注意: 数据库pymysql的commit()和execute()在提交数据时,都是同步提交至数据库,由于scrapy框架数据的解析和异步多线程的,所以scrapy的数据解析速度,要远高于数据的写入数据库的速度。如果数据写入过慢,会造成数据库写入的阻塞,影响数据库写入的效率。
通过多线程异步的形式对数据进行写入,可以提高数据的写入速度。
使用twsited异步IO框架,实现数据的异步写入。
代码中参数格式:*代表是元组,**代表是字典(固定写法!非自定义!)
示例代码:
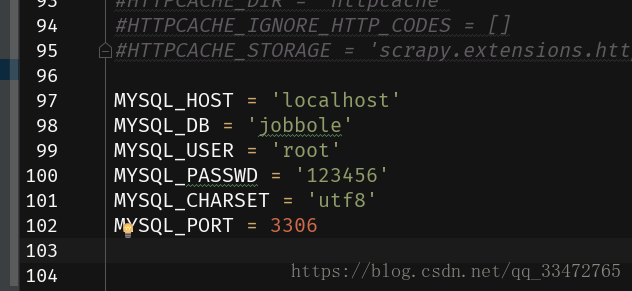
在settings.py中配置数据库参数,如下图:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
class JobbolePipeline(object):
def process_item(self, item, spider):
return item
# 定义处理图片的Pipeline
class ImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
print('---',results)
return item
# 如果图片能够下载成功,说明这个文章是有图片的。如果results中不存在path路径,说明是没有图片的。
# [(True, {'path': ''})]
# if results:
# try:
# img_path = results[0][1]['path']
# except Exception as e:
# print('img_path获取异常,',e)
# img_path = '没有图片'
# else:
# img_path = '没有图片'
# 判断完成,需要将变量img_path重新保存到item中。
# 数据库pymysql的commit()和execute()在提交数据时,都是同步提交至数据库,由于scrapy框架数据的解析和异步多线程的,所以scrapy的数据解析速度,要远高于数据的写入数据库的速度。如果数据写入过慢,会造成数据库写入的阻塞,影响数据库写入的效率。
# 通过多线程异步的形式对数据进行写入,可以提高数据的写入速度。
from pymysql import cursors
# 使用twsited异步IO框架,实现数据的异步写入。
from twisted.enterprise import adbapi
class MySQLTwistedPipeline(object):
"""
MYSQL_HOST = 'localhost'
MYSQL_DB = 'jobbole'
MYSQL_USER = 'root'
MYSQL_PASSWD = '123456'
MYSQL_CHARSET = 'utf8'
MYSQL_PORT = 3306
"""
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
params = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DB'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset=settings['MYSQL_CHARSET'],
port=settings['MYSQL_PORT'],
cursorclass=cursors.DictCursor,
)
# 初始化数据库连接池(线程池)
# 参数一:mysql的驱动
# 参数二:连接mysql的配置信息
dbpool = adbapi.ConnectionPool('pymysql', **params)
return cls(dbpool)
def process_item(self, item, spider):
# 在该函数内,利用连接池对象,开始操作数据,将数据写入到数据库中。
# pool.map(self.insert_db, [1,2,3])
# 同步阻塞的方式: cursor.execute() commit()
# 异步非阻塞的方式
# 参数1:在异步任务中要执行的函数insert_db;
# 参数2:给该函数insert_db传递的参数
query = self.dbpool.runInteraction(self.insert_db, item)
# 如果异步任务执行失败的话,可以通过ErrBack()进行监听, 给insert_db添加一个执行失败的回调事件
query.addErrback(self.handle_error)
return item
def handle_error(self, field):
print('-----数据库写入失败:',field)
def insert_db(self, cursor, item):
insert_sql = "INSERT INTO bole(title, date_time, tags, content, zan_num, keep_num, comment_num, img_src) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
cursor.execute(insert_sql, (item['title'], item['date_time'], item['tags'], item['content'], item['zan_num'], item['keep_num'], item['comment_num'], item['img_src']))
# 在execute()之后,不需要再进行commit(),连接池内部会进行提交的操作。