文件解析的终极工具:Apache Tika
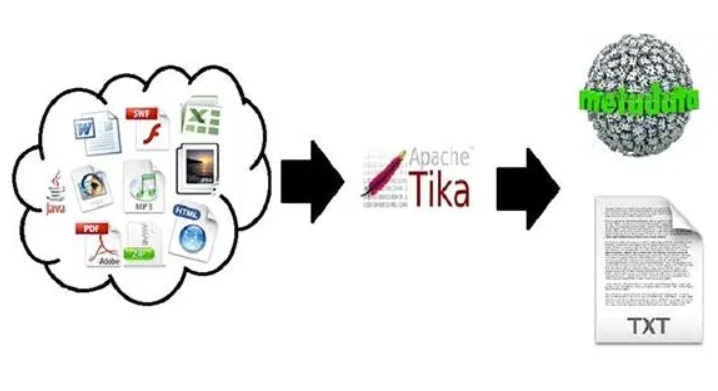
Apache Tika 简介
Apache Tika 是一个开源的、跨平台的库,用于检测、提取和解析各种类型文件的元数据。
它支持多种文件格式,包括文档、图片、音频和视频。
Tika是一个底层库,经常用于搜索引擎、内容管理系统、数据分析任务等领域,无缝地集成到其他应用或服务中以增强对文件内容处理的能力。
Apache Tika 主要特性
跨平台:Tika 可以在多种操作系统上运行,包括 Windows、Linux 和 Mac OS。
支持多种格式:Tika 支持多种文件格式,包括常见的文档、图片、音频和视频格式。
可扩展性:Tika 的设计是模块化的,允许开发者添加新的解析器来支持新的文件格式。
安全性:Tika 提供了防止文件注入攻击的机制,确保在处理用户上传的文件时保持安全性。
Apache Tika 应用场景
文档管理:Tika 可以用于提取文档中的元数据,如标题、作者和关键词,以便进行文档分类和检索。
安全审计:Tika 可以用于检测潜在的恶意文件,如宏病毒或恶意脚本,以防止安全威胁。
内容分析:Tika 可以用于提取文件内容,以便进行文本分析、情感分析或自然语言处理。
Apache Tika 架构组件
Parser(解析器):用于解析文档内容。
Fetcher(抓取器):用于从网络抓取文档。
Detector(检测器):用于确定文档的类型和元数据。
Tokenizer(标记器):用于将文本分解为标记(如词)。
Language Detector(语言检测器):用于确定文本的语言。
Metadata Extractor(元数据提取器):用于从文档中抽取元数据。
使用案例
Tika图形操作界面下载
https://mirrors.tuna.tsinghua.edu.cn/apache/tika/2.9.2/tika-app-2.9.2.jar
运行
java -jar tika-app-2.9.2.jar
如下图
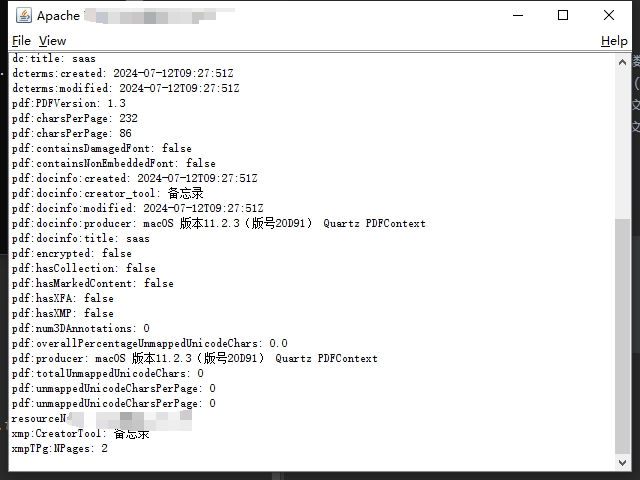
使用方式非常的简单,将文件拖入即可,如下图
使用Maven安装依赖
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>1.24</version>
</dependency>
java的案例代码
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class TikaExample {
public static void main(String[] args) throws IOException, TikaException, SAXException {
// 创建一个内容处理器和一个元数据实例
Handler handler = new Handler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.docx"));
ParseContext parsecontext = new ParseContext();
// 自动检测文档类型(探测器的工作)
Parser parser = new AutoDetectParser();
// 解析文档并提取内容和元数据
parser.parse(inputstream, handler, metadata, parsecontext);
// 打印文档内容
System.out.println("Contents of the document:" + handler.toString());
// 打印元数据信息
String[] metadataNames = metadata.names();
for (String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
// 关闭输入流
inputstream.close();
}
}
总结
Apache Tika 是一个功能丰富的文档解析工具,专门用于提取和分析多种文件类型的内容。
它广泛应用于搜索引擎的资料整理、内容管理系统的内容提取以及数据分析等领域。
– 欢迎点赞、关注、转发、收藏【我码玄黄】,gonghao同名