目录
一、简介
- 什么是任务队列?
任务队列用作在线程或计算机之间分配工作的机制。
任务队列的输入是称为任务的工作单元。专用的工作进程会不断监视任务队列以执行新工作。
Celery通过消息进行通信,通常使用代理在clients和worker之间进行调解。为了启动任务,客户端将消息添加到队列中,然后代理将消息传递给工作人员。
celery系统可以由多个 workers 和 brokers组成,让位于高可用性和水平扩展。
Celery用Python编写,但是该协议可以用任何语言实现。除了Python,还有Node.js 的node-celery和node-celery-ts,以及一个PHP客户端。
语言互操作性也可以通过公开HTTP终结点并具有请求该终结点的任务来实现(Webhooks)。
Celery由以下三部分构成:消息中间件(Broker)、任务执行单元Worker、结果存储(Backend),如下图
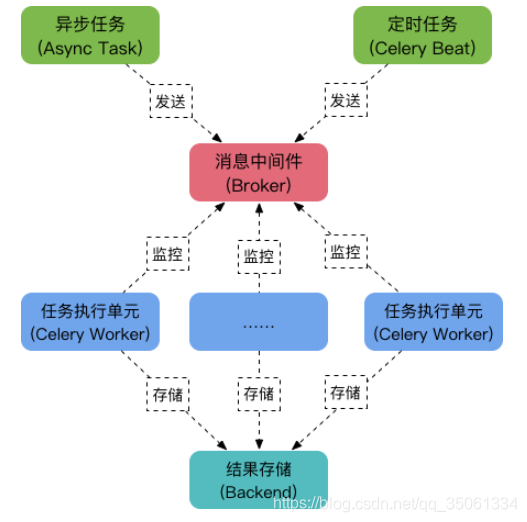
celery集群的运作流程:
从上图可见,相关的celery的编程模型中,划分为三个部分,分别是:
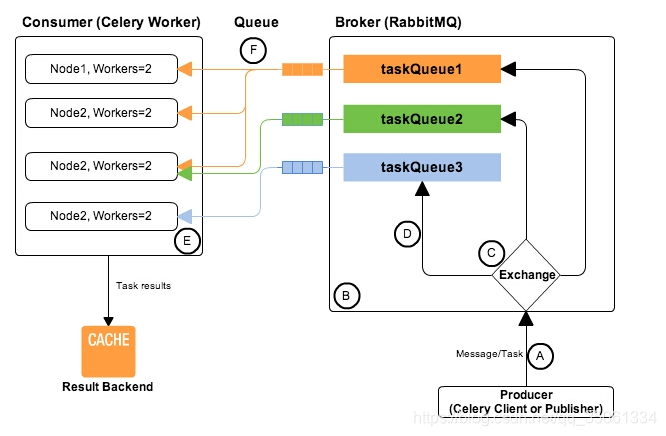
1,Producer(celery client): 负责生产相关的task,并发送到一个broker中。
2,broker: 作为一个task的路由器,将task分发到不同的接收者。这里broker实现对rabbitmq的封装,屏蔽了rabbitmq复杂的调用细节。
3,Consumer(celery worker):接收到task以后,负责根据task的信息结构,执行相关的功能。
简单说,可以有多个"消息队列"(message Queue),不同的消息可以指定发送给不同的Message Queue,而这是通过Exchange来实现的,发送消息到"消息队列"中时,可以指定routiing_key,Exchange通过routing_key来把消息路由(routes)到不同的"消息队列"中去。Exchange 对应一个消息队列(queue),即:通过"消息路由"的机制使Exchange对应queue,每个queue对应每个worker。
注:任务队列与消息队列都是由队列实现的异步协议,只是消息队列(Message Queue) 用来做异步通信,而任务队列(Task Queue) 更强调异步执行的任务。实际上发送消息也是一个任务,也就是说任务队列是在消息队列之上的管理工作,任务队列的很多典型应用就是发送消息,如发送邮件,发送短信,发送消息推送等。
celery 和 redis 之间交互的基本原理
1、当发起一个 task 时,会向 redis 的 celery key 中插入一条记录。
2、如果这时有正在待命的空闲 worker,这个 task 会立即被 worker 领取。
3、如果这时没有空闲的 worker,这个 task 的记录会保留在 celery key 中。
4、这时会将这个 task 的记录从 key celery 中移除,并添加相关信息到 unacked 和 unacked_index 中。
5、worker 根据 task 设定的期望执行时间执行任务,如果接到的不是延时任务或者已经超过了期望时间,则立刻执行。
6、worker 开始执行任务时,通知 redis。(如果设置了 CELERY_ACKS_LATE = True 那么会在任务执行结束时再通知)
7、redis 接到通知后,将 unacked 和 unacked_index 中相关记录移除。
8、如果在接到通知前,worker 中断了,这时 redis 中的 unacked 和 unacked_index 记录会重新回到 celery key 中。(这个回写的操作是由 worker 在 “临死” 前自己完成的,所以在关闭 worker 时为防止任务丢失,请务必使用正确的方法停止它,如: celery multi stop w1 -A proj1)
9、在 celery key 中的 task 可以再次重复上述 2 以下的流程。
10、celery 只是利用 redis 的 list 类型,当作个简单的 Queue,并没有使用消息订阅等功能
celery主要应用场景:

二、celery集群部署
1.1、server节点
1.1.1、安装celery
如果使用 Redis 作为中间人(Broker)必须要安装 Celery 的依赖库,您可以通过 celery[redis] 进行安装:
pip3 install -U "celery[redis]"
备注使用该命令会把下面功能全部安装:Successfully installed amqp-2.5.2 billiard-3.6.3.0 celery-4.4.2 importlib-metadata-1.6.0 kombu-4.6.8 pytz-2020.1 redis-3.5.1 vine-1.3.0 zipp-3.1.0
其他种方式
pip3 install celery
配置了解:链接.
1.1.2、选择中间人(Broker)
决定使用哪个作为Broker? 这里使用redis
Celery 支持多种消息传输的方式。
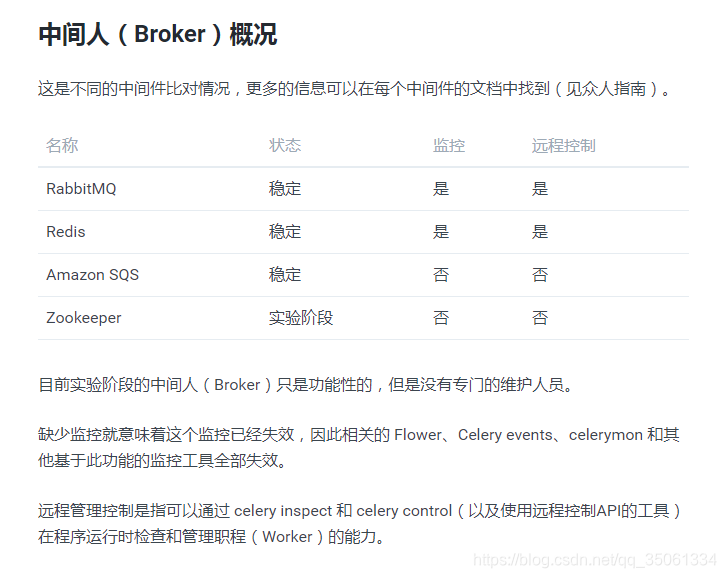
Celery 需要一个中间件来进行接收和发送消息,通常以独立的服务形式出现,成为 消息中间人(Broker)
以下有几种选择:
-
RabbitMQ
RabbitMQ 的功能比较齐全、稳定、便于安装。在生产环境来说是首选的,有关 Celery 中使用 RabbitMQ 的详细信息: -
Redis
Redis 功能比较全,但是如果突然停止运行或断电会造成数据丢失
1.1.2.1、如果选择使用redis,请安装配置
安装redis-server
sudo apt-get install redis-server
配置redis允许远程连接
- 配置redis.conf
1、将 bind 127.0.0.1 使用#注释掉
2、将 protected-mode yes 改为 protected-mode no(3.2之后加入的新特性,目的是禁止公网访问redis cache,增强redis的安全性)
3、将 requirepass foobared 注释去掉,foobared为密码,也可修改为别的值(可选,建议设置) - 设置iptables规则,允许外部访问6379端口
iptables -I INPUT 1 -p tcp -m state --state NEW -m tcp --dport 6379 -j ACCEPT
解决问题:连接Redis服务出现DENIED Redis is running in protected mode because protected mode is enabled
protected-mode yes 改为no
在执行任务之前需要启动redis,使用这个命令
src/redis-server --protected-mode no
扩展(了解):
在 Docker 中运行 Redis ,可以通过以下命令实现(不用这种方式的可以不关注):
$ docker run -d -p 6379:6379 redis
1.1.2.2、如果选择使用RabbitMQ,请安装配置
使用RabbitMQ
如果您使用的是 Ubuntu 或 Debian ,可以通过以下命令进行安装 RabbitMQ:
$ sudo apt-get install rabbitmq-server
pip install "celery[librabbitmq,redis,auth,msgpack]"
如果在 Docker 中运行 RabbitMQ ,可以使用以下命令:
$ docker run -d -p 5462:5462 rabbitmq
命令执行完毕之后,中间人(Broker)会在后台继续运行,准备输出一条 Starting rabbitmq-server: SUCCESS 的消息。
如果您没有 Ubuntu 或 Debian ,你可以访问官方网站查看其他操作系统(如:Windows)的安装方式:
http://www.rabbitmq.com/download.html
1.1.3、拷贝项目代码到机子上
简单的项目demo
[root@localhost base_demo]# cat tasks.py
from celery import Celery
app = Celery('tasks', broker='redis://192.168.2.220:6379/0')
@app.task
def add(x, y):
return x + y
[root@localhost base_demo]# cat test.py
from tasks import add
add.delay(4, 4)
1.1.4、启动worker
执行下面的命令启动worker,执行任务(下面的两个命令都可以用)
celery是以app来管理任务的
//tasks:是要管理的app名 ,即项目名
celery -A tasks worker -l info
各个参数含义:
worker: 代表第启动的角色是work当然还有beat等其他角色;
-A :项目路径,这里我的目录是project
-l:启动的日志级别,更多参数使用celery --help查看
1.2、worker节点
1.2.1、安装celery
pip3 install celery
1.2.2、拷贝项目代码到机子上
简单的项目demo(这里的redis ip一般默认是127.0.0.1 ,如果自己配置了用自己配置的redis ip,我这里是在 1.1.2.2章节配置设置的是server机子的ip地址)
[root@localhost base_demo]# cat tasks.py
from celery import Celery
app = Celery('tasks', broker='redis://192.168.2.220:6379/0')
@app.task
def add(x, y):
return x + y
[root@localhost base_demo]# cat test.py
from tasks import add
add.delay(4, 4)
1.2.3、启动worker
celery worker -A tasks -l info
三、celery参数
celery.bin.worker
用于启动芹菜工作实例的程序。
芹菜工人命令(以前称为celeryd)
-c, --concurrency
处理队列的子进程的数目。默认值是系统上可用的cpu数量。
-P, --pool
池实现:
prefork(默认)、eventlet、gevent、threads或solo。
-n, --hostname
设置自定义主机名(例如,' w1@%%h ')。扩展:%%h(主机名)、%%n(名称)和%%d(域)。
-B, --beat
还可以运行芹菜打周期任务调度程序。请注意,此服务只能有一个实例。
请注意
-B用于开发目的。对于生产环境,您需要分别启动芹菜打。
-Q, --queues
为这个worker启用的队列列表,以逗号分隔。默认情况下,所有配置的队列都是启用的。例如:q视频,形象
- x, exclude-queues
要为此工作程序禁用的队列列表,用逗号分隔。默认情况下,所有配置的队列都是启用的。例子:- x视频,形象。
-I, --include
用逗号分隔要导入的其他模块列表。例子:我foo.tasks bar.tasks
-s, --schedule
如果使用-B选项运行,则指向调度数据库的路径。默认为celerybeat-schedule。扩展”。可以将db "附加到文件名中。
- o
应用优化概要文件。支持:默认情况下,公平
--prefetch-multiplier
为这个工作者实例设置自定义预取乘数值。
--scheduler
要使用的调度程序类。默认是celery.beat.PersistentScheduler
-S, --statedb
到状态数据库的路径。扩展”。可以将db '附加到文件名中。默认值:{默认}
-E, --task-events
发送可以被监视器捕获的与任务相关的事件,如芹菜事件、celerymon和其他事件。
--without-gossip
不要订阅其他员工活动。
--without-mingle
在刚开始的时候不要和其他员工同步。
--without-heartbeat
不要发送事件心跳。
--heartbeat-interval
发送工作者心跳的间隔(秒)
--purge
在启动守护进程之前清除所有等待的任务。警告:这是不可恢复的,任务将从消息传递服务器中删除。
--time-limit
为任务启用硬时间限制(以秒为单位的int/float)。
--soft-time-limit
为任务启用软时间限制(以秒为单位int/float)。
--max-tasks-per-child
池工作程序在终止并被新工作程序替换之前可以执行的最大任务数。
--max-memory-per-child
在KiB中,子进程在被新进程替换之前可能消耗的最大驻留内存量。如果单个任务导致子进程超过此限制,则该任务将被完成,然后子进程将被替换。默认值:没有限制。
--autoscale
通过提供max_concurrency、min_concurrency启用自动调焦。例子:
--autoscale=10,3
(始终保持3个进程,但如果需要,可以增加到10个)
--detach
启动worker作为后台进程。
-f, --logfile
日志文件的路径。如果没有指定日志文件,则使用stderr。
-l, --loglevel
日志级别,在调试、信息、警告、错误、关键或致命之间进行选择。
--pidfile
可选文件,用于存储进程pid。
如果这个文件已经存在并且pid仍然是活动的,程序将不会启动。
--uid
用户id,或用户的用户名,以在分离后运行。
--gid
组id,或主组的组名,在分离后更改为。
--umask
分离后工艺的有效umask(1)(八进制)。默认情况下继承父进程的umask(1)。
--workdir
可选目录切换到分离后。
--executable
可执行文件,用于分离的进程。
参考官方文档:
1、Celery 4.4.2文档