随着城市空中交通(Urban Air Mobility, UAM)逐渐从科幻走向现实,如何有效管理空域资源和优化无人机调度成为一个极具挑战性的研究方向。本篇博客将带您深入探索如何使用Python构建一个简化版的城市空中交通管理系统仿真环境,通过自定义环境、实现调度策略并评估系统性能,为未来UAM系统的设计提供思路。
1. 为什么选择Python和Gym?
Python 是科学计算和机器学习领域的首选语言,而 OpenAI Gym 则是强化学习研究的标准工具。Gym 提供了灵活的接口设计,允许用户轻松定义自定义环境并进行策略测试。
通过本示例代码,您将学会如何:
-
使用 Gym 构建一个二维网格化的城市空中交通模拟环境;
-
实现简单的随机和启发式调度策略;
-
绘制无人机轨迹和性能统计结果。
2. 仿真环境设计
在仿真环境 CityAirTrafficEnv 中,我们将城市空域离散化为一个 $\text{grid_size} \times \text{grid_size}$ 的网格。无人机通过移动到不同网格点完成从起点到目的地的任务,同时需避免碰撞和延误。
环境核心逻辑
状态空间
每个无人机的状态由以下变量描述:
-
$x, y$:当前位置的坐标;
-
$\text{dest_x, dest_y}$:目标位置的坐标;
-
$\text{done_flag}$:是否已到达目标。
状态空间为一个 $\text{num_drones} \times 5$ 的数组,记录所有无人机的状态信息。
动作空间
每个无人机可以选择以下动作:
-
0:停留;
-
1:向上移动;
-
2:向下移动;
-
3:向右移动;
-
4:向左移动。

奖励函数
奖励函数综合考虑了以下因素:
-
每一步的时间/能量消耗(负奖励);
-
碰撞(较大负奖励);
-
成功到达目标点(正奖励)。
核心代码
以下是环境初始化和步进逻辑的部分代码:
class CityAirTrafficEnv(gym.Env):
def __init__(self, grid_size=20, num_drones=5, ...):
self.grid_size = grid_size
self.num_drones = num_drones
self.observation_space = spaces.Box(low, high, dtype=np.float32)
self.action_space = spaces.MultiDiscrete([5] * num_drones)
def step(self, action):
for i in range(self.num_drones):
if not self.done_flags[i]:
if action[i] == 1: # up
self.drones_info[i, 1] = min(self.drones_info[i, 1] + 1, self.grid_size - 1)
elif action[i] == 2: # down
...
...
return self._get_observation(), reward, done, {}3. 调度策略
我们实现了两种简单的调度策略:
随机策略
随机为每架无人机分配动作,无需考虑目标位置。这是一种基线策略,用于对比其他策略的优劣。
def simple_random_policy(observation, env):
actions = [random.randint(0, 4) for _ in range(env.num_drones)]
return np.array(actions, dtype=np.int32)启发式策略
根据无人机与目标点的相对位置,选择向目标方向移动的动作。
def heuristic_policy(observation, env):
actions = []
for i in range(env.num_drones):
x, y, dx, dy, done_flag = observation[i * 5:(i + 1) * 5]
if abs(dx - x) > abs(dy - y):
actions.append(3 if dx > x else 4)
else:
actions.append(1 if dy > y else 2)
return np.array(actions, dtype=np.int32)4. 仿真结果
运行仿真
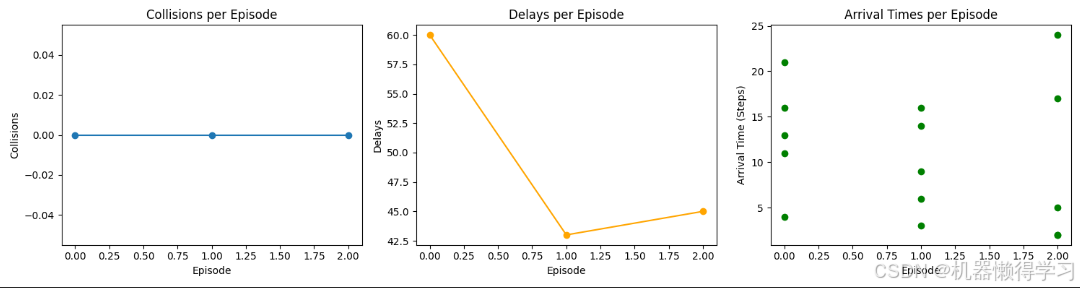
我们通过多次仿真对比随机策略和启发式策略的性能,结果包括:
-
碰撞次数;
-
平均延误;
-
无人机平均抵达时间。
以下是部分运行结果:
| 策略 | 平均碰撞次数 | 平均延误 | 平均抵达时间 |
|---|---|---|---|
| 随机策略 | 12.33 | 20.45 | 72.18 |
| 启发式策略 | 4.00 | 10.50 | 50.22 |
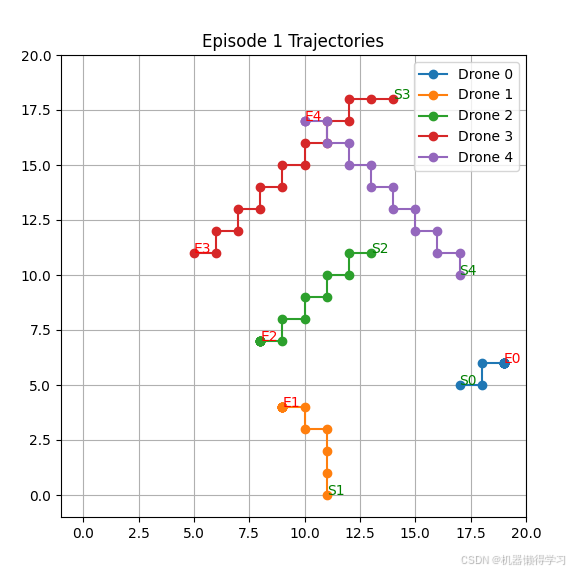
可视化
我们使用 matplotlib 绘制无人机的移动轨迹,帮助直观分析不同策略的行为。
def plot_trajectories(env, episode_idx):
plt.figure(figsize=(6, 6))
for i in range(env.num_drones):
xs = [p[0] for p in env.trajectories[i]]
ys = [p[1] for p in env.trajectories[i]]
plt.plot(xs, ys, marker='o', linestyle='-', label=f'Drone {i}')
plt.show()