流程分析
为满足上述需求,需要通过程序实现自定义生成PDF文件。幸运的是目前已有对应的代码解决方案可以实现该需求。方案涉及到itextpdf类库、AdobeAcrobat DC的使用。整体流程如下:
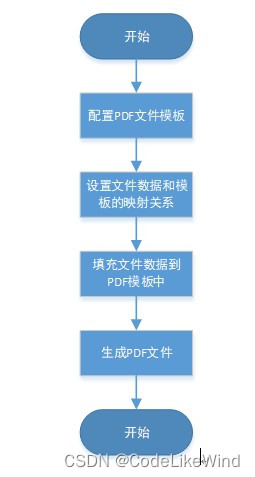
自定义生成PDF文件流程图
由上图可知,生成自定义PDF文件流程主要分为三个部分。模板配置,数据映射,数据填充。其中,模板配置需要用到AdobeAcrobat DC软件(一款PDF编辑器),在模板配置过程中,需要设置好PDF文件各个属性名称,方便后续的数据映射。最后通过itextpdf类库提供的方案,将业务数据填充到PDF模板并生成PDF文件。
步骤介绍
一、PDF模板配置
配置PDF模板需要用到AdobeAcrobat DC软件,该软件的绿色版本请见附件。首先需要创建一个PDF文件,然后使用AdobeAcrobat DC打开,如下图:
打开空白PDF文档
选择右侧“准备表单”选项,即可编辑PDF模板。模板中可以添加图片域、文本域,可以设置各个域的名称。例如标题的名称为title。如下图:

PDF模板配置
注:上述PDF模板中配置的各个域和预期生成的PDF文件数据要一一对应,例如,如果需要在PDF文件上方居中位置展示标题内容,则需要在PDF模板中创建一个文本域,文本域名称为title。然后在JAVA代码中,将标题内容通过title这个key填充到模板中。
在设置PDF模板时,我们可以自定义各个域的展示效果,包括图片域、按钮域中展示的图片具体如下图:
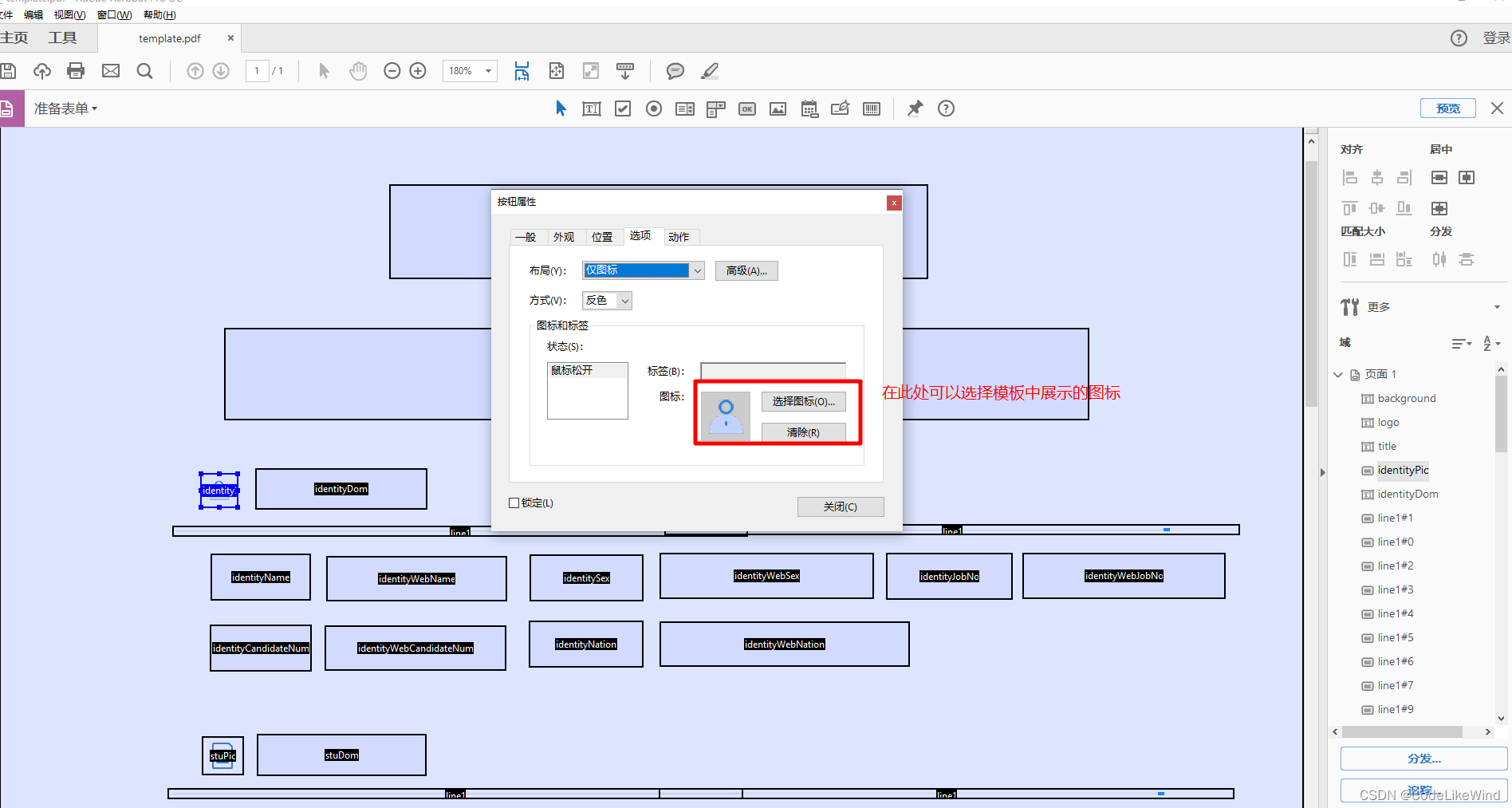
添加PDF模板默认图标
还可以设置文本域中文字的展示字体、大小。如下图:

设置PDF模板文字属性
按照业务需要配置完PDF模板后需要将模板保存为PDF文件,后续JAVA代码填充数据时需要向该PDF文件中写入数据。配置完成的PDF文件如下:

PDF模板编辑效果
二、数据写入
当我们配置好PDF模板以后,我们需要通过JAVA代码讲业务数据填入PDF模板,从而得到最终的PDF文件。
数据写入需要用到itextpdf和itext-asian两个类库。使用方法也很简单。只需要在项目pom文件中导入这两个类库的maven依赖。
| <dependency> <groupId>com.itextpdf</groupId> <artifactId>itextpdf</artifactId> <version>5.5.13.2</version> </dependency> <dependency> <groupId>com.itextpdf</groupId> <artifactId>itext-asian</artifactId> <version>5.2.0</version> </dependency> |
依赖引入成功后,我们就可以使用PdfReader 和PdfStamper这两个类来实现PDF模板的读取和PDF数据填充功能。
(1)配置文件读取/写入
配置文件的读取很简单,首先通过PdfReader读取PDF模板文件,然后结合数据输出流,创建PdfStamper即可。如下图:
| PdfReader reader = new PdfReader("D:\\test.pdf") //读取模板文件 ByteArrayOutputStream bos = new ByteArrayOutputStream(); //创建输出流 PdfStamper stamper = stamper = new PdfStamper(reader, bos) //创建PDF文件填充对象 |
(2)业务数据映射
文件填充对象创建成功后,需要向该对象添加数据,常见的数据有两种,一种是文本数据,一种是图片数据。接下来我将分别说明两种数据的填充方式,并分别提供案例。
第一种文本数据,文本数据相对比较简单,只需要处理stamper对象中的AcroFields对象即可。处理时需要设置文本字体和文本内容与PDF模板的映射。
| AcroFields form = stamper.getAcroFields(); //获取AcroFields对象 BaseFont bf = com.itextpdf.text.pdf.BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", false); Font FontChinese = new Font(bf, 5, Font.NORMAL); //创建字体 form.addSubstitutionFont(bf); //添加字体属性 Map<String,String> fieldMap = new HashMap<>(); fieldMap.put("name","张三"); //创建文本映射关系 form.setField(key, fieldMap.get(“name”)); //填充文本信息 |
注:
- form.addSubstitutionFont()不能省略,否则会导致文本填充不生效
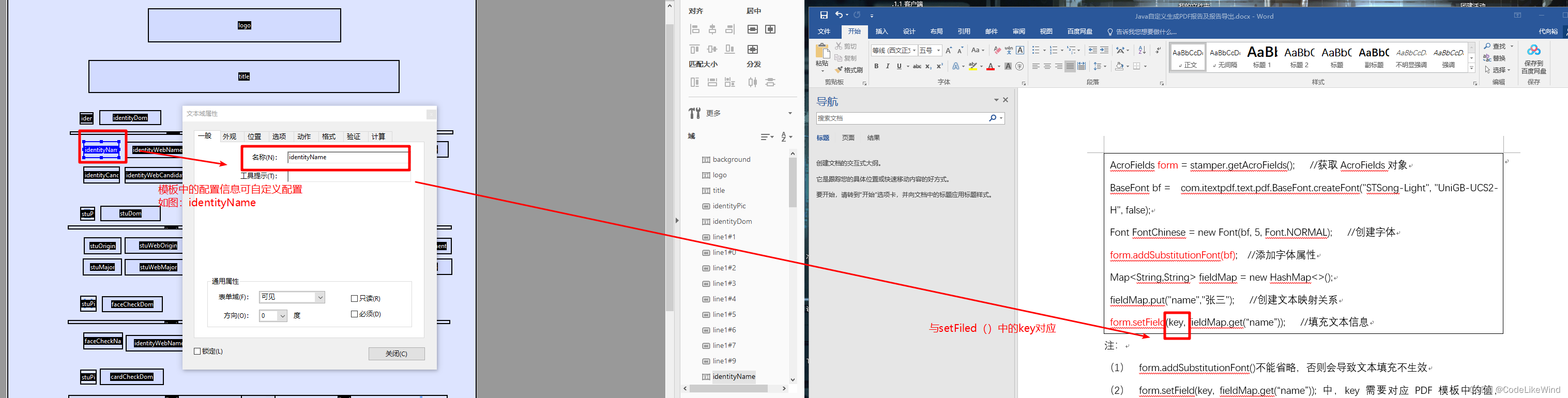
- form.setField(key, fieldMap.get(“name”)); 中,key需要对应PDF模板中的值,fieldMap.get(“name”)为PDF文件中实际填充的值,即“张三”。
Key和PDF模板的映射关系如下图:
第二种图片数据,图片数据同样需要处理AcroFields对象,但是相比于文本数据,图片数据的处理更加负责,如下代码:
| Map<String,String> map2 = new HashMap(); map2.put("testimage","D:\\qwqqqq.png"); //获取需要填充的图片 //根据图片存储路径创建图片对象 String value = map2.get(“testimage”); String imgpath = value; int pageNo = form.getFieldPositions(key).get(0).page; Rectangle signRect = form.getFieldPositions(key).get(0).position; //此处key与PDF模板对应 float x = signRect.getLeft(); //图片坐标 float y = signRect.getBottom(); //图片坐标,默认按照PDF模板设置展示 //根据路径读取图片 Image image = Image.getInstance(imgpath); //获取图片页面 PdfContentByte under = stamper.getOverContent(pageNo); //图片大小自适应 image.scaleToFit(signRect.getWidth(), signRect.getHeight()); //添加图片 image.setAbsolutePosition(x, y); under.addImage(image); |
文本和图片数据添加完成后,需要执行最后一步,生成PDF文件。
| stamper.setFormFlattening(true);// 如果为false,生成的PDF文件可以编辑,如果为true,生成的PDF文件不可以编辑 FileOutputStream out = new FileOutputStream(filePath+fileName); //PDF文件最终输出路径和PDF文件名称 stamper.close(); Document doc = new Document(); Font font = new Font(bf, 32); PdfCopy copy = new PdfCopy(doc, out); //将数据输出流通过copy输出 doc.open(); PdfImportedPage importPage = copy.getImportedPage(new PdfReader(bos.toByteArray()), 1); copy.addPage(importPage); doc.close(); |