以后再定
- 一、概念相关
- 二、编程相关
- 2.1 、clion添加注释
- 2.2、 vector元素累加
- 2.3 、终止循环的三种方式
- 2.3、 File size limit (clion)
- 2.4、 形参指针在函数运行时有变化,调用该函数后指针却不变
- 2.5、 迭代器和普通循环以及(++i和i++)
- 2.6 、C++ win下Clion生成动态链接库
- 2.7、 C++中main函数接收不同类型参数后直接运行
- 2.8、查看c++版本
- 2.9、unordered_map和unordered_set输出是无序的,map会自动排序(unordered-map不会)
- 2.10、 除法向上取整
- 2.11、删除vector中指定元素
- 2.12、数组、一维/二维vector初始化
- 2.13、 判断string、vector/set/map中是否存在指定元素(返回索引值)
- 2.14、 字符形式的数字互转整形数字(char‘1’和int 1互转)
一、概念相关
1.1、include< >和#include“ ”的区别
1)引用的头文件不同
#include< >引用的是编译器的类库路径里面的头文件。
#include“ ”引用的是你程序目录的相对路径中的头文件。
2)用法不同
#include< >用来包含标准头文件(例如stdio.h或stdlib.h).
#include“ ”用来包含非标准头文件。
3)调用文件的顺序不同
#include< >编译程序会先到标准函数库中调用文件。
#include“ ”编译程序会先从当前目录中调用文件。
4)预处理程序的指示不同
#include< >指示预处理程序到预定义的缺省路径下寻找文件。
#include“ ”指示预处理程序先到当前目录下寻找文件,再到预定义的缺省路径下寻找文件。
1.2、按值传递、指针和引用使用场景
对于函数,只使用传递过来的值,而不对值进行修改。
(1)如果数据对象很小,如内置数据类型或小型结构,使用按值传递。
(2)如果数据对象是数组,则使用指向const的指针。
(3)如果数据对象是较大的结构,则使用const指针或者const引用,以提高程序的效率。
(4)如果数据对象是类对象,则使用const引用。因此,传递类对象参数的标准方式是按引用传递。
对于函数,需要修改传递过来的值。
(1)如果数据对象是内置数据类型,则使用指针。
(2)如果数据对象是数组,则只能使用指针。
(3)如果数据对象是结构。则使用指针或者引用。
(4)如果数据对象是类对象,则使用引用。
总的来说,指针和引用效率高于按值传递。
经典例子,交换两个值的函数swap(int a, int b),分别通过按值传递、指针和引用实现:
# include<iostream>
using namespace std;
void Swapr(int &a, int &b);
void Swapp(int *pa, int *pb);
Void Swapv(int a, int b);
int main(void)
{
Int wallet1 = 300;
Int wallet2 = 350;
Cout << “wallet1 : ”<< wallet1 << endl; //300
Cout << “wallet2 : ”<<wallet2 << endl; //350
Cout << “Using & to swap contents” << endl;
Swapr(wallet1, wallet2);
Cout << “wallet1 : ”<< wallet1 << endl; //350
Cout << “wallet2 : ”<<wallet2 << endl; //300
Cout << “Using * to swap contents” << endl;
Swapp(&wallet1, &wallet2);
Cout << “wallet1 : ”<< wallet1 << endl; //300
Cout << “wallet2 : ”<<wallet2 << endl; //350
Cout << “Using value to swap contents” << endl;
Swapv(wallet1, wallet2);
Cout << “wallet1 : ”<< wallet1 << endl; //300
Cout << “wallet2 : ”<<wallet2 << endl; //350
Return 0;
}
对应三个函数实现:
//引用
Void Swapr(int &a, int &b)
{
Int temp;
Temp = a;
A = b;
B = temp;
}
//指针
Void Swapp(int *pa, int *pb)
{
Int temp;
Temp = *pa;
*pA = *pb;
*B = temp;
}
//按值传递
Void Swapv(int a, int b)
{
Int temp;
Temp = a;
A = b;
B = temp;
}
上述按值传递无法实现两个数的交换。
1.3、引用和取地址
引用:所谓引用就是为对象起一个别名。例如变量 b = &a,b就是a的一个引用。对b的任何操作等同于对a的操作,也就是说,如果你改变了b的值,同时a的值也会发生改变。b就是a的另外一个名字,他们实质是同一个变量。比如1.2中在swap(int a, int b),如果将两个值带进去,发生交换的只是形参a和b,因为函数结束的时候这两个参数的生命周期结束了,换句话说,实参a和b的值并未发生交换。而swap(int &a,int &b)则不同,它的参数是a和b的引用,也就是说函数中的a和b就是带入的实参,当函数中的a和b发生变化时,被引用的值在同时也发生了变化,而不会受到函数声明周期的影响。
取地址:取地址则顾名思义,就是取得对象的地址,通过指针来操作对象,也可以达到引用的效果,它不是直接对对象进行操作,而是根据对象的地址。与引用不同的是,引用是不占用存储空间的,而如果用指针指向对象地址的时候会有自己的存储空间。比如1.2中swap(int *a, int *b), a和b是指向实参的指针,即它们有实参的地址,而我们知道a和b的地址是没有改变的,那么根据它们的地址就可以操作它们的值,也就不用考虑函数生命周期了。
二、编程相关
2.1 、clion添加注释
单行注释:光标定位到指定代码行+Ctrl + /
多行注释:光标选定多行代码+Ctrl + shift+ /
2.2、 vector元素累加
加载头文件#include <numeric>
accumulate带有三个形参:头两个形参指定要累加的元素范围,第三个形参则是累加的初值。
例如:accumulate(a,a+5,0)
即计算数组中下标0到5的元素值的累加和;如果只有一个元素,则返回该元素值。
2.3 、终止循环的三种方式
1)不满足while循环条件,直接跳出循环;
2)利用break:break是跳出整个循环,直接执行跳出循环后的下面的代码;
3)利用continue:continue是终止当次循环,不执行下面的代码,直接进入下一次循环
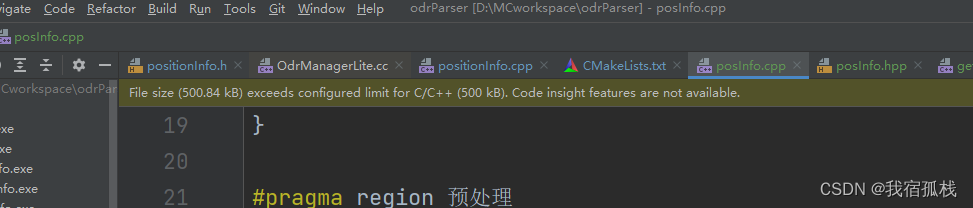
2.3、 File size limit (clion)
2.4、 形参指针在函数运行时有变化,调用该函数后指针却不变
如下代码:
bool getPosInfo::getPreSucRoadWithoutJunc(RoadHeader *road, int preSucFlage)
{
if(preSucFlage && road->getPredecessor())
{
road = road->getPredecessor();
return 1;
}
if((!preSucFlage) && road->getSuccessor()){
road = road->getSuccessor();
return 1;
}
return 0;
}
博主的初衷是让形参road保存满足结果的road,但在实际操作时,调用该函数后的road还是它的形参本身而非满足条件时更新的road->getPredecessor(),此时需要对形参指针加以修改,有两种方法可解决双指针或者加引用,博主是加的引用较之更为简单一些,
修改后代码如下:
bool getPosInfo::getPreSucRoadWithoutJunc(RoadHeader *&road, int preSucFlage)
{
if(preSucFlage && road->getPredecessor())
{
road = road->getPredecessor();
return 1;
}
if((!preSucFlage) && road->getSuccessor()){
road = road->getSuccessor();
return 1;
}
return 0;
}
只需要将RoadHeader *road改为RoadHeader *&road即可。
2.5、 迭代器和普通循环以及(++i和i++)
首先说下++i和i++
for循环时:
for (int i = 0;i < 10;i++){
...
}
for (int i = 0;i <10;++i){
...
}
两个的实现功能一样,区别在于效率上,++i的效率高于i++。因为for循环中 i++ 在处理时,i++实际为i = i+1,执行时先创建临时变量保存 i 值,然后再+1,由于要创建临时变量并保存i的值,所以需要占用内存,使用完后释放内存,一个是造成资源占用,一个是数据量大时,造成程序性能低;而++i不需要,没有这个过程,所以++i的性能高于i++。
2.6 、C++ win下Clion生成动态链接库
在cmakeList.txt中添加语句:
add_library(libOdr SHARED getOdr.cpp)
target_link_libraries(libOdr ${ODRMANGER_LIB}/libproj.dll.a ${ODRMANGER_LIB}/libODrive.1.5.5.a)
上述语句中,libOdr是指定生成的库文件的名字,注意其生成的时候会自动添加lib关键字所以实际上生成的库文件全名是liblibOdr.dll,如图所示:
SHARED 表示生成动态链接库也就是后缀名为.dll的库文件;若需要生成静态链接库关键字改为STATIC即可。
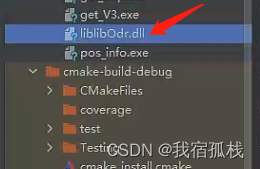
getOdr.cpp这是需要生成库文件的.cpp文件,比如博主需要封装的getInfo()方法就是在.cpp文件中。
这条语句中,后边两个非必须项,是博主运行代码需要的链接库,如果.cpp中代码运行不需要链接库则无需添加,只需要target_link_libraries(libOdr) 即可。
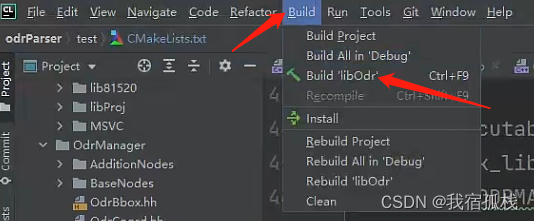
上述文件编辑好后,clion可以直接ctrl+F9进行编译,即可在bin目录下看到生成的库文件;也可以
手动点击build进行编译生成库文件。
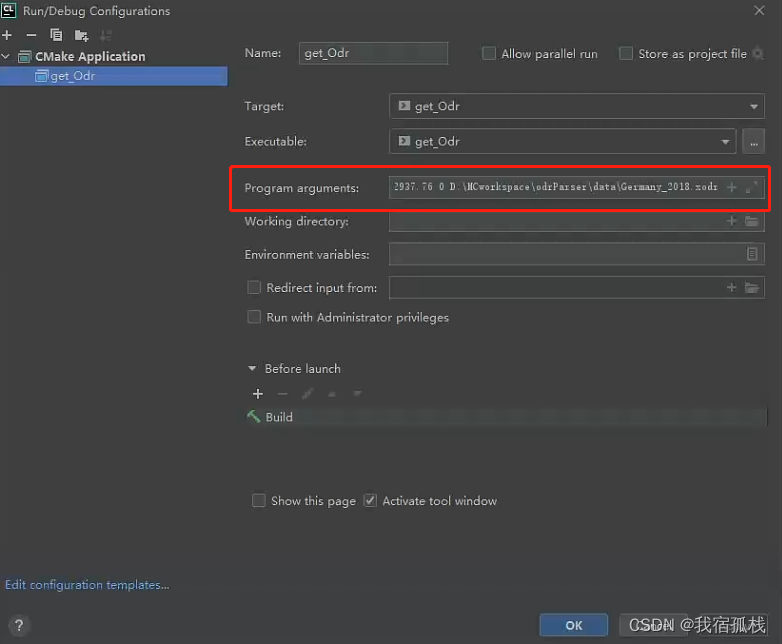
2.7、 C++中main函数接收不同类型参数后直接运行
比如我需要直接在终端输入:
**/**.exe 0 5915.00 -2937.76 0 D:\MCworkspace\odrParser\data\Germany_2018.xodr
/.exe是指定的.cpp文件生成的.exe文件,直接将后续参数接收后运行该.exe文件;或者说理解为将参数接收后传递给.exe中的函数直接运行。
比如
int main(int argc, char* argv[]) {
//string xodrPath = "..\\data\\Germany_2018.xodr";
//Point startPoint(5915.00, -2937.76, 0); //roadId:40,laneId:-1,s: 20.1629
//Point endPoint(6031.85, -3539.57, 0); //roadId:22,laneId:-2
OpenDrive::OdrManager manager;
string xodrPath;
double x, y, z;
int flag;
char ** temp = argv; /* 保留argv */
vector<char *> is;
is.reserve(5);
while( *temp != NULL ){
is.push_back(*temp);
++temp;
}
//flag = atoi(is[1]); //也可。但double不可以,只能用atof,float型
flag = stoi(is[1]);
x = stod(is[2]);
y = stod(is[3]);
z = stod(is[4]);
vector<double> xyz = {x, y, z};
xodrPath = is[5];
cout << flag << "; "<< x << ";" << y << ";"<< z << ";" << xodrPath << endl;
vector<double> v = getInfo(flag, xyz, xodrPath);
return 0;
}
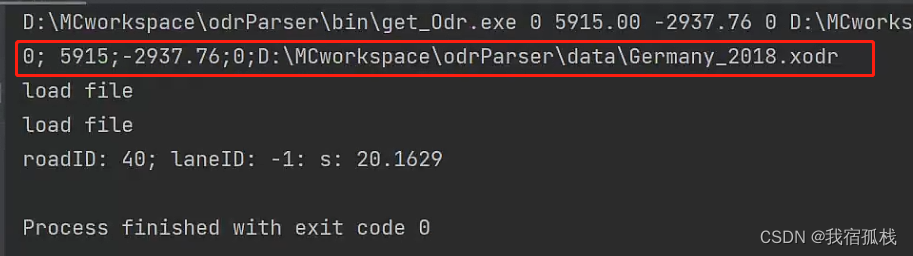
上述代码实现的便是将输入的0 5915.00 -2937.76 0 D:\MCworkspace\odrParser\data\Germany_2018.xodr参数分别读取并赋值给flag,x,y,z以及xodrPath,再将其传递给函数getInfo()。
注意int main(int argc, char* argv[])中argv接收的都是char*类型的数据,int可以使用stoi()方法直接进行转换,double使用 stod()类型进行转换,string类型可以直接使用。
如图红色框即为对接收后的数据进行分别赋值后的输出结果。
这里目录地址为绝对路径,也可以使用相对路径:
0 5915.00 -2937.76 0 ..\\data\\Germany_2018.xodr
效果是一样。
运行的时候可以在下图所示地方输入运行参数:
2.8、查看c++版本
代码语句:std::cout << __cplusplus << std::endl;
#include <iostream>
int main()
{
std::cout << "Hello World!\n";
std::cout << __cplusplus << std::endl;
return 0;
}
输出:

C++各版本对照表:
g++ main.cpp
199711
g++ -std=c++11 main.cpp
201103
g++ -std=c++14 main.cpp
201402
g++ -std=c++17 main.cpp
201500
g++ --version
5.4.0
2.9、unordered_map和unordered_set输出是无序的,map会自动排序(unordered-map不会)
无序的map、set,称为unordered_map、 unordered_set。 采用迭代器遍历出来的元素是无序的, 这是因此底层实现数据结构为哈希表。
1、哈希表不同于红黑树, 哈希表它的查找效率是o(1)、一个常数的效率。
虽然红黑树是o(logn), 很高的效率, 但不及它。
2、哈希表遍历的元素是无序的, 红黑树有序的。 这也决定他们实现的容器是何性质。
参考博文哈希表-map set无序
map 和 unordered_map 都是键值对的容器。map 的底层通过树实现,且会自动为容器内元素按key进行升序排序。unordered_map 的底层通过哈希表实现,并不会自动排序。当创建一个不需要排序的字典时应使用 unordered_map,因为哈希表对元素的查找更快。
结论:需要排序的字典用 map,不需要排序的字典用unordered_map。
2.10、 除法向上取整
例如5/2,想要得到3。
ceil(5/2) = 2;
ceil(5.0/2) = 3;
ceil()中的参数需要为double类型,所以除数和被除数需要至少一个为double类型。其中,ceil()函数需要引入头文件。
2.11、删除vector中指定元素
1、先用swap把要删除的元素和vector里最后一个元素交换位置,然后把最后一个元素pop_back
std::swap(*it, observers_.back());
observers_.pop_back();
2、先用find查找元素,然后用erase删除元素
Iterator it = std::find(observers_.begin(), observers_.end(), x);
observers_.erase(it);
1的效率高,2删除元素后需要把后面的元素依次向前移动,但有时会要求不能改变vector中元素顺序,此时只能使用2。
2.12、数组、一维/二维vector初始化
数组
博主直接用`int array[3]初始化的数组,其中数值为随机数。
//初值为{}中所赋的值,{}索引值以外的默认为
int array[3] = {};
int array[3] = {0}; //{0,0,0}
int array[3] = {3}; //{3,0,0}
//通过关键字new
int *temp = new int[100];//未初始化值
int *temp = new int[100]();//初始化所有值为0
delete []temp;
vector
一维
-
vector < int > v;
这时候v的size为0,如果直接进行访问 v[i] 会报错。
这里可以使用v.resize(n),或者v.resize(n, m)来初始化
前者是使用n个0来初始化,后者是使用n个m来初始化。
也可以直接vector <int> v(10); -
vector < int > v = {1,2,3,4,5};
可以使用初始化数组的方式来初始化vector,如例子所示,此时v.size() == 5
如果这时候使用v.resize(3),将会丢弃最后的4和5。
注意,可能之前的编译器不支持这个初始化。 -
vector < int > v(n); vector < int > v(n,m);
类似于resize的用法 -
vector < int > v(v0);
使用另外一个数组来初始化v,注意,这里的v0也必须是vector
也可以写作vector < int > v = v0;
二维
1.vector < vector < int > > v;
和一维数组一样,这里的v的size是0。
可以先v.resize(n)来初始化一个长度为n的二维数组,
vector<unordered_set<char>> s(10);//长度为10的vector
然后使用一个for循环:
for (int i = 0; i < v.size(); i++)
v[i].resize(n);
这样v的大小就是n*n。
也可以v.resize(n, v0),使用n个一维数组来初始化一个二维数组。
这里v0可以直接使用vector(n,m)来表示,比如
vector<vector<int>> v(3, vector<int>(4,1));
3*4大小的二维数组,值全为1.
2.vector < vector < int > > v(n, v0);
这个和resize的用法一样。
3.使用指针初始化
和一维数组类似,可以使用vector指针:
vector<int> v0 = { 1,2,3,4 };
vector<vector<int>> v1(4, v0);
vector<vector<int>> v(v1.begin()+1, v1.end()-1); //此时的v是 {{1,2,3,4},{1,2,3,4}}
2.13、 判断string、vector/set/map中是否存在指定元素(返回索引值)
string
- find(value),如果存在返回value第一次出现的索引位置,不存在则返回string::npos。
string a= "abcdefghigklmn" ;
string b= "def" ;
string c= "123" ;
if (a.find(b)== string::npos ) //不存在。
cout << "not found\n" ;
else
cout << "found\n" ;
vector/set/map
find(a.begin(),a.end(),value)
如果在查找的范围内找到了返回的是value的地址,如果没找到返回的是地址a+length或a.end()。
string 中的find()函数查找第一次出现的目标字符串。如果找不到的话返回s.npos(结尾位置)。
std::vector<int> vec = {10, 20, 30, 40, 50};
int targetElement = 30;
auto itr = std::find(vec.begin(), vec.end(), targetElement);
if (itr != vec.end()) {
size_t index = std::distance(vec.begin(), itr);
std::cout << "The element is found at index: " << index << std::endl;
} else {
std::cout << "The element is not found in the vector." << std::endl;
}
count(begin,end,‘a’),其中begin指的是起始地址,end指的是结束地址,第三个参数指的是需要查找的字符’a’。
vector<int> numbers = {1, 2, 2, 3, 2, 4, 5, 2};
int value= 2;
int count = count(numbers.begin(), numbers.end(), value);
2.14、 字符形式的数字互转整形数字(char‘1’和int 1互转)
可直接通过ASCLL码值互转。
char a = '1'转为 int b = 1:
b = (a + '0');
int b = 1转化为char a = '1':
a = (b - '0');