概念
K Nearest Neighbor
算法⼜叫
KNN
算法,这个算法是机器学习⾥⾯⼀个⽐较经典的算法, 总体来说
KNN
算法是相对⽐较容易理解的算法
定义
如果⼀个样本在特征空间中的
k
个最相似
(
即特征空间中最邻近
)
的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别。
常⻅的距离公式
距离公式的基本性质
在机器学习过程中,对于函数
dist()
,若它是⼀
"
距离度量
" (distance measure)
,则需满⾜⼀些基本性质
:
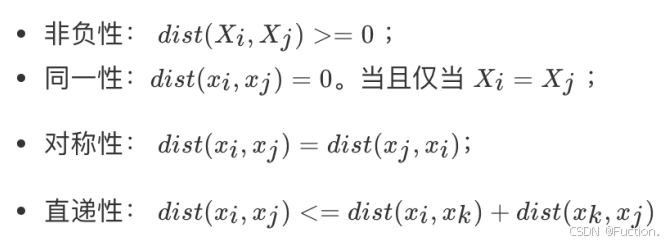
直递性常被直接称为
“
三⻆不等式
”
。
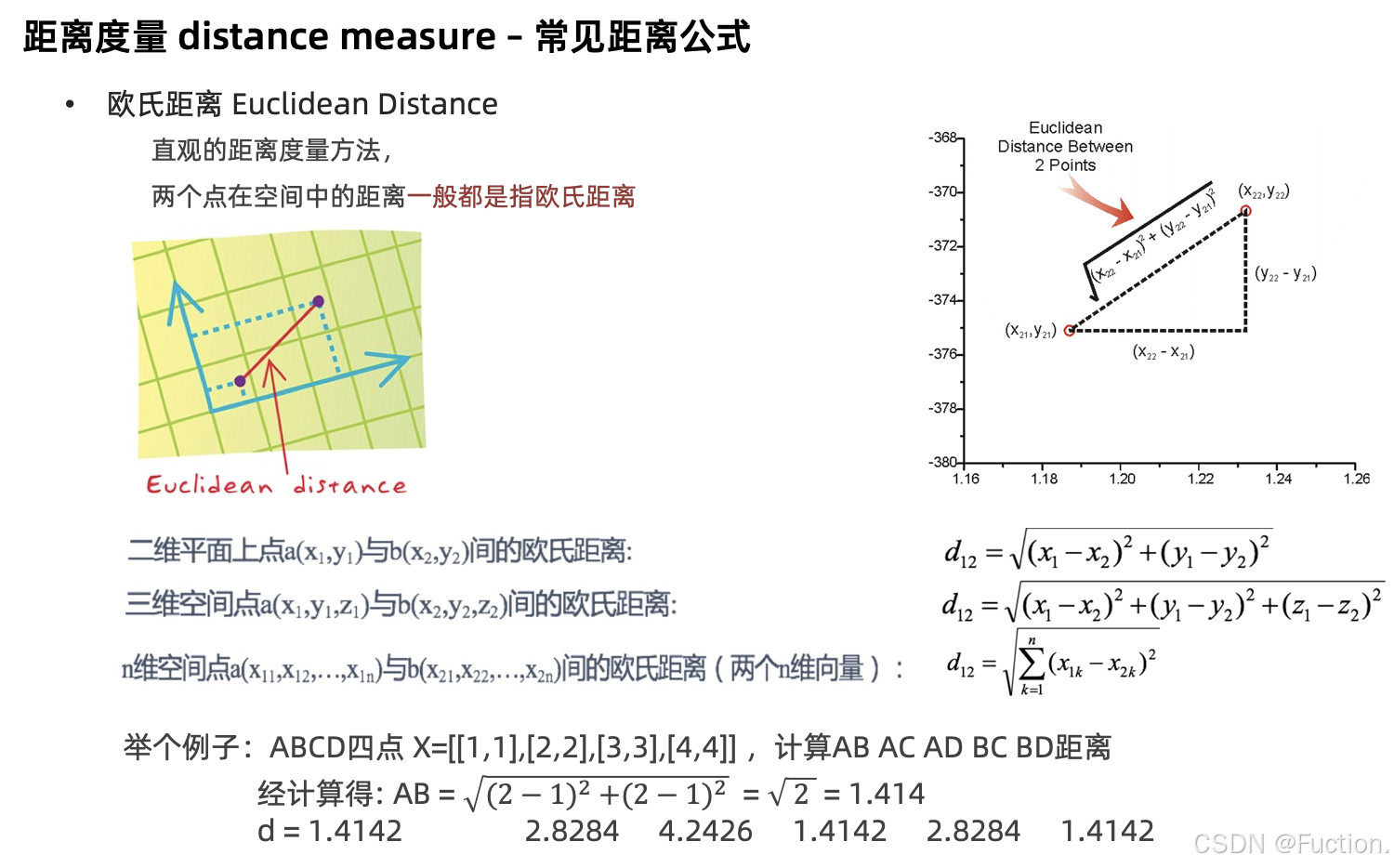
欧式距离
欧⽒距离
(Euclidean Distance)
是最容易直观理解的距离度量⽅法,我们⼩学、初中和⾼中接触到的两个点在空间中的距离⼀般都是指欧⽒距离。
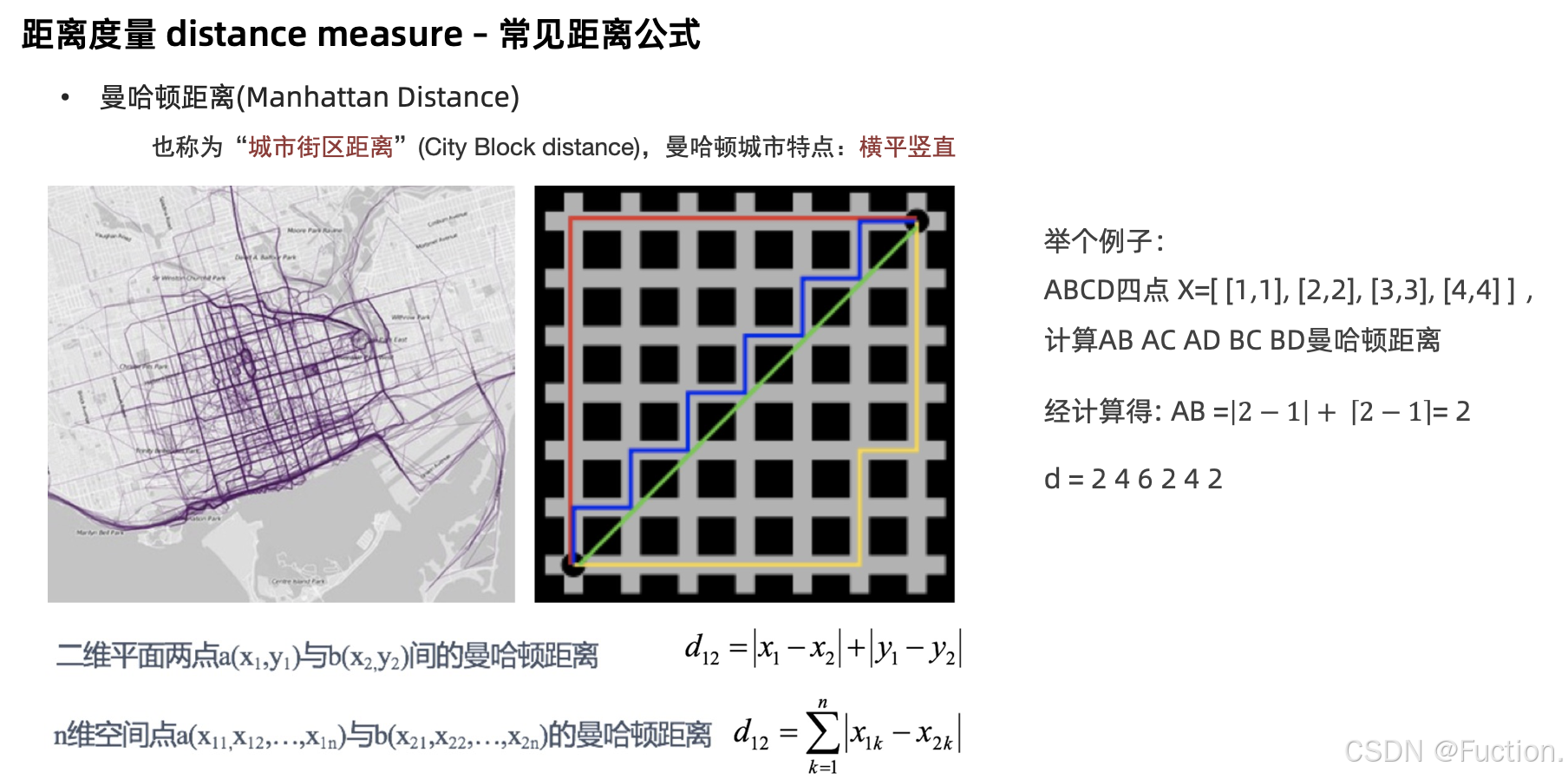
曼哈顿距离
在曼哈顿街区要从⼀个⼗字路⼝开⻋到另⼀个⼗字路⼝,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是
“
曼哈顿距离
(Manhattan Distance)”
。曼哈顿距离也称为
“
城市街区距离
”(City Block distance)
。
切⽐雪夫距离
国际象棋中,国王可以直⾏、横⾏、斜⾏,所以国王⾛⼀步可以移动到相邻
8
个⽅格中的任意⼀个。国王从格⼦
(x1,y1)
⾛到格⼦
(x2,y2)
最少需要多少步?这个距离就叫切⽐雪夫距离
(Chebyshev Distance)
。
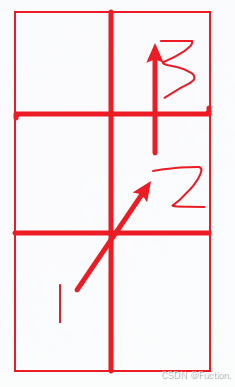
从1到2算走了一步,从2到3也是1步,所以切比雪夫距离就是3,竖向走了三步,横向走了2步,取最大值。
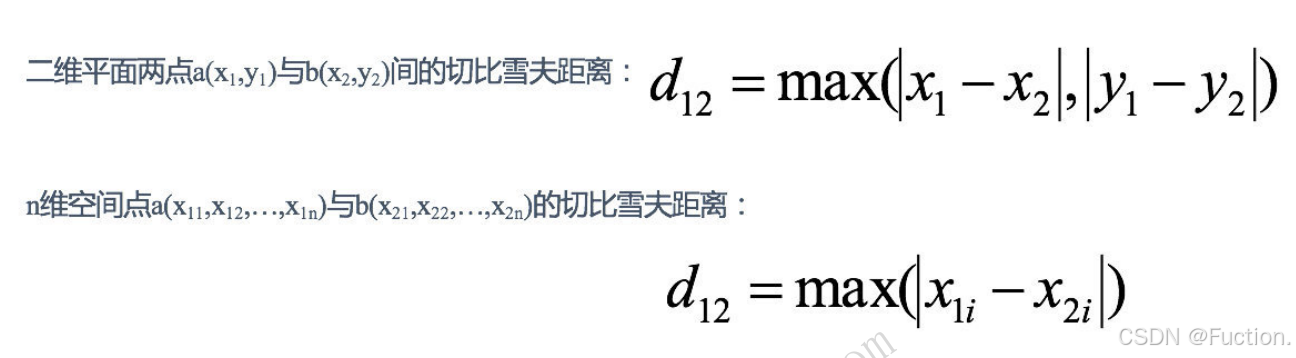
闵可夫斯基距离
闵⽒距离
(Minkowski Distance)
不是⼀种距离,⽽是⼀组距离的定义,是对多个距离度量公式的概括性的表述。两个
n
维变量
a(x ,x ,…,x )
与
b(x ,x ,…,x )
间的闵可夫斯基距离定义为:
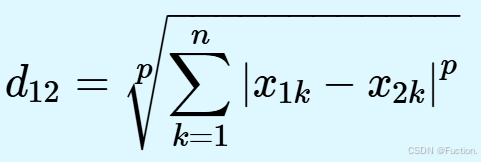
其中
p
是⼀个变参数:
当
p=1
时,就是曼哈顿距离;
当
p=2
时,就是欧⽒距离;
当
p→∞
时,就是切⽐雪夫距离。
根据
p
的不同,闵⽒距离可以表示某⼀类
/
种的距离。
闵⽒距离,包括曼哈顿距离、欧⽒距离和切⽐雪夫距离,都存在明显的缺点
:
e.g.
⼆维样本
(
身⾼
[
单位
:cm],
体重
[
单位
:kg]),
现有三个样本:
a(180,50)
,
b(190,50)
,
c(180,60)
。
a
与
b
的闵⽒距离(⽆论是曼哈顿距离、欧⽒距离或切⽐雪夫距离)等于
a
与
c
的闵⽒距离。但实际上身⾼的
10cm
并不能和体重的
10kg
划等号。
闵⽒距离的缺点:
(1)
将各个分量的量纲
(scale)
,也就是
“
单位
”
相同的看待了
;
(2)
未考虑各个分量的分布(期望,⽅差等)可能是不同的。
连续属性”和“离散属性”的距离计算
我们常将属性划分为
"
连续属性
" (continuous attribute)
和
"
离散属性
" (categoricalattribute)
,前者在定义域上有⽆穷多个可能的取值,后者在定义域上是有限个取值
.
- 若属性值之间存在序关系,则可以将其转化为连续值,例如:身⾼属性“⾼”“中等”“矮”,可转化为{1, 0.5, 0}。
- 闵可夫斯基距离可以⽤于有序属性。
- 若属性值之间不存在序关系,则通常将其转化为向量的形式,例如:性别属性“男”“⼥”,可转化为{ (1,0),(0,1)}。
电影类型分析
假设我们现在有⼏部电影
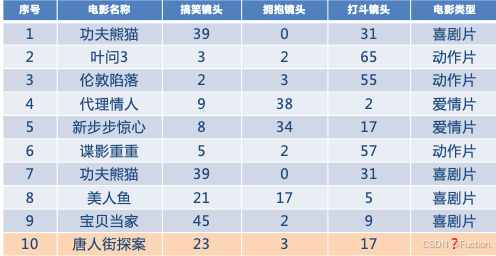
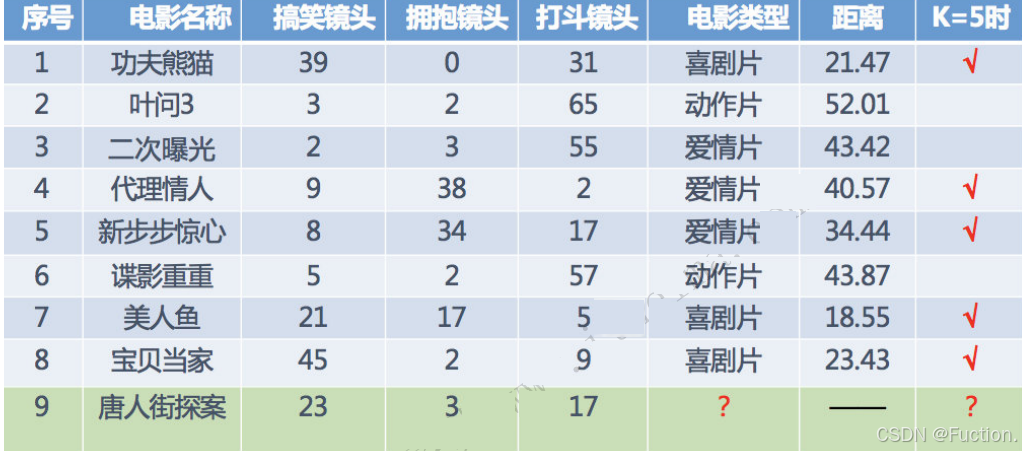
其中
9
号电影不知道类别,如何去预测?我们可以利⽤
K
近邻算法的思想
分别计算每个电影和被预测电影的距离,然后求解
KNN算法流程总结
1
)计算已知类别数据集中的点与当前点之间的距离
2
)按距离递增次序排序
3
)选取与当前点距离最⼩的
k
个点
4
)统计前
k
个点所在的类别出现的频率
5
)返回前
k
个点出现频率最
⾼
的类别作为当前点的预测分类
k近邻算法api初步使⽤
Scikit-learn
⼯具介绍

Python
语⾔的机器学习⼯具
Scikit-learn
包括许多知名的机器学习算法的实现
Scikit-learn
⽂档完善,容易上⼿,丰富的
API
安装
pip install scikit-learn
安装好之后可以通过以下命令查看是否安装成功
import sklearn
注:安装
scikit-learn
需要
Numpy, Scipy
等库
Scikit-learn
包含的内容
分类问题实现
K-
近邻算法
API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
参数介绍:
# n_neighbors:int,可选(默认= 5),k_neighbors查询默认使⽤的邻居数
代码过程
步骤⼀:导⼊模块
from sklearn.neighbors import KNeighborsClassifier
步骤⼆:构造数据集
数据集格式⼀:
x_train = [[1], [2], [3], [4]] #注意这里是二维
y_train = [0, 0, 1, 1] #这里是一维
数据集格式⼆:
x_train = [[39,0,31],[3,2,65],[2,3,55],[9,38,2],[8,34,17],[5,2,57],[21,17,5],[45,2,9
y_train = [0,1,2,2,2,2,1,1]
步骤三:机器学习
--
模型训练
# 实例化API
estimator = KNeighborsClassifier(n_neighbors=1)
# 模型训练
# 参1:训练集的特征,参2:训练集的标签
estimator.fit(x_train, y_train)
# 模型预测,并打印预测结果
# 传入测试集的特征,基于模型,获取 测试集的 预测标签
estimator.predict([[1]])
# 数据集格式⼆对应的测试数据
# estimator.predict([[23,3,17]])回归问题实现
步骤⼀:导⼊模块
from sklearn.neighbors import KNeighborsRegressor
步骤⼆:构造数据集
x_train = [[0,0,1],[1,1,0],[3,10,10],[4,11,12]]
y_train = [0.1,0.2,0.3,0.4]
x_test = [[3,10,11]]
# 训练模型
estimator.fit(x_train,y_train)
estimator.predict(x_test)
步骤三:机器学习
--
模型训练
# 实例化API
estimator = KNeighborsRegressor(n_neighbors=3)
# 模型训练
# 参1:训练集的特征,参2:训练集的标签
estimator.fit(x_train, y_train)
# 模型预测,并打印预测结果
# 传入测试集的特征,基于模型,获取 测试集的 预测标签
estimator.predict(x_test)k值的选择
K值选择说明
K
值选择问题,李航博⼠的⼀书「统计学习⽅法」上所说:
1)
选择较⼩的
K
值,就相当于⽤较⼩的领域中的训练实例进⾏预测,
2)
选择较⼤的
K
值,就相当于⽤较⼤领域中的训练实例进⾏预测,
3) K=N
(
N
为训练样本个数),则完全不⾜取,
- 近似误差:
- 对现有训练集的训练误差,关注训练集,
- 如果近似误差过⼩可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较⼤偏差的预测。
- 模型本身不是最接近最佳模型。
- 估计误差:
- 可以理解为对测试集的测试误差,关注测试集,
- 估计误差⼩说明对未知数据的预测能⼒好,
- 模型本身最接近最佳模型。