1] << " ";
cout << endl;
delete [] rbuf;
}
MPI_Finalize();
return 0;
}
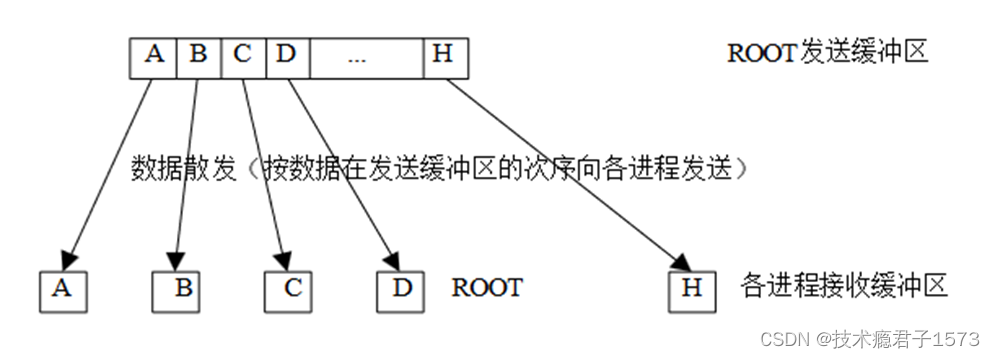
散发是一对多操作。两者互为逆操作其调用格式如下:
int MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype,
int root, MPI_Comm comm)ROOT向各个进程发送的数据可以是不同的 MPI_SCATTER和MPI_GATHER的效果正好相反
int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root,MPI_Comm comm)
#include<iostream>
#include"mpi.h"
using namespace std;
int main(int argc, char **argv)
{
int myrank, gsize, *sendbuf;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &gsize);
int rbuf[2];
rbuf[0] = rbuf[1] = myrank;
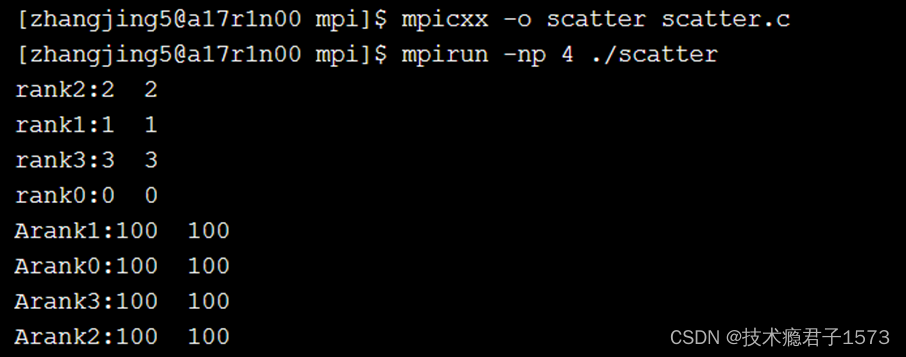
cout<<"rank"<<myrank<<":"<<rbuf[0]<<" "<<rbuf[1]<<endl;
int root = 0;
if(myrank ==root)
{
sendbuf = new int[gsize*2];
for(int i=0; i<gsize*2; i++) sendbuf[i] = 100;
}
MPI_Scatter(sendbuf, 2, MPI_INT, rbuf, 2, MPI_INT, root, MPI_COMM_WORLD);
cout << "Arank" << myrank << ":" << rbuf[0] << " " << rbuf[1] << endl;
if(myrank == root) delete [] sendbuf;
MPI_Finalize();
return 0;
}
int MPI_Allgather(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype,
MPI_Comm comm)
全互换是多对多操作。其调用格式如下:
int MPI_Alltoall(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype,
MPI_Comm comm)
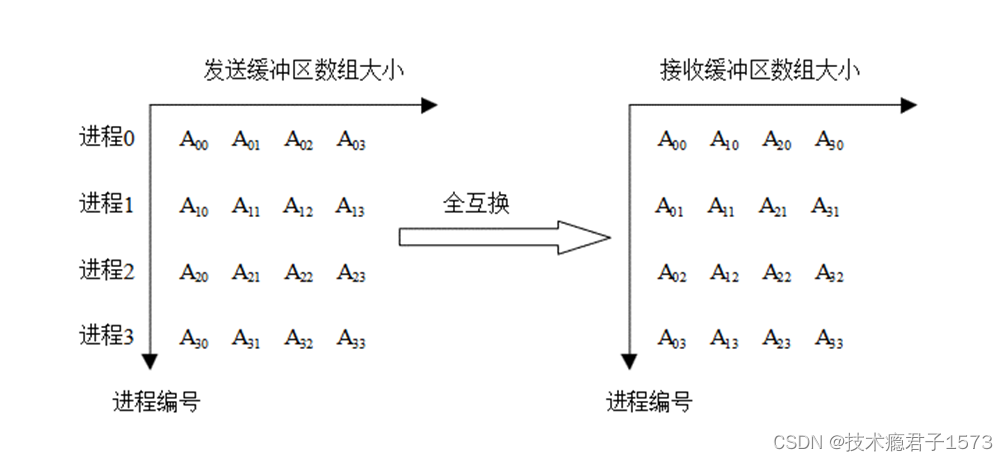
MPI_ALLTOALL 散发给不同进程的消息是不同的 因此它的发送缓冲区也是一个数组MPI_ALLTOALL 的每个进程可以向每个接收者发送数目不同的数据 第 i 个进程发送的第 j 块数据将被第 j 个进程接收并存放在其接收消息缓冲区 recvbuf 的第 i 块
归约(MPI_REDUCE)将组内每个进程输入缓冲区中的数据按给定的操作op进行运算,并将其结果返回到序列号为root的进程的输出缓冲区中。其调用格式如下:
int MPI_Reduce(void* sendbuf, void* recvbuf, int count, PI_Datatype datatype,MPI_Op op, int root, MPI_Comm comm)
所有进程都提供长度相同、元素类型相同的输入和输出缓冲区。每个进程可能提供一个元素或一系列元素,组合操作依次针对每个元素进行。
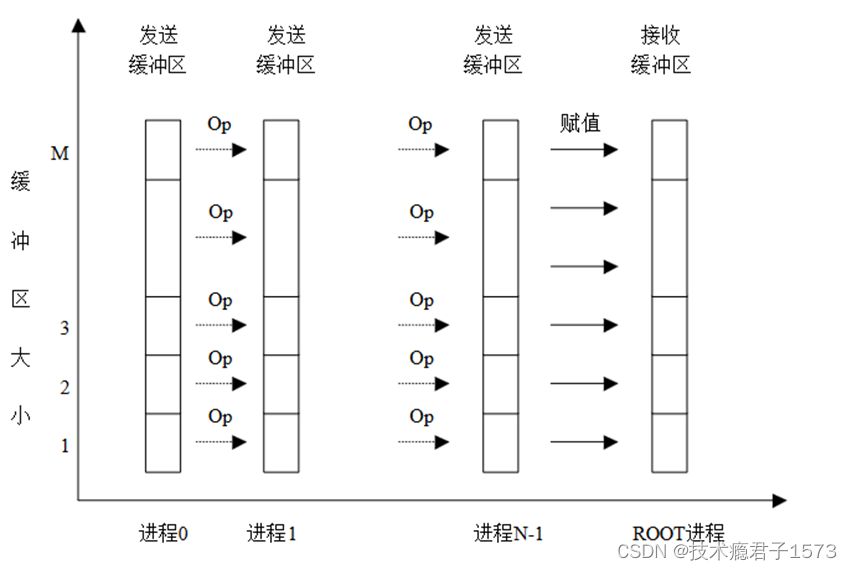
规约操作运算符
| 操作符 | 含义 |
| MPI_MAX | 最大 |
| MPI_MIN | 最小 |
| MPI_SUM | 求和 |
| MPI_PROD | 乘积 |
| MPI_LAND | 逻辑与 |
| MPI_BAND | 按位与 |
| 操作符 | 含义 |
| MPI_LOR | 逻辑或 |
| MPI_BOR | 按位或 |
| MPI_LXOR | 逻辑异或 |
| MPI_BXOR | 按位异或 |
| MPI_MAXLOC | max value and location |
| MPI_MINLOC | min value and location |
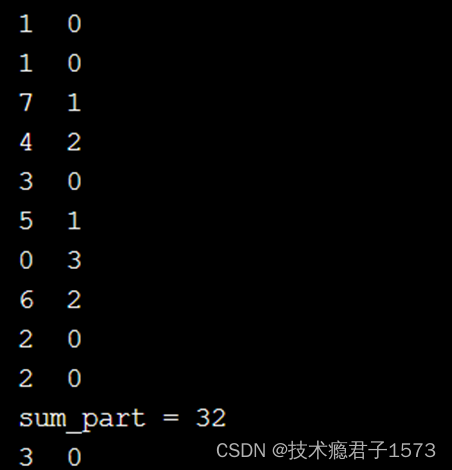
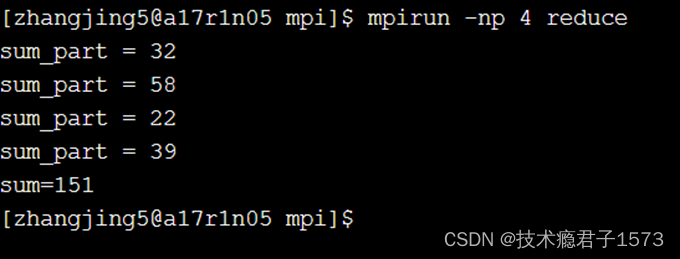
REDUCE示例
#include<iostream>
#include <ctime>
#include <cstdlib>
#include"mpi.h"
using namespace std;
int main(int argc, char **argv)
{
int myrank, gsize, *sendbuf;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &gsize);
int a[10], b[10];
double sum_part, sum;
srand(unsigned(time(0)+myrank));
sum_part = 0.0;
for(int i=0; i<10; i++)
{
a[i] = (random()%10); // 随机产生0到9的随机数
b[i] = (random()%4);
cout << a[i] << b[i] << endl;
sum_part += a[i]*b[i];
}
cout << "sum_part = " << sum_part << endl;
int root =0;
MPI_Reduce(&sum_part, &sum, 1, MPI_DOUBLE, MPI_SUM, root, MPI_COMM_WORLD);
if(myrank==root) cout<<"sum="<<sum<<endl;
MPI_Finalize();
return 0;
}两个长度为N的向量a[i]、b[i] 作内积:
S=a[0]*b[0] + a[1]*b[1] + … + a[N-1]*b[N-1]
向量a[:]和b[:]分布在多个进程上
五、MPI编程示例
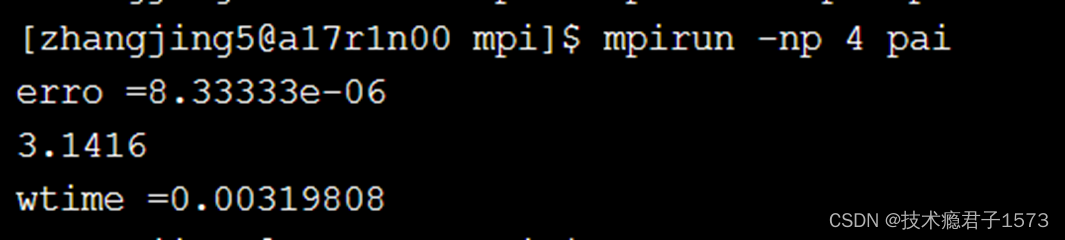
求Π
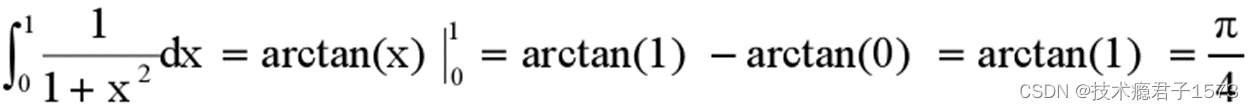
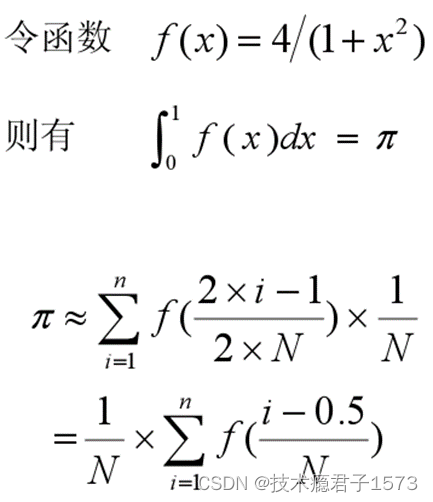
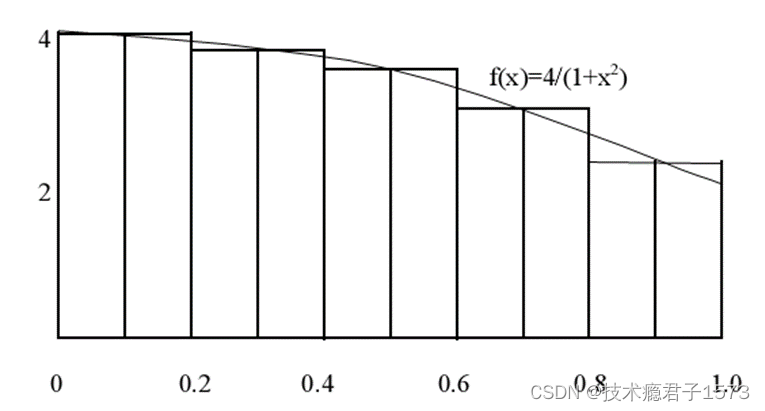
代码示例
#include<iostream>
#include "mpi.h"
using namespace std;
double f( double a){
return (4.0 / (1.0 + a*a));
}/定义函数
int main(int argc, char *argv[])
{
int n, myrank, nprocs;
double PI25DT = 3.141592653589793238;
double mypi, pi, h, sum, x;
double startwtime=0.0, endwtime;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
n = 100;//划分100个矩形
if(0 == myrank) startwtime = MPI_Wtime();
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);//将n值广播出去
h = 1.0 / (double)n; //得到矩形宽度
sum = 0.0;//矩形高赋初值
for(int i = myrank + 1; i <= n; i += nprocs)//每个进程计算一部分矩形面积,若进程为4,将0-1区间划分为100个矩形,则各个进程计算的矩形块为
{
x = h * ((double)i - 0.5);
sum += f(x);
}
mypi = h * sum;
MPI_Reduce(&mypi,&pi,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);
//cout << mypi << endl;

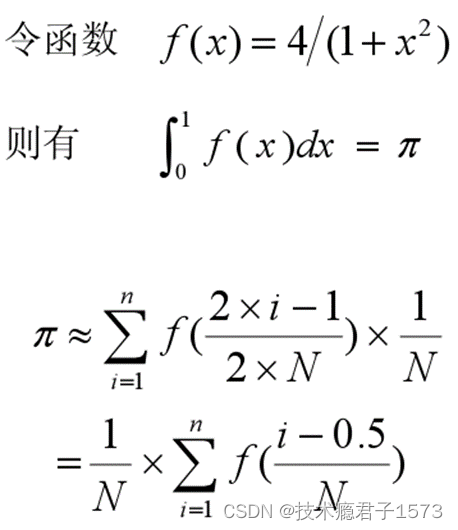
if(0 == myrank)
{
//cout << mypi << endl;
cout << “erro=" << pi-PI25DT << endl;
cout << pi << endl;
endwtime = MPI_Wtime();
cout << "wtime =" << endwtime-startwtime << endl;
}
MPI_Finalize();
return 0;
}