消息(Message)
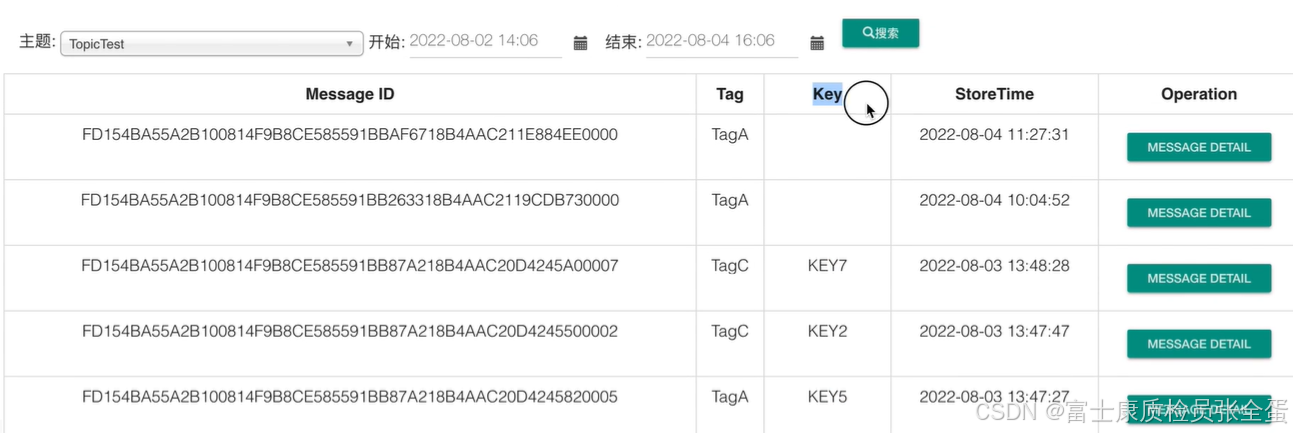
这些消息都有自己messageid,也可以给上相应的业务ID。
名字服务(Name Server) 轻量级注册中心
消息模型(Message Model)
RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责⽣产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应⼀台服务器,每个 Broker 可以存储多个Topic的消息,每个Topic的消息也可以分⽚存储于不同的 Broker。
Message Queue ⽤于存储消息的物理地址,每个Topic中的消息地址存储于多个 Message Queue 中。ConsumerGroup 由多个Consumer 实例构成。
生产者去往broker上面去发送消息,消费者consumer就能够收到。
如果没有生产者就没人发消息。如果没有broker,消息就发不到指定的目的地。如果没有consumer就没有办法被消息,也就没有意义。这是消息队列应该具备的三个部分。
消息的单位并不是broker,而是topic,topic是一个逻辑的概念。topic在broker的物理层面是message queue。
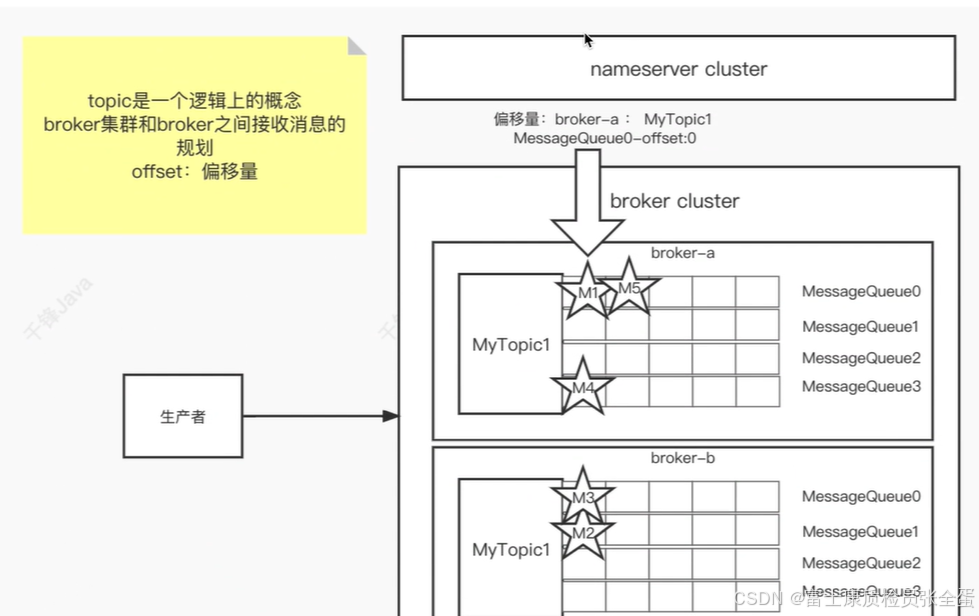
将消息发送到topic上面,topic会事先在broker上面先创建出来。它得存在消息才可以发送过去。所以在发送消息之前先要指定某个topic。消息并不会存放在topic上面,而是会存放在topic对应的messagequeue上面。 topic对应了几个messagequeue,如果没有指明那么就是默认的4个messagequeue。
主题(Topic) 用于区分消息
表示⼀类消息的集合,每个主题包含若⼲条消息,每条消息只能属于⼀个主题, 是RocketMQ进⾏消息订阅的基本单位。(这是一个逻辑上的概念,使用逻辑上的概念将消息区分开来,其实一个业务就是一个主题,比如发送的是订单的消息,这样order消息会放在一个主题里面)
实际当中根据实际的业务场景发送到业务相关的主题里面。而不应该将多种消息都发送到同一个主题里面。
消息发送过去只会选中某个队列,生产者会去做一个轮训的负载均衡,它能够记录之前是哪个messagequeue,那么下一次就是+1,这样每条消息只会存在一个队列中。
消息⽣产者(Producer)
⽣产者组(Producer Group)
如果生产者发送的是事务消息,但是事务完成了1/3,这个时候生产者挂掉了。但是生产组中还有其他生产者,那么其他生产者可以顶上来,继续完成事务消息后面的工作需要。
生产者组看似是没有太多的应用场景,但是在事务消息里面非常的重要。
消息消费者(Consumer)
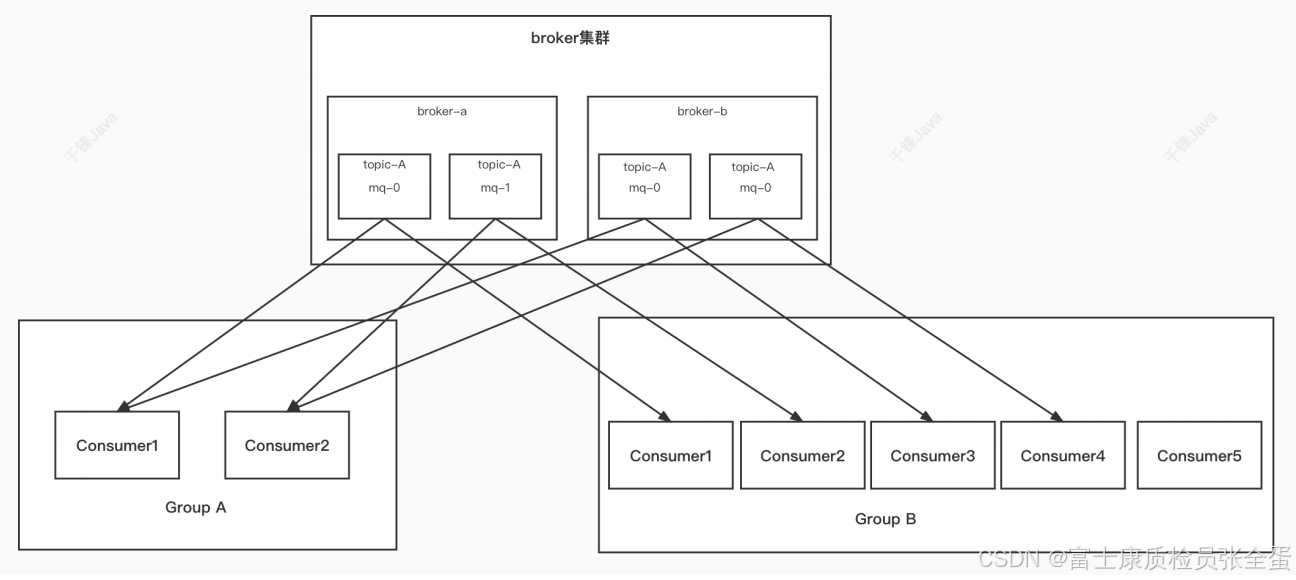
broker集群里面会有两个broker, brokera和brokerb,对于topic来说存储在broker上面是用messagequeue来表示的。
topica会在brokera和brokerb上面分别对应着2个队列。topica对应着4个队列,分别是brokera里面的mq0,和brokera里面的mq1。还有brokerb里面的mq0,好有brokerb里面mq1。
这四个队列从生产者的角度来看,消息发送过去只会发送到四个队列中的其中一个队列。假设消息在mq-0,那么消息只会消费组groupa里面的一个消费者consumer1消费。消息只能被consumer1一个消费者消费,不能被其他消费者消费!!!那么topica里面mq1就会被groupa里面另外一个消费者consumer2消费。
一个队列只能被一个消费组一个消费者消费。
消息order从0-9,第一个消费者消费了 0 1 2 3 8 9,第二个消费者消费了4 5 7。
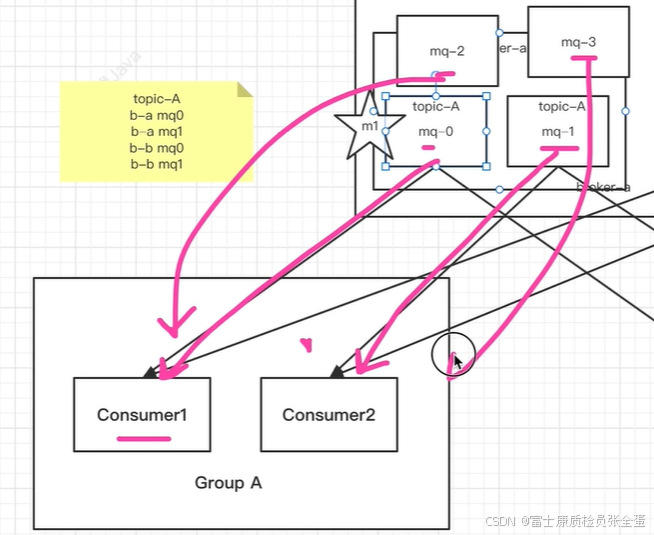
一个topic里面的一个messagequeue只能被同一个group里面一个消费者消费。这些队列至于被哪个consumer消费,这个时候broker会去做一个负载均衡。怎么负载均衡不重要,重要的是你要知道在一个broker里面的messagequeue,它只能被同一个group里面的一个消费者消费,不能说同一个messagequeue被同一个group中的两个或者多个消费者消费。这个是错误的!!!!
其实就是多个消费者将消息均摊掉了。
生产者的消息会去取模,比如有8个队列,那么消息会均匀的分布在8个消息队列里面。那么8个队列里面会各自的有消息。不同的messagequeue只能被同一个消费者消费,至于哪个被consumer1消费哪个被consumer2消费,这个是broker负载均衡需要做的事情。
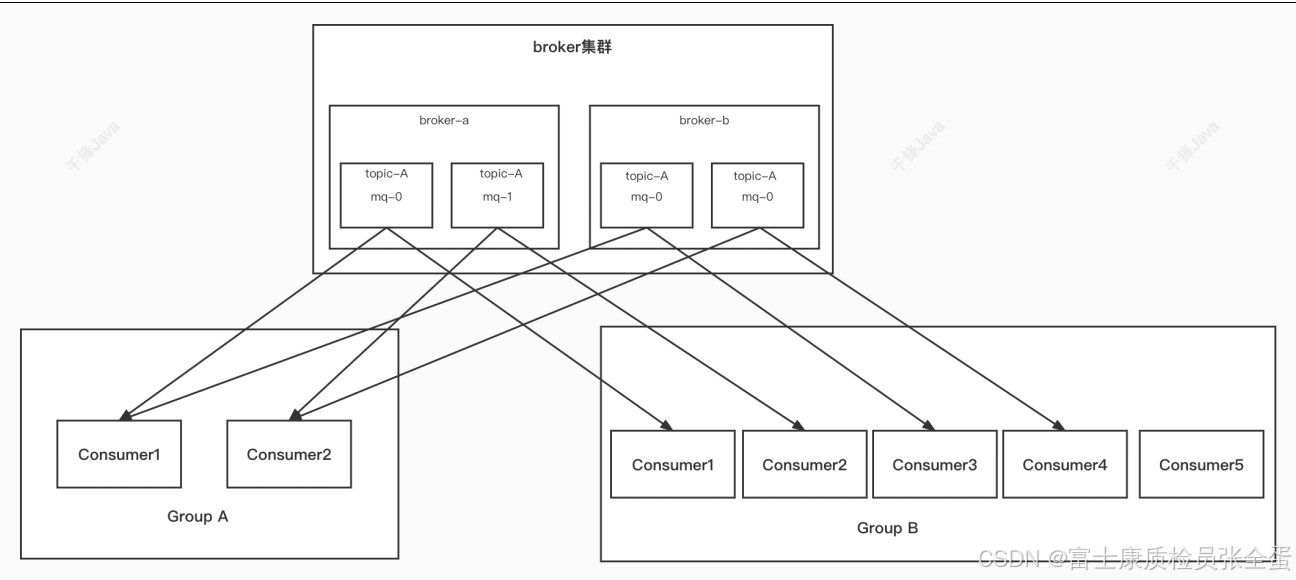
如果来了另外一个消费者也是来消费topica的,现在topic正好有4个队列,那么负载均衡将每个队列分摊给每个消费者,应该队列就被一个消费者消费。
如果在消费组里面再启动一个消费者consumer5,那么这个消费者没有什么意义,因为没有办法分到任何的messagequeue进行消费,因为一个messagequeue只能被同一个消费组里面的一个消费者消费。
consumer5存在的意义:当consumer5消费组中的其中一个消费者挂了,那么messagequeue就可以被consumer5消费。

代理服务器(Broker Server)
Dledger⾼可⽤集群
[root@localhost conf]# cd dledger/
[root@localhost dledger]# ls
broker-n0.conf broker-n1.conf broker-n2.conf
[root@localhost dledger]# cat broker-n0.conf
brokerClusterName = RaftCluster
brokerName=RaftNode00
listenPort=30911
namesrvAddr=127.0.0.1:9876
storePathRootDir=/tmp/rmqstore/node00
storePathCommitLog=/tmp/rmqstore/node00/commitlog
enableDLegerCommitLog=true
dLegerGroup=RaftNode00
dLegerPeers=n0-127.0.0.1:40911;n1-127.0.0.1:40912;n2-127.0.0.1:40913
## must be unique
dLegerSelfId=n0
sendMessageThreadPoolNums=16
在这个配置里面并没有指明当前这个broker它是什么身份,没有指明是master还是salve身份。只有nameserver地址和端口,broker的名字,还有保存的路径。
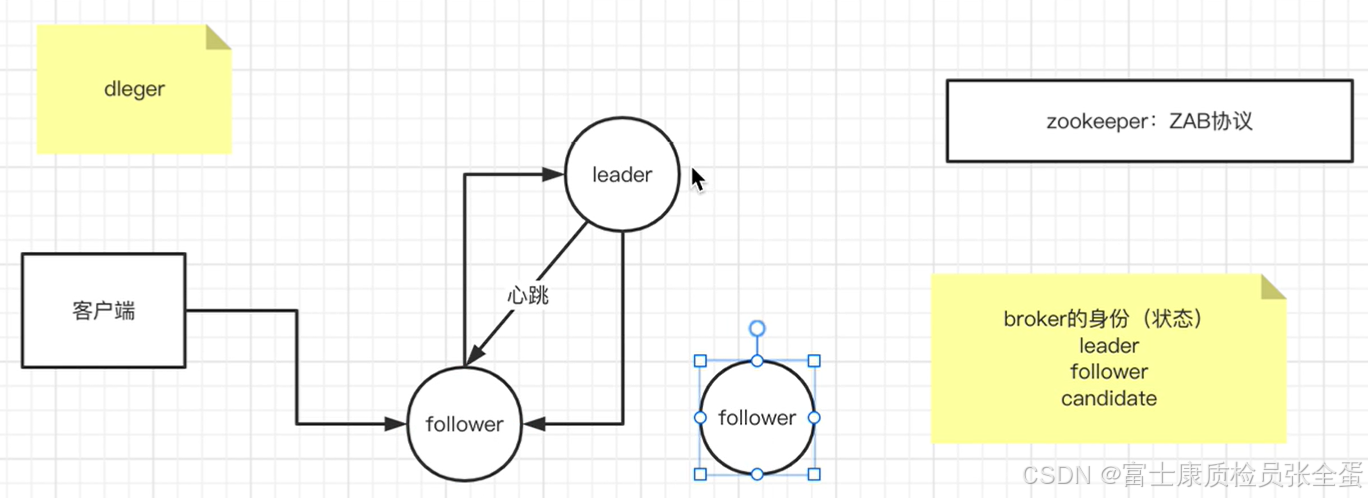
至于是master还是slave身份,这都是delger集群自己去选举出来的。leader读和写都会在leader身上发生,而follower主要是做数据的同步和数据同步的响应。即使有客户端连接到follow,那么follow也会将数据交给leader读写。
当leader挂掉之后,follow如何成为leader,这个选举逻辑参考了zk的逻辑。
zk使用了ZAB协议来实现选举。broker有三种身份,candidate是正在处于leader选举的过程当中。
处于candidate的状态的broker要去争取leader。当leader follow身份确认好之后会不断的去发送心跳给follow,到follow和leader之间的长连接和心跳是一直存在的,如果leader的心跳没有了。那么意味着leader已经出现问题,可能leader挂掉了。
那么之后follow就会变为candidate的状态,变为candidate状态就需要去做选举的。
两个candidate怎么去选举?
在delger里面会有时间片的概念,时间片随着时间的推移,某个节点随着时间的推移它的过程当中会被划分为很多个时间片。
这个时间片当中又被划分为了两段,一段是选举的时间,还有一段是正常工作的时间。随着时间的推移candidate会经历过这么多的时间片。
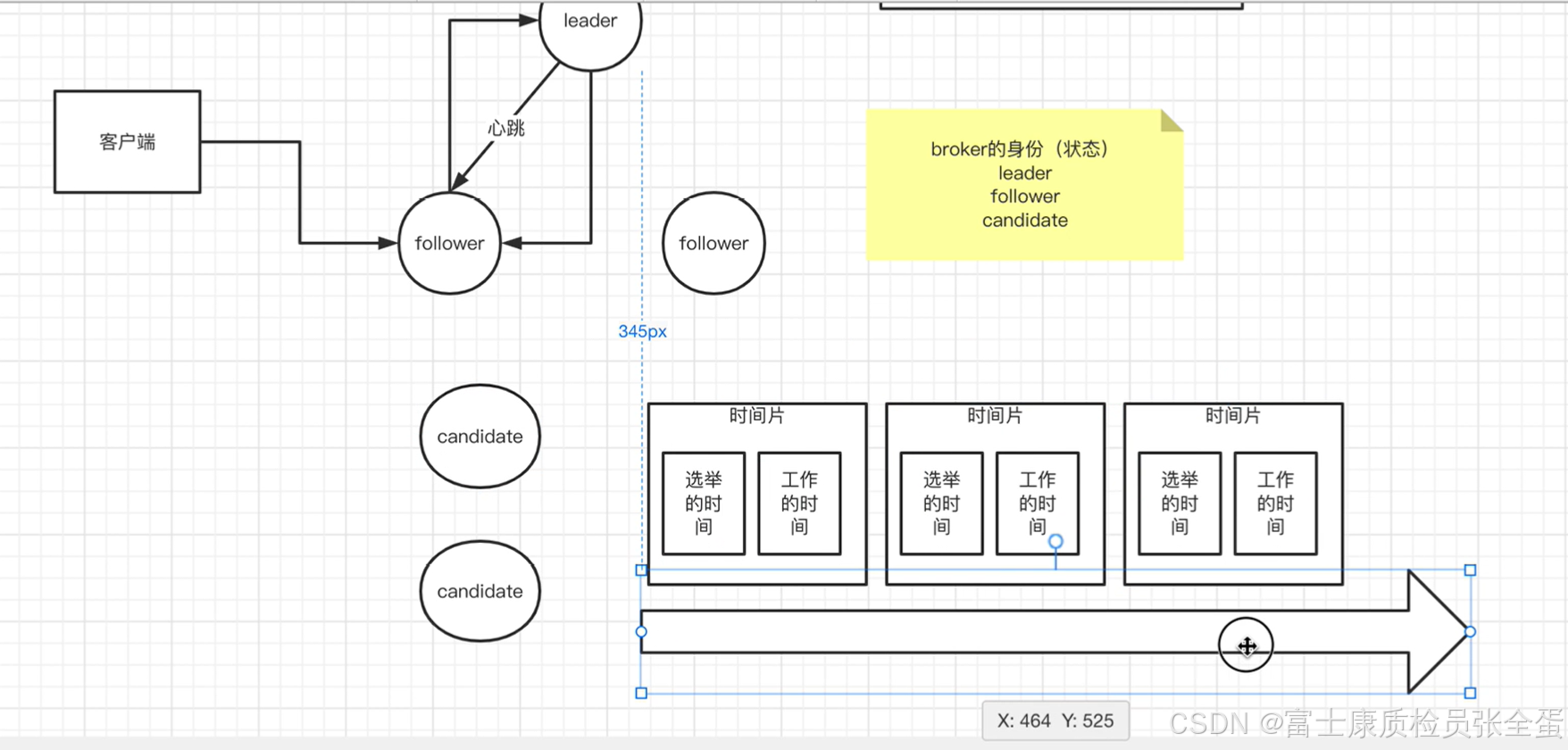
leader一旦挂掉,大家变为candidate就开始去做选举。在做选举的时候来说对于时间片来说是一个term。这个term会有一个termid,也就是时间片的id。
某个candidate节点会去投票,它的票由两部分组成,一部分是termid,还有一个是节点id。这两个节点谁会成为leader就看termid谁大。如果termid大很显然时间片在后面,时间片在后面说明是最新的,没有经过短暂的休眠,没有因为自己刚起来,刚刚恢复。也就是在线上的时间会更加久一些。
termid最大的会成为leader,因为最新,数据也是最新的,另外一个就会成为follow。所以会根据termid来投票。
如果termid相同,集群就会进入休眠状态,如果termid是一样的,会让你休眠一会,休眠之后又开始投票,因为之前其中一个休眠一会了,那么另外一个termid也就越大了,这个时候就会成为新的leader了。
除了leader心跳挂掉之后会触发选举,还有一种情况就是时间片用完,就会触发一次选举,在整个过程当中会做多次的选举,这样设计是为了防止脑裂。
脑裂:leader到follow心跳断掉了,可能是网络波动,这个时候触发选举,那么follow变为新的leader,网络不稳定但是leader还是在的,其实就是和follow之间心跳发送问题触发follow之间产生新的选举。那么久产生了两个leader。
delger方式就可以避免脑裂,即使是假死脑裂,在一个时间片之后又要重新选举。这样就有效的避免了脑裂情况的出现。