摘要
论文地址:https://arxiv.org/abs/1706.06978
DIN是阿里发表在 KDD2018 上的一篇关于对用户行为序列建模的一篇论文。论文出了一种新型模型: 深度兴趣网络(DIN)。通过设计一个局部激活单元来自适应地学习用户对某一广告历史行为的兴趣表征,从而解决了这一难题。这种表征向量会随不同的广告而变化,从而大大提高了模型的表达能力。此外,论文还提出了迷你批量感知正则化和数据自适应激活函数,它们可以帮助训练具有数亿个参数的工业深度网络。DIN 目前已成功应用于阿里巴巴的在线展示广告系统,为主要流量提供服务。
所以这篇论文注意就是以下几个创新点:
- 局部激活单元,可从给定广告的历史行为中自适应地学习用户兴趣的表示。
- 迷你批量感知正则化器,它可以节省参数数量巨大的深度网络正则化的繁重计算,并有助于避免过拟合;
- 数据自适应激活函数,它通过考虑输入的分布来泛化 PReLU,并显示出良好的性能。
DEEP INTEREST NETWORK
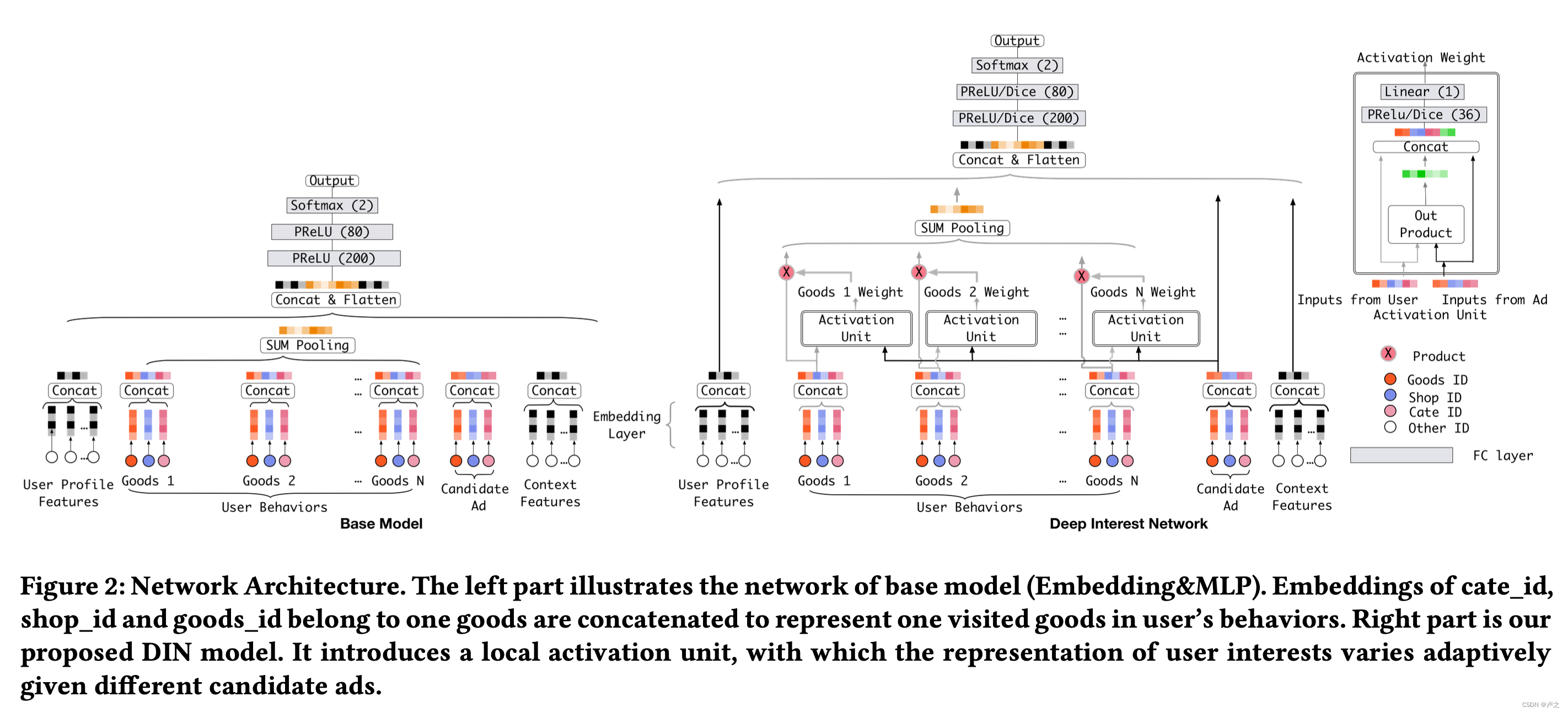
论文当中使用了注意力方法来建模短期局部的兴趣。
论文当中的注意力方法与传统注意力方法不同的是,注意力权重
∑
i
w
i
=
1
\sum_{i}w_{i}= 1
i∑wi=1 的约束条件被放宽,目的是保留用户兴趣的强度。
也就是说,放弃了对输出进行 softmax 归一化。取而代之的是,权重的大小被视为被激活用户兴趣强度的近似值。传统的注意力方法通过对输出进行归一化处理,失去了对候选商品的注意力分辨率的体现。
Mini-batch Aware Regularization
迷你批次的正则化主要是用来处理过拟合的问题,如果没有正则,模型的表现会在第一个 epoch之后下降非常快。
论文提出了 Mini-batch Aware Regularization,它只计算每个迷你批量中出现的稀疏特征参数的 L2 值,并使计算成为可能。事实上,正是 embedding 字典贡献了 CTR 网络的大部分参数,并造成了繁重计算的困难。
W \mathbf{W} W 表示所有 embedding 的参数,施加在参数上的 L2 正则表达式可以表示为:
L 2 ( W ) = ∥ W ∥ 2 2 = ∑ j = 1 K ∥ w j ∥ 2 2 = ∑ ( x , y ) ∈ S ∑ j = 1 K I ( x j ≠ 0 ) n j ∥ w j ∥ 2 2 , L_2(\mathbf{W})=\|\mathbf{W}\|_2^2=\sum_{j=1}^K\|\mathbf{w}_j\|_2^2=\sum_{(x,y)\in\mathcal{S}}\sum_{j=1}^K\frac{I(\boldsymbol{x}_j\neq0)}{\boldsymbol{n}_j}\|\boldsymbol{w}_j\|_2^2, L2(W)=∥W∥22=j=1∑K∥wj∥22=(x,y)∈S∑j=1∑KnjI(xj=0)∥wj∥22,
如果以 mini-batch 的形式,公式又可以写成如下形式:
L 2 ( W ) = ∑ j = 1 K ∑ m = 1 B ∑ ( x , y ) ∈ B m I ( x j ≠ 0 ) n j ∥ w j ∥ 2 2 L_2(\mathbf{W})=\sum_{j=1}^K\sum_{m=1}^B\sum_{(x,y)\in\mathcal{B}_m}\frac{I(x_j\neq0)}{n_j}\|w_j\|_2^2 L2(W)=j=1∑Km=1∑B(x,y)∈Bm∑njI(xj=0)∥wj∥22
那么,在每个 mini-batch 的的参数 L2 正则化后的梯度变化为:
w j ← w j − η [ 1 ∣ B m ∣ ∑ ( x , y ) ∈ B m ∂ L ( p ( x ) , y ) ∂ w j + λ α _ m j n j w j ] w_j\leftarrow w_j-\eta\left[\frac1{|B_m|}\sum_{(x,y)\in\mathcal{B}_m}\frac{\partial L(p(x),y)}{\partial w_j}+\lambda\frac{\alpha\_{mj}}{n_j}w_j\right] wj←wj−η ∣Bm∣1(x,y)∈Bm∑∂wj∂L(p(x),y)+λnjα_mjwj
Data Adaptive Activation Function
论文认为 PReLU 取值为 0 的硬校正点,这可能不适合各层输入分布不同的情况。考虑到这一点,论文设计了一种新的数据自适应激活函数 Dice.
f ( s ) = p ( s ) ⋅ s + ( 1 − p ( s ) ) ⋅ α s , p ( s ) = 1 1 + e − s − E [ s ] V a r [ s ] + ϵ f(s)=p(s)\cdot s+(1-p(s))\cdot\alpha s,\quad p(s)=\frac1{1+e^{-\frac{s-E[s]}{\sqrt{Var[s]+\epsilon}}}} f(s)=p(s)⋅s+(1−p(s))⋅αs,p(s)=1+e−Var[s]+ϵs−E[s]1
Dice 也是 0-1 之间的激活函数,在 0-1 之间平滑过渡,如下图所示
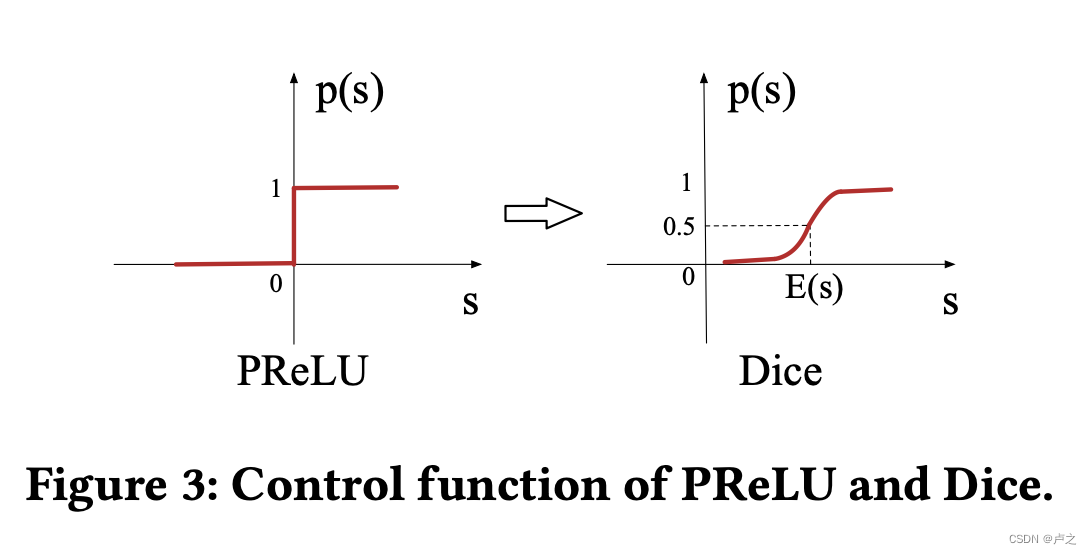
Dice 可以被看作是 PReLu 的泛化。Dice 的主要思想是根据输入数据的分布自适应地调整,其值被设定为输入数据的平均值。此外,Dice 还能控制两个通道之间的平滑切换。当 E ( s ) = 0 E(s) = 0 E(s)=0 和 V a r [ s ] = 0 Var[s] = 0 Var[s]=0 时,Dice 退化为 PReLU。
评估指标
论文里面还介绍了几种比较有趣的评估指标
一种是加权 AUC,它通过对用户的 AUC 取平均值来衡量用用户内部商品顺序的好坏,并被证明与显示广告系统的在线性能更为相关。
这里有点像是 GAUC 的概念。
A U C = ∑ i = 1 n i m p r e s s i o n i × A U C i ∑ i = 1 n i m p r e s s i o n i \mathrm{AUC}=\frac{\sum_{i=1}^n impression_i\times\mathrm{AUC}_i}{\sum_{i=1}^n impression_i} AUC=∑i=1nimpressioni∑i=1nimpressioni×AUCi
另外一个就是相关曝光指标 RelaImpr,用来衡量模型的提升程度,这个看看就好,直接与 a u c = 0.5 auc=0.5 auc=0.5 相比较也差不多。
R e l a I m p r = ( A U C ( measured model) − 0.5 A U C ( b a s e m o d e l ) − 0.5 − 1 ) × 100 % . RelaI\boldsymbol{mpr}=\left(\frac{\mathrm{AUC}(\text{measured model)}-0.5}{\mathrm{AUC}(\mathrm{base~model})-0.5}-1\right)\times100\%. RelaImpr=(AUC(base model)−0.5AUC(measured model)−0.5−1)×100%.
相关代码
Dice 实现的 python 代码:
import tensorflow as tf
def dice(_x, axis=-1, epsilon=0.000000001, name=''):
with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
alphas = tf.get_variable('alpha'+name, _x.get_shape()[-1],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
input_shape = list(_x.get_shape())
reduction_axes = list(range(len(input_shape)))
del reduction_axes[axis]
broadcast_shape = [1] * len(input_shape)
broadcast_shape[axis] = input_shape[axis]
# case: train mode (uses stats of the current batch)
mean = tf.reduce_mean(_x, axis=reduction_axes)
brodcast_mean = tf.reshape(mean, broadcast_shape)
std = tf.reduce_mean(tf.square(_x - brodcast_mean) + epsilon, axis=reduction_axes)
std = tf.sqrt(std)
brodcast_std = tf.reshape(std, broadcast_shape)
x_normed = (_x - brodcast_mean) / (brodcast_std + epsilon)
# x_normed = tf.layers.batch_normalization(_x, center=False, scale=False)
x_p = tf.sigmoid(x_normed)
return alphas * (1.0 - x_p) * _x + x_p * _x
def parametric_relu(_x):
alphas = tf.get_variable('alpha', _x.get_shape()[-1],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
pos = tf.nn.relu(_x)
neg = alphas * (_x - abs(_x)) * 0.5
return pos + neg