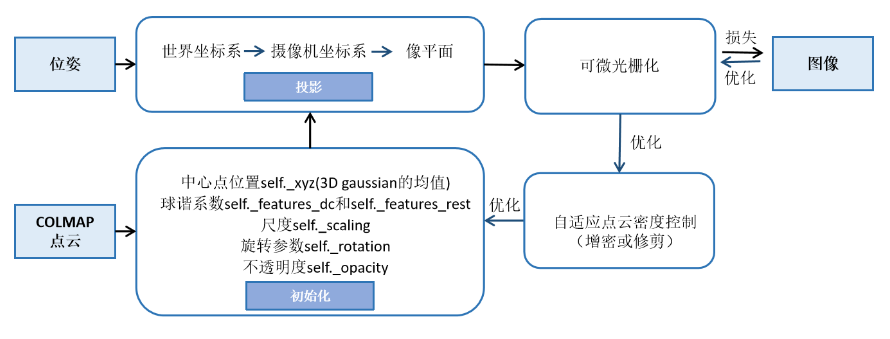
 1 模型训练
1 模型训练
这段代码实现了一个 3D 高斯模型的训练循环,旨在通过逐步优化模型参数,使其能够精确地渲染特定场景。以下是代码的详细解析:
def training(dataset, opt, pipe, testing_iterations, saving_iterations, checkpoint_iterations, checkpoint, debug_from):
first_iter = 0
# 初始化高斯模型,用于表示场景中的每个点的3D高斯分布
gaussians = GaussianModel(dataset.sh_degree)
# 初始化场景对象,加载数据集和对应的相机参数
scene = Scene(dataset, gaussians)
# 为高斯模型参数设置优化器和学习率调度器
gaussians.training_setup(opt)
# 如果提供了checkpoint,则从checkpoint加载模型参数并恢复训练进度
if checkpoint:
(model_params, first_iter) = torch.load(checkpoint)
gaussians.restore(model_params, opt)
# 设置背景颜色,白色或黑色取决于数据集要求
bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]
background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")
# 创建CUDA事件用于计时
iter_start = torch.cuda.Event(enable_timing=True)
iter_end = torch.cuda.Event(enable_timing=True)
viewpoint_stack = None
ema_loss_for_log = 0.0
# 使用tqdm库创建进度条,追踪训练进度
progress_bar = tqdm(range(first_iter, opt.iterations), desc="Training progress")
first_iter += 1
for iteration in range(first_iter, opt.iterations + 1):
# 记录迭代开始时间
iter_start.record()
# 根据当前迭代次数更新学习率
gaussians.update_learning_rate(iteration)
# 每1000次迭代,提升球谐函数的次数以改进模型复杂度
if iteration % 1000 == 0:
gaussians.oneupSHdegree()
# 随机选择一个训练用的相机视角
if not viewpoint_stack:
viewpoint_stack = scene.getTrainCameras().copy()
viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack)-1))
# 如果达到调试起始点,启用调试模式
if (iteration - 1) == debug_from:
pipe.debug = True
# 根据设置决定是否使用随机背景颜色
bg = torch.rand((3), device="cuda") if opt.random_background else background
# 渲染当前视角的图像
render_pkg = render(viewpoint_cam, gaussians, pipe, bg)
image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"]
# 计算渲染图像与真实图像之间的损失
gt_image = viewpoint_cam.original_image.cuda()
Ll1 = l1_loss(image, gt_image)
loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim(image, gt_image))
loss.backward()
# 记录迭代结束时间
iter_end.record()
with torch.no_grad():
# 更新进度条和损失显示
ema_loss_for_log = 0.4 * loss.item() + 0.6 * ema_loss_for_log
if iteration % 10 == 0:
progress_bar.set_postfix({"Loss": f"{ema_loss_for_log:.{7}f}"})
progress_bar.update(10)
if iteration == opt.iterations:
progress_bar.close()
# 定期记录训练数据并保存模型
training_report(tb_writer, iteration, Ll1, loss, l1_loss, iter_start.elapsed_time(iter_end), testing_iterations, scene, render, (pipe, background))
if iteration in saving_iterations:
print("\n[ITER {}] Saving Gaussians".format(iteration))
scene.save(iteration)
# 在指定迭代区间内,对3D高斯模型进行增密和修剪
if iteration < opt.densify_until_iter:
gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter])
gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)
if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:
size_threshold = 20 if iteration > opt.opacity_reset_interval else None
gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold)
if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter):
gaussians.reset_opacity()
# 执行优化器的一步,并准备下一次迭代
if iteration < opt.iterations:
gaussians.optimizer.step()
gaussians.optimizer.zero_grad(set_to_none=True)
# 定期保存checkpoint
if iteration in checkpoint_iterations:
print("\n[ITER {}] Saving Checkpoint".format(iteration))
torch.save((gaussians.capture(), iteration), scene.model_path + "/chkpnt" + str(iteration) + ".pth")
函数解析
training(dataset, opt, pipe, testing_iterations, saving_iterations, checkpoint_iterations, checkpoint, debug_from)
该函数的作用是加载数据、设置场景和高斯模型的初始化参数,通过迭代训练模型,调整模型参数,以减小渲染图像与真实图像之间的误差。
- 参数:
dataset: 数据集对象,包含图像和相机参数。opt: 配置对象,包含训练过程的超参数,如学习率和迭代次数。pipe: 渲染管道,用于生成渲染图像。testing_iterations: 在这些迭代次数中进行测试。saving_iterations: 在这些迭代次数中保存高斯模型。checkpoint_iterations: 在这些迭代次数中保存 checkpoint。checkpoint: 如果提供了 checkpoint 文件,则从中恢复模型状态。debug_from: 设定调试起始点,达到该迭代后启用调试模式。
整个函数旨在通过高斯模型增密、学习率调整、定期保存 checkpoint 和渲染优化,训练一个能够表示 3D 场景的高斯模型。
2 数据加载
2.1 Class Scene:
这段代码定义了
Scene类,用于管理和加载 3D 场景的参数、模型和相机信息,并支持不同分辨率的相机数据。Scene类结合了高斯模型和数据集处理逻辑,尤其适用于从 COLMAP 或 Blender 数据集中加载相机和场景信息,以便进行 3D 表示和训练。
class Scene:
"""
Scene 类用于管理场景的3D模型,包括相机参数、点云数据和高斯模型的初始化和加载
"""
def __init__(self, args: ModelParams, gaussians: GaussianModel, load_iteration=None, shuffle=True, resolution_scales=[1.0]):
"""
初始化场景对象
:param args: 包含模型路径和源路径等模型参数
:param gaussians: 高斯模型对象,用于场景点的3D表示
:param load_iteration: 指定加载模型的迭代次数,如果为-1,则自动寻找最大迭代次数
:param shuffle: 是否在训练前打乱相机列表
:param resolution_scales: 分辨率比例列表,用于处理不同分辨率的相机
"""
self.model_path = args.model_path # 模型文件保存路径
self.loaded_iter = None # 已加载的迭代次数
self.gaussians = gaussians # 高斯模型对象
# 检查并加载已有的训练模型
if load_iteration:
if load_iteration == -1:
self.loaded_iter = searchForMaxIteration(os.path.join(self.model_path, "point_cloud"))
else:
self.loaded_iter = load_iteration
print(f"Loading trained model at iteration {self.loaded_iter}")
self.train_cameras = {} # 用于训练的相机参数
self.test_cameras = {} # 用于测试的相机参数
# 根据数据集类型(COLMAP或Blender)加载场景信息
if os.path.exists(os.path.join(args.source_path, "sparse")):
scene_info = sceneLoadTypeCallbacks["Colmap"](args.source_path, args.images, args.eval)
elif os.path.exists(os.path.join(args.source_path, "transforms_train.json")):
print("Found transforms_train.json file, assuming Blender data set!")
scene_info = sceneLoadTypeCallbacks["Blender"](args.source_path, args.white_background, args.eval)
else:
assert False, "Could not recognize scene type!"
# 如果是初次训练,初始化3D高斯模型;否则,加载已有模型
if self.loaded_iter:
self.gaussians.load_ply(os.path.join(self.model_path, "point_cloud", "iteration_" + str(self.loaded_iter), "point_cloud.ply"))
else:
self.gaussians.create_from_pcd(scene_info.point_cloud, self.cameras_extent)
# 根据resolution_scales加载不同分辨率的训练和测试位姿
for resolution_scale in resolution_scales:
print("Loading Training Cameras")
self.train_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.train_cameras, resolution_scale, args)
print("Loading Test Cameras")
self.test_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.test_cameras, resolution_scale, args)
def save(self, iteration):
"""
保存当前迭代下的3D高斯模型点云。
:param iteration: 当前的迭代次数。
"""
point_cloud_path = os.path.join(self.model_path, f"point_cloud/iteration_{iteration}")
self.gaussians.save_ply(os.path.join(point_cloud_path, "point_cloud.ply"))
def getTrainCameras(self, scale=1.0):
"""
获取指定分辨率比例的训练相机列表
:param scale: 分辨率比例
:return: 指定分辨率比例的训练相机列表
"""
return self.train_cameras[scale]
sceneLoadTypeCallbacks = {
"Colmap": readColmapSceneInfo,
"Blender" : readNerfSyntheticInfo
}类属性和方法解析
1.
__init__(self, args: ModelParams, gaussians: GaussianModel, load_iteration=None, shuffle=True, resolution_scales=[1.0])构造函数
__init__用于初始化Scene对象,加载数据集和初始化 3D 高斯模型,并为训练和测试分辨率管理相机参数。
参数:
args:包含模型路径和源路径等配置参数。gaussians:高斯模型对象,用于管理场景中的 3D 高斯分布。load_iteration:指定加载的迭代次数,若为 -1,自动搜索最后保存的模型。shuffle:是否对相机列表进行随机排序。resolution_scales:用于管理不同分辨率下的相机数据。主要步骤:
- 加载已有模型:如果
load_iteration不为None,加载指定迭代次数的模型;若load_iteration == -1,加载最新迭代的模型。- 场景信息加载:通过回调函数
sceneLoadTypeCallbacks,从COLMAP或Blender数据集中加载场景信息。- 初始化高斯模型:如果没有加载已有的模型,调用
create_from_pcd方法,使用从数据集中加载的点云初始化高斯模型。- 分辨率管理:根据
resolution_scales参数加载不同分辨率的训练和测试相机列表,分别存储在self.train_cameras和self.test_cameras字典中。2.
save(self, iteration)该方法用于在指定的
iteration下保存当前 3D 高斯模型的点云数据。
参数:
iteration:当前的迭代次数。实现:
- 根据
iteration创建路径,并调用self.gaussians.save_ply保存点云数据。3.
getTrainCameras(self, scale=1.0)该方法用于获取指定分辨率比例的训练相机列表。
参数:
scale:分辨率比例(默认为 1.0),用来返回该分辨率对应的训练相机列表。返回值:
- 以
scale为键从self.train_cameras中获取对应的相机列表。4.
sceneLoadTypeCallbacks
sceneLoadTypeCallbacks是一个字典,用于匹配和回调不同数据集的加载函数:
- 如果数据集是
COLMAP类型,调用readColmapSceneInfo。- 如果是
Blender数据集,调用readNerfSyntheticInfo。示例流程
初始化:
Scene类根据数据集路径自动检测数据类型,并调用合适的回调函数加载相机和场景信息。分辨率和相机管理:
- 支持不同分辨率的训练和测试相机列表。用户可以通过
getTrainCameras(scale)获取指定分辨率下的训练相机。保存:
- 在指定的迭代次数
iteration下,调用save()将 3D 高斯模型点云数据保存为.ply文件。代码优点
- 模块化和扩展性:支持多种数据集格式,并允许通过回调函数轻松扩展至其他格式。
- 分辨率管理:灵活加载和管理不同分辨率的相机列表,以便在训练和测试中使用不同精度的相机数据
2.2 readColmapSceneInfo 和 readColmapCameras
这段代码提供了两个主要函数 readColmapSceneInfo 和 readColmapCameras,用于读取和处理 COLMAP 生成的相机参数和场景信息,并将其格式化为易于使用的数据结构。这些函数为后续 3D 重建和 NeRF 训练准备相机参数、点云数据及其他场景归一化信息。
def readColmapSceneInfo(path, images, eval, llffhold=8):
# 尝试读取COLMAP处理结果中的二进制相机外参和内参文件
try:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.bin")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.bin")
cam_extrinsics = read_extrinsics_binary(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_binary(cameras_intrinsic_file)
except:
# 如果二进制文件读取失败,尝试读取文本格式的相机外参和内参文件
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.txt")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.txt")
cam_extrinsics = read_extrinsics_text(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_text(cameras_intrinsic_file)
# 定义存放图片的目录,如果未指定则默认为"images"
reading_dir = "images" if images is None else images
# 读取并处理相机参数,转换为内部使用的格式
cam_infos_unsorted = readColmapCameras(cam_extrinsics=cam_extrinsics, cam_intrinsics=cam_intrinsics, images_folder=os.path.join(path, reading_dir))
# 根据图片名称对相机信息进行排序,以保证顺序一致性
cam_infos = sorted(cam_infos_unsorted.copy(), key=lambda x: x.image_name)
# 根据是否为评估模式(eval),将相机分为训练集和测试集
# 如果为评估模式,根据llffhold参数(通常用于LLFF数据集)间隔选择测试相机
if eval:
train_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold != 0]
test_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold == 0]
else:
# 如果不是评估模式,所有相机均为训练相机,测试相机列表为空
train_cam_infos = cam_infos
test_cam_infos = []
# 计算场景归一化参数,这是为了处理不同尺寸和位置的场景,使模型训练更稳定
nerf_normalization = getNerfppNorm(train_cam_infos)
# 尝试读取点云数据,优先从PLY文件读取,如果不存在,则尝试从BIN或TXT文件转换并保存为PLY格式
ply_path = os.path.join(path, "sparse/0/points3D.ply")
bin_path = os.path.join(path, "sparse/0/points3D.bin")
txt_path = os.path.join(path, "sparse/0/points3D.txt")
if not os.path.exists(ply_path):
print("Converting point3d.bin to .ply, will happen only the first time you open the scene.")
try:
xyz, rgb, _ = read_points3D_binary(bin_path)
except:
xyz, rgb, _ = read_points3D_text(txt_path)
storePly(ply_path, xyz, rgb)
try:
pcd = fetchPly(ply_path)
except:
pcd = None
# 组装场景信息,包括点云、训练用相机、测试用相机、场景归一化参数和点云文件路径
scene_info = SceneInfo(point_cloud=pcd,
train_cameras=train_cam_infos,
test_cameras=test_cam_infos,
nerf_normalization=nerf_normalization,
ply_path=ply_path)
return scene_info
def readColmapCameras(cam_extrinsics, cam_intrinsics, images_folder):
cam_infos = [] # 初始化用于存储相机信息的列表
# 遍历所有相机的外参
for idx, key in enumerate(cam_extrinsics):
# 动态显示读取相机信息的进度
sys.stdout.write('\r')
sys.stdout.write("Reading camera {}/{}".format(idx+1, len(cam_extrinsics)))
sys.stdout.flush()
# 获取当前相机的外参和内参
extr = cam_extrinsics[key] # 当前相机的外参
intr = cam_intrinsics[extr.camera_id] # 根据外参中的camera_id找到对应的内参
height = intr.height # 相机图片的高度
width = intr.width # 相机图片的宽度
uid = intr.id # 相机的唯一标识符
# 将四元数表示的旋转转换为旋转矩阵R
R = np.transpose(qvec2rotmat(extr.qvec))
# 外参中的平移向量
T = np.array(extr.tvec)
# 根据相机内参模型计算视场角(FoV)
if intr.model == "SIMPLE_PINHOLE":
# 如果是简单针孔模型,只有一个焦距参数
focal_length_x = intr.params[0]
FovY = focal2fov(focal_length_x, height) # 计算垂直方向的视场角
FovX = focal2fov(focal_length_x, width) # 计算水平方向的视场角
elif intr.model == "PINHOLE":
# 如果是针孔模型,有两个焦距参数
focal_length_x = intr.params[0]
focal_length_y = intr.params[1]
FovY = focal2fov(focal_length_y, height) # 使用y方向的焦距计算垂直视场角
FovX = focal2fov(focal_length_x, width) # 使用x方向的焦距计算水平视场角
else:
# 如果不是以上两种模型,抛出错误
assert False, "Colmap camera model not handled: only undistorted datasets (PINHOLE or SIMPLE_PINHOLE cameras) supported!"
# 构建图片的完整路径
image_path = os.path.join(images_folder, os.path.basename(extr.name))
image_name = os.path.basename(image_path).split(".")[0] # 提取图片名称,不包含扩展名
# 使用PIL库打开图片文件
image = Image.open(image_path)
# 创建并存储相机信息
cam_info = CameraInfo(uid=uid, R=R, T=T, FovY=FovY, FovX=FovX, image=image,
image_path=image_path, image_name=image_name, width=width, height=height)
cam_infos.append(cam_info)
# 在读取完所有相机信息后换行
sys.stdout.write('\n')
# 返回整理好的相机信息列表
return cam_infos
函数解析
1. readColmapSceneInfo(path, images, eval, llffhold=8)
该函数负责读取和解析 COLMAP 数据集的场景信息,包括相机参数、点云和归一化参数等。主要步骤如下:
相机参数文件读取:
- 首先尝试读取二进制格式的相机外参 (
images.bin) 和内参 (cameras.bin) 文件,若读取失败则尝试加载文本格式的文件(images.txt和cameras.txt)。- 外参和内参分别通过
read_extrinsics_binary和read_intrinsics_binary等函数加载。相机信息解析:
- 调用
readColmapCameras函数解析外参和内参文件中的相机数据,并返回相机列表cam_infos。训练和测试集划分:
- 根据
eval参数决定是否将数据集划分为训练集和测试集。- 如果为评估模式 (
eval=True),会根据llffhold参数(通常用于 LLFF 数据集)进行间隔划分,得到train_cam_infos和test_cam_infos。场景归一化参数计算:
- 调用
getNerfppNorm函数,对训练集中的相机位姿进行归一化,确保不同场景的尺度和位置对齐,以便更稳定的训练。点云文件读取与转换:
- 点云文件优先从
points3D.ply文件中读取;若不存在则尝试从二进制或文本格式的points3D文件中读取,并转换为.ply文件存储。- 最终通过
fetchPly函数读取.ply格式的点云数据。返回值:
- 将
SceneInfo对象返回,其中包含点云数据、训练相机、测试相机、归一化参数和点云文件路径。
2. readColmapCameras(cam_extrinsics, cam_intrinsics, images_folder)
该函数用于将
cam_extrinsics和cam_intrinsics中的相机数据解析成CameraInfo对象的列表,并处理每个相机的旋转、平移、视场角等信息。
主要步骤:
- 迭代解析相机外参:遍历
cam_extrinsics字典中的每个相机,获取旋转矩阵R和平移向量T。- 视场角计算:根据相机模型(
SIMPLE_PINHOLE或PINHOLE)计算垂直和水平方向的视场角。- 图像路径与信息:结合图像文件夹路径
images_folder,生成图像路径和图像名称,并打开图像文件。- 创建并存储相机信息:将解析到的相机信息存储在
CameraInfo对象中,并添加到cam_infos列表。返回值:
- 返回
cam_infos,包含所有解析过的相机信息列表。
代码优点
- 自动文件读取和兼容性:自动适配二进制和文本格式的文件读取,使得代码更加兼容不同格式的 COLMAP 输出。
- 训练/测试集划分灵活:支持按一定间隔划分训练和测试集,适合用于评估模式的数据集处理。
- 相机视场角处理:根据相机模型选择不同的视场角计算方式,适应多种相机模型。
代码潜在改进
- 异常处理:在图像加载和文件读取时增加更多异常处理,以应对图像丢失或格式不匹配的情况。
- 多线程优化:如果相机数量较多,可使用多线程或并行处理以加快相机参数的读取速度。