目录
Identifying the Treatment Effect
Identification with Randomization
Identifying the Treatment Effect
现在你已经理解了问题所在,接下来该看看解决方案(至少是一个解决方案)了。识别(identification)是因果推断分析中的第一步。你在第三章会看到更多关于它的内容,但现在,了解它是什么很重要。请记住,由于只能观察到一个潜在结果,你无法直接观测到因果量。你无法直接估计类似![E[Y_1-Y_0]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWV8xLVlfMCU1RA%3D%3D)
![E[Y|T=t]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWSU3Q1QlM0R0JTVE)
![E[Y_t]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWV90JTVE)
![E[Y|T=1]-E[Y|T=0]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWSU3Q1QlM0QxJTVELUUlNUJZJTdDVCUzRDAlNUQ%3D)
你也可以将识别视为消除偏倚的过程。利用潜在结果的概念,你还可以说明使关联等于因果关系所需要的条件。如果![E[Y_0|T=0]=E[Y_0|T=1]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWV8wJTdDVCUzRDAlNUQlM0RFJTVCWV8wJTdDVCUzRDElNUQ%3D)
![E[Y|T=1]-E[Y|T=0]=E[Y_1-Y_0|T=1]=ATT](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWSU3Q1QlM0QxJTVELUUlNUJZJTdDVCUzRDAlNUQ%3D%3DE%5BY_1-Y_0%7CT%3D1%5D%3DATT)
此外,如果处理组和未处理组对处理的响应相似,也就是说,
![E[Y_1-Y_0|T=1]=E[Y_1-Y_0|T=0]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWV8xLVlfMCU3Q1QlM0QxJTVEJTNERSU1QllfMS1ZXzAlN0NUJTNEMCU1RA%3D%3D)
那么(请注意这一点),平均差值变成了平均因果效应:
![E[Y|T=1]-E[Y|T=0]=ATT=ATE=E[Y_1-Y_0]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWSU3Q1QlM0QxJTVELUUlNUJZJTdDVCUzRDAlNUQ%3D%3DATT%3DATE%3DE%5BY_1-Y_0%5D)
尽管这里的数学看起来很复杂,但它实际上说的是,一旦你让处理组和对照组可互换,用数据中的可观察量表达因果效应就变得很简单了。应用到我们的例子中,如果降价和不降价的企业彼此相似——也就是说,可互换——那么,有促销活动和无促销活动的企业之间销售量的差异完全可以归因于价格削减。
The Independence Assumption
这种可互换性是因果推断中的核心假设。由于其重要性,不同的科学家以不同的方式表述了这一概念。我先介绍一种可能最常见的表述方式,即独立性假设。在这里,我会说潜在结果与处理是独立的: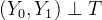
这种独立性意味着![E[Y_0|T]=E[Y_0]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWV8wJTdDVCU1RCUzREUlNUJZXzAlNUQ%3D)
![E[Y_0|T=1]=E[Y_0|T=0]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWV8wJTdDVCUzRDElNUQlM0RFJTVCWV8wJTdDVCUzRDAlNUQ%3D)
![E[Y_1|T]=E[Y_1]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9FJTVCWV8xJTdDVCU1RCUzREUlNUJZXzElNUQ%3D)
Identification with Randomization
在这里,我们将独立性视作一个假设。也就是说,你知道你需要将关联等同于因果关系,但你尚未学会如何使这个条件成立。回想一下,因果推断问题常常被分解为两个步骤:
- 识别(Identification),在这里你找出如何用可观察数据来表示你感兴趣的因果量。
- 估计(Estimation),在这里你实际使用数据来估计之前识别出的因果量。
为了通过一个非常简单的例子来说明这一过程,让我们假设你可以随机化处理。我知道我之前说过,在你工作的在线市场中,企业完全自主设定价格,但你仍然能找到方法来随机化处理IsOnSales。例如,假设你与企业协商,获得强迫他们降价的权利,但市场将补偿你所迫使的价格差异。好的,所以假设你现在有一种方法可以随机化销售,那又怎样呢?实际上,这是一个大问题!
首先,随机化将处理分配绑定到了抛硬币上,因此其变化与因果机制中的任何其他因素完全无关:
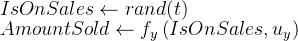
在随机化下,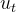
为了使这一点清晰明了,让我们看看随机化是如何几乎消除了偏差的,从处理分配前开始。第一幅图展示了尚未实现的潜在结果(三角形)的世界。这在左边的图像中被描绘出来:
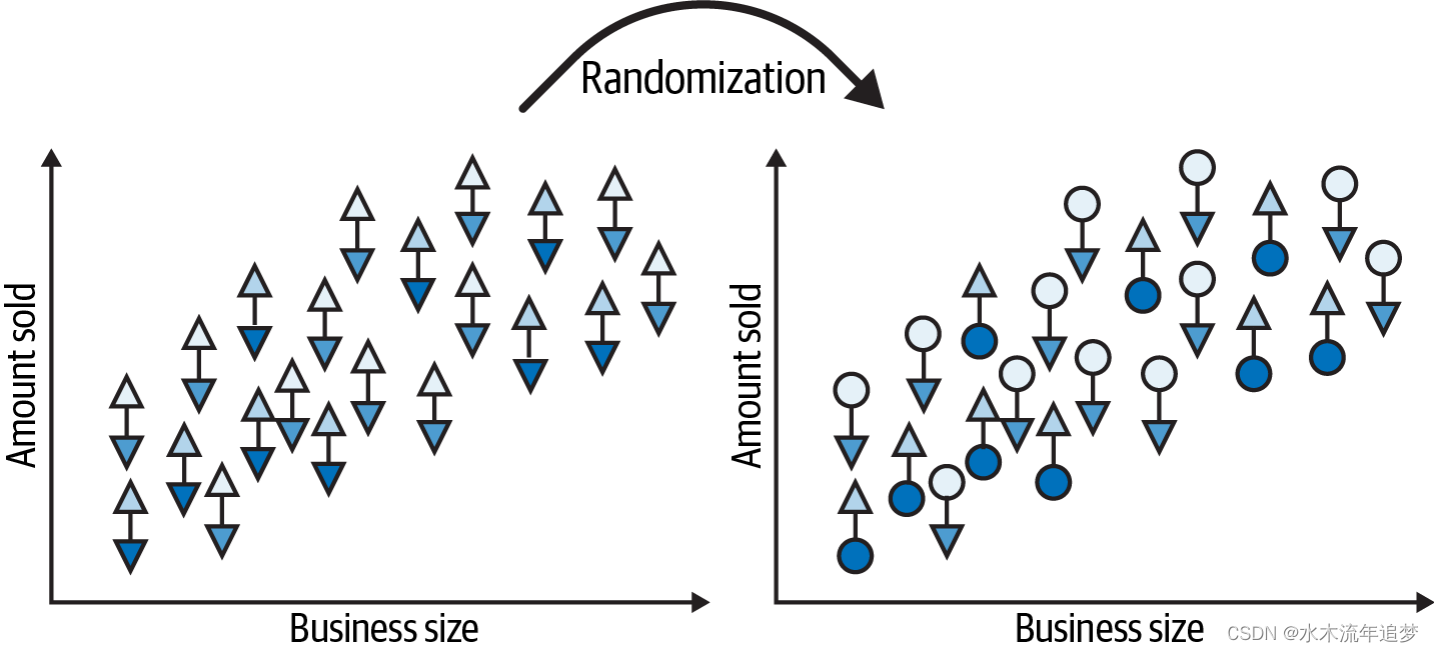
然后,随机地,治疗实现了一个或另一个潜在的结果。
接下来,让我们去除冗余,移除未实现的潜在结果(三角形)。现在你可以比较接受处理的与未接受处理的群体:
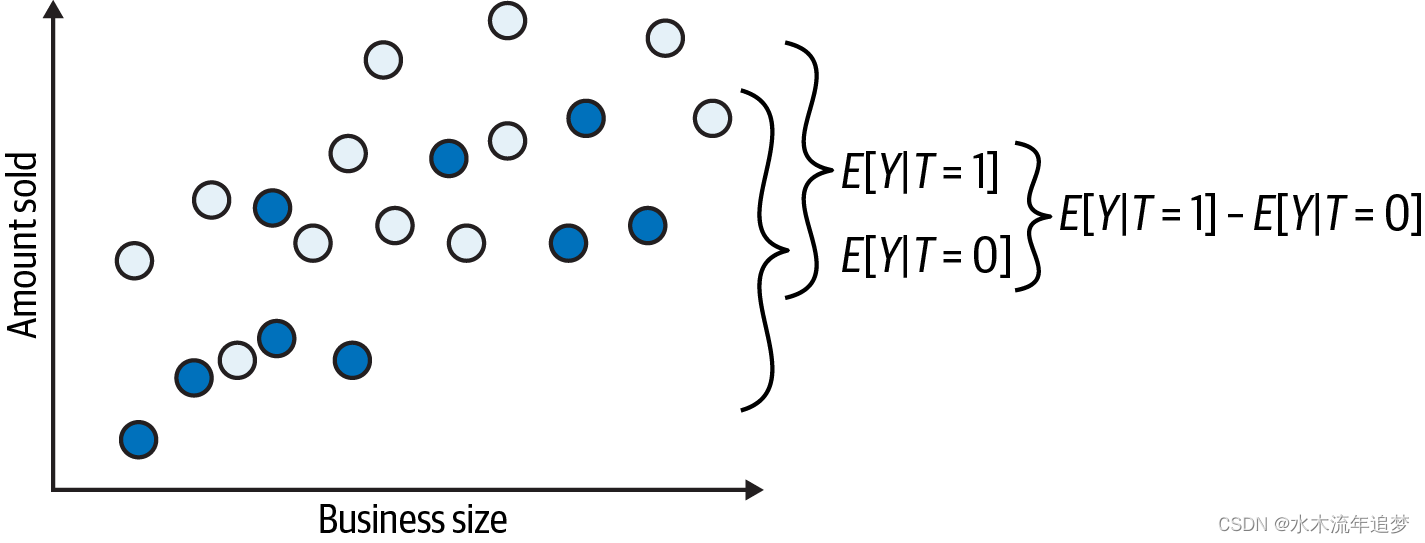
在这种情况下,接受处理与未接受处理群体之间的结果差异就是平均因果效应。这是因为它们之间除了处理本身外没有其他造成差异的来源。因此,你看到的所有差异都必须归因于处理。简单地说,不存在偏差。如果你设置所有人都不接受处理,只观察Y0的结果,你会发现接受处理和未接受处理的群体之间没有差异:

这就是因果识别这项艰巨任务的核心所在。它关乎找到巧妙的方法来消除偏差,使接受处理和未接受处理的群体变得可比,这样你看到的所有差异都可以归因于处理效应。重要的是,识别只有在你了解(或者愿意假设)有关数据生成过程的一些信息时才可能。通常,这是关于处理如何分布或分配的。这就是我之前说过的,仅凭数据本身无法回答因果问题的原因。当然,数据对于估计因果效应很重要。但是,除了数据之外,你总是需要关于数据——特别是处理——如何产生的陈述。你可以通过你的专业知识或干预世界,影响处理并观察结果如何响应变化来获得这一陈述。
最终,因果推断是关于弄清楚世界是如何运作的,剥离所有的幻觉和误解。而现在你理解了这一点,你就可以前进,掌握一些最强大的方法来消除偏差,这些是勇敢和真实者的工具,用于识别因果效应。