requires_grad
requires_grad意为是否需要计算梯度- 使用
backward()函数反向传播计算梯度时,并不是计算所有tensor的梯度,只有满足下面条件的tensor的梯度才会被计算:1. 当前tensor的require_grad=True(代码示例一);2. 依赖于该tensor的所有tensor的require_grad=True,即可以获得依赖于该tensor的所有tensor的梯度值(代码示例二)。 - 在所有的
require_grad=True中- 默认情况下,非叶子节点的梯度值在反向传播过程中使用完后就会被清除,不会被保留。
- 默认情况下,只有叶子节点的梯度值能够被保留下来。
- 被保留下来的叶子节点的梯度值会存入
tensor的grad属性中,在optimizer.step()过程中会更新叶子节点的data属性值,从而实现参数的更新。
代码示例
示例一:require_grad=True时才会计算梯度
import torch
import torch.nn as nn
import torch.optim as optim
import random
import os
import numpy as np
def seed_torch(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 为了禁止hash随机化,使得实验可复现
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_torch()
# 定义一个网络
class net(nn.Module):
def __init__(self, num_class=10):
super(net, self).__init__()
self.pool1 = nn.AvgPool1d(2)
self.bn1 = nn.BatchNorm1d(3)
self.fc1 = nn.Linear(12, 4)
def forward(self, x):
x = self.pool1(x)
x = self.bn1(x)
x = x.reshape(x.size(0), -1)
x = self.fc1(x)
return x
# 定义网络
model = net()
# 定义loss
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=1e-2)
# 定义训练数据
x = torch.randn((3, 3, 8))
model.fc1.weight.requires_grad = False # fc1.weight不计算梯度
print(model.fc1.weight.grad)
print(model.fc1.bias.grad) # fc1.bias计算梯度
output = model(x)
target = torch.tensor([1, 1, 1])
loss = loss_fn(output, target)
loss.backward()
print(model.fc1.weight.grad)
print(model.fc1.bias.grad)
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python net.py
None
None
None
tensor([ 0.1875, -0.8615, 0.3708, 0.3033])
示例二:使用detach()使非叶子节点被剥离计算图不计算梯度值(requires_grad=False)时,被该非叶子节点依赖的叶子节点不计算梯度,即使该叶子节点的requires_grad=True
import torch
import torch.nn as nn
import torch.optim as optim
import random
import os
import numpy as np
def seed_torch(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 为了禁止hash随机化,使得实验可复现
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_torch()
# 定义一个网络
class net(nn.Module):
def __init__(self, num_class=10):
super(net, self).__init__()
self.pool1 = nn.AvgPool1d(2)
self.bn1 = nn.BatchNorm1d(3)
self.fc1 = nn.Linear(12, 4)
def forward(self, x):
x = self.pool1(x)
x = self.bn1(x)
x = x.reshape(x.size(0), -1)
x = x.detach() # 将非叶子节点剥离成叶子节点 x.requires_grad = False x.grad_fn=None
y = self.fc1(x)
return y
# 定义网络
model = net()
# 定义loss
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=1e-2)
# 定义训练数据
x = torch.randn((3, 3, 8))
# 训练前叶子结点 bn1.weight 的参数情况
print(model.bn1.weight.requires_grad)
print(model.bn1.weight.grad)
# 训练前叶子结点 fc1.weight 的参数情况
print(model.fc1.weight.requires_grad)
print(model.fc1.weight.grad)
output = model(x)
target = torch.tensor([1, 1, 1])
loss = loss_fn(output, target)
loss.backward()
# 训练后叶子结点 bn1.weight 的参数情况
print(model.bn1.weight.requires_grad)
print(model.bn1.weight.grad)
# 训练后叶子结点 fc1.weight 的参数情况
print(model.fc1.weight.requires_grad)
print(model.fc1.weight.grad)
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python net.py
True
None
True
None
True
None
True
tensor([[ 0.0053, 0.0341, 0.0272, 0.0231, -0.1196, 0.0164, 0.0442, 0.1511,
-0.1146, 0.2443, -0.0513, -0.0404],
[ 0.1127, 0.0141, 0.1857, -0.3597, 0.5626, 0.1670, -0.0569, -0.6800,
0.5046, -1.0340, 0.2865, 0.2857],
[-0.0225, -0.0370, 0.0581, 0.0509, -0.2231, 0.1119, 0.0313, 0.2887,
-0.1560, 0.5342, -0.0799, -0.0358],
[-0.0955, -0.0112, -0.2710, 0.2857, -0.2199, -0.2953, -0.0185, 0.2402,
-0.2340, 0.2555, -0.1553, -0.2095]])
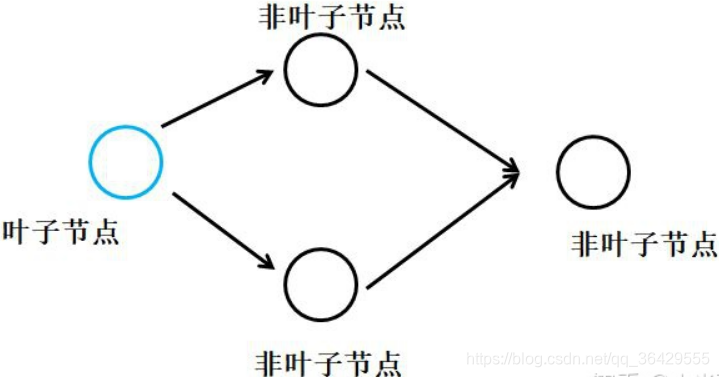
叶子节点与非叶子节点
tensor可分为两类:叶子节点和非叶子节点- 可通过
is_leaf来判断一个tensor是否为叶子节点
叶子结点
-
叶子节点可以理解成不依赖其他tensor的tensor
-
在pytorch中,神经网络层中的权值weight和偏差bias的tensor均为叶子节点;自己定义的tensor例如a=torch.tensor([1.0])定义的节点是叶子节点
import torch a=torch.tensor([1.0]) a.is_leaf True b=a+1 b.is_leaf True- 可以看出b竟然也是叶节点!这件事可以这样理解,单纯从数值关系上b=a+1,b确实依赖a。但是从pytorch的看来,一切是为了反向求导,a的requires_grad属性为False,其不要求获得梯度,那么a这个tensor在反向传播时其实是“无意义”的,可认为是游离在计算图之外的,故b仍然为叶子节点,如下图
- 可以看出b竟然也是叶节点!这件事可以这样理解,单纯从数值关系上b=a+1,b确实依赖a。但是从pytorch的看来,一切是为了反向求导,a的requires_grad属性为False,其不要求获得梯度,那么a这个tensor在反向传播时其实是“无意义”的,可认为是游离在计算图之外的,故b仍然为叶子节点,如下图
-
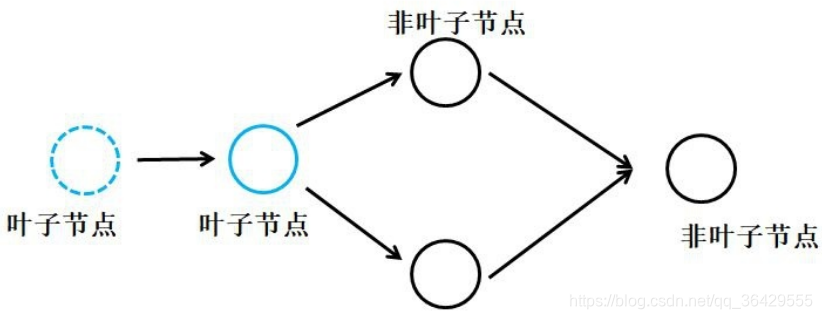
再例如下图的计算图,本来是叶子节点是可以正常进行反向传播计算梯度的:
但是使用detach()函数将某一个非叶子节点剥离成为叶子节点后
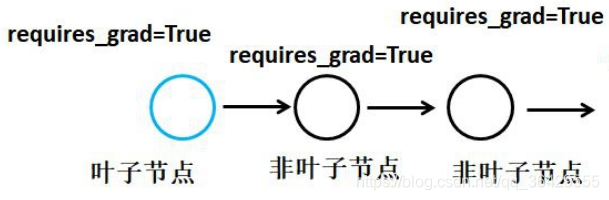
无论requires_grad属性为何值,原先的叶子节点求导通路中断,便无法获得梯度数值了。 -
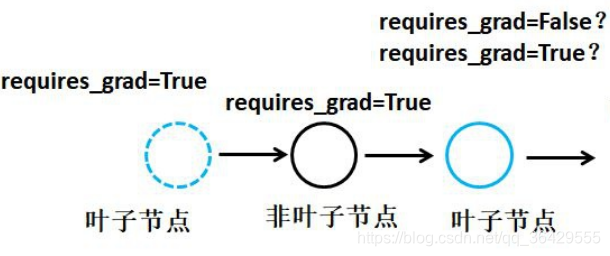
其次,如上所示,对于需要求导的tensor,其requires_grad属性必须为True,例如对于下图中最上面的叶子节点,pytorch不会自动计算其导数。
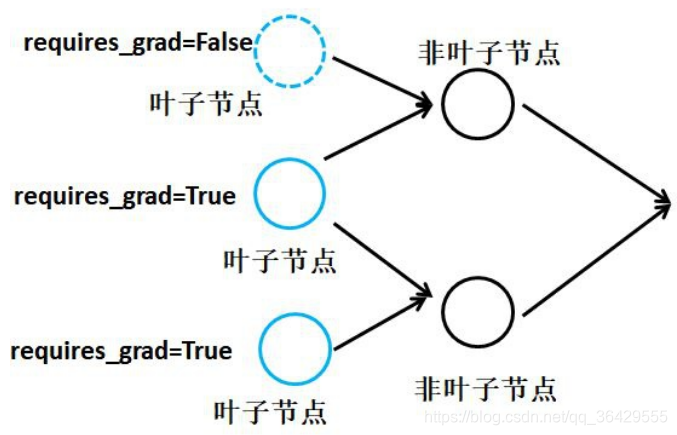
非叶子节点
在默认情况下,非叶子节点中保存了pytorch计算图的另一种元素:运算(grad_fn),运算就是加减乘除、开方、幂指对、三角函数等可求导运算,有了运算才可以求叶子结点的梯度。
# 定义一个网络
class net(nn.Module):
def __init__(self, num_class=10):
super(net, self).__init__()
self.pool1 = nn.AvgPool1d(2)
self.bn1 = nn.BatchNorm1d(3)
self.fc1 = nn.Linear(12, 4)
def forward(self, x):
x = self.pool1(x)
x = self.bn1(x)
x = x.reshape(x.size(0), -1)
print(x)
y = self.fc1(x)
return y
# 定义网络
model = net()
# 定义loss
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=1e-2)
# 定义训练数据
x = torch.randn((3, 3, 8))
output = model(x)
# 结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python net.py
tensor([[-0.2112, -1.1580, 0.9010, -0.3500, -0.3878, 1.9242, -0.3629, 0.6713,
0.4996, 2.3366, 0.1928, 0.7291],
[-0.7056, -0.4324, -1.8940, 1.7456, -0.7856, -1.8655, -0.4469, 0.7612,
-0.8044, 0.4850, -0.7059, -1.0746],
[ 0.4769, 1.4226, 0.3125, -0.1074, -0.7744, -0.5955, 0.9378, 0.9242,
-1.3836, 0.8161, -0.4706, -0.6202]], grad_fn=<ViewBackward>)
with torch.no_grad()
-
torch.no_grad()是一个上下文管理器,用来禁止梯度的计算,通常用在网络推断(eval)中,可以减少计算内存的使用量 -
被
torch.no_grad()包裹起来的部分不会被追踪梯度,虽然仍可以前向传播进行计算得到输出,但计算过程(grad_fn)不会被记录,也就不能反向传播更新参数。具体地,对非叶子节点来说- 非叶子节点的
requires_grad属性变为了False - 非叶子节点的
grad_fn属性变为了None
这样便不会计算非叶子节点的梯度。因此,虽然叶子结点(模型各层的可学习参数)的
requires_grad属性没有改变(依然为True),也不会计算梯度,grad属性为None,且如果使用loss.backward()会报错(因为第一个非叶子节点(loss)的requires_grad属性为False,grad_fn属性为None)。因此,模型的可学习参数不会更新。 - 非叶子节点的
-
torch.no_grad()不会影响dropout和batchnorm层在train和eval时的行为
代码示例
import torch
import torch.nn as nn
import torch.optim as optim
import random
import os
import numpy as np
def seed_torch(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 为了禁止hash随机化,使得实验可复现
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_torch()
# 定义一个网络
class net(nn.Module):
def __init__(self, num_class=10):
super(net, self).__init__()
self.pool1 = nn.AvgPool1d(2)
self.bn1 = nn.BatchNorm1d(3)
self.fc1 = nn.Linear(12, 4)
def forward(self, x):
x = self.pool1(x)
x = self.bn1(x)
x = x.reshape(x.size(0), -1)
print("非叶子节点的requires_grad: ", x.requires_grad) # 非叶子节点的wrequires_grad
print("非叶子节点的grad_fn: ", x.grad_fn) # 非叶子节点的grad_fn
y = self.fc1(x)
return y
# 定义网络
model = net()
# 定义loss
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=1e-2)
# 定义训练数据
x = torch.randn((3, 3, 8))
print("包裹前fc1.weight的requires_grad: ", model.fc1.weight.requires_grad) # 包裹前fc1.weight的requires_grad
with torch.no_grad():
print("包裹后fc1.weight的requires_grad: ", model.fc1.weight.requires_grad) # 包裹后fc1.weight的requires_grad
print("训练前的fc1.weight.grad: ", model.fc1.weight.grad) # 训练前的fc1.weight.grad
output = model(x)
target = torch.tensor([1, 1, 1])
loss = loss_fn(output, target)
# 实际不会这么写 这里是为了验证不会计算grad 会报错
loss.backward()
print("训练后的fc1.weight.grad: ", model.fc1.weight.grad) # 训练后的fc1.weight.grad
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python net.py
包裹前fc1.weight的requires_grad: True
包裹后fc1.weight的requires_grad: True
训练前的fc1.weight.grad: None
非叶子节点的requires_grad: False
非叶子节点的grad_fn: None
Traceback (most recent call last):
File "/home/jyzhang/test/net.py", line 66, in <module>
loss.backward()
File "/home/jyzhang/anaconda3/envs/bbn/lib/python3.9/site-packages/torch/tensor.py", line 245, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/jyzhang/anaconda3/envs/bbn/lib/python3.9/site-packages/torch/autograd/__init__.py", line 145, in backward
Variable._execution_engine.run_backward(
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
# element 0 of tensors指的是计算出的loss
model.eval()
-
底层分析
-
因为自定义的网络以及自定义的网络中的各个层都继承于nn.Module这个父类,nn.Module存在一个
training的属性,默认为True,所以,model.eval()使得自定义的网络以及自定义的网络中的各个层的training属性变为了False -
class net(nn.Module): def __init__(self): super(net, self).__init__() self.bn = nn.BatchNorm1d(3, track_running_stats=True) def forward(self, x): return self.bn(x) model = net() model.eval() print(model.training) print(model.bn.training) # 输出 (bbn) jyzhang@admin2-X10DAi:~/test$ python net.py False False
-
-
在PyTorch中进行validation时,会使用
model.eval()切换到测试模式 -
该模式用于通知
dropout层和batchnorm层切换至val模式- 在
val模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值(这里的学习是指在训练阶段数据前向传播的过程中累积更新的mean和var值) - 关于对
batchnorm层的影响的详细分析见下面的batch_normalization层部分,这里坑很多!!!
- 在
-
该模式不会影响各层的gradient计算行为,即gradient计算和存储与training模式一样,(代码示例一),具体地
- 叶子结点(模型各层的可学习参数)的
requires_grad属性没有改变(依然为True) - 非叶子节点的
requires_grad属性为True - 非叶子节点的
grad_fn属性不为None - 因此,该模式不会影响各层的gradient计算行为,甚至
loss.backward()还能正常运行计算梯度(通常不使用)
- 叶子结点(模型各层的可学习参数)的
-
注意,训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,相同的数据输出结果也会改变。这是model中含有BN层和Dropout所带来的的性质 (代码示例二)
-
如果不在意显存大小和计算时间的话,仅仅使用model.eval()已足够得到正确的validation/test的结果(在validation/test时不写
loss.backward());而with torch.no_grad()则是更进一步加速和节省gpu空间(因为不用计算和存储梯度),从而可以更快计算,也可以跑更大的batch来测试。
代码示例一
import torch
import torch.nn as nn
import torch.optim as optim
import random
import os
import numpy as np
def seed_torch(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 为了禁止hash随机化,使得实验可复现
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_torch()
# 定义一个网络
class net(nn.Module):
def __init__(self, num_class=10):
super(net, self).__init__()
self.pool1 = nn.AvgPool1d(2)
self.bn1 = nn.BatchNorm1d(3)
self.fc1 = nn.Linear(12, 4)
def forward(self, x):
x = self.pool1(x)
x = self.bn1(x)
x = x.reshape(x.size(0), -1)
print("非叶子节点的requires_grad: ", x.requires_grad) # 非叶子节点的wrequires_grad
print("非叶子节点的grad_fn: ", x.grad_fn) # 非叶子节点的grad_fn
y = self.fc1(x)
return y
# 定义网络
model = net()
# 定义loss
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=1e-2)
# 定义训练数据
x = torch.randn((3, 3, 8))
print("切换至eval前fc1.weight的requires_grad: ", model.fc1.weight.requires_grad) # 切换至eval前fc1.weight的requires_grad
model.eval()
print("切换至eval后fc1.weight的requires_grad: ", model.fc1.weight.requires_grad) # 切换至eval前fc1.weight的requires_grad
output = model(x)
target = torch.tensor([1, 1, 1])
loss = loss_fn(output, target)
# 一般不这么使用,只是为了验证eval不改变各节点的梯度计算行文
loss.backward()
print("反向传播后model.fc1.weight.grad: ", model.fc1.weight.grad) # 反向传播后model.fc1.weight.grad
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python net.py
切换至eval前fc1.weight的requires_grad: True
切换至eval后fc1.weight的requires_grad: True
非叶子节点的requires_grad: True
非叶子节点的grad_fn: <ViewBackward object at 0x7f656790a040>
反向传播后model.fc1.weight.grad: tensor([[-0.0395, -0.0310, -0.0322, -0.0101, -0.1166, -0.0275, -0.0164, 0.0703,
-0.0346, 0.1522, -0.0075, -0.0020],
[ 0.1980, 0.1494, 0.2325, -0.0340, 0.5011, 0.2446, 0.1040, -0.2942,
0.1612, -0.5969, 0.0538, 0.0527],
[-0.0783, -0.0664, -0.0703, -0.0085, -0.2122, -0.0585, -0.0395, 0.1268,
-0.0598, 0.2753, -0.0148, -0.0059],
[-0.0801, -0.0521, -0.1300, 0.0526, -0.1723, -0.1586, -0.0480, 0.0971,
-0.0669, 0.1695, -0.0315, -0.0449]])
代码示例二
import torch
import torch.nn as nn
import torch.optim as optim
import random
import os
import numpy as np
def seed_torch(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 为了禁止hash随机化,使得实验可复现
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_torch()
# 定义一个网络
class net(nn.Module):
def __init__(self, num_class=10):
super(net, self).__init__()
self.pool1 = nn.AvgPool1d(2)
self.bn1 = nn.BatchNorm1d(3)
self.fc1 = nn.Linear(12, 4)
def forward(self, x):
x = self.pool1(x)
x = self.bn1(x)
x = x.reshape(x.size(0), -1)
y = self.fc1(x)
return y
# 定义网络
model = net()
# 定义loss
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=1e-2)
# 定义训练数据
x1 = torch.randn((1, 3, 8))
x2 = torch.randn((1, 3, 8))
x3 = torch.randn((1, 3, 8))
x4 = torch.randn((1, 3, 8))
# 切换至eval模式之前
print(model.bn1.running_mean)
model(x1)
print(model.bn1.running_mean)
model(x2)
print(model.bn1.running_mean)
# 切换至eval模式之后
model.eval()
print(model.bn1.running_mean)
model(x3)
print(model.bn1.running_mean)
model(x4)
print(model.bn1.running_mean)
# 再次切换至train模式
model.train()
print(model.bn1.running_mean)
model(x1)
print(model.bn1.running_mean)
model(x2)
print(model.bn1.running_mean)
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python net.py
tensor([0., 0., 0.])
tensor([-0.0287, 0.0524, -0.0517])
tensor([-0.0249, 0.0314, -0.0441])
tensor([-0.0249, 0.0314, -0.0441])
tensor([-0.0249, 0.0314, -0.0441])
tensor([-0.0249, 0.0314, -0.0441])
tensor([-0.0249, 0.0314, -0.0441])
tensor([-0.0511, 0.0806, -0.0914])
tensor([-0.0450, 0.0568, -0.0798])
model.train()
作用跟model.eval()正好相反,具体分析类比model.eval()
batch_normalization层
Pytorch中的BatchNorm
API
Pytorch中的BatchNorm的API主要有:
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
参数说明
-
num_features
输入维度是(N, C, L)时,num_features应该取C;这里N是batch size,C是数据的channel,L是数据长度
输入维度是(N, C)时,num_features应该取C;这里N是batch size,C是数据的channel,每个channel代表一种特征,省略了C
-
eps
对输入数据进行归一化时加在分母上,防止除零
-
momentum
更新全局均值
running_mean和方差running_var时使用该值进行平滑 -
affine
设为True时,BatchNorm层才会有学习参数学习参数
γ 、 β \gamma、 \beta γ、β
否则不包含这两个变量,变量名是weight和bias -
track_running_stats
设为True时,表示跟踪整个训练过程中的batch的统计特性,得到方差和均值,而不只是仅仅依赖与当前输入的batch的统计特性,BatchNorm层会统计全局均值
running_mean和方差running_var
参数详解
总述
由于上文提到的model.train()和model.eval()控制了training属性,track_running_stats参数又表示是否跟踪整个训练过程中的batch的统计特性,因此,这两个属性组合会出现不同的计算行为,值得注意
详解
-
首先声明一下归一化公式
在batch normalization中,使用的归一化公式为:
y = x − E [ x ] Var [ x ] + ϵ y=\frac{x-E[x]}{\sqrt{\operatorname{Var}[x]+\epsilon}} y=Var[x]+ϵx−E[x]
其中,E[x]表示均值,Var[x]表示方差 -
再说明一下参数
affine,如果affine=True,则会在通过归一化公式对batch数据进行归一化后,对归一化后的batch进行仿射变换,即乘以模块内部的weight(初值是[1., 1., 1., 1.])然后加上模块内部的bias(初值是[0., 0., 0., 0.]),这两个变量是可学习参数,会在反向传播时得到更新。 -
training=True, track_running_stats=True-
这是我们常见的训练时的参数设置,即
model.train()起作用时的常见设置 -
此时,存在均值
running_mean(初值是[0., 0., 0., 0.])和方差running_var(初值是[1., 1., 1., 1.]),且均值running_mean和方差running_var会跟踪不同batch数据的mean和variance进行更新,更新公式为
x new = ( 1 − momentum ) × x cur + momentum × x batch x_{\text {new }}=(1-\text { momentum }) \times x_{\text {cur }}+\text { momentum } \times x_{\text {batch }} \text {} xnew =(1− momentum )×xcur + momentum ×xbatch
x cur x_{\text {cur }} xcur 表示更新前的running_mean和running_var, x batch x_{\text {batch }} xbatch 表示当前batch的均值和无偏样本方差(分母是N-1)。 -
但是,在当前batch进行归一化(即使用上述归一化公式)时,使用的均值是当前batch的均值,方差是当前batch的有偏样本方差(分母是N),而不是
running_mean和running_var。
-
-
training=True, track_running_stats=False- 此时,就不存在均值
running_mean和方差running_var,均值running_mean和方差running_var的值为None,因此,均值running_mean和方差running_var就不会跟踪不同batch数据的mean和variance进行更新 - 此时,在当前batch进行归一化(即使用上述归一化公式)时,使用的均值是当前batch的均值,方差是当前batch的有偏样本方差(分母是N),而不是
running_mean和running_var。
- 此时,就不存在均值
-
training=False, track_running_stats=True- 这是我们常见的验证和测试时的参数设置,即
model.eval()起作用时的常见设置 - 此时,存在均值
running_mean(初值是[0., 0., 0., 0.])和方差running_var(初值是[1., 1., 1., 1.]),但均值running_mean和方差running_var不会跟踪不同batch数据的mean和variance进行更新。 - 在当前batch进行归一化(即使用上述归一化公式)时,使用的均值和方差分别是
running_mean和running_var
- 这是我们常见的验证和测试时的参数设置,即
-
training=False, track_running_stats=False- 此时,就不存在均值
running_mean和方差running_var,均值running_mean和方差running_var的值为None,因此,均值running_mean和方差running_var就不会跟踪不同batch数据的mean和variance进行更新; - 当前batch进行归一化(即使用上述归一化公式)时,使用的均值是当前batch的均值,方差是当前batch的有偏样本方差(分母是N)
- 跟
training=True, track_running_stats=False情况相同
- 此时,就不存在均值
参考博客
[1] https://zhuanlan.zhihu.com/p/259160576
[2] https://blog.csdn.net/weixin_39228381/article/details/107896863#BatchNorm1d%E8%AE%AD%E7%BB%83%E6%97%B6%E5%89%8D%E5%90%91%E4%BC%A0%E6%92%AD
[3] https://www.zhihu.com/question/282672547