搭建deepseek
安装Ollama
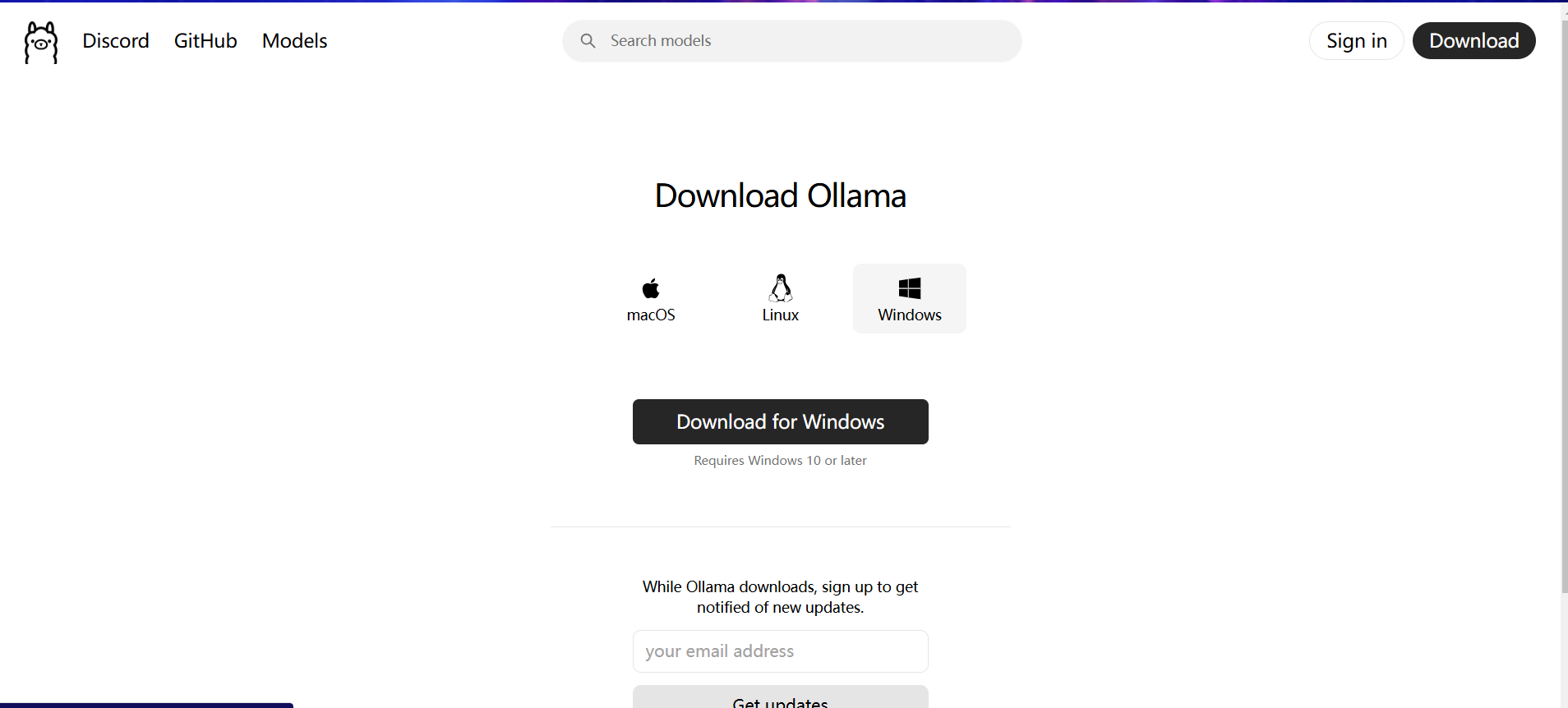
下载完成后双击打开Ollama进行安装,点击install
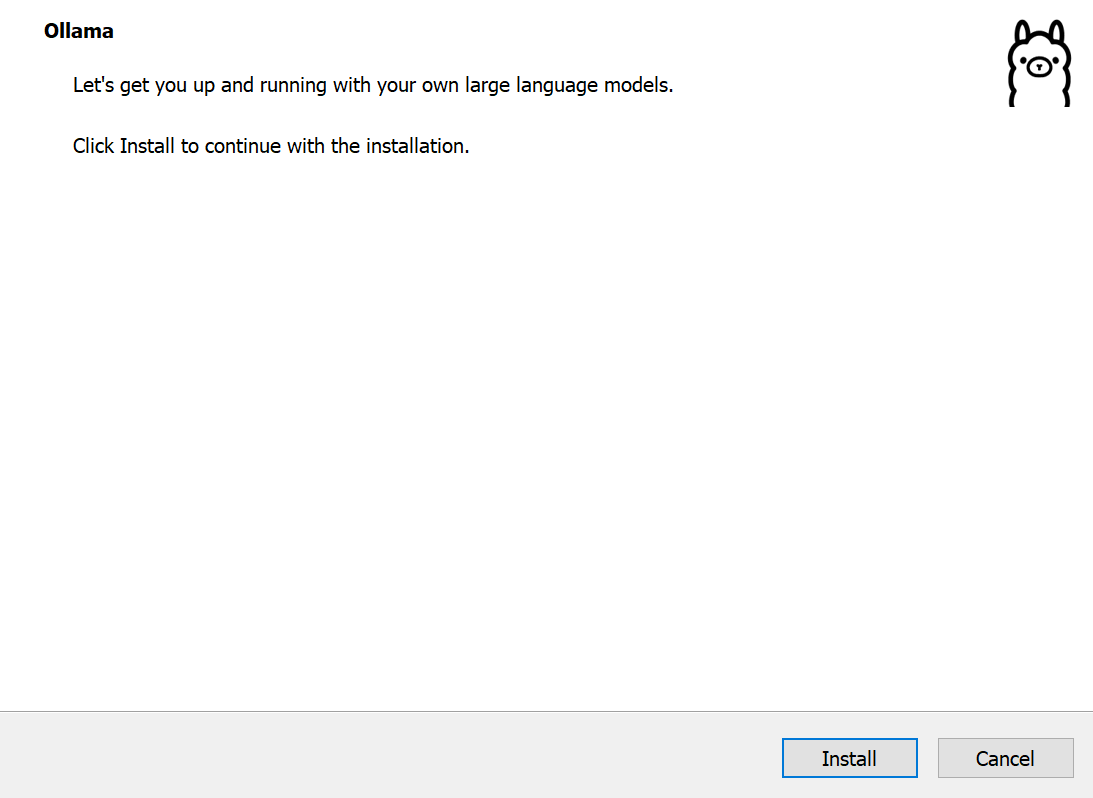
安装完成后系统会弹出下图提示代表安装成功并且已启动
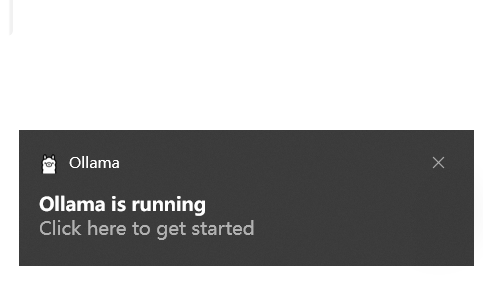
验证安装
ollama -v
安装完成后,cmd 打开命令行窗口,输入 “ollama -v” 测试,显示 ollama 的版本为 “0.5.7”,表明安装成功。
Ollama 没有用户界面,在后台运行。
打开浏览器,输入 “http://localhost:11434/”,显示 “Ollama is running”。

Ollma 安装 deepseek-r1 模型
deepseek-r1 模型介绍
从 ollama 官网 查找 deepseek-r1 模型。
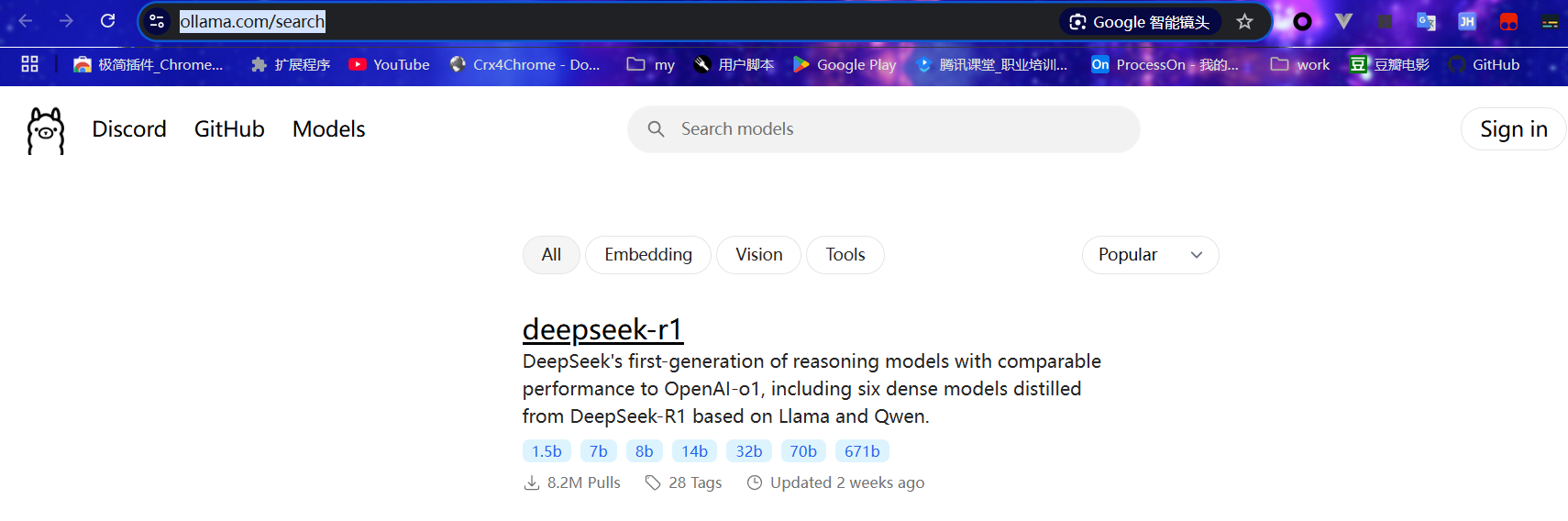
DeepSeek-R1 提供多个参数版本,不同版本的计算资源需求不同:
| 模型版本 | 参数量 | 存储需求 |
|---|---|---|
| 1.5B | 15 亿 | 1.1GB |
| 7B | 70 亿 | 4.7GB |
| 14B | 140 亿 | 9GB |
| 32B | 320 亿 | 20GB |
| 70B | 700 亿 | 40GB |
| 671B | 6710 亿 | 500GB |
建议: 如果是初次尝试,建议先下载 1.5B 或 7B 版本,跑通整个流程后,再根据硬件配置选择更大的模型。
下载并运行 DeepSeek-R1
在命令行运行以下命令(以 7B 版本为例):
Ollama 会自动下载模型文件并运行。
ollama run deepseek-r1:7b
安装模型的同时可以同时搭建OpenWebUI节约时间
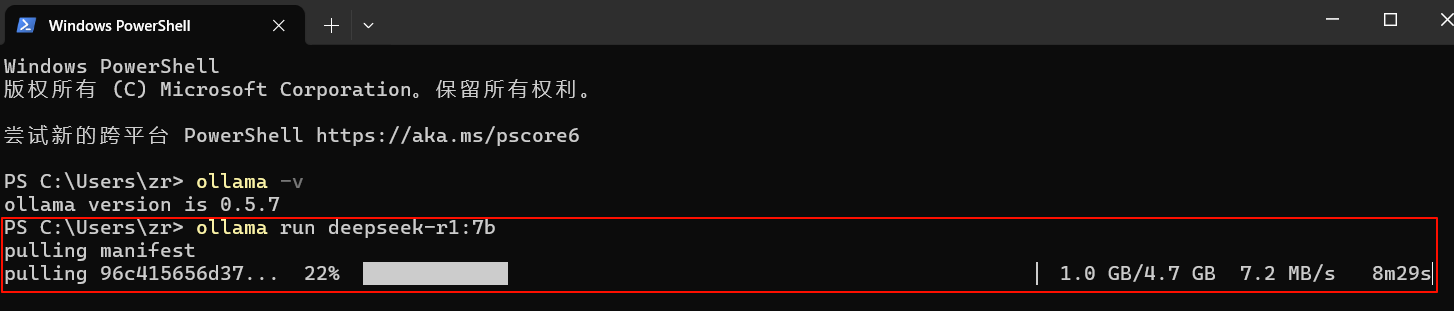
控制台测试

其他版本命令示例:
ollama run deepseek-r1:1.5b # 1.5B 版本
ollama run deepseek-r1:14b # 14B 版本
ollama run deepseek-r1:32b # 32B 版本
ollama run deepseek-r1:70b # 70B 版本
ollama run deepseek-r1:671b # 671B 版本
更改默认模型存储路径(可选)
默认情况下,模型会存储在C:\Users\%username%\.ollama\models。 如果想修改路径,例如存储在 C:\Model,可以:
- 创建
C:\Model目录 - 在系统环境变量中添加:
- 变量名:
OLLAMA_MODELS - 变量值:
C:\Model
- 变量名:
这样,Ollama 会将模型文件存储在新路径。
我使用的为默认的,没有修改,如下图

搭建OpenWebUI
安装Docker Desktop
- Windows 版本要求
- Windows 10 64 位,版本 1903(Build 18362) 或更高。
- Windows 10 Pro、Enterprise 或 Education 版本(Home 版用户需要启用 WSL2)。
- 硬件要求
- 至少 4GB RAM
- 支持 CPU 虚拟化(VT-x/AMD-V),可以在 BIOS/UEFI 中启用。
前往 Docker 官网下载最新版本的 Docker Desktop:https://www.docker.com/products/docker-desktop
- 运行安装程序
- 下载完成后,双击
Docker Desktop Installer.exe启动安装。
- 下载完成后,双击
- 配置安装选项
- 启用 WSL 2(推荐):勾选 “Use the WSL 2 based engine”。
- 启用 Windows 容器(可选):如果需要运行 Windows 容器,可以勾选 “Enable Windows Containers”。
- 点击“Install”
- 安装过程会自动进行,大约需要几分钟时间。
- 安装完成后,点击“Close and restart”
- 这会重启系统,使 Docker Desktop 生效。
- 运行
docker version验证安装是否成功。

配置国内镜像源
在命令行执行命令 “docker run hello-world”,可能出现报错:
“docker: Error response from daemon. (Client. Timeout exceeded while awaiting headers).”
这是 Docker 守护进程在尝试连接到 Docker Hub(registry-1.docker.io)时,发生连接超时,即尝试访问国外的镜像源失败。
对于这个问题,可以使用国内的镜像源或者相关加速。
进入 docker,选择 Settings – Docker Engine,将镜像源替换如下
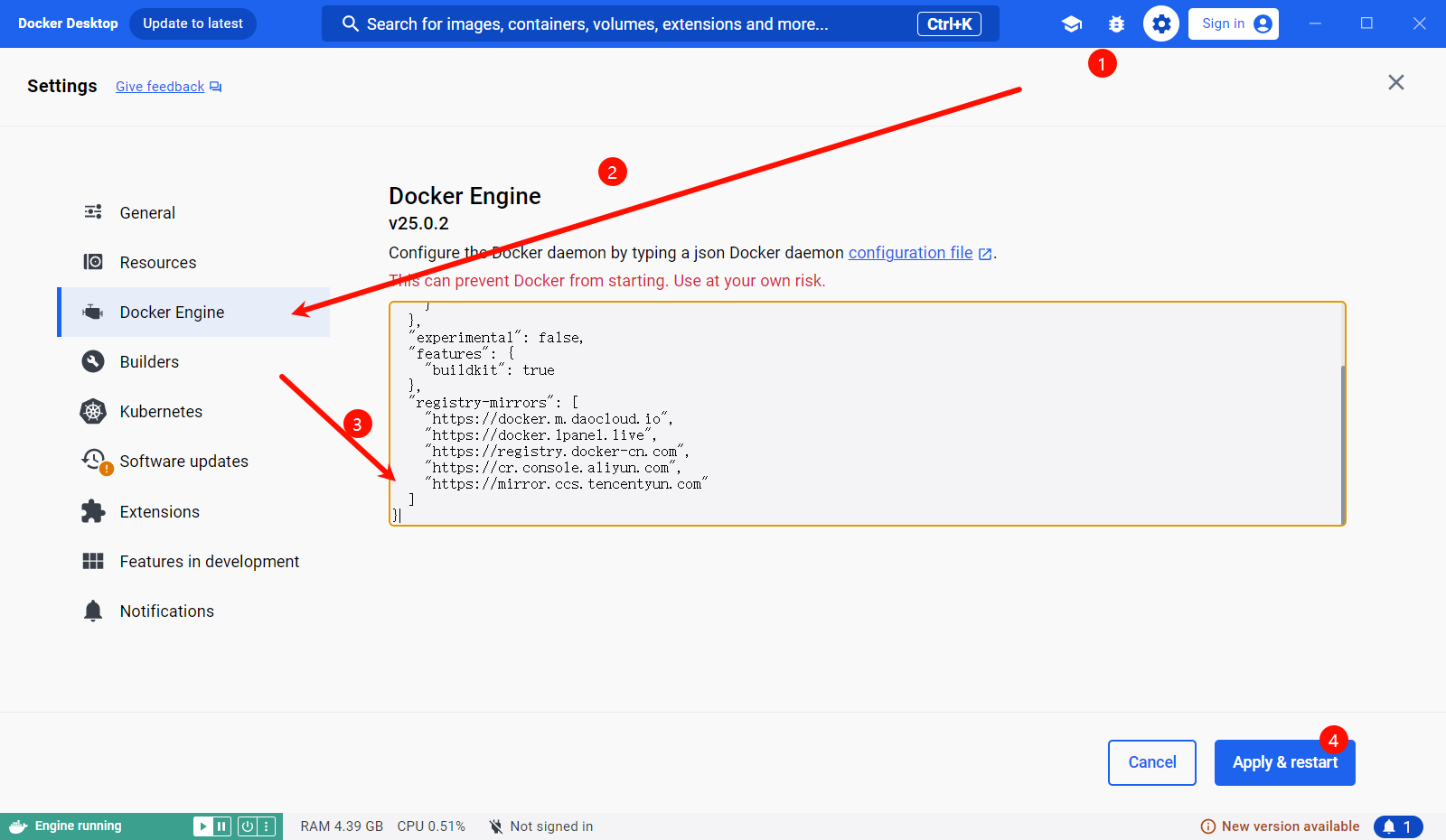
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"features": {
"buildkit": true
},
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://registry.docker-cn.com",
"https://cr.console.aliyun.com",
"https://mirror.ccs.tencentyun.com"
]
}
运行 OpenWebUI(Docker 方式)
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
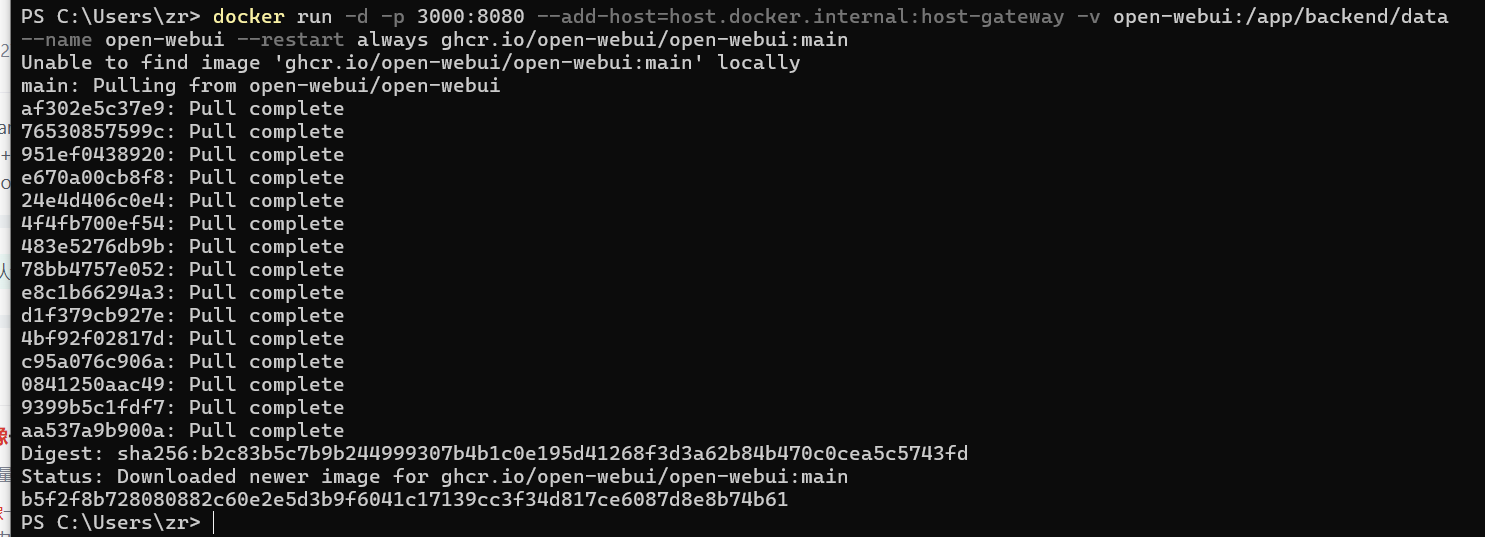
如果不想换源或者换了也不行可以使用我备份在阿里云的镜像,会下载得快一些
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always registry.cn-hangzhou.aliyuncs.com/zr-dev/open-webui:main
通过docker desktop 查看查看是否持续启动
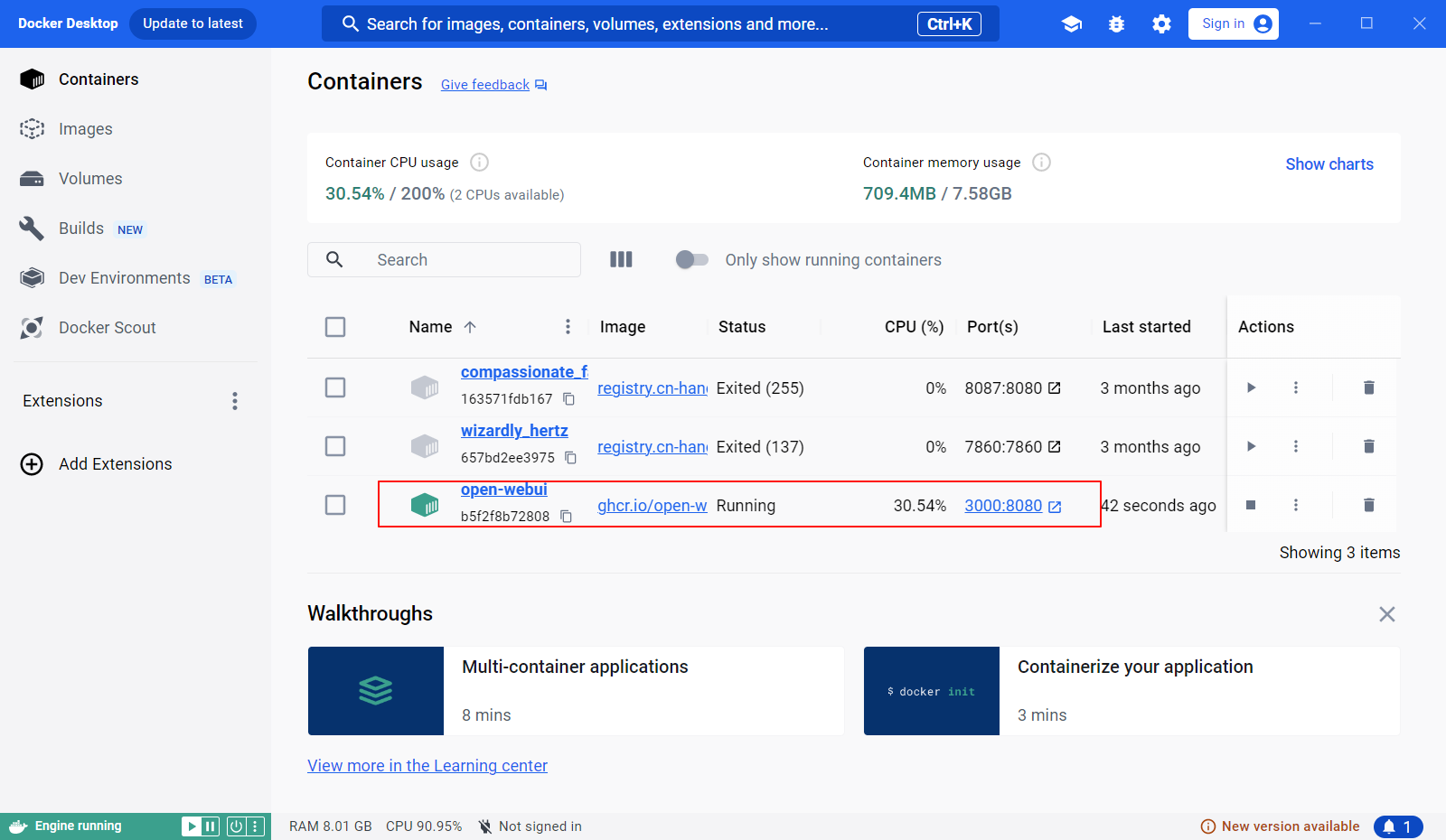
访问 Open-WebUI 进入 deepseek-r1
在浏览器输入 http://localhost:3000/auth 进行访问。
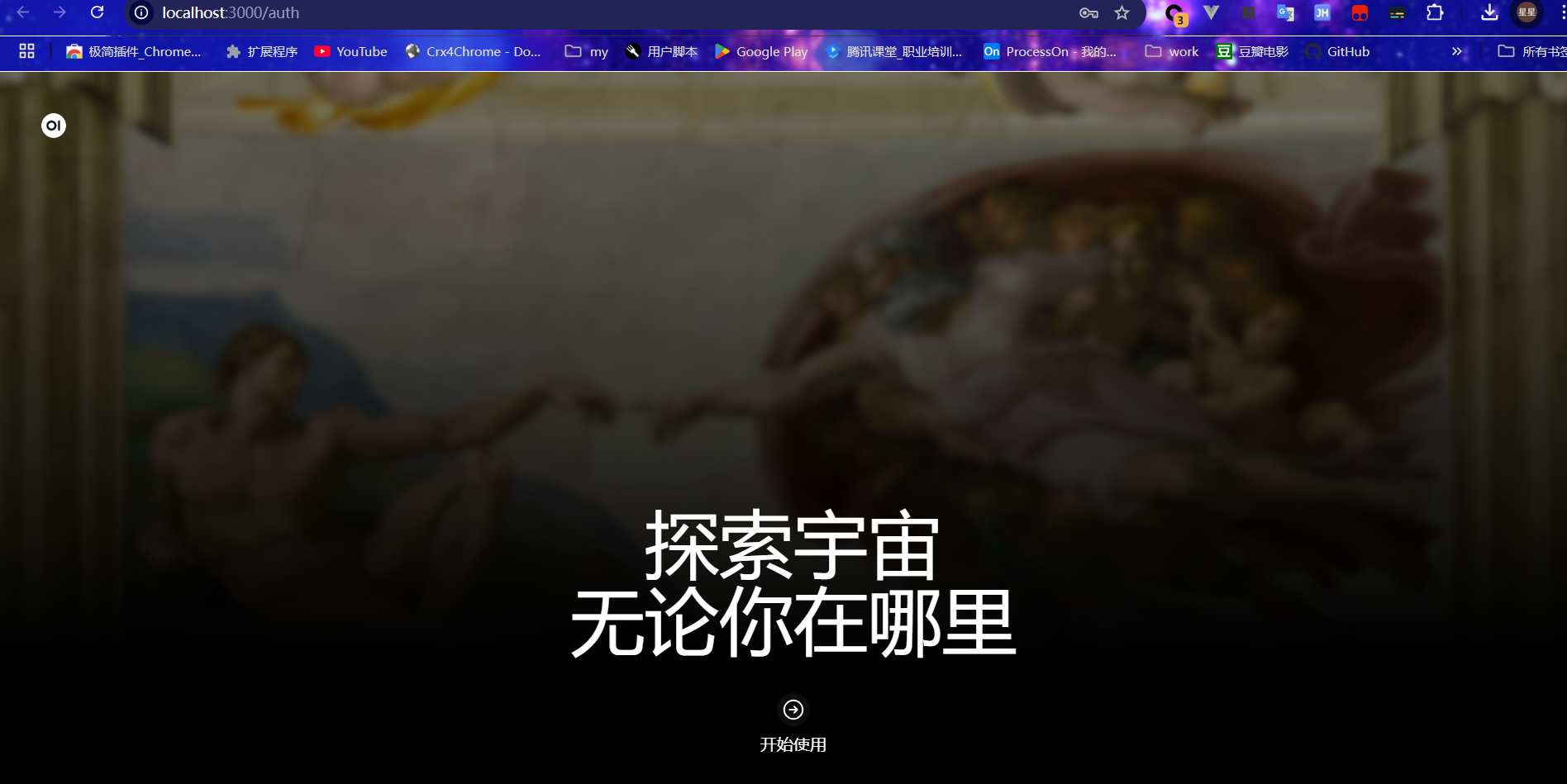
创建管理员账号并登录

进入 OpenWebUI 主界面
注册完成并登录,就进入 deepseek-r1 模型的首页:
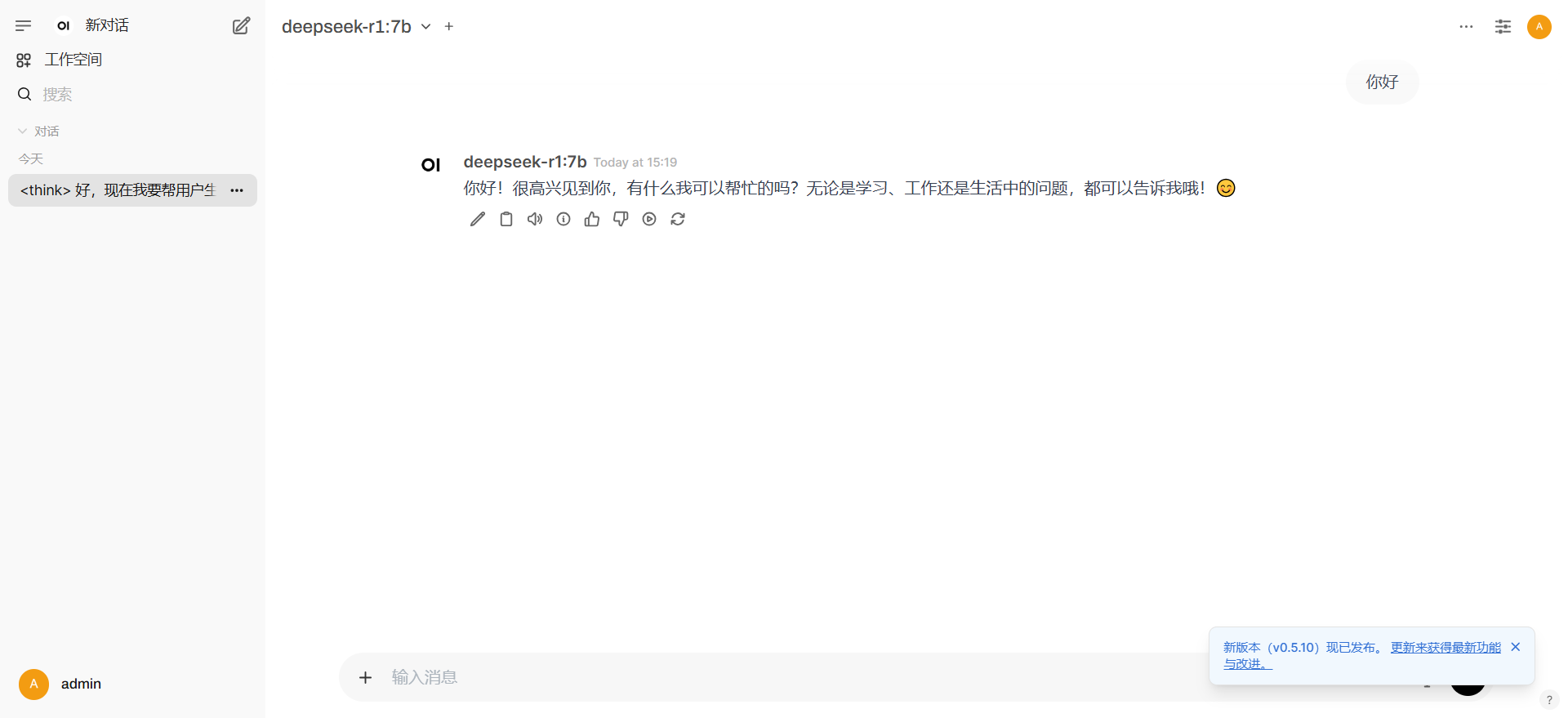
开始使用 DeepSeek-R1
现在,你可以在 OpenWebUI 的聊天界面中,使用本地部署的 DeepSeek-R1 模型进行对话。
以下内容为相关技术栈概述,有兴趣的可以了解一下
Ollama概述
🔹 Ollama 的作用 🚀
Ollama 是一个本地运行大语言模型(LLM)的工具,主要用于简化模型部署和推理。它可以让你在本地 快速下载、运行、管理和调用 LLM,而不需要手动配置复杂的环境。
🔹 Ollama 的核心功能
1️⃣ 运行本地大语言模型
Ollama 允许你直接在本地运行 Llama、Mistral、DeepSeek、Gemma 等模型,无需手动下载 Hugging Face 权重或设置 Python 环境。
示例:
ollama run mistral
这将自动下载并运行 Mistral-7B 模型。
2️⃣ 量化优化(节省显存)
Ollama 使用 GGUF 量化格式(支持 4-bit、8-bit),可以在 低显存显卡(如 8GB 显存) 上流畅运行大模型。
例如,默认使用 mistral:
ollama pull mistral
ollama run mistral
这会下载 4-bit 量化模型,使其可以在 8GB VRAM 设备上运行。
3️⃣ 本地 API 服务
Ollama 提供 HTTP API,可以让你像调用 OpenAI API 一样,在本地使用 LLM:
ollama serve
然后你可以用 Python 访问:
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "mistral", "prompt": "你好!", "stream": False}
)
print(response.json()["response"])
这意味着你可以 本地搭建 ChatGPT 风格的 API,而无需 OpenAI 服务器。
4️⃣ 自定义模型(Modelfile)
你可以通过 Modelfile 自定义模型:
FROM mistral
SYSTEM "你是一个帮助用户写代码的助手"
然后构建:
ollama create my-model -f Modelfile
ollama run my-model
这相当于本地微调 Prompt,适用于 RAG、智能助手、自定义 AI 应用。
🔹 Ollama 的适用场景
✅ 快速本地运行 LLM(免配置)
✅ 在低显存(8GB)设备上运行大模型
✅ 本地 API 调用,替代 OpenAI API
✅ 微调和自定义 AI 助手
✅ 私有部署,保障数据安全
🔹 Ollama vs. 其他本地 LLM 方案
| 方案 | 适合人群 | 适用场景 | 优势 | 缺点 |
|---|---|---|---|---|
| Ollama | 新手 & 开发者 | 轻量推理、API | 易用、自动优化、低门槛 | 自定义能力有限 |
| TextGen WebUI | 高级用户 | 微调、交互 | UI 友好、插件多 | 需要手动配置 |
| LM Studio | 普通用户 | 本地推理 | UI 操作简单 | 不能微调 |
| vLLM | 专业用户 | 高效推理 | 性能强、支持批量 | 需要显存大 |
如果你想要 最简单的本地 LLM 部署方式,Ollama 是最佳选择🚀
OpenWebUI概述
🔹OpenWebUI 是什么
OpenWebUI 是一个 开源的本地 AI 聊天界面,可以连接 Ollama、OpenAI API、GPT-4、Claude 等大模型,让你像 ChatGPT 一样与 AI 交互。
👉 官网:https://github.com/open-webui/open-webui
🔹 OpenWebUI 的核心作用
✅ 1. 作为 ChatGPT 的替代品(本地运行)
- 你可以用 本地大模型(如 Ollama),完全不依赖 OpenAI 服务器。
- 数据 100% 本地化,适合隐私保护需求。
- 提供 与 ChatGPT 类似的 UI,支持 对话历史、提示词管理。
✅ 2. 连接 Ollama 本地大模型
如果你已经在本地安装了 Ollama(支持 Llama、DeepSeek、Mistral 等),OpenWebUI 可以作为它的 聊天界面。
运行 Ollama:
ollama serve
然后在 OpenWebUI 里添加 Ollama API:
http://localhost:11434
这样你就可以像用 ChatGPT 一样,和本地 AI 互动了。
✅ 3. 连接 OpenAI / 其他 API
如果你有 OpenAI API Key 或 其他 LLM(Claude、Gemini),也可以在 OpenWebUI 里配置:
- 本地大模型(Ollama, LLaMA, DeepSeek)
- OpenAI API
- Claude, Mistral, Gemini 等
你可以自由切换不同的 AI 进行聊天。
✅ 4. 提供 Web 端访问
安装 OpenWebUI 后,你可以在 浏览器访问:
http://localhost:3000
或者搭建 远程 AI 聊天服务,让其他人访问你的 AI 助手。
🔹 OpenWebUI 安装指南
方法 1:Docker(推荐)
最简单的方式:
docker run -d --name openwebui -p 3000:3000 -v openwebui_data:/app/data openwebui/openwebui:latest
然后访问:
http://localhost:3000
方法 2:本地手动安装(本文不演示)
去代码仓库拉去代码自行编译安装
🔹 OpenWebUI vs. 其他 WebUI
| WebUI | 适用场景 | 主要特点 | 适配模型 |
|---|---|---|---|
| OpenWebUI | 本地 AI 聊天 | 简单易用,支持 Ollama/OpenAI | ✅ Ollama, OpenAI, Claude |
| TextGen WebUI | 高级微调/推理 | 支持 LoRA、量化、插件丰富 | ✅ GPTQ, GGUF, vLLM |
| LM Studio | 轻量 LLM | 仅支持本地推理 | ✅ Ollama, GGUF |
| Chatbot UI | 开发者 | 高度可定制 | ✅ OpenAI API |
📌 结论
- 如果你用 Ollama 本地模型,推荐 OpenWebUI。
- 如果你需要高级功能(LoRA 微调),推荐 TextGen WebUI。
🔹 适用人群
✅ 想在本地运行 AI 聊天(替代 ChatGPT)
✅ 使用 Ollama 但不想用命令行
✅ 想要简洁的 Web 端聊天界面
✅ 需要远程 AI 访问(搭建自己的 ChatGPT)
💡 总结:OpenWebUI = ChatGPT + Ollama + 本地 AI 聊天工具,简单易用,适合个人和团队搭建 私有 AI 助手! 🚀