一、数据概念
1、脏数据所指的就是未提交的数据。也就是说,一个事务正在对一条记录做修改,在这个事务完成并提交之前,这条数据是处于待定状态的(可能提交也可能回滚),这时,第二个事务来读取这条没有提交的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被称为脏读。
2、不可重复读(Non-Repeatable Reads):一个事务先后读取同一条记录,而事务在两次读取之间该数据被其它事务所修改,则两次读取的数据不同,我们称之为不可重复读。
3、幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为幻读。
4、幻读是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,以后就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样.一般解决幻读的方法是增加范围锁RangeS,锁定检索范围为只读,这样就避免了幻读。
二、数据库事务的四大特性:
1、原子性:事务包含的所有数据库操作要么全部成功,要不全部失败回滚
2、一致性:一个事务执行之前和执行之后都必须处于一致性状态。拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
3、隔离性:一个事务未提交的业务结果是否对于其它事务可见。级别一般有:read_uncommit,read_commit,read_repeatable,串行化访问。
4、持久性:一个事务一旦被提交了,那么对数据库中数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
三、数据库的隔离级别
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted 、Read committed 、Repeatable read 、Serializable ,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。
√: 可能出现 ×: 不会出现
|
| 脏读 | 不可重复读 | 幻读 |
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | × | × |
注意:我们讨论隔离级别的场景,主要是在多个事务并发 的情况下,因此,接下来的讲解都围绕事务并发。
Read uncommitted 读未提交
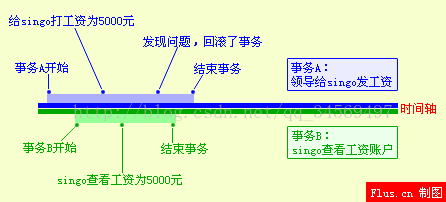
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高 兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有 2000元,singo空欢喜一场。
出现上述情况,即我们所说的脏读 ,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Read uncommitted 时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
Read committed 读提交
singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在 singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为 何......
出现上述情况,即我们所说的不可重复读 ,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed 时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
Repeatable read 重复读
在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
当隔离级别设置为Repeatable read 时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读 。
singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额 (select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction ... ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出 现了幻觉,幻读就这样产生了。
注:Mysql的默认隔离级别就是Repeatable read。
不可重复读和脏读的区别是:脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
Serializable 序列化(串行化)
Serializable 是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻读。
四、数据库设计三大范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
在实际开发中最为常见的设计范式有三个:
1.第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
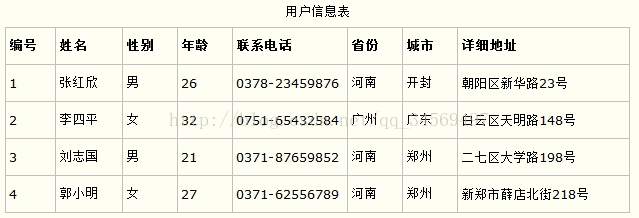
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
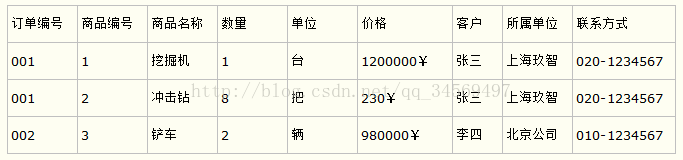
订单信息表
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。

这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。

这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。