1.自我介绍
2.jenkins相关插件
3.TCP/UDP区别和使用场景
TCP通信协议
TCP是面向连接的;
每条TCP连接只能由于两个端点,一对一通信;
TCP提供可靠的交付服务,传输数据无差错,不丢失,不重复,且按时序到达;
TCP提供全双工通信;
面向字节流,TCP根据对方给出的窗口和当前的网络拥塞程度决定一个报文应该包含多少个字节。
UDP通信协议
无连接;
UDP使用尽最大努力交付,不保证可靠性UDP是面向报文的,UDP对应用层交付下来的报文,既不合并,也不拆分,而是保留报文的边界;
应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文;
UDP没有拥塞控制;
UDP支持一对一,一对多,多对一和多对多的交互通信。
UDP的首部开销小,只有8字节。
应用场景上的区别:
TCP协议需要三次握手通信成功后进行建立,应用场景:互联网和企业网上客户端应用,数据传输性能让位于数据传输的完整性,可控制性和可靠性。
UDP协议是直接发送,不会判断是否接收和发送成功,应用场景:当强调输出性能而非完整性时,如音频和多媒体的应用。
4.如何判断是一个好的网络,从用户方面说
测试上传速度
测试下载速度
测试网络是否稳定,是否延迟,是否丢包(ping网址的时延和丢包)
长期:网络系统必须在较长的时间内正常工作,不能发生宕机、重启等故障。
可靠:在满负载的情况下工作正常,不能崩溃或者效率下降很多。
带宽:能够稳定提供不少于某个指标的数据传输率。
几个指标:
MTBF:平均无故障时间间隔,测试方法:以该系统最大带宽的50%~80%的速率传输数据,
连续不间断工作,记录系统出故障时间。
带宽:稳定的数据传输率。测试方法:同上,逐渐加大数据传输率,测试出最大的稳定带宽
最大并发流数目:TCP或者其他协议的最大支持数,测试方法:采用多客户机多线程方法建立多条链路,
记录系统最大在多少个连接的情况下网络传输率下降不明显。
测试说明:由于是一个较长过程的整体表现,因此,多测试几遍,去掉最高与最低的结果,其余结果取平均值。
5.自动化测试和手动测试的区别和联系
手工测试和自动化测试其实都是一条一条的执行测试用例,只不过自动化测试是由程序代替人的手工操作。
手工测试可能需要重复机械操作,耗时费力,劳心费神。自动化测试可以替代一部分机械性的重复的手工测试。
手工测试永远无法被自动化测试取代。在整个软件开发周期中,手工测试发现Bug的比例更大(大约占80%);同时自动化测试不是适合所有项目的。
对于一些需求不经常变化(版本不会经常变化)的项目做自动化测试不会提高效率,反而会降低效率,浪费时间。(因为需求即版本很少的话手动比较快)
自动化测试主要用于回归测试,测试已经有的功能,而非新功能。
6.浏览器输入一个网址后的整个过程
解析域名的IP地址(在浏览器缓存或hosts或DNS服务器查找)
发起连接请求,TCP三次握手
发送HTTP请求信息
接受服务器返回的数据并渲染到页面
断开TCP连接,四次挥手
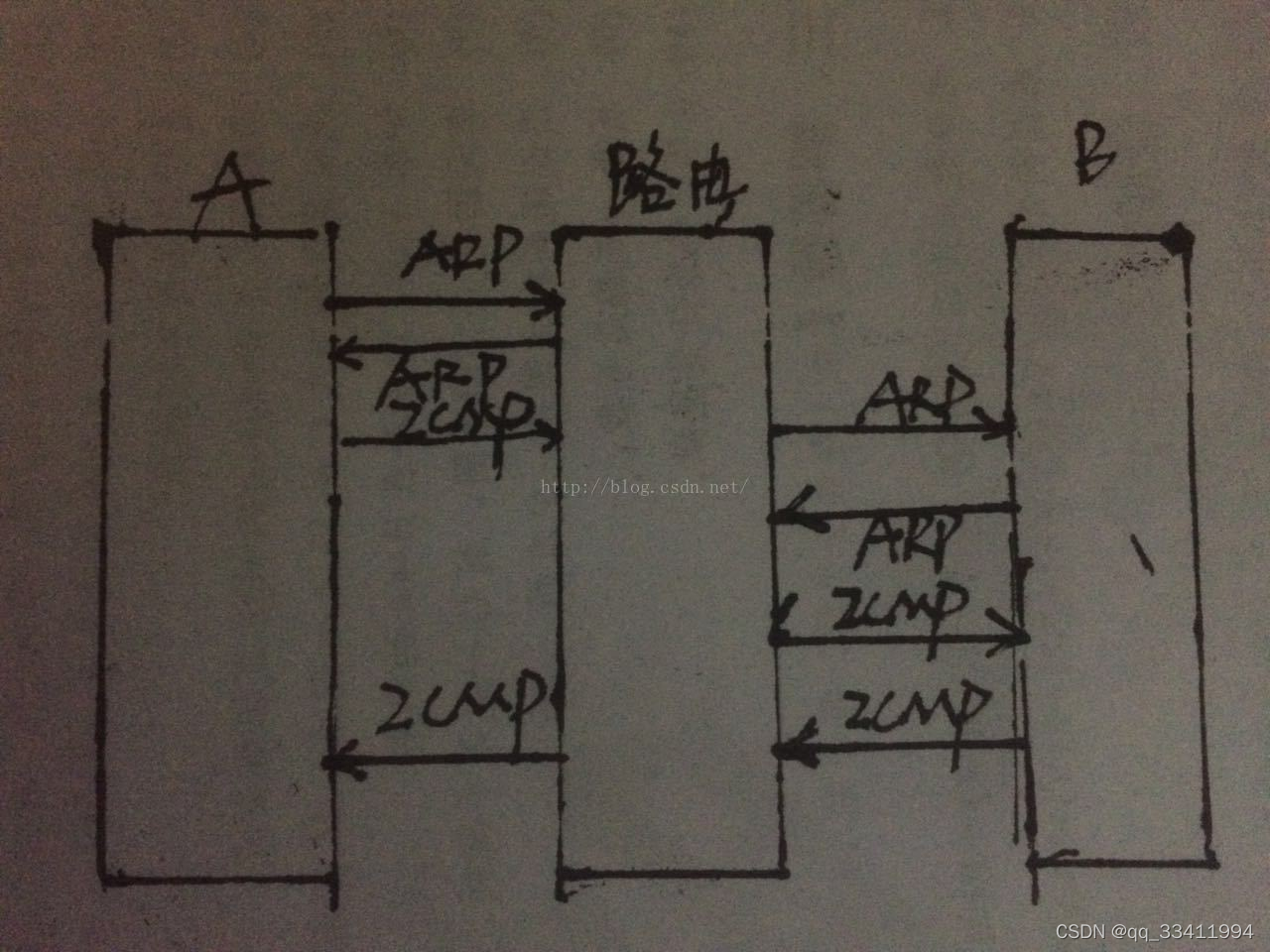
7.一个设备上电后ping另一个网段的设备的整个过程
https://blog.51cto.com/wanicy/335207
同一网段:
首先封装二层报文,先查自己的mac地址表,没有则发ARP广播包到交换机,交换机(有学习mac功能)查看是否保存了目标mac,有就返回,没有则向除了源端口的所有端口发ARP广播,其他主机发现不是找自己纷纷丢弃不予理会,直到目标mac收到该报文立即响应即回复ARP消息同时学到源mac的地址。源主机学到目的主机的mac后把该mac封装到ICMP协议的二层报文中向目的主机发送,目的主机收到后回复ICMP。
不同网段:
不同网段则去找网关转发,不知道网关mac则先发ARP广播学习到网关mac后封装ICMP报文发给网关路由器,路由器发现源主机ICMP报文里的目的mac是自己,根据目的主机ip查找路由表,通过路由表项得到出口指针,去掉原来的mac头部加上自己的mac地址向目的主机转发(如果网关路由器也没有目的主机的mac地址则一样需要arp广播学习),最后目的主机学到了网关路由器mac,路由器学到了源主机mac的情况下,他们就不需要在做ARP解析就将ICMP回复。
所以三层转发目的ip不变但目的mac会多次发生变化;前面一直是网关的mac地址,直到最后一跳为目的mac地址
8.python GIL
GIL(Global Interpreter Lock),全局解释器锁
GIL是一个互斥锁,它防止多个线程同时执行Python字节码。这个锁是必要的,主要是因为CPython(python解释器)的内存管理不是线程安全的。
Python内部对变量或数据对象使用了引用计数器,我们通过计算引用个数,当个数为0时,变量或者数据对象就被自动释放。
这个引用计数器需要保护,当多个线程同时修改这个值时,可能会导致内存泄漏;SO,我们使用锁来解决这个问题,可有时会添加多个锁来解决,这就会导致另个问题,死锁;为了避免内存泄漏和死锁问题,CPython使用了单锁,即全局解释器锁(GIL),即执行Python字节码都需要获取GIL,这可以防止死锁,但它有效地使任何受CPU限制的Python程序都是单线程.
9.浅拷贝和深拷贝
浅拷贝,没有拷贝子对象,所以原始数据改变,子对象会改变
深拷贝,包含对象里面的自对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变
10.进程和线程的区别
进程:进程是操作系统资源分配的基本单位。
线程:线程是任务调度和执行的基本单位。
一个应用程序至少一个进程,一个进程至少一个线程。
两者区别:同一进程内的线程共享本进程的资源如内存、I/O、cpu等,但是进程之间的资源是独立的。
11.多进程和多线程的实现,举例说明怎么实现多进程
import threading
from multiprocessing import Process
总结:可以用python自带的Process类或Thread类创建对象并使用其中方法,也可以自己写类继承Process类或Thread类后重定义用到的方法。
https://www.cnblogs.com/xiaozengzeng/p/10723954.html
即两种方法:
1、给构造函数传递回调对象
mthread=threading.Thread(target=xxxx,args=(xxxx))
mthread.start()
2、在子类中重写run() 方法(start会调用run方法),在子类中只有_init_()和run()方法被重写
12.代码题:发一个红包,最大额度为200,1~20个人随机领取,每个人领取到多少钱。
import random
def send_money(money_sum,person_num,money_list=[]):
if person_num == 1:
money_last = money_sum
money_list.append(money_last)
return money_list
else:
person_num = person_num - 1
money_rand = random.uniform(0,money_sum)
print money_rand
money_get = round(money_rand,2)
print money_get
money_left = money_sum - money_get
money_list.append(money_get)
return send_money(money_left,person_num,money_list)
if _name_ == ‘_main_’:
print send_money(200,20,[])
花了一个小时写出上面的代码,问题是随机有时候会得到复数,
[0.27, 73.58, 9.27, 38.05, 65.64, 3.68, 1.01, 0.93, 5.72, 0.27, 0.95, 0.31, 0.26, 0.05, 0.01, -0.0, -0.0, -0.0, -0.0, -1.2264494975156026e-15]
有如下原因:
1)因为round取两位小数的时候四舍五入,如果是五入则会导致获取的大于剩下的,导致负数的出现;因为我们要确保获取的小于剩下的,所以要四舍五不入
2)每个人获取的值需要大于0.01,不然在金钱世界里没有意义
修改如下:
money_rand = random.uniform(0.01,money_sum)
#money_get = round(money_rand,2)
num_list = str(money_rand).split(".")
num_str = num_list[0] + '.' + num_list[1][:2]
money_get = float(num_str)
money_left = money_sum - money_get
但是随机数导致前几个人取完就剩0.01供后面几个人再领取的话就不合理,因为0.01已经是最小值,不能再由多个人领取,所以需要再加限制条件来保证后面的人在剩余的钱里至少能领取0.01元
#money_rand = random.uniform(0.01,money_sum)
max_get = money_sum - 0.01*person_num
money_rand = random.uniform(0.01,max_get)
最后的完整代码为:
import random
def send_money(money_sum,person_num,money_list=[]):
if person_num == 1:
money_last = money_sum
money_last = round(money_last,2)
money_list.append(money_last)
return money_list
else:
person_num = person_num - 1
#money_rand = random.uniform(0.01,money_sum)
max_get = money_sum - 0.01*person_num
money_rand = random.uniform(0.01,max_get)
#money_get = round(money_rand,2)
num_list = str(money_rand).split(".")
num_str = num_list[0] + ‘.’ + num_list[1][:2]
money_get = float(num_str)
money_left = money_sum - money_get
money_list.append(money_get)
return send_money(money_left,person_num,money_list)
if _name_ == ‘_main_’:
print send_money(200,20,[])
这样运行下来理论上没什么问题,但后面的人都只能获取到几分钱
[188.3, 7.43, 3.59, 0.36, 0.07, 0.03, 0.04, 0.04, 0.01, 0.01, 0.01, 0.02, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.02]
所以改进一下使差距不要太大,范围修改一下:
max_get = money_sum - 8*person_num //剩下的人平均下来每个人能分8块钱,如果总数是200,人数是20,把8改为10则分配到的钱比较平均,如果起始范围也是10的话则平均每个人直接分到10块钱
money_rand = random.uniform(5,max_get)//起始为5块钱
[38.27, 12.16, 11.34, 6.49, 5.43, 5.58, 15.83, 5.79, 8.12, 10.53, 5.51, 7.01, 11.83, 6.93, 7.64, 7.96, 5.57, 7.04, 12.16, 8.81]
还需要改进的地方:
剩下的人平均每个人分配的钱8应该也设置为一个参数,起始值5也应该是一个参数值
import random
def send_money(money_sum,person_num,balance,money_list=[]):
if person_num == 1:
money_last = money_sum
money_last = round(money_last,2)
money_list.append(money_last)
return money_list
else:
person_num = person_num - 1
#money_rand = random.uniform(0.01,money_sum)
max_get = money_sum - balance*person_num
money_rand = random.uniform(balance/2,max_get)
#money_get = round(money_rand,2)
num_list = str(money_rand).split(".")
num_str = num_list[0] + ‘.’ + num_list[1][:2]
money_get = float(num_str)
money_left = money_sum - money_get
money_list.append(money_get)
return send_money(money_left,person_num,balance,money_list)
if _name_ == ‘_main_’:
print send_money(200,20,200/20,[])
跟balance相关的地方控制着每人领取值是否更均衡。