目录
传送门
SpringMVC的源码解析(精品)
Spring6的源码解析(精品)
SpringBoot3框架(精品)
MyBatis框架(精品)
MyBatis-Plus
SpringDataJPA
SpringCloudNetflix
SpringCloudAlibaba(精品)
Shiro
SpringSecurity
java的LOG日志框架
Activiti(敬请期待)
JDK8新特性
JDK9新特性
JDK10新特性
JDK11新特性
JDK12新特性
JDK13新特性
JDK14新特性
JDK15新特性
JDK16新特性
JDK17新特性
JDK18新特性
JDK19新特性
JDK20新特性
JDK21新特性
其他技术文章传送门入口
前言
1、JDK各版本特性
JDK Version 1.0
1996-01-23 Oak(橡树)
初代版本 ,伟大的一个里程碑 ,但是是纯解释运行 ,使用外挂JIT ,性能比较差 ,运行速度慢。
JDK Version 1.1
1997-02-19
JDBC(Java DataBase Connectivity);
支持内部类;
RMI(Remote Method Invocation) ;
反射;
Java Bean;
JDK Version 1.2
1998-12-08 Playground(操场)
集合框架;
JIT(Just In Time)编译器;
对打包的Java文件进行数字签名;
JFC(Java Foundation Classes), 包括Swing 1.0, 拖放和Java2D类库;
Java插件;
JDBC中引入可滚动结果集 ,BLOB,CLOB,批量更新和用户自定义类型;
Applet中添加声音支持 .
同时,Sun发布了 JSP/Servlet、 EJB规范,以及将Java分成了 J2EE、J2SE和J2ME。 这表明了 Java开始向企业、桌面 应用和移动设备应用3大领域挺进。
JDK Version 1.3
2000-05-08 Kestrel(红集)
Java Sound API;
jar文件索引;
对Java的各个方面都做了大量优化和增强;
此时,Hotspot虚拟机成为Java的默认虚拟机。
JDK Version 1.4
2002-02-13 Merlin(集)
断言;
XML处理;
Java打印服务;
Logging API;
Java Web Start;
JDBC 3.0 API;
Preferences API;
链式异常处理;
支持IPV6;
支持正则表达式;
引入Image I/O API
同时,古老的Classic虚拟机退出历史舞台。
一年后,Java平台的Scala正式发布,同年Groovy也加入了 Java阵营。
JAVA 5
2004-09-30 Tiger(老虎)
类型安全的枚举;
泛型;
自动装箱与自动拆箱;
元数据(注解);
增强循环 ,可以使用迭代方式;
可变参数;
静态引入;
Instrumentation;
同时JDK 1.5改名为J2SE 5.0。
JAVA 6
2006-12-11 Mustang(野马)
支持脚本语言;
JDBC 4.0API;
Java Compiler API;
可插拔注解;
增加对Native PKI(Public Key Infrastructure), Java GSS(Generic Security
Service),Kerberos和LDAP(Lightweight Directory Access Protocol)支持;
继承Web Services;
同年,Java开源并建立了 OpenJDK。顺理成章,Hotspot虚拟机也成为了 OpenJDK中的默认虚拟机。
2007年,Java平台迎来了新伙伴Clojure。
2008 年,Oracle 收购了 BEA,得到了 JRockit 虚拟机。
2009年,Twitter宣布把后台大部分程序从Ruby迁移到Scala,这是Java平台的又一次大规模应用。
2010年,Oracle收购了Sun,获得最具价值的Hotspot虚拟机。此时,Oracle拥有市场占用率最高的两款虚拟机 Hotspot和JRockit ,并计划在未来对它们进行整合。
JAVA 7
2011-07-28 Dolphin(海豚)
钻石型语法(在创建泛型对象时应用类型推断);
支持try-with-resources(在一个语句块中捕获多种异常);
switch语句块中允许以字符串作为分支条件;
引入Java NIO.2开发包;
在创建泛型对象时应用类型推断;
支持动态语言;
数值类型可以用二进制字符串表示 ,并且可以在字符串表示中添加下划线;
null值的自动处理;
在JDK 1.7中,正式启用了新的垃圾回收器G1,支持了64位系统的压缩指针。
JAVA 8
2014-03-18
Lambda 表达式 − Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中。
方法引用 − 方法引用提供了非常有用的语法 ,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda 联合使用 ,方法引用可以使语言的构造更紧凑简洁 ,减少冗余代码。
默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
新工具 − 新的编译工具 ,如 :Nashorn引擎 jjs、 类依赖分析器jdeps。
Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
Date Time API − 加强对日期与时间的处理。
Optional 类 − Optional 类已经成为 Java 8 类库的一部分 ,用来解决空指针异常。
Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎 ,它允许我们在JVM上运行特 定的javascript应用。
JAVA 9
2017-09-22
模块系统 :模块是一个包的容器 ,Java 9 最大的变化之一是引入了模块系统( Jigsaw 项目)。
REPL (JShell) :交互式编程环境。
HTTP 2 客户端 :HTTP/2标准是HTTP协议的最新版本 ,新的 HTTPClient API 支持 WebSocket 和 HTTP2 流 以及服务器推送特性。
改进的 Javadoc :Javadoc 现在支持在 API 文档中的进行搜索。另外 ,Javadoc 的输出现在符合兼容 HTML5 标准。
多版本兼容 JAR 包 :多版本兼容 JAR 功能能让你创建仅在特定版本的 Java 环境中运行库程序时选择使用的 class 版本。
集合工厂方法 :List ,Set 和 Map 接口中 ,新的静态工厂方法可以创建这些集合的不可变实例。
私有接口方法 :在接口中使用private私有方法。我们可以使用 private 访问修饰符在接口中编写私有方法。
进程 API: 改进的 API 来控制和管理操作系统进程。引进 java.lang.ProcessHandle 及其嵌套接口 Info 来让开发者逃离时常因为要获取一个本地进程的 PID 而不得不使用本地代码的窘境。
改进的 Stream API:改进的 Stream API 添加了一些便利的方法 ,使流处理更容易 ,并使用收集器编写复杂的查 询。
改进 try-with-resources :如果你已经有一个资源是 final 或等效于 final 变量 ,您可以在 try-with- resources 语句中使用该变量 ,而无需在 try-with-resources 语句中声明一个新变量。
改进的弃用注解 @Deprecated :注解 @Deprecated 可以标记 Java API 状态 ,可以表示被标记的 API 将会被 移除 ,或者已经破坏。
改进钻石操作符(Diamond Operator) :匿名类可以使用钻石操作符(Diamond Operator)。
改进 Optional 类 :java.util.Optional 添加了很多新的有用方法 ,Optional 可以直接转为 stream。
多分辨率图像 API:定义多分辨率图像API ,开发者可以很容易的操作和展示不同分辨率的图像了。
改进的 CompletableFuture API : CompletableFuture 类的异步机制可以在 ProcessHandle.onExit
方法退出时执行操作。
轻量级的 JSON API: 内置了一个轻量级的JSON API
响应式流( Reactive Streams) API: Java 9中引入了新的响应式流 API 来支持 Java 9 中的响应式编程。
JAVA 10
2018-03-21
JEP286 ,var 局部变量类型推断。
JEP296 ,将原来用 Mercurial 管理的众多 JDK 仓库代码 ,合并到一个仓库中 ,简化开发和管理过程。
JEP304 ,统一的垃圾回收接口。
JEP307 ,G1 垃圾回收器的并行完整垃圾回收 ,实现并行性来改善最坏情况下的延迟。
JEP310 ,应用程序类数据 (AppCDS) 共享 ,通过跨进程共享通用类元数据来减少内存占用空间 ,和减少启动时间。 10
JEP312 ,ThreadLocal 握手交互。在不进入到全局 JVM 安全点 (Safepoint) 的情况下 ,对线程执行回调。优 化可以只停止单个线程 ,而不是停全部线程或一个都不停。
JEP313 ,移除 JDK 中附带的 javah 工具。可以使用 javac -h 代替。
JEP314 ,使用附加的 Unicode 语言标记扩展。
JEP317 ,能将堆内存占用分配给用户指定的备用内存设备。
JEP317 ,使用 Graal 基于 Java 的编译器 ,可以预先把 Java 代码编译成本地代码来提升效能。
JEP318 ,在 OpenJDK 中提供一组默认的根证书颁发机构证书。开源目前 Oracle 提供的的 Java SE 的根证 书 ,这样 OpenJDK 对开发人员使用起来更方便。
JEP322 ,基于时间定义的发布版本 ,即上述提到的发布周期。版本号为
$FEATURE.$INTERIM.$UPDATE.$PATCH ,分别是大版本 ,中间版本 ,升级包和补丁版本。
JAVA 11
2018-09-25
181: Nest-Based Access Control(基于嵌套的访问控制)
309: Dynamic Class-File Constants(动态的类文件常量)
315: Improve Aarch64 Intrinsics(改进 Aarch64 Intrinsics)
318: Epsilon: A No-Op Garbage Collector( Epsilon 垃圾回收器 ,又被称为 "No-Op(无操作) "回收 器)
320: Remove the Java EE and CORBA Modules(移除 Java EE 和 CORBA 模块 ,JavaFX 也已被移除)
321: HTTP Client (Standard)
323: Local-Variable Syntax for Lambda Parameters(用于 Lambda 参数的局部变量语法)
324: Key Agreement with Curve25519 and Curve448(采用 Curve25519 和 Curve448 算法实现的密 钥协议)
327: Unicode 10
328: Flight Recorder(飞行记录仪)
329: ChaCha20 and Poly1305 Cryptographic Algorithms(实现 ChaCha20 和 Poly1305 加密算法)
330: Launch Single-File Source-Code Programs(启动单个 Java 源代码文件的程序)
331: Low-Overhead Heap Profiling(低开销的堆分配采样方法)
332: Transport Layer Security (TLS) 1.3(对 TLS 1.3 的支持)
333: ZGC: A Scalable Low-Latency Garbage Collector (Experimental)( ZGC:可伸缩的低延迟垃圾 回收器 ,处于实验性阶段)
335: Deprecate the Nashorn JavaScript Engine(弃用 Nashorn JavaScript 引擎) 32
336: Deprecate the Pack200 Tools and API(弃用 Pack200 工具及其 API )
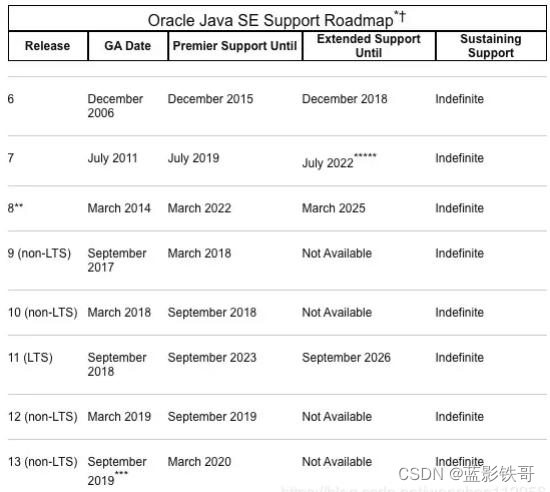
2、JDK 各版本支持周期
为了更快地迭代,Java的更新从传统的以特性驱动的发布周期,转变为以时间驱动的(6 个月为周期)发布模式 —— 每半年发布一个大版本,每个季度发布一个中间特性版本,并且承诺不会跳票。通过这样的方式,开发团队可以把一 些关键特性尽早合并到 JDK 之中,以快速得到开发者反馈,在一定程度上避免出现像 Java 9 这样两次被迫延迟发布 的窘况。
按照官方的说法,新的发布周期会严格遵循时间点,将于每年的3月份和9月份发布。所以 Java 11 的版本号是
18.9(LTS ,long term support)。Oracle 直到2023年9月都会为 Java 11 提供技术支持,而补丁和安全警告等扩展支 持将持续到2026年。
新的长期支持版本每三年发布一次,根据后续的发布计划,下一个长期支持版 Java 17 将于2021年发布。
3、版本升级的破坏性
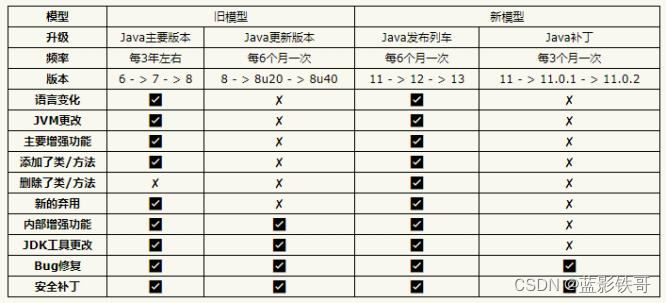
Oracle 的官方观点认为:与 Java 7->8->9 相比,Java 9->10->11的升级和 8->8u20->8u40 更相似。
表格清楚地显示新模式下的 Java 版本发布都会包含许多变更,包括语言变更和 JVM 变更,这两者都会对 IDE、字节 码库和框架产生重大影响。此外,不仅会新增其他 API,还会有 API 被删除(这在 Java 8 之前没有发生过) 。
Oracle 的观点是,因为每个版本仅在前一个版本发布后的 6 个月推出,所以不会有太多新的“东西” ,因此升级并不困 难。虽然如此,但这不是重点。 重要的是升级是否有可能会破坏代码。 很明显,从 11 -> 12 -> 13 开始,代码遭受破 坏的可能性要大于 8 -> 8u20 -> 8u40。
11 -> 12 -> 13 与 8u20 -> 8u40 等这样的更新主要区别在于对字节码版本的更改以及对规范的更改,对字节码版本的
更改往往特别具有破坏性,大多数框架都大量使用与每个字节码版本密切相关的 ASM 或 ByteBuddy 等库。而 8u20 -> 8u40 仍然使用相同的 Java SE 规范,具有所有相同的类和方法,不同于从 Java 12 移动到 13。
除此之外,Oracle 的另一个声明也十分值得我们关注。声明透露出的消息是,如果坚持使用 Java 11 并计划在下一个 LTS 版本(即 Java 17)发布时再进行升级,开发者可能会发现自己的项目代码无法通过编译。所以请记住,Java 新的 开发规则现在声明可以在一个版本中弃用某个 API 方法,并在下一个版本中删除它。 因此,一个方法可以在13中弃 用并在15中删除。有人从11升级到17只会找到一个从未见过弃用的已删除API。
4、JDK12新特性概述
美国当地时间 2019 年 3 月 19 日,也就是北京时间 20 号 Java 12 正式发布了!
Features :总共有8个新的JEP(JDK Enhancement Proposals)。
189:Shenandoah:A Low-Pause-Time Garbage Collector(Experimental)
低暂停时间的GC
http://openjdk.java.net/jeps/189
230:Microbenchmark Suite
微基准测试套件
http://openjdk.java.net/jeps/230
325:Switch Expressions(Preview)
switch表达式
http://openjdk.java.net/jeps/325
334:JVM Constants API
JVM常量API
http://openjdk.java.net/jeps/334
340:One AArch64 Port,Not Two
只保留一个AArch64实现
http://openjdk.java.net/jeps/340
341:Default CDS Archives
默认类数据共享归档文件
http://openjdk.java.net/jeps/341
344:Abortable Mixed Collections for G1
可中止的G1 Mixed GC
http://openjdk.java.net/jeps/344
346:Promptly Return Unused Committed Memory from G1
G1及时返回未使用的已分配内存
http://openjdk.java.net/jeps/346
一、Switch表达式(预览)
1、传统switch的弊端
传统的switch声明语句(switch statement)在使用中有一些问题:
- 匹配是自上而下的,如果忘记写break, 后面的case语句不论匹配与否都会执行;
- 所有的case语句共用一个块范围,在不同的case语句定义的变量名不能重复;
- 不能在一个case里写多个执行结果一致的条件;
- 整个switch不能作为表达式返回值;
Java 12将会对switch声明语句进行扩展,可将其作为增强版的 switch 语句或称为 "switch 表达式"来写出更加简化的 代码。
2、 何为预览语言
Switch 表达式也是作为预览语言功能的第一个语言改动被引入新版 Java 中来的,预览语言功能的想法是在 2018 年 初被引入 Java 中的,本质上讲,这是一种引入新特性的测试版的方法。 通过这种方式,能够根据用户反馈进行升
级、更改,在极端情况下,如果没有被很好的接纳,则可以完全删除该功能。预览功能的关键在于它们没有被包含在 Java SE 规范中。
3、语法详解
扩展的 switch 语句,不仅可以作为语句(statement),还可以作为表达式( expression),并且两种写法都可以 使用传统的 switch 语法,或者使用简化的“case L ->”模式匹配语法作用于不同范围并控制执行流。这些更改将简化日 常编码工作,并为 switch 中的模式匹配(JEP 305)做好准备。
- 使用 Java 12 中 Switch 表达式的写法,省去了 break 语句,避免了因少写 break 而出错。
- 同时将多个 case 合并到一行,显得简洁、清晰也更加优雅的表达逻辑分支,其具体写法就是将之前的 case 语 句表成了: case L -> ,即如果条件匹配 case L,则执行标签右侧的代码 ,同时标签右侧的代码段只能是表达 式、代码块或 throw 语句。
- 为了保持兼容性, case 条件语句中依然可以使用字符 : ,这时 fall-through 规则依然有效的,即不能省略原有 的 break 语句,但是同一个 Switch 结构里不能混用 -> 和 : ,否则会有编译错误。并且简化后的 Switch 代码块 中定义的局部变量,其作用域就限制在代码块中,而不是蔓延到整个 Switch 结构,也不用根据不同的判断条件 来给变量赋值。
4、使用案例
JDK12之前:
package com.zt.jdk12NewFeatures;
public class Jdk12NewFeatures {
// JDK12之前
public static void main(String[] args) {
int numberOfLetters;
Fruit fruit = Fruit.APPLE;
switch (fruit) {
case PEAR:
numberOfLetters = 4;
break;
// 后面的没有break,会case穿透,顺序往下,直到break
case APPLE:
case GRAPE:
case MANGO:
numberOfLetters = 5;
break;
case ORANGE:
case PAPAYA:
numberOfLetters = 6;
break;
default:
throw new IllegalStateException("No Such Fruit:" + fruit);
}
System.out.println(numberOfLetters);// 5
}
enum Fruit {
PEAR, APPLE, GRAPE, MANGO, ORANGE, PAPAYA;
}
}
如果有编码经验,你一定知道,switch 语句如果漏写了一个 break,那么逻辑往往就跑偏了,这种方式既繁琐,又容 易出错。如果换成 switch 表达式,Pattern Matching 机制能够自然地保证只有单一路径会被执行。
JDK12优化一:
// JDK12优化一
public static void main(String[] args) {
Fruit fruit = Fruit.GRAPE;
switch(fruit){
case PEAR -> System.out.println(4);
case APPLE,MANGO,GRAPE -> System.out.println(5);// 打印输出5
case ORANGE,PAPAYA -> System.out.println(6);
default -> throw new IllegalStateException("No Such Fruit:" + fruit); };
}
enum Fruit {
PEAR, APPLE, GRAPE, MANGO, ORANGE, PAPAYA;
}
JDK12优化二:
更进一步,下面的表达式,为我们提供了优雅地表达特定场合计算逻辑的方式:
// JDK12优化二
public static void main(String[] args) {
Fruit fruit = Fruit.GRAPE;
int numberOfLetters = switch(fruit){
case PEAR -> 4;
case APPLE,MANGO,GRAPE -> 5;
case ORANGE,PAPAYA -> 6;
default -> throw new IllegalStateException("No Such Fruit:" + fruit); };
System.out.println(numberOfLetters);// 5
}
enum Fruit {
PEAR, APPLE, GRAPE, MANGO, ORANGE, PAPAYA;
}
5、使用总结
这个语法如果做过Android开发的不会陌生,因为Kotlin 家的 when 表达式就是这么干的!
Switch Expressions 或者说起相关的 Pattern Matching 特性,为我们勾勒出了 Java 语法进化的一个趋势,将开发者 从复杂繁琐的低层次抽象中逐渐解放出来,以更高层次更优雅的抽象,既降低代码量,又避免意外编程错误的出现, 进而提高代码质量和开发效率。
6、展望
Java 11 以及之前版本中,Switch 表达式支持下面类型: byte、char、short、 int、 Byte、Character、Short、
Integer、enum、String,在未来的某个 Java 版本有可能会允许支持 float、double 和 long (以及对应类型的包装 类型)。
二、Shenandoah GC:低停顿时间的GC(预览)
1、背景和设计思路
Shenandoah (/ˌʃɛnənˈdoʊə/ 谢南多厄)垃圾回收器是 Red Hat 在 2014 年宣布进行的一项垃圾收集器研究项目 Pauseless GC 的实现,旨在针 对 JVM 上的内存收回实现低停顿的需求。该设计将与应用程序线程并发,通过交换 CPU 并发周期和空间以改善停顿 时间,使得垃圾回收器执行线程能够在 Java 线程运行时进行堆压缩,并且标记和整理能够同时进行,因此避免了在 大多数 JVM 垃圾收集器中所遇到的问题。
据 Red Hat 研发 Shenandoah 团队对外宣称,Shenandoah 垃圾回收器的暂停时间与堆大小无关,这意味着无论将 堆设置为 200 MB 还是 200 GB,都将拥有一致的系统暂停时间,不过实际使用性能将取决于实际工作堆的大小和工 作负载。
与其他 Pauseless GC 类似,Shenandoah GC 主要目标是 99.9% 的暂停小于 10ms ,暂停与堆大小无关等。
这是一个实验性功能,不包含在默认(Oracle)的OpenJDK版本中。
2、前置知识:STW
Stop-the-World ,简称STW ,指的是GC 事件发生过程中,停止所有的应用程序线程的执行。就像警察办案,需要 清场一样。
垃圾回收器的任务是识别和回收垃圾对象进行内存清理。为了让垃圾回收器可以正常且高效地执行,大部分情况下会 要求系统进入一个停顿的状态。 停顿的目的是终止所有应用程序的执行,只有这样,系统中才不会有新的垃圾产生, 同时停顿保证了系统状态在某一个瞬间的一致性 ,也有益于垃圾回收器更好地标记垃圾对象。因此,在垃圾回收时, 都会产生应用程序的停顿。停顿产生时整个应用程序会被暂停,没有任何响应,有点像卡死的感觉,这个停顿称为
STW 。
如果Stop-the- World 出现在新生代的Minor GC 中时, 由于新生代的内存空间通常都比较小, 所以暂停时间也在可 接受的合理范围之内,不过一旦出现在老年代的Full GC 中时,程序的工作线程被暂停的时间将会更久。简单来说,
内存空间越大,执行Full GC 的时间就会越久, 相对的工作线程被暂停的时间也就会更长。
到目前为止,哪怕是G1 也不能完全避免Stop-the-world 情况发生,只能说垃圾回收器越来越优秀,回收效率越来越 高, 尽可能地缩短了暂停时间。
3、前置知识:垃圾收集器的分类
由于JDK 的版本处于高速迭代过程中,因此Java 发展至今已经衍生了众多的GC 版本。
从不同角度分析垃圾收集器,可以将GC 分为不同的类型。
按线程数分,可以分为串行垃圾回收器和并行垃圾回收器。
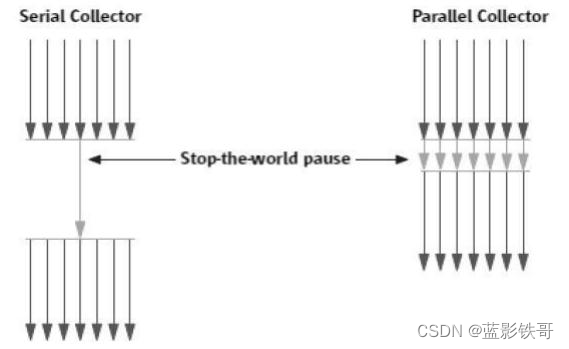
- 串行回收指的是在同一时间段内只允许一件事情发生,简单来说,当多个CPU 可用时,也只能有一个CPU 用于执行垃圾回收操作,井且在执行垃圾回收时,程序中的工作线程将会被暂停,当垃圾收集工作完成后 才会恢复之前被暂停的工作线程,这就是串行回收。
- 和串行回收相反,并行收集可以运用多个CPU 同时执行垃圾回收,因此提升了应用的吞吐量,不过并行回
收仍然与串行回收一样,采用独占式,使用了“ Stop-the-world ”机制和复制算法。
按照工作模式分,可以分为并发式回收器和独占式垃圾回收器。
- 并发式垃圾回收器与应用程序线程交替工作,以尽可能减少应用程序的停顿时间。
- 独占式垃圾回收器( Stop the world)一旦运行,就停止应用程序中的其他所有线程,直到垃圾回收过程完 全结束。
按碎片处理方式可分为压缩式垃圾回收器和非压缩式垃圾回收器。
- 压缩式垃圾回收器会在回收完成后,对存活对象进行压缩整理,消除回收后的碎片。
- 非压缩式的垃圾回收器不进行这步操作。
按工作的内存区间,又可分为年轻代垃圾回收器和老年代垃圾回收器。
4、前置知识:如何评估一款GC的性能
吞吐量:程序的运行时间(程序的运行时间+内存回收的时间)。
垃圾收集开销:吞吐量的补数,垃圾收集器所占时间与总时间的比例。
暂停时间:执行垃圾收集时,程序的工作线程被暂停的时间。
收集频率:相对于应用程序的执行,收集操作发生的频率。
堆空间: Java 堆区所占的内存大小。
快速: 一个对象从诞生到被回收所经历的时间。
需要注意的是, 垃圾收集器中吞吐量和低延迟这两个目标本身是相互矛盾的,因为如果选择以吞吐量优先,那么必 然需要降低内存回收的执行频率,但是这样会导致GC 需要更长的暂停时间来执行内存回收。相反的,如果选择以低 延迟优先为原则,那么为了降低每次执行内存回收时的暂停时间,也只能频繁地执行内存回收,但这又引起了年轻代 内存的缩减和导致程序吞吐量的下降。
5、工作原理
从原理的角度,我们可以参考该项目官方的示意图,其内存结构与 G1 非常相似,都是将内存划分为类似棋盘的region。整体流程与 G1 也是比较相似的,最大的区别在于实现了并发的 疏散(Evacuation) 环节,引入的 Brooks Forwarding Pointer 技术使得 GC 在移动对象时,对象引用仍然可以访问。
Shenandoah GC 工作周期如下所示:
上图对应工作周期如下:
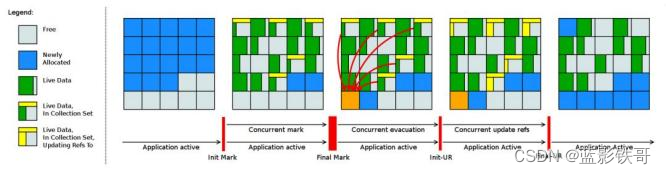
- Init Mark 启动并发标记 阶段
- 并发标记遍历堆阶段
- 并发标记完成阶段
- 并发整理回收无活动区域阶段
- 并发 Evacuation 整理内存区域阶段
- Init Update Refs 更新引用初始化 阶段
- 并发更新引用阶段
- Final Update Refs 完成引用更新阶段
- 并发回收无引用区域阶段
6、信息延展
也许了解 Shenandoah GC 的人比较少,业界声音比较响亮的是 Oracle 在 JDK11 中开源出来的 ZGC,或者商业版本 的 Azul C4(Continuously Concurrent Compacting Collector)。但是,至少目前我认为,其实际意义大于后两
者,因为:
- 使用 ZGC 的最低门槛是升级到 JDK11,对很多团队来说,这种版本的跳跃并不是非常低成本的事情,更何况是 尚不清楚 ZGC 在自身业务场景中的实际表现如何。
- 而 C4,毕竟是土豪们的选择,现实情况是,有多少公司连个几十块钱的 License 都不舍得。
- 而 Shenandoah GC 可是有稳定的 JDK8u 版本发布的。据了解,已经有个别公司在 HBase 等高实时性产品中实 践许久。
- ZGC也是面向low-pause-time的垃圾收集器,不过ZGC是基于colored pointers来实现,而Shenandoah GC是 基于brooks pointers来实现。
需要了解,不是唯有 GC 停顿可能导致常规应用程序响应时间比较长。具有较长的 GC 停顿时间会导致系统响应慢的 问题,但响应时间慢并非一定是 GC 停顿时间长导致的,队列延迟、网络延迟、其他依赖服务延迟和操作提供调度程 序抖动等都可能导致响应变慢。 使用 Shenandoah 时需要全面了解系统运行情况,综合分析系统响应时间。下面是 jbb15 benchmark 中,Shenandoah GC 相对于其他主流 GC 的表现。
各种 GC 工作负载对比:
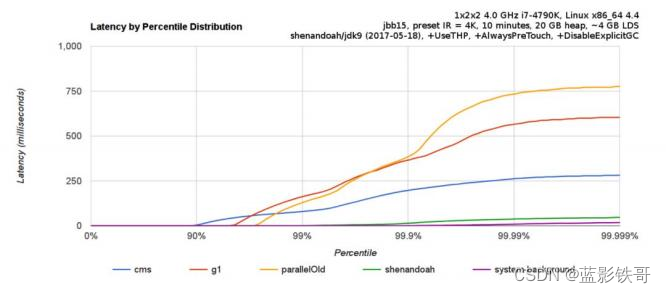
GC 暂停相比于 CMS 等选择有数量级程度的提高,对于 GC 暂停非常敏感的场景,价值还是很明显的,能够在 SLA 层面有显著提高。当然,这种对于低延迟的保证,也是以消耗 CPU 等计算资源为代价的,实际吞吐量表现也不是非 常明朗,需要看企业的实际场景需求,并不是一个一劳永逸的解决方案。
下面推荐几个配置或调试 Shenandoah 的 JVM 参数:
-XX:+AlwaysPreTouch :使用所有可用的内存分页 ,减少系统运行停顿 ,为避免运行时性能损失。
-Xmx == -Xmsv :设置初始堆大小与最大值一致 ,可以减轻伸缩堆大小带来的压力 ,与 AlwaysPreTouch 参数配 合使用 ,在启动时提交所有内存 ,避免在最终使用中出现系统停顿。
-XX:+ UseTransparentHugePages :能够大大提高大堆的性能 ,同时建议在 Linux 上使用时将 /sys/kernel/mm/transparent_hugepage/enabled 和
/sys/kernel/mm/transparent_hugepage/defragv 设置为 :madvise ,同时与 AlwaysPreTouch 一起使 用时 ,init 和 shutdownv 速度会更快 ,因为它将使用更大的页面进行预处理。
-XX:+UseNUMA:虽然 Shenandoah 尚未明确支持 NUMA( Non-Uniform Memory Access) ,但最好启用此功 能以在多插槽主机上启用 NUMA 交错。与 AlwaysPreTouch 相结合 ,它提供了比默认配置更好的性能。
-XX:+DisableExplicitGC:忽略代码中的 System.gc() 调用。当用户在代码中调用 System.gc() 时会强制 Shenandoah 执行 STW Full GC ,应禁用它以防止执行此操作 ,另外还可以使用 -
XX:+ExplicitGCInvokesConcurrent ,在 调用 System.gc() 时执行 CMS GC 而不是 Full GC ,建议在有 System.gc() 调用的情况下使用。
不过目前 Shenandoah 垃圾回收器还被标记为实验项目 ,如果要使用Shenandoah GC需要编译时–with-jvm- features选项带有shenandoahgc ,然后启动时使用参数
-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC
三、JVM 常量 API
1、概念
Java 12 中引入 JVM 常量 API,用来更容易地对关键类文件 (key class-file) 和运行时构件(artefact)的名义描述 (nominal description) 进行建模,特别是对那些从常量池加载的常量,这是一项非常技术性的变化,能够以更简 单、标准的方式处理可加载常量。
具体来说就是java.base模块新增了java.lang.constant包(而非 java.lang.invoke.constant )。包中定义了一系列基 于值的符号引用(JVMS 5.1)类型,它们能够描述每种可加载常量。
官方api链接地址:
http://cr.openjdk.java.net/~iris/se/12/latestSpec/api/java.base/java/lang/constant/pack age-summary.html
Java SE > Java SE Specifications > Java Virtual Machine Specification下的第5章 : Chapter 5. Loading, Linking, and Initializing
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-5.html
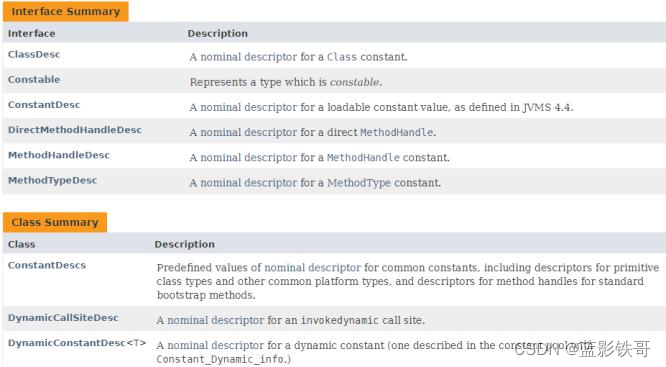
引入了ConstantDesc接口(ClassDesc、MethodTypeDesc、MethodHandleDesc这几个接口直接继承了ConstantDesc接口)以及Constable接口;ConstantDesc接口定义了resolveConstantDesc方法,Constable接口定义了describeConstable方法;String、 Integer、 Long、 Float、 Double均实现了这两个接口,而EnumDesc实现了 ConstantDesc接口
符号引用以纯 nominal 形式描述可加载常量,与类加载或可访问性上下文区分开。有些类可以作为自己的符号引用 (例如 String)。而对于可链接常量,另外定义了一系列符号引用类型,具体包括: ClassDesc (Class 的可加载常量 标称描述符) ,MethodTypeDesc(方法类型常量标称描述符) ,MethodHandleDesc (方法句柄常量标称描述符) 和DynamicConstantDesc (动态常量标称描述符) ,它们包含描述这些常量的 nominal 信息。此 API 对于操作类和方法 的工具很有帮助。
2、String 实现了 Constable 接口
public final class String implements java.io.Serializable, Comparable<String>, CharSequence,Constable, ConstantDesc {}
java.lang.constant.Constable接口定义了抽象方法:
public interface Constable {
Optional<? extends ConstantDesc> describeConstable();
}
Java 12 String 的实现源码:
public Optional<String> describeConstable() {
return Optional.of(this);
}
很简单,其实就是调用 Optional.of 方法返回一个 Optional 类型,Optional不懂的可以参考Java 8的新特性。
3、String的describeConstable和resolveConstantDesc
一个非常有趣的方法来自新引入的接口java.lang.constant.Constable - 它用于标记constable类型,这意味着这类型 的值是常量,可以在JVMS 4.4常量池中定义。
Java SE > Java SE Specifications > Java Virtual Machine Specification下的第4章 : Chapter 4. The class File Format
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html
String的源码:
/**
* Returns an {@link Optional} containing the nominal descriptor for this
* instance, which is the instance itself. *
* @return an {@link Optional} describing the {@linkplain String} instance
* @since 12 */
@Override
public Optional<String> describeConstable() {
return Optional.of(this);
}
/**
* Resolves this instance as a {@link ConstantDesc}, the result of which is
* the instance itself. *
* @param lookup ignored
* @return the {@linkplain String} instance
* @since 12 */
@Override
public String resolveConstantDesc(MethodHandles.Lookup lookup) {
return this;
}
使用案例:
private static void testDescribeConstable() {
String name = "蓝影铁哥";
Optional<String> optional = name.describeConstable();
System.out.println(optional.get());// 蓝影铁哥
}
类加载的时候定义了一些常量的描述,实现上面两个接口的类,在加载这些类的时候更加便捷,可以从常量池加载,更加高效快捷。
四、 微基准测试套件
1、何为JMH
JMH,即Java Microbenchmark Harness,是专门用于代码微基准测试的工具套件。何谓Micro Benchmark呢?简 单的来说就是基于方法层面的基准测试,精度可以达到微秒级。当你定位到热点方法,希望进一步优化方法性能的时 候,就可以使用JMH对优化的结果进行量化的分析。
2、JMH比较典型的应用场景
● 想准确的知道某个方法需要执行多长时间,以及执行时间和输入之间的相关性;
● 对比接口不同实现在给定条件下的吞吐量;
● 查看多少百分比的请求在多长时间内完成;
3、JMH的使用
要使用JMH,首先需要准备好Maven环境,JMH的源代码以及官方提供的Sample就是使用Maven进行项目管理的, github上也有使用gradle的例子可自行搜索参考。使用mvn命令行创建一个JMH工程:
mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype \
-DgroupId=co.speedar.infra \
-DartifactId=jmh-test \
-Dversion=1.0
如果要在现有Maven项目中使用JMH,只需要把生成出来的两个依赖以及shade插件拷贝到项目的pom中即可:
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>0.7.1</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId> <version>0.7.1</version>
<scope>provided</scope>
</dependency>
...
<plugin>
<groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>microbenchmarks</finalName> <transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jmh.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
4、新特性的说明
ava 12 中添加一套新的基本的微基准测试套件(microbenchmarks suite),此功能为JDK源代码添加了一套微基准 测试(大约100个),简化了现有微基准测试的运行和新基准测试的创建过程。 使开发人员可以轻松运行现有的微基准测试并创建新的基准测试,其目标在于提供一个稳定且优化过的基准。 它基于Java Microbenchmark Harness(JMH),可以轻松测试JDK性能,支持JMH更新。
微基准套件与 JDK 源代码位于同一个目录中,并且在构建后将生成单个 jar 文件。但它是一个单独的项目,在支持构 建期间不会执行,以方便开发人员和其他对构建微基准套件不感兴趣的人在构建时花费比较少的构建时间。
要构建微基准套件,用户需要运行命令:make build-microbenchmark ,类似的命令还有:make test TEST=“micro:java.lang.invoke” 将使用默认设置运行 java.lang.invoke 相关的微基准测试。
五、只保留一个 AArch64 实现
1、现状
当前 Java 11 及之前版本JDK中存在两个64位ARM端口。这些文件的主要来源位于 src/hotspot/cpu/arm和
open/src/hotspot/cpu/aarch64 目录中。尽管两个端口都产生了 aarch64实现,我们将前者(由Oracle贡献)称 为 arm64 ,将后者称为 aarch64 。
2、新特性
Java 12 中将删除由 Oracle 提供的 arm64端口相关的所有源码,即删除目录 open/src/hotspot/cpu/arm 中关于 64-bit 的这套实现,只保留其中有关 32-bit ARM端口的实现,余下目录的 open/src/hotspot/cpu/aarch64 代码 部分就成了 AArch64 的默认实现。
3、目的
这将使开发贡献者将他们的精力集中在单个 64 位 ARM 实现上,并消除维护两套实现所需的重复工作。
六、默认生成类数据共享(CDS)归档文件
1、概述
我们知道在同一个物理机/虚拟机上启动多个JVM时,如果每个虚拟机都单独装载自己需要的所有类,启动成本和内 存占用是比较高的。所以Java团队引入了类数据共享机制 (Class Data Sharing ,简称 CDS) 的概念,通过把一些核心 类在每个JVM间共享,每个JVM只需要装载自己的应用类即可。好处是:启动时间减少了,另外核心类是共享的,所 以JVM的内存占用也减少了。
2、历史版本
- JDK5引入了Class-Data Sharing可以用于多个JVM共享class,提升启动速度,最早只支持system classes及 serial GC。
- JDK9对其进行扩展以支持application classes及其他GC算法。
- java10的新特性JEP 310: Application Class-Data Sharing扩展了JDK5引入的Class-Data Sharing,支持 application的Class-Data Sharing并开源出来(以前是commercial feature)
- CDS 只能作用于 BootClassLoader 加载的类,不能作用于 AppClassLoader 或者自定义的 ClassLoader 加载的类。在 Java 10 中,则将 CDS 扩展为 AppCDS,顾名思义,AppCDS 不止能够作用于BootClassLoader了,AppClassLoader 和自定义的 ClassLoader 也都能够起作用,大大加大了 CDS 的适 用范围。也就说开发自定义的类也可以装载给多个JVM共享了。
- JDK11将-Xshare:off改为默认-Xshare:auto,以更加方便使用CDS特性
3、迭代效果
可以说,自 Java 8 以来,在基本 CDS 功能上进行了许多增强、改进,启用 CDS 后应用的启动时间和内存占用量显着 减少。使用 Java 11 早期版本在 64 位 Linux 平台上运行 HelloWorld 进行测试,测试结果显示启动时间缩短有 32%,同时在其他 64 位平台上,也有类似或更高的启动性能提升。
4、新特性
JDK 12之前,想要利用CDS的用户,即使仅使用JDK中提供的默认类列表,也必须 java -Xshare:dump作为额外的步 骤来运行。
Java 12 针对 64 位平台下的 JDK 构建过程进行了增强改进,使其默认生成类数据共享(CDS)归档,以进一步达到 改进应用程序的启动时间的目的,同时也避免了需要手动运行:java -Xshare:dump 的需要,修改后的 JDK 将在 ${JAVA_HOME}/lib/server 目录中生成一份名为classes.jsa的默认archive文件(大概有18M)方便大家使用。
当然如果需要,也可以添加其他 GC 参数,来调整堆大小等,以获得更优的内存分布情况,同时用户也可以像之前一 样创建自定义的 CDS 存档文件。
七、可中断的 G1 Mixed GC
简言之,当 G1 垃圾回收器的回收超过暂停时间的目标,则能中止垃圾回收过程。
G1是一个垃圾收集器,设计用于具有大量内存的多处理器机器。由于它提高了性能效率,G1垃圾收集器最终将取代 CMS垃圾收集器。
该垃圾收集器设计的主要目标之一是满足用户设置的预期的 JVM 停顿时间。
G1 采用一个高级分析引擎来选择在收集期间要处理的工作量,此选择过程的结果是一组称为 GC 回收集(collection set( CSet))的区域。一旦收集器确定了 GC 回收集 并且 GC 回收、整理工作已经开始,这个过程是withoutstopping的,即 G1 收集器必须完成收集集合的所有区域中的所有活动对象之后才能停止;但是如果收集器选择过大 的 GC 回收集,此时的STW时间会过长超出目标pause time。
这种情况在mixed collections时候比较明显。这个特性启动了一个机制,当选择了一个比较大的collection set ,Java 12 中将把 GC 回收集(混合收集集合)拆分为mandatory(必需或强制)及optional两部分(当完成mandatory的部 分 ,如果还有剩余时间则会去处理optional部分)来将mixed collections从without stopping变为abortable,以更好满 足指定pause time的目标。
- 其中必需处理的部分包括 G1 垃圾收集器不能递增处理的 GC 回收集的部分(如:年轻代),同时也可以包含老 年代以提高处理效率。
- 将 GC 回收集拆分为必需和可选部分时,垃圾收集过程优先处理必需部分。同时,需要为可选 GC 回收集部分维 护一些其他数据,这会产生轻微的 CPU 开销,但小于 1 %的变化,同时在 G1 回收器处理 GC 回收集期间,本 机内存使用率也可能会增加,使用上述情况只适用于包含可选 GC 回收部分的 GC 混合回收集合
- 在 G1 垃圾回收器完成收集需要必需回收的部分之后,如果还有时间的话,便开始收集可选的部分。但是粗粒度 的处理,可选部分的处理粒度取决于剩余的时间,一次只能处理可选部分的一个子集区域。在完成可选收集部 分的收集后,G1 垃圾回收器可以根据剩余时间决定是否停止收集。如果在处理完必需处理的部分后,剩余时间 不足,总时间花销接近预期时间,G1 垃圾回收器也可以中止可选部分的回收以达到满足预期停顿时间的目标
八、增强G1,自动返回未用堆内存给操作系统
1、概述
上面介绍了 Java 12 中增强了 G1 垃圾收集器关于混合收集集合的处理策略,这节主要介绍在 Java 12 中同时也对 G1 垃圾回收器进行了改进,使其能够在空闲时自动将 Java 堆内存返还给操作系统,这也是 Java 12 中的另外一项重大 改进。
目前 Java 11 版本中包含的 G1 垃圾收集器暂时无法及时将已提交的 Java 堆内存返回给操作系统。为什么呢? G1目 前只有在full GC或者concurrent cycle(并发处理周期)的时候才会归还内存,由于这两个场景都是G1极力避免的, 因此在大多数场景下可能不会及时归还committed Java heap memory给操作系统。除非有外部强制执行。
在使用云平台的容器环境中,这种不利之处特别明显。 即使在虚拟机不活动,但如果仍然使用其分配的内存资源,哪 怕是其中的一小部分,G1 回收器也仍将保留所有已分配的 Java 堆内存。而这将导致用户需要始终为所有资源付费, 哪怕是实际并未用到,而云提供商也无法充分利用其硬件。 如果在此期间虚拟机能够检测到 Java 堆内存的实际使用 情况,并在利用空闲时间自动将 Java 堆内存返还,则两者都将受益。
2、具体操作
为了尽可能的向操作系统返回空闲内存,G1 垃圾收集器将在应用程序不活动期间定期生成或持续循环检查整体 Java 堆使用情况,以便 G1 垃圾收集器能够更及时的将 Java 堆中不使用内存部分返还给操作系统。对于长时间处于空闲 状态的应用程序,此项改进将使 JVM 的内存利用率更加高效。
而在用户控制下,可以可选地执行Full GC ,以使返回的内存量最大化。
JDK12的这个特性新增了两个参数分别是G1 PeriodicGCInterval及G1 PeriodicGCSystemLoadThreshold,设置为0 的话,表示禁用。如果应用程序为非活动状态,在下面两种情况任何一个描述下,G1 回收器会触发定期垃圾收集:
- 自上次垃圾回收完成以来已超过 G1PeriodicGCInterval ( milliseconds) ,并且此时没有正在进行的垃圾回收 任务。如果 G1PeriodicGCInterval 值为零表示禁用快速回收内存的定期垃圾收集。
- 应用所在主机系统上执行方法 getloadavg(),默认一分钟内系统返回的平均负载值低于G1PeriodicGCSystemLoadThreshold指定的阈值,则触发full GC或者concurrent GC(如果开启G1PeriodicGCInvokesConcurrent) ,GC之后Java heap size会被重写调整,然后多余的内存将会归还给操作 系统。如果 G1PeriodicGCSystemLoadThreshold 值为零,则此条件不生效。
如果不满足上述条件中的任何一个,则取消当期的定期垃圾回收。等一个 G1PeriodicGCInterval 时间周期后,将重 新考虑是否执行定期垃圾回收。
G1 定期垃圾收集的类型根据 G1PeriodicGCInvokesConcurrent 参数的值确定:如果设置值了,G1 垃圾回收器将继 续上一个或者启动一个新并发周期;如果没有设置值,则 G1 回收器将执行一个Full GC。在每次一次 GC 回收末尾, G1 回收器将调整当前的 Java 堆大小,此时便有可能会将未使用内存返还给操作系统。新的 Java 堆内存大小根据现 有配置确定,具体包括下列配置: - XX:MinHeapFreeRatio、-XX:MaxHeapFreeRatio、-Xms、-Xmx。
默认情况下,G1 回收器在定期垃圾回收期间新启动或继续上一轮并发周期,将最大限度地减少应用程序的中断。 如 果定期垃圾收集严重影响程序执行,则需要考虑整个系统 CPU 负载,或让用户禁用定期垃圾收集。
九、其他解读
上面列出的是大方面的特性,除此之外还有一些api的更新及废弃,主要见JDK 12 Release Notes ,这里举几个例 子。
1、增加项:支持unicode 11
JDK 12版本包括对Unicode 11.0.0的支持。在发布支持Unicode 10.0.0的JDK 11之后 ,Unicode 11.0.0引 入了以下JDK 12中包含的新功能 :
684 new characters
11 new blocks
7 new scripts.
其中 :
684个新字符 ,包含以下重要内容 :
66个表情符号字符( 66 emoji characters)
Copyleft符号( Copyleft symbol)
评级系统的半星( Half stars for rating systems)
额外的占星符号( Additional astrological symbols)
象棋中国象棋符号( Xiangqi Chinese chess symbols)
7个新脚本 :
Hanifi Rohingya
Old Sogdian
Sogdian
Dogra
Gunjala Gondi
Makasar
Medefaidrin
11个新块 ,包括上面列出的新脚本的7个块和以下现有脚本的4个块 :
格鲁吉亚扩展( Georgian Extended)
玛雅数字( Mayan Numerals)
印度Siyaq数字( Indic Siyaq Numbers)
国际象棋符号( Chess Symbols)
2、增加项:支持压缩数字格式化
NumberFormat 添加了对以紧凑形式格式化数字的支持。紧凑数字格式是指以简短或人类可读形式表示的数字。例如,在en_US语言环境中,1000可以格式化为“1K” ,1000000可以格式化为“1M”,具体取决于指定的样式 NumberFormat.Style。
@Test
public void testCompactNumberFormat(){
var cnf = NumberFormat.getCompactNumberInstance(Locale.CHINA,
NumberFormat.Style.SHORT);
System.out.println(cnf.format(1_0000));
System.out.println(cnf.format(1_9200));
System.out.println(cnf.format(1_000_000));
System.out.println(cnf.format(1L << 30));
System.out.println(cnf.format(1L << 40));
System.out.println(cnf.format(1L << 50));
}
输出
1万
2万
100万
11亿
1兆
1126兆
3、增加项:String新增方法
3.1、String#transform(Function)
JDK-8203442引入的一个小方法,它提供的函数作为输入提供给特定的String实例,并返回该函数返回的输出。
var result = "foo".transform(input -> input + " bar");
System.out.println(result); // foo bar
// 或者
var result = "foo"
.transform(input -> input + " bar")
.transform(String::toUpperCase)
System.out.println(result); // FOO BAR
对应的源码:
public <R> R transform(Function<? super String, ? extends R> f) {
return f.apply(this);
}
传入一个函数式接口 Function,接受一个值,返回一个值,参考:Java 8 新特性之函数式接口。
在某种情况下,该方法应该被称为map()。
举例:
private static void testTransform() {
System.out.println("======test java 12 transform======");
List<String> list1 = List.of("Java", " Python", " C++ ");
List<String> list2 = new ArrayList<>();
list1.forEach(element -> list2.add(element.transform(String::strip) .transform(String::toUpperCase)
.transform((e) -> "Hi," + e))
);
list2.forEach(System.out::println);
}
结果输出:
======test java 12 transform======
Hi,JAVA
Hi,PYTHON
Hi,C++
示例是对一个字符串连续转换了三遍,代码很简单。如果使用Java 8的Stream特性,可以如下实现:
private static void testTransform1() {
System.out.println("======test before java 12 ======");
List<String> list1 = List.of("Java ", " Python", " C++ ");
Stream<String> stringStream = list1.stream().map(element ->
element.strip()).map(String::toUpperCase).map(element -> "Hello," + element); List<String> list2 = stringStream.collect(Collectors.toList());
list2.forEach(System.out::println);
}
3.2、String#indent
该方法允许我们调整String实例的缩进。
举例:
private static void testIndent() {
System.out.println("======test java 12 indent======");
String result = "Java\n Python\nC++".indent(3);
System.out.println(result);
}
结果输出:
======test java 12 indent======
Java
Python
C++
换行符 \n 后向前缩进 n 个空格,为 0 或负数不缩进。
以下是 indent 的核心源码:
public String indent(int n) {
if (isEmpty()) {
return "";
}
Stream<String> stream = lines();
if (n > 0) {
final String spaces = " ".repeat(n);
stream = stream.map(s -> spaces + s);
} else if (n == Integer.MIN_VALUE) {
stream = stream.map(s -> s.stripLeading());
} else if (n < 0) {
stream = stream.map(s -> s.substring(Math.min(-n,
s.indexOfNonWhitespace())));
}
return stream.collect(Collectors.joining("\n", "", "\n"));
}
其实就是调用了 lines() 方法来创建一个 Stream ,然后再往前拼接指定数量的空格。
4、新增项:Files新增mismatch方法
@Test
public void testFilesMismatch() throws IOException {
FileWriter fileWriter = new FileWriter("tmp\\a.txt");
fileWriter.write("a");
fileWriter.write("b");
fileWriter.write("c");
fileWriter.close();
FileWriter fileWriterB = new FileWriter("tmp\\b.txt");
fileWriterB.write("a");
fileWriterB.write("1");
fileWriterB.write("c");
fileWriterB.close();
System.out.println(Files.mismatch(Path.of("tmp/a.txt"),Path.of("tmp/b.txt")));
}
5、新增项:其他
- Collectors新增teeing方法用于聚合两个downstream的结果
- CompletionStage新增exceptionallyAsync、exceptionallyComposeAsync方法,允许方法体在异步线程执 行,同时新增了exceptionallyCompose方法支持在exceptionally的时候构建新的CompletionStage。
- ZGC: Concurrent Class Unloading,ZGC在JDK11的时候还不支持class unloading ,JDK12对ZGC支持了Concurrent Class Unloading,默认是开启,使用-XX:-ClassUnloading可以禁用
- 新增-XX:+ExtensiveErrorReports,-XX:+ExtensiveErrorReports可以用于在jvm crash的时候收集更多的报告信息到hs_err.log文件中, product builds中默认是关闭的,要开启的话,需要自己添加-XX:+ExtensiveErrorReports参数新增安全相关的改进
- 新增安全相关的改进,支持java.security.manager系统属性,当设置为disallow的时候,则不使用SecurityManager以提升性能,如果此时调用System.setSecurityManager则会抛出UnsupportedOperationExceptionkeytool新增- groupname选项允许在生成key pair的时候指定一个named group新增PKCS12 KeyStore配置属性用于自 定义PKCS12 keystores的生成Java Flight Recorder新增了security-related的event支持ChaCha20 and Poly1305 TLS Cipher Suites
6、移除项
- 移除com.sun.awt.SecurityWarnin ;
- 移除FileInputStream、 FileOutputStream、- Java.util.ZipFile/Inflator/Deflator的finalize方法;
- 移除GTE CyberTrust Global Root;
- 移除javac的-source, -target对6及1.6的支持,同时移除–release选项;
7、废弃项
- 废弃的API列表见deprecated-list
- 废弃-XX:+/-MonitorInUseLists选项
- 废弃Default Keytool的-keyalg值
8、开发者如何看待 Java 12

此外,不少开发者对 Raw String Literals 特性情有独钟,该特性类似于 JavaScript ES6 语法中的模板字符串,使用它 基本可以告别丑陋的字符串拼接。特性详见:
http://openjdk.java.net/jeps/326
该特性原计划于 JDK 12 发布,可惜最后还是被取消了,详见:
http://mail.openjdk.java.net/pipermail/jdk-dev/2018-December/002402.html
可能是因为业界呼声太高,最近委员会又把这个特性拿出来重新讨论了:
https://mail.openjdk.java.net/pipermail/amber-spec-experts/2019-January/000931.html