GLM-4-9b
论文
暂无
模型结构
基于transformer结构
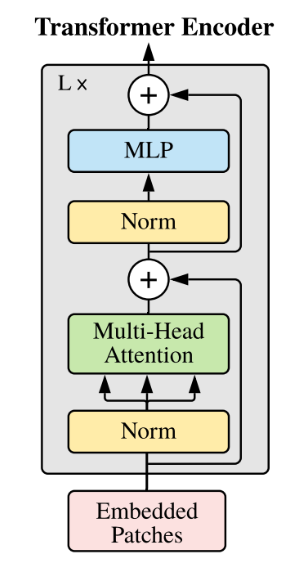
算法原理
GLM-4-9B是智谱AI推出的最新一代预训练模型GLM-4系列中的开源版本,在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B及其人类偏好对齐的版本GLM-4-9B-Chat均表现出超越Llama-3-8B的卓越性能。以多模态模型GLM-4V-9B为例,这一模型采用了与CogVLM2相似的架构设计,能够处理高达1120 x 1120分辨率的输入,并通过降采样技术有效减少了token的开销。为了减小部署与计算开销,GLM-4V-9B没有引入额外的视觉专家模块,采用了直接混合文本和图片数据的方式进行训练,在保持文本性能的同时提升多模态能力。
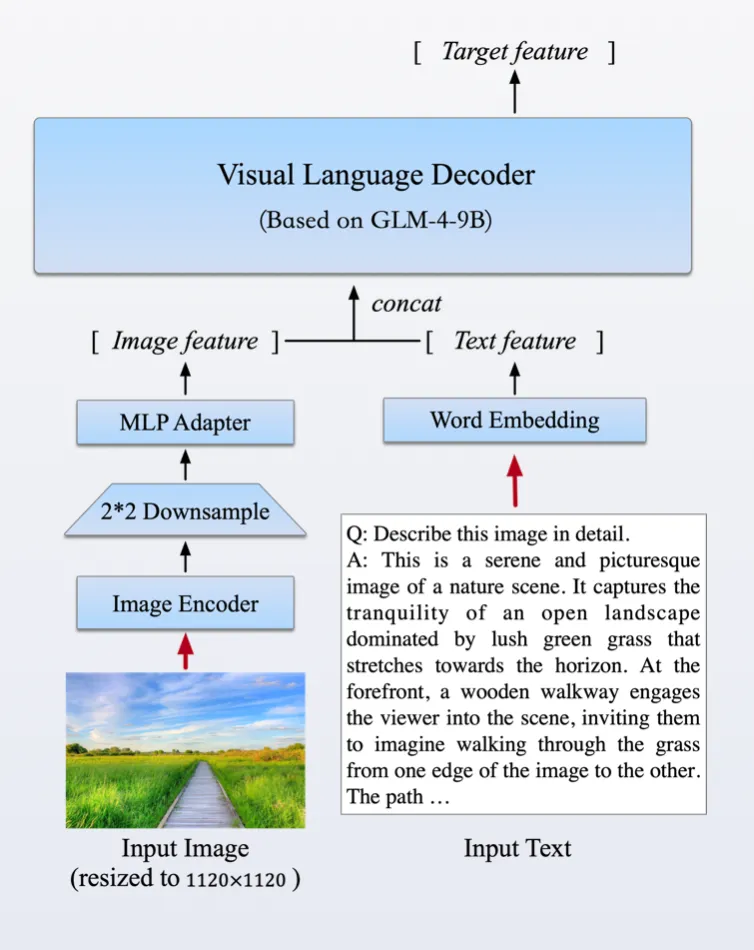
环境配置
-v 路径、docker_name和imageID根据实际情况修改
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=32G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro imageID /bin/bash
cd /your_code_path/glm4-9b_pytorch
cd basic_demo
pip install -r requirements.txt
Dockerfile(方法二)
cd ./docker
docker build --no-cache -t glm4-9b:latest .
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=32G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro imageID /bin/bash
cd /your_code_path/glm4-9b_pytorch
cd basic_demo
pip install -r requirements.txt
Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK软件栈:dtk24.04
python:python3.10
torch:2.1
deepspeed: 0.12.3
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照下面步骤进行安装
cd basic_demo
pip install deepspeed-0.12.3+das1.0+gita724046.abi0.dtk2404.torch2.1.0-cp310-cp310-manylinux2014_x86_64.whl
pip install -r requirements.txt
数据集
准备数据集
本仓库以ADGEN (广告生成) 数据集为例介绍代码的使用方法,可通过Google Drive 或者 Tsinghua Cloud下载处理好的 ADGEN 数据集。数据集下载完成后,将数据解压到data目录下。
数据按路径存放后,执行下面的数据转换代码,生成的dev.jsonl train.jsonl默认保存在AdvertiseGen/saves目录下:
python gen_messages_data.py --data_path /path/to/AdvertiseGen
数据集目录结构如下:
├── data
│ ├── AdvertiseGen
│ ├── saves # 生成的
│ ├── dev.json
│ └── train.json
若想生成自己的数据文件,代码可参考gen_messages_data.py进行修改,样例采用如下格式。
- 这里是一个不带有工具的例子:
{"messages": [{"role": "user", "content": "类型#裤*材质#牛仔布*风格#性感"}, {"role": "assistant", "content": "3x1的这款牛仔裤采用浅白的牛仔面料为裤身材质,其柔然的手感和细腻的质地,在穿着舒适的同时,透露着清纯甜美的个性气质。除此之外,流畅的裤身剪裁将性感的腿部曲线彰显的淋漓尽致,不失为一款随性出街的必备单品。"}]}
- 这是一个带有工具调用的例子:
{"messages": [{"role": "system", "content": "", "tools": [{"type": "function", "function": {"name": "get_recommended_books", "description": "Get recommended books based on user's interests", "parameters": {"type": "object", "properties": {"interests": {"type": "array", "items": {"type": "string"}, "description": "The interests to recommend books for"}}, "required": ["interests"]}}}]}, {"role": "user", "content": "Hi, I am looking for some book recommendations. I am interested in history and science fiction."}, {"role": "assistant", "content": "{\"name\": \"get_recommended_books\", \"arguments\": {\"interests\": [\"history\", \"science fiction\"]}}"}, {"role": "observation", "content": "{\"books\": [\"Sapiens: A Brief History of Humankind by Yuval Noah Harari\", \"A Brief History of Time by Stephen Hawking\", \"Dune by Frank Herbert\", \"The Martian by Andy Weir\"]}"}, {"role": "assistant", "content": "Based on your interests in history and science fiction, I would recommend the following books: \"Sapiens: A Brief History of Humankind\" by Yuval Noah Harari, \"A Brief History of Time\" by Stephen Hawking, \"Dune\" by Frank Herbert, and \"The Martian\" by Andy Weir."}]}
system角色为可选角色,但若存在system角色,其必须出现在user角色之前,且一个完整的对话数据(无论单轮或者多轮对话)只能出现一次system角色。tools字段为可选字段,若存在tools字段,其必须出现在system角色之后,且一个完整的对话数据(无论单轮或者多轮对话)只能出现一次tools字段。当tools字段存在时,system角色必须存在并且content字段为空。
训练
预训练模型可通过SCNet AIModels下载,当前用例默认预训练模型为:glm-4-9b-chat。
- 进入
finetune_demo目录下,首先安装所需环境信息:
pip install -r requirements.txt
- 配置文件位于configs目录下,包括以下文件:
deepspeed配置文件:ds_zereo_2,ds_zereo_3lora.yaml/ ptuning_v2.yaml / sft.yaml: 模型不同方式的配置文件,包括模型参数、优化器参数、训练参数等。部分重要参数解释如下:- data_config 部分
- train_file: 训练数据集的文件路径。
- val_file: 验证数据集的文件路径。
- test_file: 测试数据集的文件路径。
- num_proc: 在加载数据时使用的进程数量。
- max_input_length: 输入序列的最大长度。
- max_output_length: 输出序列的最大长度。
- training_args 部分
- output_dir: 用于保存模型和其他输出的目录。
- max_steps: 训练的最大步数。
- per_device_train_batch_size: 每个设备(如 GPU)的训练批次大小。
- dataloader_num_workers: 加载数据时使用的工作线程数量。
- remove_unused_columns: 是否移除数据中未使用的列。
- save_strategy: 模型保存策略(例如,每隔多少步保存一次)。
- save_steps: 每隔多少步保存一次模型。
- log_level: 日志级别(如 info)。
- logging_strategy: 日志记录策略。
- logging_steps: 每隔多少步记录一次日志。
- per_device_eval_batch_size: 每个设备的评估批次大小。
- evaluation_strategy: 评估策略(例如,每隔多少步进行一次评估)。
- eval_steps: 每隔多少步进行一次评估。
- predict_with_generate: 是否使用生成模式进行预测。
- generation_config 部分
- max_new_tokens: 生成的最大新 token 数量。
- peft_config 部分
- peft_type: 使用的参数有效调整类型 (支持 LORA 和 PREFIX_TUNING)。
- task_type: 任务类型,这里是因果语言模型 (不要改动)。
- Lora 参数:
- r: LoRA 的秩。
- lora_alpha: LoRA 的缩放因子。
- lora_dropout: 在 LoRA 层使用的 dropout 概率。
- P-TuningV2 参数:
- num_virtual_tokens: 虚拟 token 的数量。
- num_attention_heads: 2: P-TuningV2 的注意力头数(不要改动)。
- token_dim: 256: P-TuningV2 的 token 维度(不要改动)。
- data_config 部分
- 脚本中主要参数解释, 以下参数均可根据自身数据地址进行替换:
data/AdvertiseGen/saves/:.jsonl数据地址../checkpoints/glm-4-9b-chat/: 模型地址configs/lora.yaml: 配置文件地址
单机单卡
bash train.sh
单机多卡/多机多卡
这里使用deepspeed作为加速方案,请确认当前环境已经根据环境配置章节安装好了deepspeed库。
bash train_dp.sh
从保存点进行微调
如果按照上述方式进行训练,每次微调都会从头开始,如果你想从训练一半的模型开始微调,你可以加入第四个参数,这个参数有两种传入方式:
yes, 自动从最后一个保存的Checkpoint开始训练,例如:
python finetune.py ../data/AdvertiseGen/saves/ ../checkpoints/glm-4-9b-chat/ configs/lora.yaml yes
XX, 断点号数字,例600则从序号600 Checkpoint开始训练,例如:
python finetune.py ../data/AdvertiseGen/saves/ ../checkpoints/glm-4-9b-chat/ configs/lora.yaml 600
推理
进入basic_demo目录下
快速调用
参数解释
- --model_name_or_path:待测模型名或模型地址,当前默认"THUDM/glm-4-9b-chat"
- --device: 当前默认"cuda"
- --query: 待测输入语句,当前默认"你好"
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com/
python quick_start.py
使用命令行与 GLM-4-9B 模型进行对话
# chat
python trans_cli_demo.py --model_name_or_path ../checkpoints/glm-4-9b-chat
# 多模态
python trans_cli_vision_demo.py --model_name_or_path ../checkpoints/glm-4v-9b
使用 Gradio 网页端与 GLM-4-9B-Chat 模型进行对话
python trans_web_demo.py --model_name_or_path ../checkpoints/glm-4-9b-chat
验证微调后的模型
您可以在finetune_demo/inference.py 中使用微调后的模型,执行方式如下。
python inference.py your_finetune_path
result

精度
数据集:AdvertiseGen
| device | iters | train_loss |
|---|---|---|
| A800 | 1000 | 3.0219 |
| K100 | 1000 | 3.0205 |
应用场景
算法类别
多轮对话
热点应用行业
家居,教育,科研