Transformer是一种基于自注意力机制的深度神经网络模型,被广泛应用于自然语言处理(NLP)和多模态学习领域。

Transformer最初由Google在2017年提出,其核心思想是通过自注意力(Self-Attention)机制来捕捉输入序列之间的全局依赖关系,从而能够处理各种复杂的序列任务。由于其并行化计算的优点和对长距离依赖的强大捕捉能力,Transformer很快成为了多个NLP任务的基石。
从模型架构的角度来看,Transformer 主要由编码器(Encoders)和解码器(Decoders)两部分组成。每个编码器和解码器包含多个相同的层,每一层都包括多头注意力机制(Multi-Head Attention)、位置前馈网络(Feed Forward Networks)和层归一化(Layer Normalization)等组成部分。“多头注意力”允许模型同时在不同的表示子空间中学习到信息,极大提高了模型处理复杂语义关系的能力。
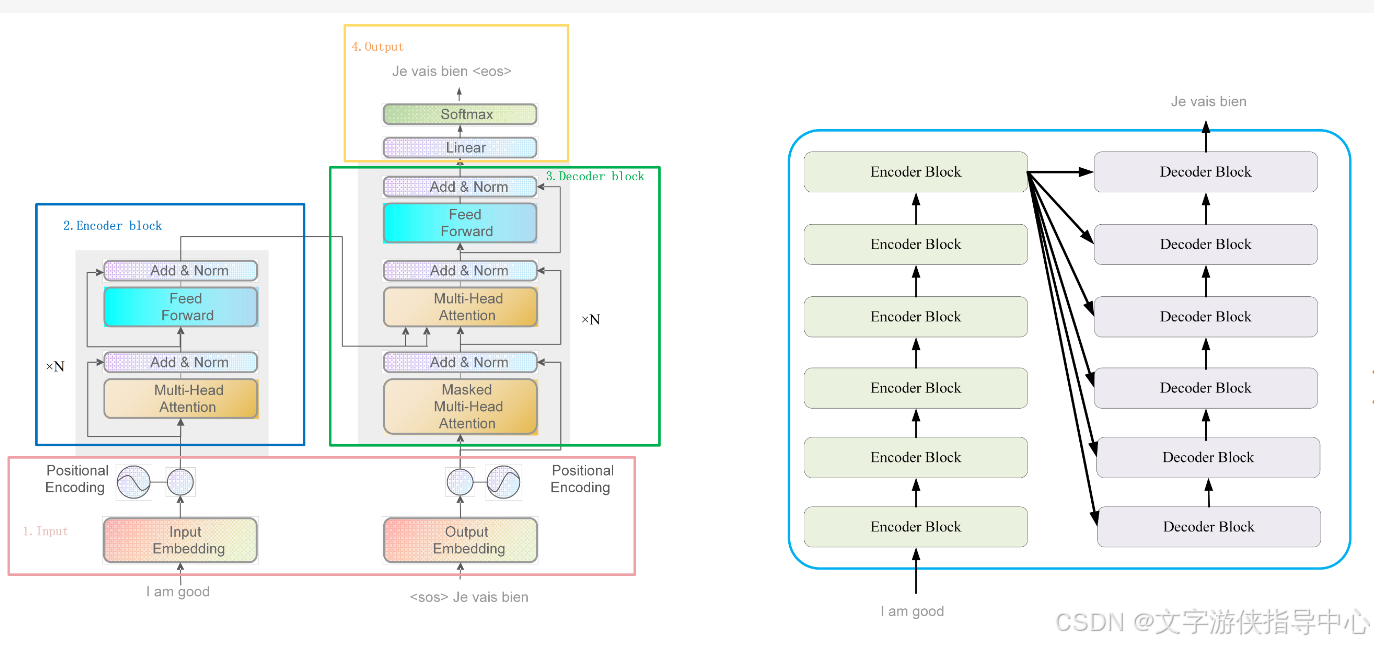
在应用领域,Transformer的影响力深远。其最著名的应用之一就是在机器翻译领域,例如谷歌的T2T模型。除此之外,Transformer也被用于文本理解、文本生成、语音识别等众多NLP任务中。更进一步,基于Transformer的模型也被成功应用于图像处理领域,如Vision Transformer(ViT)模型,以及最新的多模态模型,可以同时处理并理解文本和图像信息。
总而言之,Transformer通过其创新的自注意力机制和高效的计算性能,不仅极大地推动了自然语言处理技术的发展,也正在逐步扩展到其他人工智能领域。
最后,给大家推荐一个近期比较火爆的AI创作模型工具,可以大幅度提高工作效率,目前还在不断优化升级中,有兴趣或想体验的可以看看下方文章介绍:
“文字游侠”:AI赋能下的自媒体革命,一键生成爆款文章变现!附上渠道和教程!

当然,如果想了解更多相关的知识点,也可以关注宫中号【追梦好彩头】