Redis6学习笔记-第二章-Redis6的基本操作
阅读本专栏您需要具有以下基础:
1.了解Linux的基本命令
2.对SpringBoot有一定了解
3.具有一定的计算机网络相关知识
本专栏预计分为四个章节:
第一章:Redis6的介绍和环境搭建
第二章:Redis6的基本操作(五大数据类型、Redis6配置文件详解、Redis6发布和订阅模式、Redis6新数据类型、Jedis操作Redis6、Redis6与Springboot整合)
第三章:Redis6的提高部分(Redis6的事务,RDB、AOF持久化操作,Redis6的主从复制、Redis6集群)
第四章:Redis6的应用问题解决(缓存穿透、缓存击穿、缓存雪崩、分布式锁)
eg:本专栏的内容来自于尚硅谷的Redis6课程,经过学习后总结的笔记,部分图片来源于网络,如有侵权请联系我修改。后续会慢慢更新,建议订阅专栏
文章目录
- Redis6学习笔记-第二章-Redis6的基本操作
-
- 五、Redis的五大常用数据类型
-
- 1.Redis键操作(Key)
- 2.Redis字符串(String)
-
- 2.1添加K,V---set
- 2.2获取V值---get
- 2.3将给定的V值追加到原值的末尾---append
- 2.4获取V的长度---strlen
- 2.5只有在K不存在时,设置K的V---setnx
- 2.6将K中储存的V数字值增1---incr
- 2.7将K中储存的V数字值减1---decr
- 2.8将K中储存的V数字值自定义增减长度---incrby / decrby
- 2.9批量添加K,V---mset
- 2.10批量获取V值---mget
- 2.11只有在K不存在时,批量设置K的V---msetnx
- 2.12获得值的范围,类似java中的substring---getrange
- 2.13覆盖值的范围---setrange
- 2.14设置K,V的时候同时设置过期时间---setex
- 2.15设置新的V的时候获取到旧的V---getset
- 3.Redis列表(List)
- 4.Redis集合(set)
- 5.Redis哈希(Hash)
- 6.Redis有序集合(Zset)
-
- 6.1将一个或多个 member 元素及其 score 值加入到有序集 key 当中---zadd
- 6.2返回有序集 key 中,下标在开始和结束索引之间的元素,带上WITHSCORES,可以让分数一起和值返回到结果集---zrange
- 6.3返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列
- 6.4同上,改为从大到小排列
- 6.5为某个V的score加上增量---zincrby
- 6.6删除该集合下,指定的V元素---zrem
- 6.7统计分数区间内V的个数 ---zcount
- 6.8 返回该V在集合中的排名,从0开始---zrank
- 六、Redis配置文件详解
- 七、Redis的发布和订阅
- 八、Redis新数据类型
- 九、Jedis操作Redis6
- 十、SpringBoot整合Redis
- 十一、通过SpringBoot整合Redis实现一个验证码登录的功能---简单版本
五、Redis的五大常用数据类型
获得redis常见数据类型操作命令http://www.redis.cn/commands.html
Redis五大常用数据类型:
String—字符串
List—列表
Set—集合
Hash—哈希
Zset—有序集合
它们五个的应用场景
string的应用场景
普通的key-value键值对都可以用string来保存,
1,访问量统计,每次访问博客和文章的,都用intr命令加一
2,做缓存。
list的应用场景
作为队列,list的两端操作比较方便,所以可以用来一些需要获取最新数据的场景。比如新闻类应用的最新新闻。
hash的应用场景
用来储存,修改对象属性,如果说用户(name,age,like),文章(标题,time,作者,内容,),其中用户相当于key,而(name,age,;like)相当于vlaue
set的应用场景
1,好友推荐,根据set的内容交集,大于每个值就可以推荐,
2,利用set的唯一性,统计网站内容所有独立ip
zset的应用场景
排行榜,因为zset时有序的
互联网古斯一般用到数据里类型
String:缓存,限流,计数器,分布式锁,分布式Session
Hash:储存用户信息,用户主页访问量,组合查询
List:微博关注人时间轴列表,简单队列
Set:赞,踩,标签,好友关系
Zset:排行榜
1.Redis键操作(Key)
1.1设置三个kv值—set
案例:k1-lucy,k2-mary,k3-jack
127.0.0.1:6379> set k1 lucy
OK
127.0.0.1:6379> set k2 mary
OK
127.0.0.1:6379> set k3 jack
OK
1.2查看当前库所有key—keys *
查看当前所有key
127.0.0.1:6379> keys *
1) "k3"
2) "k1"
3) "k2"
匹配当前一个key
127.0.0.1:6379> keys *1
1) "k1"
1.3判断某个key是否存在—exists key
判断k1是否存在
127.0.0.1:6379> exists key k1
(integer) 1
判断k5是否存在
127.0.0.1:6379> exists key k5
(integer) 0
1.4查看key的类型—type key
查看k1的类型
127.0.0.1:6379> type k1
string
1.5删除指定的key数据—del key
删除k2
127.0.0.1:6379> del k2
(integer) 1
127.0.0.1:6379> keys *
1) "k3"
2) "k1"
1.6根据value选择非阻塞删除—unlink key
仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
删除k3
127.0.0.1:6379> unlink k3
(integer) 1
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
1.7为给定的key设置过期时间—expire key time(ttl)
为k1设置10秒过期时间
127.0.0.1:6379> expire k1 10
(integer) 1
ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
127.0.0.1:6379> expire k1 10
(integer) 1
127.0.0.1:6379> ttl k1
(integer) 3
127.0.0.1:6379> ttl k1
(integer) 0
127.0.0.1:6379> ttl k1
(integer) -2
1.8命令切换数据库—select
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]>
1.9查看当前数据库的key的数量—dbsize
127.0.0.1:6379> dbsize
(integer) 2
1.10flushdb清空当前库
1.11flushall通杀全部库
2.Redis字符串(String)
String是Redis最基本的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
数据结构:
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
2.1添加K,V—set
添加k1-v100,k2-v200
127.0.0.1:6379> set k1 v100
OK
127.0.0.1:6379> set k2 v200
OK
当重新设置k值的时候,会覆盖掉之前的v值
2.2获取V值—get
获取k1的v
127.0.0.1:6379> get k1
"v100"
2.3将给定的V值追加到原值的末尾—append
追加abc到k1的v的末尾
127.0.0.1:6379> append k1 abc
(integer) 7
127.0.0.1:6379> get k1
"v100abc"
2.4获取V的长度—strlen
获取k1的v的长度
127.0.0.1:6379> strlen k1
(integer) 7
2.5只有在K不存在时,设置K的V—setnx
设置k1的V为abc
127.0.0.1:6379> setnx k1 abc
(integer) 0
设置k3的V为v300
127.0.0.1:6379> setnx k3 v300
(integer) 1
127.0.0.1:6379> get k3
"v300"
2.6将K中储存的V数字值增1—incr
将k4的v 500增加为501
127.0.0.1:6379> set k4 500
OK
127.0.0.1:6379> incr k4
(integer) 501
127.0.0.1:6379> get k4
"501"
只能对数字值操作,如果为空,新增值为1
2.7将K中储存的V数字值减1—decr
将k4的v 501减少为500
127.0.0.1:6379> decr k4
(integer) 500
127.0.0.1:6379> get k4
"500"
2.8将K中储存的V数字值自定义增减长度—incrby / decrby
将k4的v 500增加100
将k4的v 600减少110
127.0.0.1:6379> incrby k4 100
(integer) 600
127.0.0.1:6379> decrby k4 110
(integer) 490
2.9批量添加K,V—mset
之前flushdb过一次
批量添加k1-v1 k2-v2 k3-v3
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
2.10批量获取V值—mget
批量获取v1 v2 v3
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
2.11只有在K不存在时,批量设置K的V—msetnx
批量添加k4-v4 k5-v5 k6-v6
127.0.0.1:6379> msetnx k4 v4 k5 v5 k6 v6
(integer) 1
127.0.0.1:6379> mget k4 k5 k6
1) "v4"
2) "v5"
3) "v6"
2.12获得值的范围,类似java中的substring—getrange
将name的v(lucymary)获取为lucy
127.0.0.1:6379> set name lucymary
OK
127.0.0.1:6379> getrange name 0 3
"lucy"
2.13覆盖值的范围—setrange
将name的v(lucymary)的覆盖为(luabcary)
127.0.0.1:6379> setrange name 2 abc
(integer) 8
127.0.0.1:6379> get name
"luabcary"
2.14设置K,V的时候同时设置过期时间—setex
设置一个k6 v6过期时间为10秒
127.0.0.1:6379> setex k6 10 v6
OK
127.0.0.1:6379> ttl k6
(integer) 7
127.0.0.1:6379> ttl k6
(integer) 0
127.0.0.1:6379> ttl k6
(integer) -2
2.15设置新的V的时候获取到旧的V—getset
获取到k5的旧v,并设置新的v为v500
127.0.0.1:6379> getset k5 v500
"v5"
127.0.0.1:6379> get k5
"v500"
3.Redis列表(List)
单键多值(一个K可以对应多个v,k-v1,v2,v3)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

数据结构:
List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表,它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist,因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

Redis将链表和ziplist结合起来组成了quicklist。
quicklist=链表+ziplist
-==也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
3.1从左边/右边插入一个或多个值—lpush/rpush
先flushdb了一次
从左边插入k1-v1 v2 v3
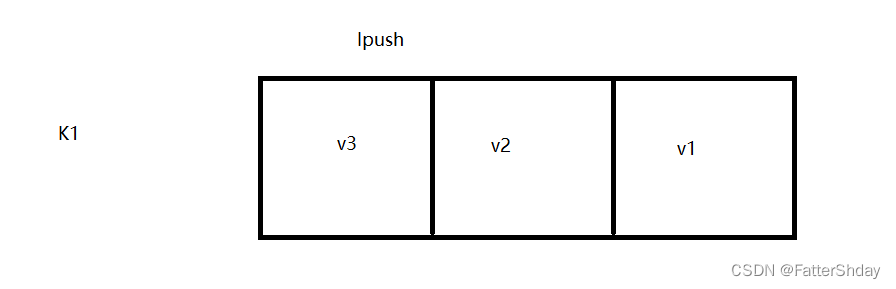
127.0.0.1:6379> lpush k1 v1 v2 v3
(integer) 3
127.0.0.1:6379> lrange k1 0 -1
1) "v3"
2) "v2"
3) "v1"
从右边插入k2-v1 v2 v3
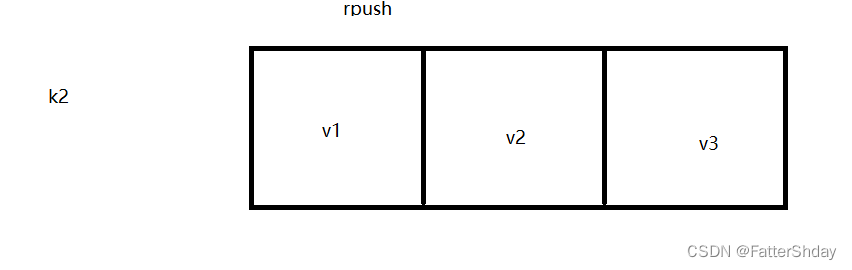
127.0.0.1:6379> rpush k2 v1 v2 v3
(integer) 3
127.0.0.1:6379> lrange k2 0 -1
1) "v1"
2) "v2"
3) "v3"
3.2按照索引下标获得元素(从左到右)—lrange
0左边第一个,-1右边第一个,(0-1表示获取所有)
获取k1的全部的V(0,-1是全部获取的意思)
127.0.0.1:6379> lrange k1 0 -1
1) "v3"
2) "v2"
3) "v1"
3.3从左边/右边吐出一个值。值在键在,值光键亡。—lpop/rpop
从左边吐出一个k1的V
127.0.0.1:6379> lpop k1
"v3"
127.0.0.1:6379> lrange k1 0 -1
1) "v2"
2) "v1"
从右边吐出一个k2的V
127.0.0.1:6379> rpop k2
"v3"
127.0.0.1:6379> lrange k2 0 -1
1) "v1"
2) "v2"
3.4从一个列表右边吐出一个值,插到另外一个列表左边—rpoplpush
k1-v3,v2,v1
k2-v11,v12,v13
127.0.0.1:6379> rpoplpush k1 k2
"v1"
127.0.0.1:6379> lrange k2 0 -1
1) "v1"
2) "v11"
3) "v12"
4) "v13"
3.5按照索引下标获得元素(从左到右,从0开始)—lindex
取出k2下标为3的元素
127.0.0.1:6379> lindex k2 3
"v13"
3.6获得列表长度—llen
获取k2的长度
127.0.0.1:6379> llen k2
(integer) 4
3.7在某个V的前面或者是后面插入一个值—linsert
在k2的v11前面插入一个newv11
127.0.0.1:6379> linsert k2 before "v11" "newv11"
(integer) 5
127.0.0.1:6379> lrange k2 0 -1
1) "v1"
2) "newv11"
3) "v11"
4) "v12"
5) "v13"
在k2的v13后面插入一个newv13
127.0.0.1:6379> linsert k2 after "v13" "newv13"
(integer) 6
127.0.0.1:6379> lrange k2 0 -1
1) "v1"
2) "newv11"
3) "v11"
4) "v12"
5) "v13"
6) "newv13"
3.8从左边删除n个value(从左到右)—lrem
删除k2(v1,newv11,v11,newv11,v12,v13,newv13)中前两个newv11
127.0.0.1:6379> lrem k2 2 newv11
(integer) 2
127.0.0.1:6379> lrange k2 0 -1
1) "v1"
2) "v11"
3) "v12"
4) "v13"
5) "newv13"
3.9将列表key下标为index的值替换成value—lset
将k2的第一个V(v1)替换为(changev1)
127.0.0.1:6379> lset k2 0 changev1
OK
127.0.0.1:6379> lrange k2 0 -1
1) "changev1"
2) "v11"
3) "v12"
4) "v13"
5) "newv13"
4.Redis集合(set)
单键多值(一个K可以对应多个v,k-v1,v2,v3)
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。添加,删除,查找的复杂度都是O(1)。一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变。
数据结构:
Set数据结构类似Java里面的Map<String,null>
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
4.1将一个或多个V元素加入到集合K中,已经存在的 member 元素将被忽略—sadd
添加k1-v1,v2,v3,v1四个元素
127.0.0.1:6379> sadd k1 v1 v2 v3 v1
(integer) 3
127.0.0.1:6379> smembers k1
1) "v1"
2) "v2"
3) "v3"
4.2取出该集合的所有的V—smembers
取出k1的所有V
127.0.0.1:6379> smembers k1
1) "v1"
2) "v2"
3) "v3"
4.3判断集合K是否为含有该V值,有1,没有0
判断k1中是否有v1元素和v4元素
127.0.0.1:6379> sismember k1 v1
(integer) 1
127.0.0.1:6379> sismember k1 v4
(integer) 0
4.4返回该集合的元素个数—scard
查看k1中的元素个数
127.0.0.1:6379> scard k1
(integer) 3
4.5删除集合中的某个元素—srem
指定删除k1中v1,v2元素
127.0.0.1:6379> srem k1 v1 v2
(integer) 2
127.0.0.1:6379> smembers k1
1) "v3"
4.6随机从该集合中吐出一个值—spop
新建一个k2-v1,v2,v3,v4,随机吐出v1,v2,v3,v4
当集合中的元素pop完了,该K也就不存在了
127.0.0.1:6379> spop k2
"v3"
127.0.0.1:6379> spop k2
"v4"
127.0.0.1:6379> smembers k2
1) "v1"
2) "v2"
127.0.0.1:6379> exists k2
(integer) 0
127.0.0.1:6379> spop k2
"v2"
127.0.0.1:6379> spop k2
"v1"
127.0.0.1:6379> exists k2
(integer) 0
4.7 随机从该集合中取出n个值。不会从集合中删除 —srandmember
新建一个k3-v1,v2,v3,v4,随机取出两个v
127.0.0.1:6379> srandmember k3 2
1) "v1"
2) "v3"
127.0.0.1:6379> srandmember k3 2
1) "v4"
2) "v3"
127.0.0.1:6379> srandmember k3 2
1) "v2"
2) "v4"
4.8value把集合中一个值从一个集合移动到另一个集合—smove
为了测试方便,先flushdb了一次
重新加入了k3-v1,v2,v3和k4-v4,v5,v6
把k3中的v3移动到k4中
127.0.0.1:6379> smove k3 k4 v3
(integer) 1
127.0.0.1:6379> smembers k3
1) "v2"
2) "v1"
127.0.0.1:6379> smembers k4
1) "v3"
2) "v5"
3) "v6"
4) "v4"
4.9返回两个集合的交集/并集/差集元素—sinter/sunion/sdiff
返回k1和k2的交集元素
127.0.0.1:6379> sinter k1 k2
(empty array)
返回k1和k2的并集元素
127.0.0.1:6379> sunion k1 k2
1) "v5"
2) "v2"
3) "v4"
4) "v3"
5) "v1"
6) "v6"
返回k1和k2的差集元素(k1中有的,k2中没有的)
127.0.0.1:6379> sdiff k1 k2
1) "v1"
2) "v2"
127.0.0.1:6379> sdiff k2 k1
1) "v6"
2) "v5"
3) "v4"
4) "v3"
5.Redis哈希(Hash)
Redis hash 是一个键值对集合。
Redis hash是一个String类型的field和value的映射表,hash特别适合用于存储对象。V类似Java里面的Map<String,Object>
数据结构:
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
比如:
现在要存储一个{id=1,name=zhangsan,age=20}的一个user对象
主要有以下2种存储方式:
第一种用String存取:
直接把user当成K,{id=1,name=zhangsan,age=20}当成V
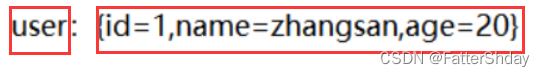
缺点:如果我想把age的值改为21,我要把V取出来->把V转化成JSON->把JSON转化为Java对象,修改以后再把Java对象转化为JSON->JSON转化为V->把V再放回Redis中,非常的麻烦
第二种用Hash存取:
直接把user当成K,field和value当成V

优点:修改V中的值非常方便,比如还是想把age的值改为21,直接可以拿到V中的age的field,然后修改即可
5.1给K中的V的field的value赋值—hset
先进行了一次flushdb操作
给K=user01,field=id的value赋值为10,field=name的value赋值为zhangsan
127.0.0.1:6379> hset user01 id 10
(integer) 1
127.0.0.1:6379> hset user01 name zhangsan
(integer) 1
127.0.0.1:6379> hget user01 id
"10"
127.0.0.1:6379> hget user01 name
"zhangsan"
5.2取出K中的V的field的value值—hget
取出K=user01,field=id的value的值,field=name的value的值
127.0.0.1:6379> hget user01 id
"10"
127.0.0.1:6379> hget user01 name
"zhangsan"
5.3批量给K中的V的field的value赋值—hmset
给K=user02,field=id的value赋值为2,field=name的value赋值为lisi,field=nage的value赋值为30
127.0.0.1:6379> hmset user02 id 2 name lisi age 30
OK
127.0.0.1:6379> hget user02 id
"2"
127.0.0.1:6379> hget user02 name
"lisi"
127.0.0.1:6379> hget user02 age
"30"
5.4查看V中,给定域 field 是否存在—hexists
查看user01中是否有id这个field
127.0.0.1:6379> hexists user01 id
(integer) 1
查看user01中是否有age这个field
127.0.0.1:6379> hexists user01 age
(integer) 0
5.5列出该V的所有field—hkeys
列出user02的所有field
127.0.0.1:6379> hkeys user02
1) "id"
2) "name"
3) "age"
5.6列出该V的所有value—hvals
列出user02的所有value
127.0.0.1:6379> hvals user02
1) "2"
2) "lisi"
3) "30"
5.7为V中的域 field 的值加上增量n —hincrby
给user02中的field=age的value=30增加为32
127.0.0.1:6379> hincrby user02 age 2
(integer) 32
127.0.0.1:6379> hget user02 age
"32"
5.8给V中添加指定field并且设置value值,如果field已存在就不能设置—hsetnx
给user02添加指定field=age,value=40
127.0.0.1:6379> hsetnx user02 age 40
(integer) 0
给user02添加指定field=gender,value=1
127.0.0.1:6379> hsetnx user02 gender 1
(integer) 1
查看效果
127.0.0.1:6379> hkeys user02
1) "id"
2) "name"
3) "age"
4) "gender"
127.0.0.1:6379> hvals user02
1) "2"
2) "lisi"
3) "32"
4) "1"
6.Redis有序集合(Zset)
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score) 这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
数据结构:
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构:
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表,其实就是一种可以进行二分查找的有序链表。
跳跃表: 有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
说明:
2、实例
对比有序链表和跳跃表,从链表中查询出51
(1) 有序链表

要查找值为16的元素,需要从第一个元素开始依次查找、比较才能找到。共需要10次比较。时间复杂度为O(n)
(2) 跳跃表
那么我们如何提高查找效率呢?我们可以对链表建立一级“索引”,每两个结点提取一个结点到上一级,我们把抽取出来的那一级叫做索引或者索引层,如下图所示,down表示down指针。时间复杂度为O(m*logn),空间复杂度为O(n)
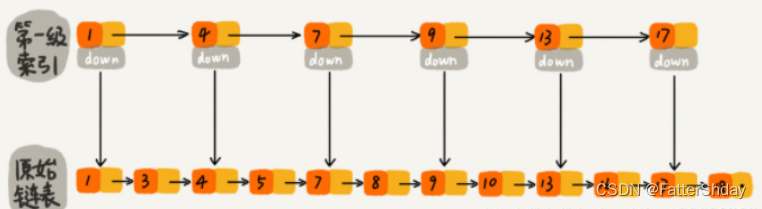
假设我们现在要查找值为16的这个结点。我们可以先在索引层遍历,当遍历索引层中值为13的时候,通过值为13的结点的指针域发现下一个结点值为17,因为链表本身有序,所以值为16的结点肯定在13和17这两个结点之间。然后我们通过索引层结点的down指针,下降到原始链表这一层,继续往后遍历查找。这个时候我们只需要遍历2个结点(值为13和16的结点),就可以找到值等于16的这个结点了。如果使用原来的链表方式进行查找值为16的结点,则需要遍历10个结点才能找到,而现在只需要遍历7个结点即可,从而提高了查找效率。
那么我们可以由此得到启发,和上面建立第一级索引的方式相似,在第一级索引的基础上,每两个一级索引结点就抽到一个结点到第二级索引中。再来查找值为16的结点,只需要遍历6个结点即可,从而进一步提高了查找效率。这次只需要遍历6次
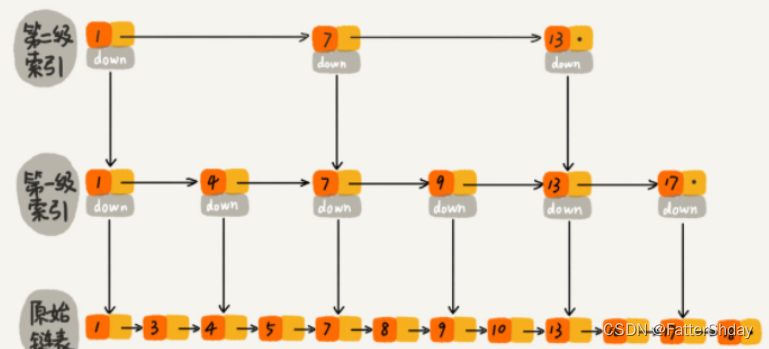
如果当链表的长度为10000、10000000时,通过构件索引之后,查找的效率就会提升的非常明显。
6.1将一个或多个 member 元素及其 score 值加入到有序集 key 当中—zadd
为了测试顺利,先flushdb了一次
添加了一个topn-java(200),c++(300),mysql(400),php(500)
127.0.0.1:6379> zadd topn 200 java 300 c++ 400 mysql 500 php
(integer) 4
127.0.0.1:6379> zrange topn 0 -1 withscores
1) "java"
2) "200"
3) "c++"
4) "300"
5) "mysql"
6) "400"
7) "php"
8) "500"
6.2返回有序集 key 中,下标在开始和结束索引之间的元素,带上WITHSCORES,可以让分数一起和值返回到结果集—zrange
查看topn中所有的V,并且带上评分(有序集成员按 score 值递增(从小到大)次序排列)
127.0.0.1:6379> zrange topn 0 -1 withscores
1) "java"
2) "200"
3) "c++"
4) "300"
5) "mysql"
6) "400"
7) "php"
8) "500"
6.3返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列
查看topn在300-500评分中所有的V
127.0.0.1:6379> zrangebyscore topn 300 500 withscores
1) "c++"
2) "300"
3) "mysql"
4) "400"
5) "php"
6) "500"
6.4同上,改为从大到小排列
查看topn在300-500评分中所有的V,倒序排列
127.0.0.1:6379> zrevrangebyscore topn 500 300 withscores
1) "php"
2) "500"
3) "mysql"
4) "400"
5) "c++"
6) "300"
6.5为某个V的score加上增量—zincrby
把java(200)增加为java(250)
127.0.0.1:6379> zincrby topn 50 java
"250"
127.0.0.1:6379> zrange topn 0 -1 withscores
1) "java"
2) "250"
3) "c++"
4) "300"
5) "mysql"
6) "400"
7) "php"
8) "500"
6.6删除该集合下,指定的V元素—zrem
删除V的php
127.0.0.1:6379> zrem topn php
(integer) 1
127.0.0.1:6379> zrange topn 0 -1 withscores
1) "java"
2) "250"
3) "c++"
4) "300"
5) "mysql"
6) "400"
6.7统计分数区间内V的个数 —zcount
统计topn中200-400的元素个数
127.0.0.1:6379> zcount topn 200 400
(integer) 3
6.8 返回该V在集合中的排名,从0开始—zrank
查看java在集合中的排名
127.0.0.1:6379> zrank topn java
(integer) 0
查看mysql在集合中的排名
127.0.0.1:6379> zrank topn mysql
(integer) 2
六、Redis配置文件详解
首先查看我们的redis.conf文件,我之前备份过一次redis.conf文件到/etc目录下,所以我打开的命令是
[root@centos100 ~]#less /etc/redis.conf
然后依次解读配置文件中的具体包含了什么内容
1.文件开头
配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit对大小写不敏感。
# Redis configuration file example.
#
# Note that in order to read the configuration file, Redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
2.### INCLUDES
类似jsp中的include,多实例的情况可以把公用的配置文件提取出来,比如这里就是把/path/to/local.conf,/path/to/other.conf里面的内容引入到了redis.conf文件
################################## INCLUDES ###################################
# Include one or more other config files here. This is useful if you
# have a standard template that goes to all Redis servers but also need
# to customize a few per-server settings. Include files can include
# other files, so use this wisely.
#
# Note that option "include" won't be rewritten by command "CONFIG REWRITE"
# from admin or Redis Sentinel. Since Redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
3.### NETWORK
################################## NETWORK #####################################
#默认情况bind=127.0.0.1只能接受本机的访问请求
#如果把它注释或者是删除掉那么就能够无限制地接受任何ip地址的访问
bind 127.0.0.1 -::1
#开启保护模式,yes=只允许本机访问不允许远程访问
protected-mode yes
#默认的Redis端口号
port 6379
#设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列。
#在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。
#注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn#和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果
tcp-backlog 511
#一个空闲的客户端维持多少秒会关闭,0表示关闭该功能。即永不关闭。
timeout 0
#单位:秒,默认是300;客户端与服务器端如果没有任何数据交互,多少秒会进行一次ping,pong 交互,主要是考虑客户端是不是假死,网络等断开情况
tcp-keepalive 300
4.### GENERAL
################################# GENERAL #####################################
#是否为后台进程,设置为yes为是守护进程,后台启动
daemonize yes
#存放pid文件的位置,每个实例会产生一个不同的pid文件,保存进程号
pidfile /var/run/redis_6379.pid
#指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice
#四个级别根据使用阶段来选择,生产环境选择notice 或者warning
loglevel notice
#指定日志文件名。也可以使用空字符串强制
logfile ""
# To enable logging to the system logger, just set 'syslog-enabled' to yes,
# and optionally update the other syslog parameters to suit your needs.
# syslog-enabled no
# Specify the syslog identity.
# syslog-ident redis
# Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7.
# syslog-facility local0
# To disable the built in crash log, which will possibly produce cleaner core
# dumps when they are needed, uncomment the following:
#
# crash-log-enabled no
# To disable the fast memory check that's run as part of the crash log, which
# will possibly let redis terminate sooner, uncomment the following:
#
# crash-memcheck-enabled no
#设定库的数量 默认16,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
databases 16
# By default Redis shows an ASCII art logo only when started to log to the
# standard output and if the standard output is a TTY and syslog logging is
# disabled. Basically this means that normally a logo is displayed only in
# interactive sessions.
#
# However it is possible to force the pre-4.0 behavior and always show a
# ASCII art logo in startup logs by setting the following option to yes.
always-show-logo no
# By default, Redis modifies the process title (as seen in 'top' and 'ps') to
# provide some runtime information. It is possible to disable this and leave
# the process name as executed by setting the following to no.
set-proc-title yes
# When changing the process title, Redis uses the following template to construct
# the modified title.
#
# Template variables are specified in curly brackets. The following variables are
# supported:
#
# {title} Name of process as executed if parent, or type of child process.
# {listen-addr} Bind address or '*' followed by TCP or TLS port listening on, or
# Unix socket if only that's available.
# {server-mode} Special mode, i.e. "[sentinel]" or "[cluster]".
# {port} TCP port listening on, or 0.
# {tls-port} TLS port listening on, or 0.
# {unixsocket} Unix domain socket listening on, or "".
# {config-file} Name of configuration file used.
#
proc-title-template "{title} {listen-addr} {server-mode}"
5.### SECURITY
################################## SECURITY ###################################
# Warning: since Redis is pretty fast, an outside user can try up to
# 1 million passwords per second against a modern box. This means that you
# should use very strong passwords, otherwise they will be very easy to break.
# Note that because the password is really a shared secret between the client
# and the server, and should not be memorized by any human, the password
# can be easily a long string from /dev/urandom or whatever, so by using a
# long and unguessable password no brute force attack will be possible.
# Redis ACL users are defined in the following format:
#
# user <username> ... acl rules ...
#
# For example:
#
# user worker +@list +@connection ~jobs:* on >ffa9203c493aa99
#
# The special username "default" is used for new connections. If this user
# has the "nopass" rule, then new connections will be immediately authenticated
# as the "default" user without the need of any password provided via the
# AUTH command. Otherwise if the "default" user is not flagged with "nopass"
# the connections will start in not authenticated state, and will require
# AUTH (or the HELLO command AUTH option) in order to be authenticated and
# start to work.
#
# The ACL rules that describe what a user can do are the following:
#
# on Enable the user: it is possible to authenticate as this user.
# off Disable the user: it's no longer possible to authenticate
# with this user, however the already authenticated connections
# will still work.
# skip-sanitize-payload RESTORE dump-payload sanitation is skipped.
# sanitize-payload RESTORE dump-payload is sanitized (default).
# +<command> Allow the execution of that command
# -<command> Disallow the execution of that command
# +@<category> Allow the execution of all the commands in such category
# with valid categories are like @admin, @set, @sortedset, ...
# and so forth, see the full list in the server.c file where
# the Redis command table is described and defined.
# The special category @all means all the commands, but currently
# present in the server, and that will be loaded in the future
# via modules.
# +<command>|subcommand Allow a specific subcommand of an otherwise
# disabled command. Note that this form is not
# allowed as negative like -DEBUG|SEGFAULT, but
# only additive starting with "+".
# allcommands Alias for +@all. Note that it implies the ability to execute
# all the future commands loaded via the modules system.
# nocommands Alias for -@all.
# ~<pattern> Add a pattern of keys that can be mentioned as part of
# commands. For instance ~* allows all the keys. The pattern
# is a glob-style pattern like the one of KEYS.
# It is possible to specify multiple patterns.
# allkeys Alias for ~*
# resetkeys Flush the list of allowed keys patterns.
# &<pattern> Add a glob-style pattern of Pub/Sub channels that can be
# accessed by the user. It is possible to specify multiple channel
# patterns.
# allchannels Alias for &*
# resetchannels Flush the list of allowed channel patterns.
# ><password> Add this password to the list of valid password for the user.
# For example >mypass will add "mypass" to the list.
# This directive clears the "nopass" flag (see later).
# <<password> Remove this password from the list of valid passwords.
# nopass All the set passwords of the user are removed, and the user
# is flagged as requiring no password: it means that every
# password will work against this user. If this directive is
# used for the default user, every new connection will be
# immediately authenticated with the default user without
# any explicit AUTH command required. Note that the "resetpass"
# directive will clear this condition.
# resetpass Flush the list of allowed passwords. Moreover removes the
# "nopass" status. After "resetpass" the user has no associated
# passwords and there is no way to authenticate without adding
# some password (or setting it as "nopass" later).
# reset Performs the following actions: resetpass, resetkeys, off,
# -@all. The user returns to the same state it has immediately
# after its creation.
#
# ACL rules can be specified in any order: for instance you can start with
# passwords, then flags, or key patterns. However note that the additive
# and subtractive rules will CHANGE MEANING depending on the ordering.
# For instance see the following example:
#
# user alice on +@all -DEBUG ~* >somepassword
#
# This will allow "alice" to use all the commands with the exception of the
# DEBUG command, since +@all added all the commands to the set of the commands
# alice can use, and later DEBUG was removed. However if we invert the order
# of two ACL rules the result will be different:
#
# user alice on -DEBUG +@all ~* >somepassword
#
# Now DEBUG was removed when alice had yet no commands in the set of allowed
# commands, later all the commands are added, so the user will be able to
# execute everything.
#
# Basically ACL rules are processed left-to-right.
#
# For more information about ACL configuration please refer to
# the Redis web site at https://redis.io/topics/acl
# ACL LOG
#
# The ACL Log tracks failed commands and authentication events associated
# with ACLs. The ACL Log is useful to troubleshoot failed commands blocked
# by ACLs. The ACL Log is stored in memory. You can reclaim memory with
# ACL LOG RESET. Define the maximum entry length of the ACL Log below.
acllog-max-len 128
# Using an external ACL file
#
# Instead of configuring users here in this file, it is possible to use
# a stand-alone file just listing users. The two methods cannot be mixed:
# if you configure users here and at the same time you activate the external
# ACL file, the server will refuse to start.
#
# The format of the external ACL user file is exactly the same as the
# format that is used inside redis.conf to describe users.
#
# aclfile /etc/redis/users.acl
#密码的设置,需要把这个注释打开
# requirepass foobared
# New users are initialized with restrictive permissions by default, via the
# equivalent of this ACL rule 'off resetkeys -@all'. Starting with Redis 6.2, it
# is possible to manage access to Pub/Sub channels with ACL rules as well. The
# default Pub/Sub channels permission if new users is controlled by the
# acl-pubsub-default configuration directive, which accepts one of these values:
#
# allchannels: grants access to all Pub/Sub channels
# resetchannels: revokes access to all Pub/Sub channels
#
# To ensure backward compatibility while upgrading Redis 6.0, acl-pubsub-default
# defaults to the 'allchannels' permission.
#
# Future compatibility note: it is very likely that in a future version of Redis
# the directive's default of 'allchannels' will be changed to 'resetchannels' in
# order to provide better out-of-the-box Pub/Sub security. Therefore, it is
# recommended that you explicitly define Pub/Sub permissions for all users
# rather then rely on implicit default values. Once you've set explicit
# Pub/Sub for all existing users, you should uncomment the following line.
#
# acl-pubsub-default resetchannels
# Command renaming (DEPRECATED).
#
# ------------------------------------------------------------------------
# WARNING: avoid using this option if possible. Instead use ACLs to remove
# commands from the default user, and put them only in some admin user you
# create for administrative purposes.
# ------------------------------------------------------------------------
#
# It is possible to change the name of dangerous commands in a shared
# environment. For instance the CONFIG command may be renamed into something
# hard to guess so that it will still be available for internal-use tools
# but not available for general clients.
#
# Example:
#
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
#
# It is also possible to completely kill a command by renaming it into
# an empty string:
#
# rename-command CONFIG ""
#
# Please note that changing the name of commands that are logged into the
# AOF file or transmitted to replicas may cause problems.
6.### CLIENTS
################################### CLIENTS ####################################
#设置redis同时可以与多少个客户端进行连接。默认情况下为10000个客户端。
#如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。
# maxclients 10000
7.### MEMORY MANAGEMENT
############################## MEMORY MANAGEMENT ################################
#建议必须设置,否则,将内存占满,造成服务器宕机
#设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。
#如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
#但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明你的redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。
# maxmemory <bytes>
#volatile-lru:使用LRU算法移除key,只对设置了过期时间的键;(最近最少使用)
#allkeys-lru:在所有集合key中,使用LRU算法移除key
#volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
#allkeys-random:在所有集合key中,移除随机的key
#volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
#noeviction:不进行移除。针对写操作,只是返回错误信息
# maxmemory-policy noeviction
#设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个。
#一般设置3到7的数字,数值越小样本越不准确,但性能消耗越小。
# maxmemory-samples 5
# Eviction processing is designed to function well with the default setting.
# If there is an unusually large amount of write traffic, this value may need to
# be increased. Decreasing this value may reduce latency at the risk of
# eviction processing effectiveness
# 0 = minimum latency, 10 = default, 100 = process without regard to latency
#
# maxmemory-eviction-tenacity 10
# Starting from Redis 5, by default a replica will ignore its maxmemory setting
# (unless it is promoted to master after a failover or manually). It means
# that the eviction of keys will be just handled by the master, sending the
# DEL commands to the replica as keys evict in the master side.
#
# This behavior ensures that masters and replicas stay consistent, and is usually
# what you want, however if your replica is writable, or you want the replica
# to have a different memory setting, and you are sure all the writes performed
# to the replica are idempotent, then you may change this default (but be sure
# to understand what you are doing).
#
# Note that since the replica by default does not evict, it may end using more
# memory than the one set via maxmemory (there are certain buffers that may
# be larger on the replica, or data structures may sometimes take more memory
# and so forth). So make sure you monitor your replicas and make sure they
# have enough memory to never hit a real out-of-memory condition before the
# master hits the configured maxmemory setting.
#
# replica-ignore-maxmemory yes
# Redis reclaims expired keys in two ways: upon access when those keys are
# found to be expired, and also in background, in what is called the
# "active expire key". The key space is slowly and interactively scanned
# looking for expired keys to reclaim, so that it is possible to free memory
# of keys that are expired and will never be accessed again in a short time.
#
# The default effort of the expire cycle will try to avoid having more than
# ten percent of expired keys still in memory, and will try to avoid consuming
# more than 25% of total memory and to add latency to the system. However
# it is possible to increase the expire "effort" that is normally set to
# "1", to a greater value, up to the value "10". At its maximum value the
# system will use more CPU, longer cycles (and technically may introduce
# more latency), and will tolerate less already expired keys still present
# in the system. It's a tradeoff between memory, CPU and latency.
#
# active-expire-effort 1
8.### SNAPSHOTTING
################################ SNAPSHOTTING ################################
#进行快照时候的一些配置
#格式:save 秒钟 写操作次数
#RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件,
#默认是1分钟内改了1万次,或5分钟内改了100次,或15分钟内改了1次。
#禁用
#不设置save指令,或者给save传入空字符串
# save ""
#如果Redis无法写入磁盘了,直接关掉Redis的写操作,默认是yes
stop-writes-on-bgsave-error yes
#对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。
#如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。推荐yes.
rdbcompression yes
#在存储快照后,还可以让redis使用CRC64算法来进行数据校验,
#但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。推荐yes。
rdbchecksum yes
# Enables or disables full sanitation checks for ziplist and listpack etc when
# loading an RDB or RESTORE payload. This reduces the chances of a assertion or
# crash later on while processing commands.
# Options:
# no - Never perform full sanitation
# yes - Always perform full sanitation
# clients - Perform full sanitation only for user connections.
# Excludes: RDB files, RESTORE commands received from the master
# connection, and client connections which have the
# skip-sanitize-payload ACL flag.
# The default should be 'clients' but since it currently affects cluster
# resharding via MIGRATE, it is temporarily set to 'no' by default.
#
# sanitize-dump-payload no
# 进入RDB操作后生成的文件名字
dbfilename dump.rdb
# Remove RDB files used by replication in instances without persistence
# enabled. By default this option is disabled, however there are environments
# where for regulations or other security concerns, RDB files persisted on
# disk by masters in order to feed replicas, or stored on disk by replicas
# in order to load them for the initial synchronization, should be deleted
# ASAP. Note that this option ONLY WORKS in instances that have both AOF
# and RDB persistence disabled, otherwise is completely ignored.
#
# An alternative (and sometimes better) way to obtain the same effect is
# to use diskless replication on both master and replicas instances. However
# in the case of replicas, diskless is not always an option.
rdb-del-sync-files no
#在哪个路径生成的rdb文件,下面是在我们当前启动目录的时候的生成位置
dir ./
9.### APPEND ONLY MODE
############################## APPEND ONLY MODE ###############################
#开启AOF,默认为,NO开启为YES
appendonly no
# 生成的AOF文件名
appendfilename "appendonly.aof"
#始终同步,每次Redis的写入都会立刻记入日志;性能较差但数据完整性比较好
#appendfsync always
#每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
#appendfsync everysec
#redis不主动进行同步,把同步时机交给操作系统。
#appendfsync no
# When the AOF fsync policy is set to always or everysec, and a background
# saving process (a background save or AOF log background rewriting) is
# performing a lot of I/O against the disk, in some Linux configurations
# Redis may block too long on the fsync() call. Note that there is no fix for
# this currently, as even performing fsync in a different thread will block
# our synchronous write(2) call.
#
# In order to mitigate this problem it's possible to use the following option
# that will prevent fsync() from being called in the main process while a
# BGSAVE or BGREWRITEAOF is in progress.
#
# This means that while another child is saving, the durability of Redis is
# the same as "appendfsync none". In practical terms, this means that it is
# possible to lose up to 30 seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
no-appendfsync-on-rewrite no
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# An AOF file may be found to be truncated at the end during the Redis
# startup process, when the AOF data gets loaded back into memory.
# This may happen when the system where Redis is running
# crashes, especially when an ext4 filesystem is mounted without the
# data=ordered option (however this can't happen when Redis itself
# crashes or aborts but the operating system still works correctly).
#
# Redis can either exit with an error when this happens, or load as much
# data as possible (the default now) and start if the AOF file is found
# to be truncated at the end. The following option controls this behavior.
#
# If aof-load-truncated is set to yes, a truncated AOF file is loaded and
# the Redis server starts emitting a log to inform the user of the event.
# Otherwise if the option is set to no, the server aborts with an error
# and refuses to start. When the option is set to no, the user requires
# to fix the AOF file using the "redis-check-aof" utility before to restart
# the server.
#
# Note that if the AOF file will be found to be corrupted in the middle
# the server will still exit with an error. This option only applies when
# Redis will try to read more data from the AOF file but not enough bytes
# will be found.
aof-load-truncated yes
# When rewriting the AOF file, Redis is able to use an RDB preamble in the
# AOF file for faster rewrites and recoveries. When this option is turned
# on the rewritten AOF file is composed of two different stanzas:
#
# [RDB file][AOF tail]
#
# When loading, Redis recognizes that the AOF file starts with the "REDIS"
# string and loads the prefixed RDB file, then continues loading the AOF
# tail.
aof-use-rdb-preamble yes
七、Redis的发布和订阅
1.发布和订阅
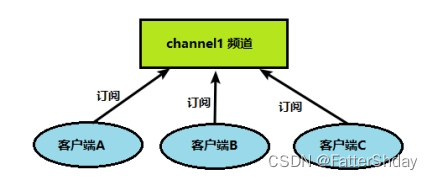
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息,类似于设计模式中的观察者模式。
Redis 客户端可以订阅任意数量的频道。
客户端可以订阅频道如下图
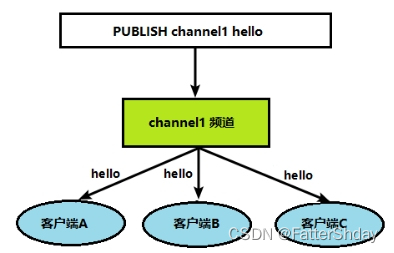
当给这个频道发布消息后,消息就会发送给订阅的客户端
2.发布订阅命令行实现
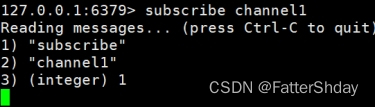
2.1打开一个客户端订阅channel1
SUBSCRIBE channel1
2.2打开另一个客户端,给channel1发布消息hello
publish channel1 hello

返回的1是订阅者数量
2.3打开第一个客户端可以看到发送的消息
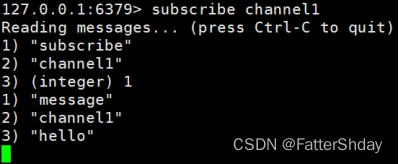
注:发布的消息没有持久化,如果在订阅的客户端收不到hello,只能收到订阅后发布的消息
八、Redis新数据类型
1.Bitmaps
1.1简介
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如下图