思维导图

0. 前言
MySQL 与 Elasticsearch 一致性问题是老生常谈了。网上有太多关于这方面的文章了,但是千篇一律,看了跟没看没有太大区别。
在生产中,我们往往会通过 DTS 工具将 binlog 导入到 Kafka,再通过 Kafka 消费 binlog,组装数据写入 ES。
在这个过程中,可能会存在 binlog 到 Kafka 数据丢失,或者应用程序消费 Kafka 数据成功,但是数据未正确写入至 ES。
本文将探讨如何解决 MySQL 与 ES 的数据一致性问题。
1. 消费侧 Client 到 ES 数据丢失
这里出现丢失的问题,可能有以下几种情况
- ES 写入线程满了,请求被拒绝。
- ES 写入冲突。
1.1 ES 写入请求被拒绝
一般是通过递阶式重试来解决问题,例如第一次等待 1s 后写入,第二次还出现,则等待 3s 后再尝试写入。如果最后写入还是失败,应该记录日志,并告警,而后通过人工介入的方式补偿数据。
不过也需要考虑另外一个问题,为什么并发这么高?这么高的写入并发,对 ES 压力是否太大了?
一般而言,我们认为 ES 是不适合并发太高的写入。因此在消费侧除了要控制 MQ 并发消费的线程数,也要多用用 同步 Bulk API 做批量更新。
1.2 ES 写入冲突
消费侧的逻辑一般如下:
- 会将有关联记录打到同一个队列,防止并发问题。例如同一个商品的 Binlog 都打到同一个队列
- 在主表的
Insert Binlog中,查询关联表信息,拼装完整记录写入 ES - 其它关联表的更新、写入以及主表的
Update Binlog都用Update API做部分更新操作 Delete Binlog用Delete API做删除操作
如果是通过我上面说的方式进行写入,会出现冲突问题的仅有 Update API。
ES Client Update Api 提供了 retry_on_conflict 参数。该参数的意思是,如果发生版本冲突则重试,该参数默认为 0,即默认不重试。生产环境中,我们可以通过配置中心动态配置该参数值。如果重试之后还是发生错误,建议捕获版本冲突异常,并告警,然后人工手动更新。
2. DTS 工具到 Kafka 数据丢失
这里的丢失包含 2 个部分
- DTS 到 Kafka 丢失
- 数据在 Kafka Broker 端丢失
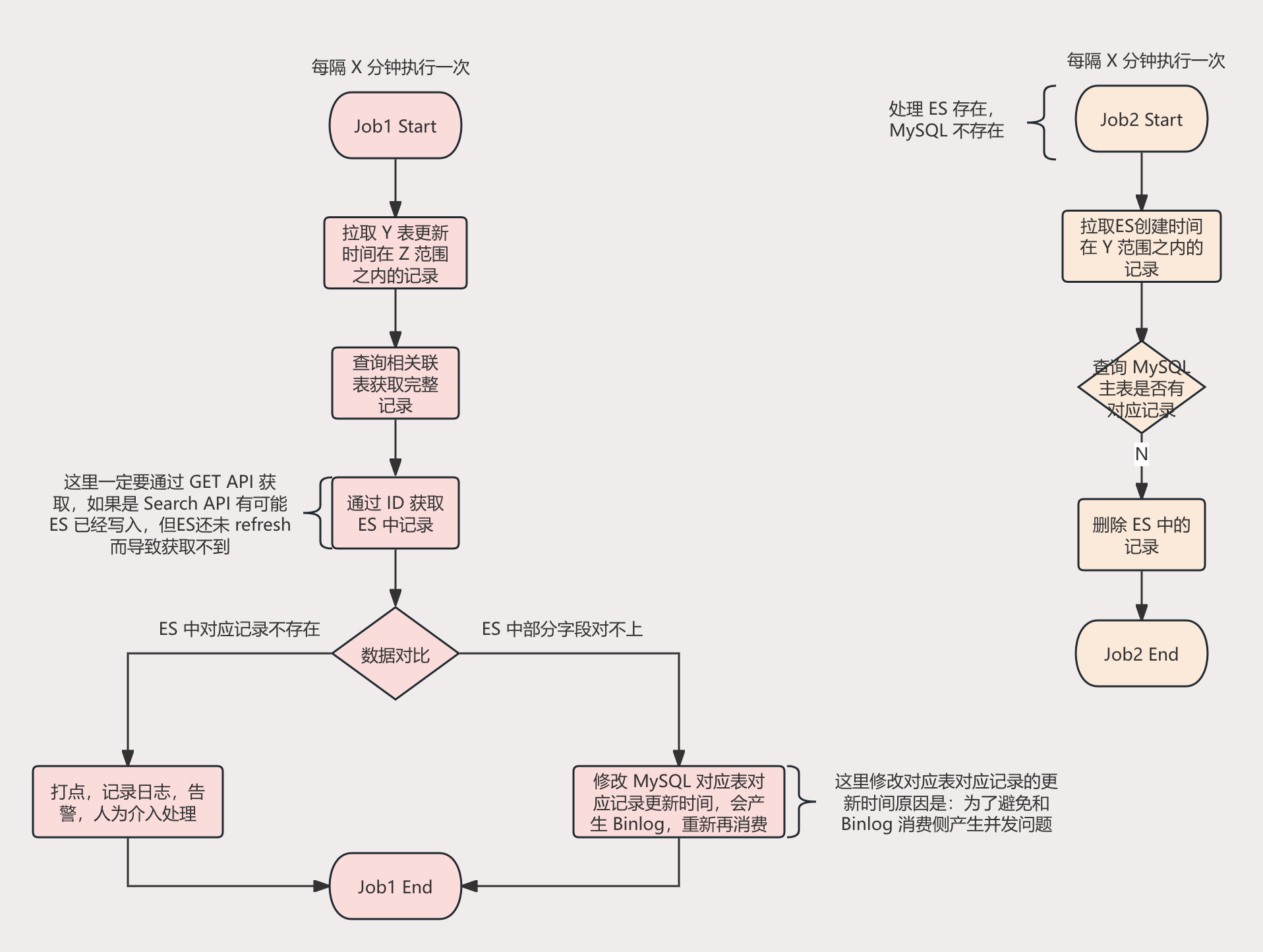
一般是采用定时增量校验。校验 MySQL 和 Elasticsearch 数据是否一致性。
整体的流程图如下所示: