在单样本问题中, 人们想要检验的是总体的中心是否等于一个已知的值. 但在实际问题中, 更受注意的往往是比较两个总体的位置参数; 比如, 两种训练方法中哪一种更出成绩, 两种汽油中哪一种污染更少, 两种市场营销策略中哪种更有效等等.
1. χ 2 \chi^2 χ2独立性检验的原理
若随机变量
X
,
Y
X,Y
X,Y的分布函数分别为
F
1
(
x
)
和
F
2
(
y
)
F_1(x) 和 F_2(y)
F1(x)和F2(y), 且联合分布为
F
(
x
,
y
)
F(x, y)
F(x,y), 则X与Y的独立性归结为假设检验问题:
H
0
:
F
(
x
,
y
)
=
F
1
(
x
)
F
2
(
y
)
H
1
:
F
(
x
,
y
)
≠
F
1
(
x
)
F
2
(
y
)
H_0: F(x,y)=F_1(x)F_2(y) \quad H_1: F(x,y)\neq F_1(x)F_2(y)
H0:F(x,y)=F1(x)F2(y)H1:F(x,y)=F1(x)F2(y)
若X与Y为分类变量,其中X的取值为
X
1
,
X
2
,
.
.
.
,
X
r
X_1, X_2,...,X_r
X1,X2,...,Xr, Y的取值为
Y
1
,
Y
2
,
.
.
.
,
Y
s
Y_1,Y_2,...,Y_s
Y1,Y2,...,Ys, 将X与Y的各种情况组合用一张
r
×
s
r \times s
r×s列联表表示,称为
r
×
s
r\times s
r×s二维列联表,如下图所示:
表中
n
i
j
n_{ij}
nij表示n个随机试验的结果中X取
X
i
X_i
Xi及Y取
Y
j
Y_j
Yj的频数,
∑
i
=
1
r
∑
j
=
1
s
n
i
j
=
n
\sum_{i=1}^r\sum_{j=1}^sn_{ij}=n
∑i=1r∑j=1snij=n.
n
i
.
=
∑
j
=
1
s
n
i
j
,
i
=
1
,
2
,
.
.
.
,
r
,
表
示
各
行
之
和
n_{i.}=\sum_{j=1}^sn_{ij}, i=1,2,...,r, 表示各行之和
ni.=j=1∑snij,i=1,2,...,r,表示各行之和
n
.
j
=
∑
i
=
1
r
n
i
j
,
j
=
1
,
2
,
.
.
.
s
,
表
示
各
列
之
和
n_{.j}=\sum_{i=1}^rn_{ij}, j=1,2,...s, 表示各列之和
n.j=i=1∑rnij,j=1,2,...s,表示各列之和
令
p
i
j
=
P
(
X
=
X
i
,
Y
=
Y
j
)
,
p
i
.
=
P
(
X
=
X
i
)
,
p
.
j
=
P
(
Y
=
Y
j
)
,
i
=
1
,
2
,
.
.
.
,
r
;
j
=
1
,
2
,
.
.
.
,
s
,
p_{ij}=P(X=X_i, Y=Y_j), p_{i.}=P(X=X_i), p_{.j}=P(Y=Y_j), i=1,2,...,r; j=1,2,...,s,
pij=P(X=Xi,Y=Yj),pi.=P(X=Xi),p.j=P(Y=Yj),i=1,2,...,r;j=1,2,...,s, 则X与Y的独立性检验等价于下述检验:
H
0
:
p
i
j
=
p
i
.
p
.
j
,
∀
1
≤
i
≤
r
,
1
≤
j
≤
s
H
1
:
∃
(
i
,
j
)
,
p
i
j
≠
p
i
.
p
.
j
H_0: p_{ij} = p_{i.}p_{.j}, \forall 1\le i \le r, 1\le j \le s \quad H_1: \exist (i,j), p_{ij}\neq p_{i.}p_{.j}
H0:pij=pi.p.j,∀1≤i≤r,1≤j≤sH1:∃(i,j),pij=pi.p.j
注: 若X与Y 为连续型随机变量, 这时将它们的取值范围分成r个及s个互不相交的小区间, 用
n
i
j
n_{ij}
nij 表示n个随机试验的结果中“X属于第i个小区间, Y 属于第k个小区间”的频数
(
i
=
1
,
2
,
.
.
.
,
r
;
k
=
1
,
2
,
.
.
.
,
s
)
(i=1,2,...,r; k=1,2,...,s)
(i=1,2,...,r;k=1,2,...,s) 这时可将X与Y 的独立性转化为列联表的独立性检验问题.
由于
p
i
.
p_{i.}
pi.的极大似然估计为
p
^
i
.
=
n
i
.
/
n
\hat p_{i.} = n_{i.}/n
p^i.=ni./n,
p
.
j
p_{.j}
p.j的极大似然估计为
p
^
.
j
/
n
\hat p_{.j}/n
p^.j/n, 因此若
H
0
H_0
H0成立,则
p
i
j
p_{ij}
pij的极大似然估计为
p
^
i
.
p
^
.
j
=
n
i
.
n
.
j
/
n
2
\hat p_{i.} \hat p_{.j}=n_{i.}n_{.j}/n^2
p^i.p^.j=ni.n.j/n2. 从而X取代
X
i
X_i
Xi, Y取代
Y
j
Y_j
Yj(试验数据落入第
(
i
,
j
)
(i,j)
(i,j)个类)的理论频数为
n
×
n
i
.
n
.
j
/
n
2
=
n
i
.
n
.
j
/
n
n \times n_{i.}n_{.j}/n^2 = n_{i.}n_{.j}/n
n×ni.n.j/n2=ni.n.j/n. 由此构造检验统计量为:
χ
2
=
∑
i
=
1
r
∑
k
=
1
s
[
n
i
j
−
n
i
.
n
.
j
n
]
2
/
n
i
.
n
.
j
n
\chi^2=\sum_{i=1}^r\sum_{k=1}^s[n_{ij}-\frac{n_{i.}n_{.j}}{n}]^2/\frac{n_{i.}n_{.j}}{n}
χ2=i=1∑rk=1∑s[nij−nni.n.j]2/nni.n.j
可以证明在原假设成立时,
χ
2
\chi^2
χ2近似服从
χ
2
(
(
r
−
1
)
(
s
−
1
)
)
\chi^2((r-1)(s-1))
χ2((r−1)(s−1))

2. 使用Python展示和计算
在python中的pandas库中有一个DataFrame的数据结构,可以用来保存二维数据,并进行计算。
例1: 对表1所示频数分布表,以59%显著水平,检验色觉与性别是否相关。
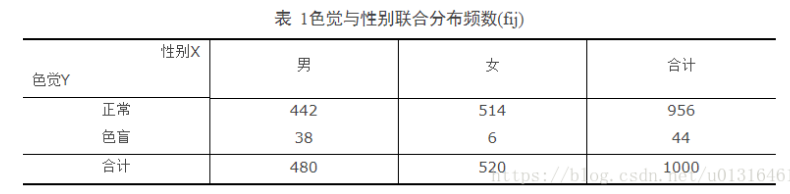
2. 1. 初始化数据
import numpy as np
import pandas as pd
from scipy import stats
d=np.array([[442, 514],[38,6]])
r,s = d.shape
df = pd.DataFrame(d, columns=['male', 'female'], index=['normal', 'blindness'])
上述代码已将初始化数据存入df,显示如下:
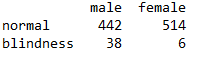
2.2. 计算边际频数
首先在df基础上建立一个数据框(数据一致)。并在新建的数据框基础继续计算。
df1 = df[:]
df1= pd.DataFrame(df1)
df1['r_tot']=np.sum(df1,axis=1)
df1.loc['c_tot']=np.sum(df1, axis=0)
经过上面的处理,df1就是带有编辑频数的数据框。显示如下:

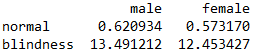
2.3. 计算理论频数分布表
r_tot = df1['r_tot'][:-1]
c_tot=df1.loc['c_tot'][:-1]
total = np.sum(r_tot)
data = np.zeros((r,s))
for i in range(len(r_tot)):
for j in range(len(c_tot)):
data[i,j]=r_tot[i]*c_tot[j]/total
df2=pd.DataFrame(data, index=['normal', 'blindness'], columns=['male', 'female'])
至此,我们将计算得到的理论频数分布表保存在了df2中,而原始数据在df中,如下图所示:

2.4. 统计量计算
为了清晰整个计算过程,这里添加一步(对计算结果来说是多余的)产生统计量数据框的代码:
(df-df2)**2/df2
其产生的统计量数据框如下图:
其实,下面一行代码即可获得卡方统计量的值并获取pval:
chi_square=np.sum((df-df2)**2/df2).sum()
stats.chi2.sf(chi_squre, df=(r-1)*(s-1))
得到
χ
2
=
27.13874340443378
,
p
v
a
l
=
1.8936459120177876
e
−
07
\chi^2=27.13874340443378, pval=1.8936459120177876e-07
χ2=27.13874340443378,pval=1.8936459120177876e−07
因为
p
v
a
l
<
α
=
0.05
pval \lt \alpha=0.05
pval<α=0.05, 所以拒绝原假设,可以认为色盲和性别有关系