一、多层感知机
多层感知机 (Multi-Layer Perceptron)是一种有监督的学习算法,它通过在数据集进行训练来学习函数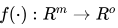
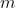

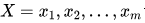
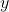
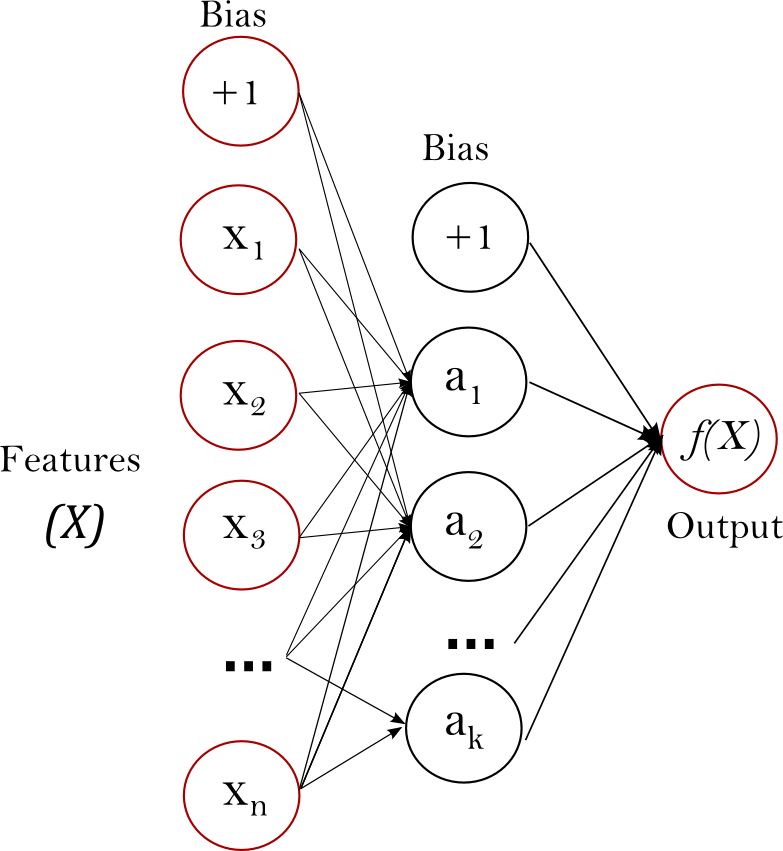
二、二分类任务
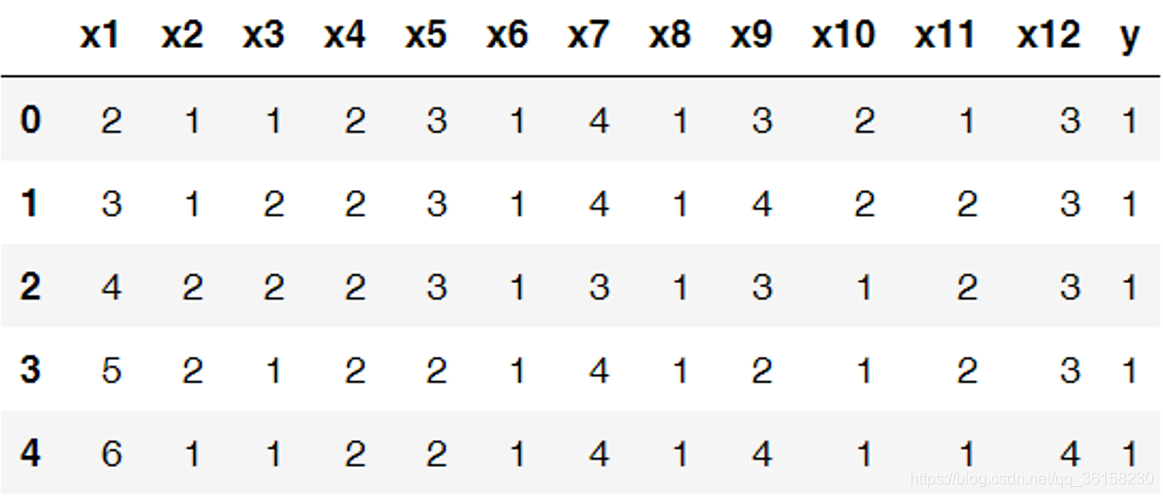
1. 数据的收集:首先设计一个问卷调查,用来统计学生对于某门课程的各方面信息(可以当成模型的输入特征),然后结合一学期的考勤,得到一个学期这门课程的标记(有缺课记录、无缺课记录)信息。最终可整合成一个数据集。其中,这个数据集的特征和标记的说明如下。
| x1: ID x2: Q3_性别 1:男,2:女 x3: Q4_你的研究方向是什么?(1:间接相关;2:直接相关) x4: Q5_你的研究与机器学习什么方向有结合?(1:暂无结合;2:有结合) x5: Q6_你怎么评估自己的数学基础?(5分为最好) x6: Q7_你是否有做过机器学习相关的实验? x7: Q8_评价下自己对机器学习的兴趣程度。(5分为非常感兴趣) x8: Q9_是否学习过机器学习相关课程(包括网上自学)? 1:是 2:否 x9: Q10_评估下毕业后从事机器学习相关工作的可能性。(5分可能性最高) x10: Q11_学习机器学习这门课的主要目的是什么?(1:兴趣;2:科研;3:学分) x11: Q12_是否与两位任课老师有科研合作? 1:是 2:否 x12: Q13_评价下目前为止课程难度(5分为最难) y: 到课情况 1:点名到课;-1 点名没到 |
数据集的部分样例如下。
2. 数据的使用:通过收集好的数据,我们可以训练得到一个机器学习模型。
3. 模型的应用:在将来的课程中,继续沿用设计好的调查问卷,根据学生所填的信息,输入到训练好的机器学习模型,然后输出一个类别,这个类别可以预测学生是否会缺课,老师可以重点关注这些学生,以此来改善课堂考勤率。
三、sklearn解决二分类任务
这里利用的是多层感知机来解决上述的二分类任务。代码如下:
import csv
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 加载训练数据集
def load_dataset(path):
dataset_file = csv.reader(open(path))
vector_x = [] # 样本
y = [] # 样本所对应的标签
# 从文件读取训练数据集
for content in dataset_file:
# 如果读取的不是表头
if dataset_file.line_num != 1:
# 读取一行并转化为列表
content = list(map(float, content))
if len(content) != 0:
vector_x.append(content[1:12]) # 第1-12列是样本的特征
y.append(content[-1]) # 最后一列是样本的标签
return vector_x, y # 返回训练数据集
# 训练模型
def mlp_cls(vector_x_train, y_train):
# 输入层->第一层->第二层->输出层
# 12 30 20 1 # 节点个数
# MLPClassifier参数说明详情见https://www.cnblogs.com/-X-peng/p/14225973.html
mlp = MLPClassifier(solver='adam', alpha=0, hidden_layer_sizes=(30, 20), random_state=1)
mlp.fit(vector_x_train, y_train) # 训练
return mlp
# 模型预测
def mlp_cls_predict(mlp, vector_x_test, y_test):
# 预测
y_predict = mlp.predict(vector_x_test)
# 输出模型预测的准确度
print(accuracy_score(y_predict, y_test))
# 实验
if __name__ == '__main__':
# 1. 加载数据集
vector_x, y = load_dataset("dataset.csv")
scalar = StandardScaler() # 标准化转换
scalar.fit(vector_x) # 训练标准化对象
vector_x = scalar.transform(vector_x) # 转换数据集
# 2. 划分训练集和测试集
vector_x_train, vector_x_test, y_train, y_test = train_test_split(vector_x, y, test_size=0.2, random_state=0)
# 3. 训练
mlp = mlp_cls(vector_x_train, y_train)
# 4. 预测
mlp_cls_predict(mlp, vector_x_test, y_test)输出
0.9696969696969697
ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.参考资料
2.sklearn 神经网络MLPclassifier参数详解
3.实验所需的数据集