创建高级联结
使用表别名
之前说到用AS可以创建别名,别名除了用于列名和计算字段外,SQL还允许给表名起别名,这样做有两个主要的理由:
- 缩短SQL语句
- 允许在单条SELECT 语句中多次使用相同的表
通过上面的语句,可以看到FROM子句中3个表全部都具有别名,customers AS c建立c作为customers的别名,在这个例子中,表别名只用于WHERE子句,但是表别名不仅能用于WHERE子句,还可用于SELECT的列表,ORDER BY子句以及语句的其他部分;
使用不同类型的联结
之前使用的都是内部联结或等值联结的简单联结;还有三种分别是自联结,自然联结,和外部联结;
自联结
使用表别名的主要原因之一是能在单条SELECT语句中不止一次引用相同的表;
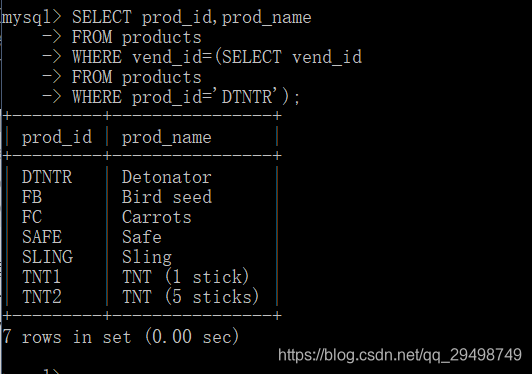
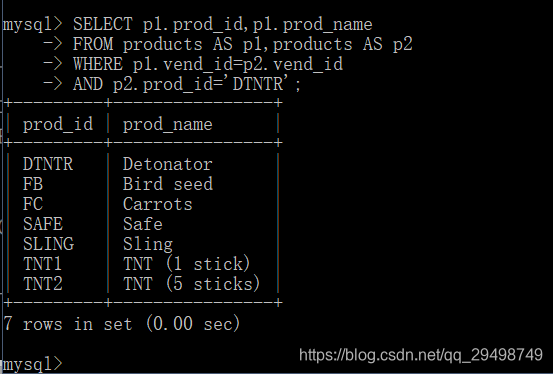
为此,我使用了两个别名,p1,p2,并且根据实例进行联结查找表,按第二个表中的prod_id过滤数据,返回所需的数据
自联结通常作为外部语句来代替从相同表中检索数据时使用的子查询,最终结果都相同,但有时候处理联结远比处理子查询快的多;
自然联结
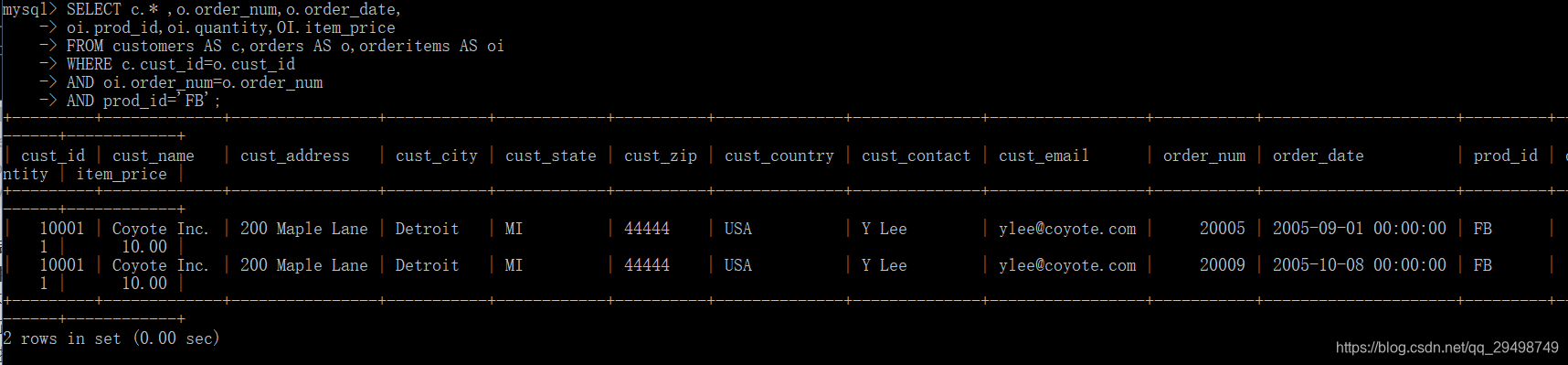
无论何时对表进行联结,应该至少有一个列出现在不止应该表中,标准的联结返回所有的数据,甚至会有多次出现,自然联结排除多次,使每个列返回一次;
自然联结是这样一种联结,其中你只能选择那些唯一的列,这一般是通过对表使用通配符(SELECT *),对所有其他表的列使用明确的子集来完成的:
外部联结
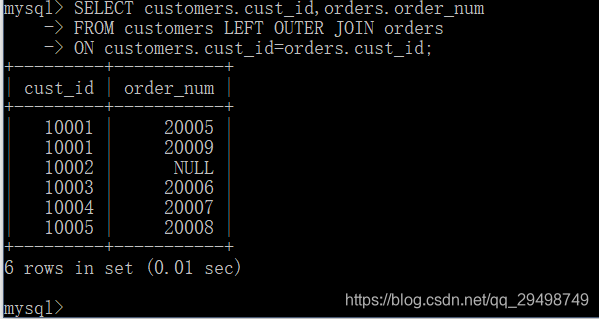
许多联结将一个表中的行于另一个表中的行相关联,有时会需要包含没有关联行的那些行;联结包含了那些在相关表中没有关联行的行,这种类型被称为外部联结
使用带聚集函数的联结
聚集函数用来汇总数据,聚集函数的所有例子只是从单个表汇总,这些函数也可以于联结一起使用:
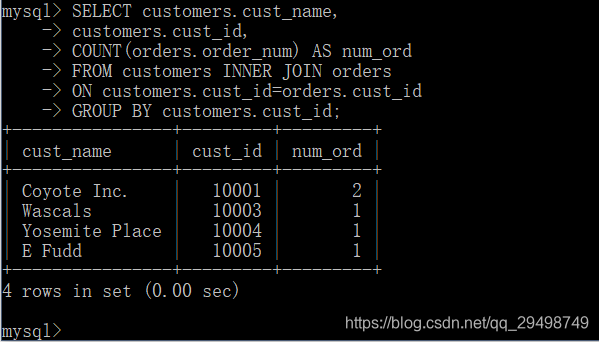
聚集函数也可以方便的和其他联结一起使用
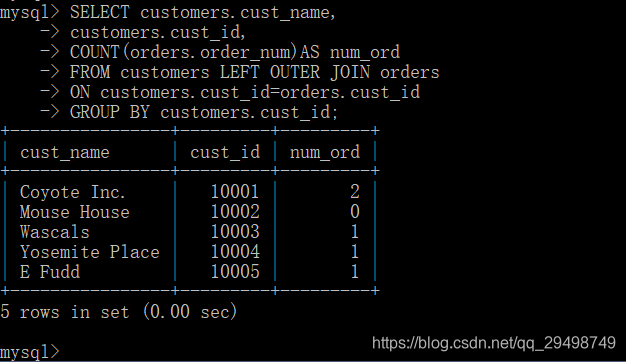
使用联结和联结条件
联结及其使用的要点:
- 注意所使用的联结类型,一般使用内部联结,但使用外部联结也是有效的
- 保证使用正确的联结条件,否则返回不正确的数据
- 应该总是提供联结条件,否则会得出笛卡尔积
- 在一个联结中可以包含多个表,甚至对于每个联结可以采用不同的联结类型,虽然合法,一般很有用,应该在使用前分别测试每个联结
组合查询
组合查询
mysql允许执行多个查询,并将结果作为单个查询集返回,这些组合查询通常称为并(union)或复合查询(compound query)
有两种基本情况,其中需要使用组合查询:
- 在单个查询中从不同的表返回类似结构的数据
- 对单个表执行多个查询,按单个查询返回数据
创建组合查询
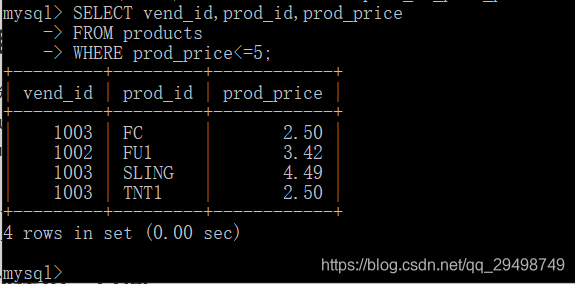
可用UNION操作符来组合数条SQL查询,利用UNION,可给出多条SELECT语句,将它们的结果组合成单个结果集;
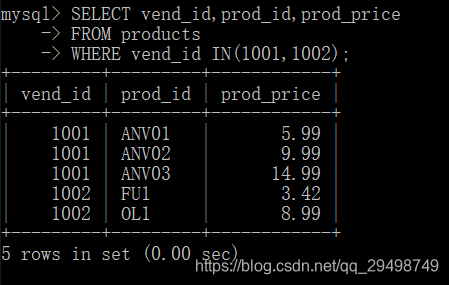
使用UNION
UNION的使用很简单,给出每条SELECT语句,在给条语句之间放上关键字UNION
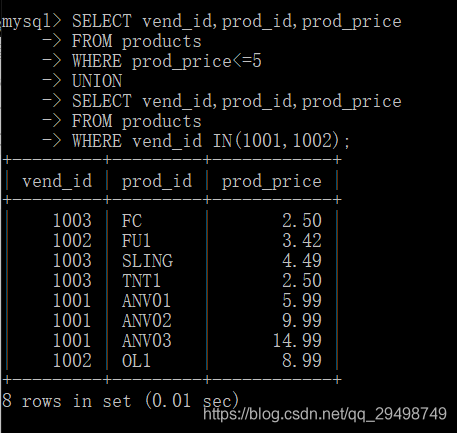
UNION规则
在使用UNION的几条规则:
- UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔,(因此,如果组合4条SELECT语句,要使用3个UNION关键字)
- UNION中的每个查询必须包含相同的列,表达式或聚集函数(不过各个列不需要相同的次序列出)
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含的转换类型,(列如,不同的数值类型或不同的日期类型)。
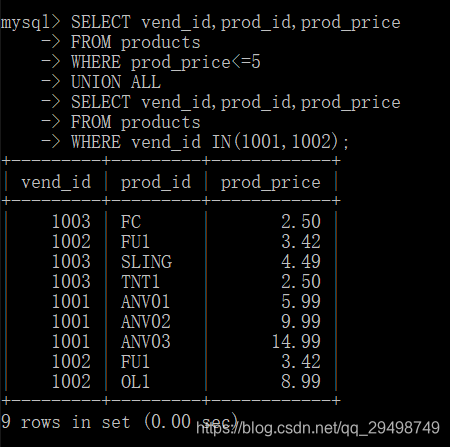
包含或取消重复的行
在使用UNION时,重复的行被自动取消,这是UNION的默认行为,如果需要,可以改变它,可以使用UNION ALL而不是UNION。
对组合查询结果排序
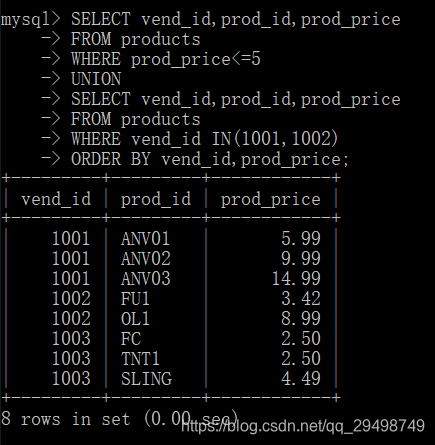
ORDERY BY子句虽然只出现在后面但是它排序了所有的SELECT 语句的数据;
全文本搜索
理解全文本搜索
虽然之前有LIKE关键字,它利用通配操作符匹配文本,使用LIKE,能够查找包含特殊值或部分值的行。
虽然搜索机制非常有用,但还是有几个限制:
- 性能——通配符和正则表达式匹配通常要求MYSQL尝试匹配表中所有行,因此,由于被搜索行数不断地增加,这些搜索可能非常耗时
- 明确控制——使用通配符和正则表达式匹配。很难明确的控制匹配什么和不匹配什么;
- 智能化的结果——虽然基于通配符和正则表达式的搜索提供了非常灵活的搜索,但他们都不能提供一种智能化的选择结果的方法;
所有这些限制以及更多的限制都可以用全文本搜索来解决,在使用全文本搜索时,mysql不需要分别查看每个行,也不需要分别分析和处理每个词,mysql创建指定列中各词的应该索引,搜索可以针对这些词进行搜索;
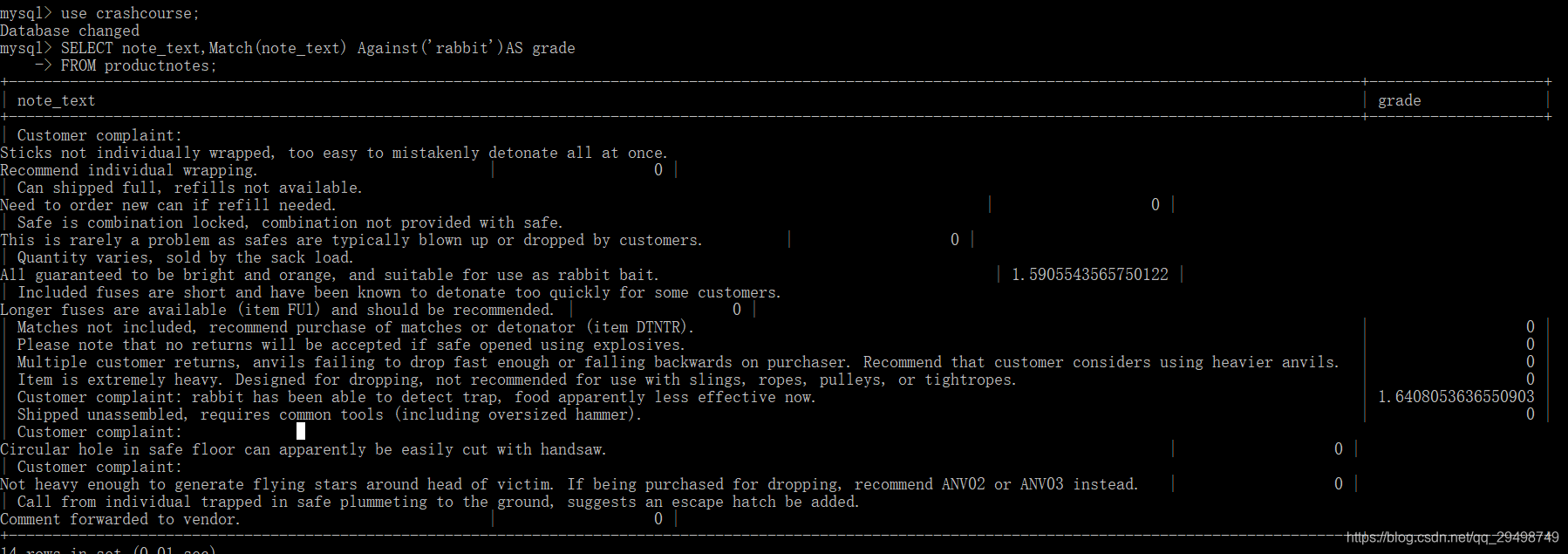
使用全文本搜索
进行全文本搜索,要索引被搜索的列,要随着数据的改变而改变,MySQL会自动进行索引的索引和重新索引;
之后,SELECT可与MATCH()和Against()一起使用以实际执行搜索
启用全文本搜索支持
在创建表时启用全文本搜索,CREATE TABLE语句接受FULLTEXT子句,它给出被索引列的一个逗号分隔的列表;

进行全文本搜索


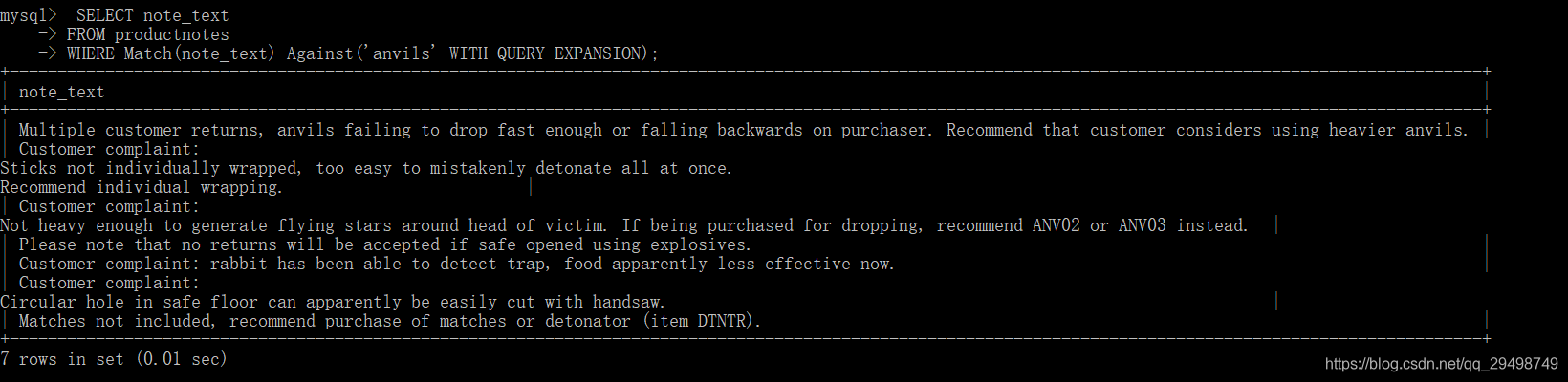
使用查询扩展
查询扩展用来设法放宽所返回的全文本搜索结果的范围,这也是查询扩展的一项任务,在使用查询扩展时,MySQL对数据和索引进行两遍扫描来完成搜索:
- 首先:进行一个基本的全文本搜索,找出与搜索条件匹配的所有行‘
- 其次,MySQL检查这些匹配行并选择所有有用的词
- 再之后,MySQL再次进行全文本搜索,这次不仅使用原来的条件,而且还使用所有有用的词;
布尔文本搜索
mysql支持全文本搜索的另一种方式:称为布尔方式(boolean mode),以布尔方式。
- 要匹配的词
- 要排斥的词
- 排列的提升
- 表达式分组
- 另外一些内容
此全文本搜索检索包含词heavy的所有行,其中使用了关键字IN BOOLEAN MODE,实际上没有指定布尔操作符,因此结果和没有指定的是相同;

插入数据
数据插入
INSERT 是用来插入行到数据库表的,插入可以用几种方式使用:
- 插入完整的行
- 插入行的一部分
- 插入多行
- 插入某些查询的结果
插入完整的行
将数据插入表中最简单的方式是使用INSERT语法:要求指定表名和被插入到新行中的值:
INSERT INTO Customers
VALUES(NULL,
'Pep E. LaPew',
'100 Main Street',
'Los Angeles',
'CA',
'90046'
'USA'
NULL,
NULL);
INSERT语句一般不会产生输出,此语句是插入一个新客户到customers表中,存储到每个表列中的数据再VALUES子句中给出,对每个列必须提供一个值,上述的插入语句可能不够安全;
INSERT INTO customers(cust_name,
cust_address,
cust_city,
cust_state,
cust_zipe,
cust_country,
cust_contact,
cust_email)
VALUES(NULL,
'Pep E. LaPew',
'100 Main Street',
'Los Angeles',
'CA',
'90046'
'USA'
NULL,
NULL);
虽然完成的是相同的工作,但是略显繁琐;但是够安全;
插入多个列
INSERT可以插入一行到一个表中,如果想要插入多行呢?
可以使用多条INSERT语句,一次提交它们,每条语句用一个分号结束
INSERT INTO customers(cust_name,
cust_address,
cust_city,
cust_state,
cust_zipe,
cust_country,
)
VALUES(NULL,
'Pep E. LaPew',
'100 Main Street',
'Los Angeles',
'CA',
'90046'
'USA');
INSERT INTO customers(cust_name,
cust_address,
cust_city,
cust_state,
cust_zipe,
cust_country,
)
VALUES('M.martian',
'42 Galaxy way',
'New York',
'NY',
'11213',
'USA');
插入检索出的数据
INSERT 还存在另外一种形式,可以利用它将一条SELECT语句的结果插入表中,这检索所谓的INSERT SELECT,它是由INSERT语句和SELECT语句构成的;
INSERT INTO customers(cust_id,
cust_contact,
cust_email,
cuts_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country)
SELECT cust_id,
cust_cpmtact
cust_email,
cuts_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country)
FROM custenw;
使用INSERT SELECT 从custnew将数据导入其中;
更新和删除数据
更新数据
为了更新(修改)表中的数据,可以使用UPDATE语句
- 更新表中特定行
- 更新表中所有行
UPDATE customers
SET cust_email = '[email protected]'
WHERE cust_id=10005;
UPDATEE语句以where语句结束,高数MySQL更新到哪一行了;
删除数据
为了从一个表中删除数据,使用DELEATE语句,可以两种方式使用DELETE
从表中删除特定的行
从表中删除所有行
DELETE FROM customers,
WHERE cust_id=10006;
删掉customers表中,cust_id=10006中的数据;