Covariate Shift 是迁移学习下面的一个子研究领域, 对它的研究最早起源于统计学领域的一篇文章 “Improving predictive inference under covariate shift by weighting the log-likelihood function”. 本文将从机器学习的角度来解读这篇原始文章[1], 并着重提取那些比较适用于机器学习领域的要点. 因为Covariate Shift 目前还没有比较合适的中文翻译(有文献翻译成协方差转变, 但个人认为这不是很恰当), 故下文仍然使用这个英语表述.
1 Covariate Shift
Covariate Shift 定义:设源域(source domain)和目标域(target domain)的输入空间均为X, 输出空间均为Y. 源域的边际分布



2 文献[1]的动机
文献[1]的出现是为了解决错定模型(model misspecification)和Covariate Shift 共同发生的情形下使用极大似然估计(Maximum Likelihood Estimation, MLE)法估计参数所带来的问题.
在机器学习中, 一定是先假设数据是由潜在的模型产生, 这样学习才有意义. 从概率的视角, 我们会对条件分布P(y|x) 进行建模:(1)假设对x进行标记的概率模型P(y|x)来自某个模型空间




只要我们假定的模型空间F能够把真实的概率模型





源域:

由(I)和(II)产生源域的一个包含1000个训练样例的集合





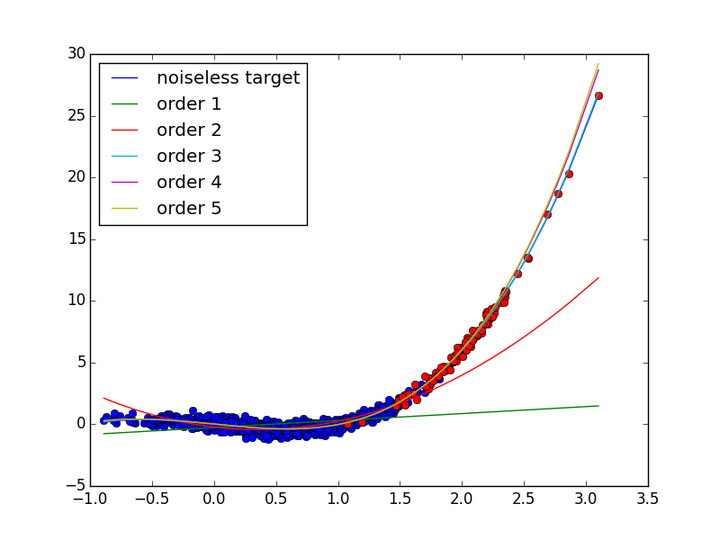
_ 图1 不同阶数多项式回归对比图
如果我们选择的模型空间F没能把潜在的真实的模型覆盖住, 那么我们实际上就是用了一个错定的模型(model misspecification), 这个时候, 如果

事实上, Covariate Shift 与错定模型这个两个事件的发生与否在很大程度上影响着我们对真实模型的学习. 具体地, 可以考虑表1中的4种情况:
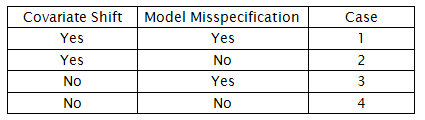
_ 表1 Covariate Shift 与错定模型的所有可能组合
文献[1]要解决的是case 1 情形下的参数估计问题. 对于case 2和case 4, 由前面的论述和多项式回归的实验可以证明, 这2种情况下使用极大似然估计法去估计模型参数依然是没有问题的. Case 3只涉及到模型空间的选择问题, 这是关于先验知识或归纳偏好的问题, 文献[1]没有去讨论这种情况.
3 文献[1]的结果(主要贡献)
在case 1 发生的情形下, 已经不能直接使用极大似然估计法进行参数估计, 而应该使用加权的极大似然估计法. 具体地, 当我们选定模型空间F之后, 模型的参数应该这样估计:

而且权重w(x)与模型空间F的选择可以通过一个准则——AIC信息准则的变种:

在选定了权重函数w(x)以及模型空间F之后, 只利用源域的标记数据, 就可以对(V)进行计算. 假设有若干个权重函数以及若干个模型空间, 我们最后选择那个
![w(x)=(\frac{P_{T}(x)}{P_{S}(x)})^\lambda, \lambda \in [0,1]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvODJlNzk5ZjhhYTFmMTUxNTMyNGY0MDg0OGMyZWJmMTEucG5n)


4 文献[1]的过程(文章脉络)
文献[1]的一条主体线索是:(1)
(1)学习场景设定: Covariate Shift和错定模型同时发生. 
_

(2)用一个简单的线性回归例子, 说明使用极大似然估计法学习模型参数的危害
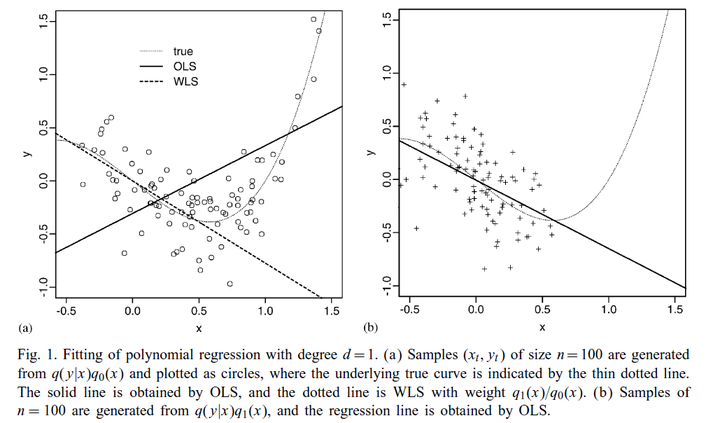
_
(3)借助importance sampling identity,大数定律说明学习模型的参数要使用加权极大似然估计法
考虑log损失, 由importance sampling identity:

根据大数定律:

所以要学得一个在目标域期望损失小的模型, 需要在源域训练一个加权经验最小化的模型:

从(VI)到(VII)的过程中应用了大数定律, 这决定了(VIII)只能适用于

这一部分论述得比较详细, 因为机器学习领域的Covairate Shift 工作引用最多的就是这篇文献的这一部分的内容.
_
(4)考虑加权极大似然估计法所学模型的平均泛化误差, 通过平均泛化误差的展开式研究权重w(x)应该如何选取(肯定是选择w(x)使得模型的平均泛化误差最小)
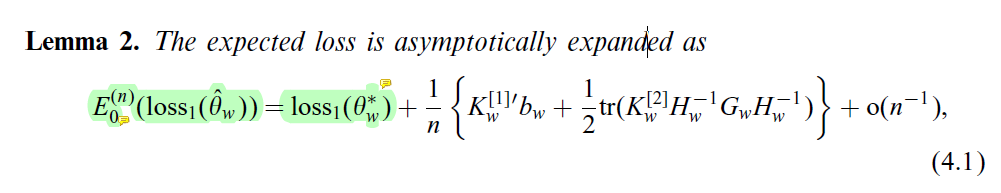
_
(5) 由于(4)中的计算需要知道真实模型q(y|x)(4.1等式右端第一项的计算需要), 而真实模型q(y|x)是不知道的, 导致无法计算所学模型的平均泛化误差. 于是文献[1]推导出一个新的信息准则

该信息准则是模型平均泛化误差(4.1)的近似无偏估计, 可以作为选权重函数w(x)以及模型空间F的依据. 阐述了新提出的信息准则与AIC信息准则的联系.
_
(6)针对提出的信息准则

_
(7)实验验证当源域数据很多时, (5.1)可以近似代替(4.1), 即验证了
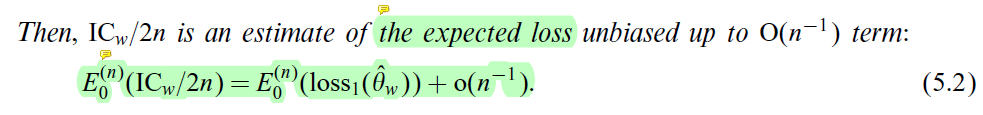

用实验进一步验证了信息准则
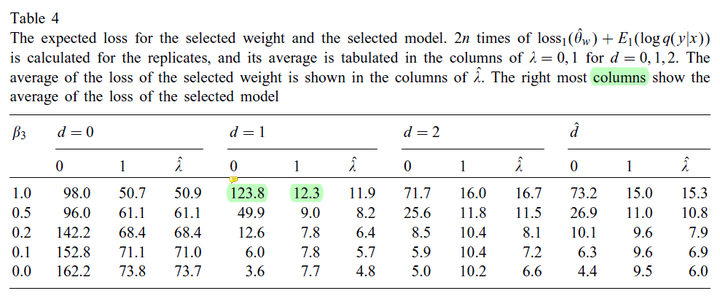
_
(8)说明了几点: 1,
参考文献
[1] H. Shimodaira, “Improving predictive inference under covariate shift by weighting the log-likelihood function” ,Journal of Statistical Planning and Inference, vol. 90, pp. 227–244, 2000.
附录
图1 不同阶数多项式回归对比图的python程序
import random
import numpy as np
import matplotlib.pyplot as plt
import numpy.linalg as linalg
from sklearn.linear_model import LinearRegression
print 'standard weights (w0,w1,w2,w3) = (0,-1,0,1)'
n = 1000
X_src = np.empty(n)
Y_src = np.empty(n)
X_tgt = np.empty(n / 10)
Y_tgt = np.empty(n / 10)
for i in range(n):
X_src[i] = random.gauss(0.5,0.5)
Y_src[i] = -X_src[i] + np.power(X_src[i],3) + random.gauss(0.0,0.3)
for i in range(n / 10):
X_tgt[i] = random.gauss(2.0,0.3)
Y_tgt[i] = -X_tgt[i] + np.power(X_tgt[i],3) + random.gauss(0.0,0.3)
reg = LinearRegression()
reg.fit([[v] for v in X_src],Y_src)
W1 = reg.intercept_,reg.coef_[0]
print 'W1 :',W1
reg = LinearRegression()
reg.fit([[v,v ** 2] for v in X_src],Y_src)
W2 = reg.intercept_,reg.coef_[0],reg.coef_[1]
print 'W2 :',W2
reg = LinearRegression()
reg.fit([[v,v ** 2,v ** 3] for v in X_src],Y_src)
W3 = reg.intercept_,reg.coef_[0],reg.coef_[1],reg.coef_[2]
print 'W3 :',W3
reg = LinearRegression()
reg.fit([[v,v ** 2,v ** 3,v **4] for v in X_src],Y_src)
W4 = reg.intercept_,reg.coef_[0],reg.coef_[1],reg.coef_[2],reg.coef_[3]
print 'W4 :',W4
reg = LinearRegression()
reg.fit([[v,v ** 2,v ** 3,v **4,v ** 5] for v in X_src],Y_src)
W5 = reg.intercept_,reg.coef_[0],reg.coef_[1],reg.coef_[2],reg.coef_[3],reg.coef_[4]
print 'W5 :',W5
X_plot = sorted(np.concatenate((X_src,X_tgt)))
plt.figure()
plt.plot(X_plot,[-i + np.power(i,3) for i in X_plot],label = 'noiseless target')
plt.plot(X_src,Y_src,'bo')
plt.plot(X_tgt,Y_tgt,'ro')
plt.plot(X_plot,[W1[0] + i * W1[1] for i in X_plot],label = 'order 1')
plt.plot(X_plot,[W2[0] + i * W2[1] + (i ** 2) * W2[2] for i in X_plot],label = 'order 2')
plt.plot(X_plot,[W3[0] + i * W3[1] + (i ** 2) * W3[2] + \
(i ** 3) * W3[3] for i in X_plot],label = 'order 3')
plt.plot(X_plot,[W4[0] + i * W4[1] + (i ** 2) * W4[2] + \
(i ** 3) * W4[3] + (i ** 4) * W4[4] for i in X_plot],label = 'order 4')
plt.plot(X_plot,[W5[0] + i * W5[1] + (i ** 2) * W5[2] + \
(i ** 3) * W5[3] + (i ** 4) * W5[4] + \
(i ** 5) * W5[5] for i in X_plot],label = 'order 5')
plt.legend(loc="best")
plt.show()
output:
standard weights (w0,w1,w2,w3) = (0,-1,0,1)
W1 : (-0.29578843795357851, 0.60680756922840728)
W2 : (-0.24137839883077888, -1.118596466841606, 1.6175250868307449)
W3 : (0.014386018101656139, -0.97736257687681483, -0.094743118854225233, 1.0393479036121429)
W4 : (0.015342798845553927, -0.98215866187620304, -0.097515221286365028, 1.0522118734968753, -0.0057473254710901367)
W5 : (0.01562503337882579, -0.97914406740220483, -0.10422149623464838, 1.0477376702208572, 0.005522699171098433, -0.003975707670178269)
编辑于 2017-04-17