文章目录
- Input & Output
- Fundamentals of the Analysis of Algorithm Efficiency
- For-loop
- Data Structure
- Function 函数
- Class and object
- Array and Linked List
- Debuging
- Python八股收集
Input & Output

Variables & Data types
str: a string represents a sequence of characters.
int: an integer, a whole number
float: a decimal number
bool: a boolean value is either True or False.
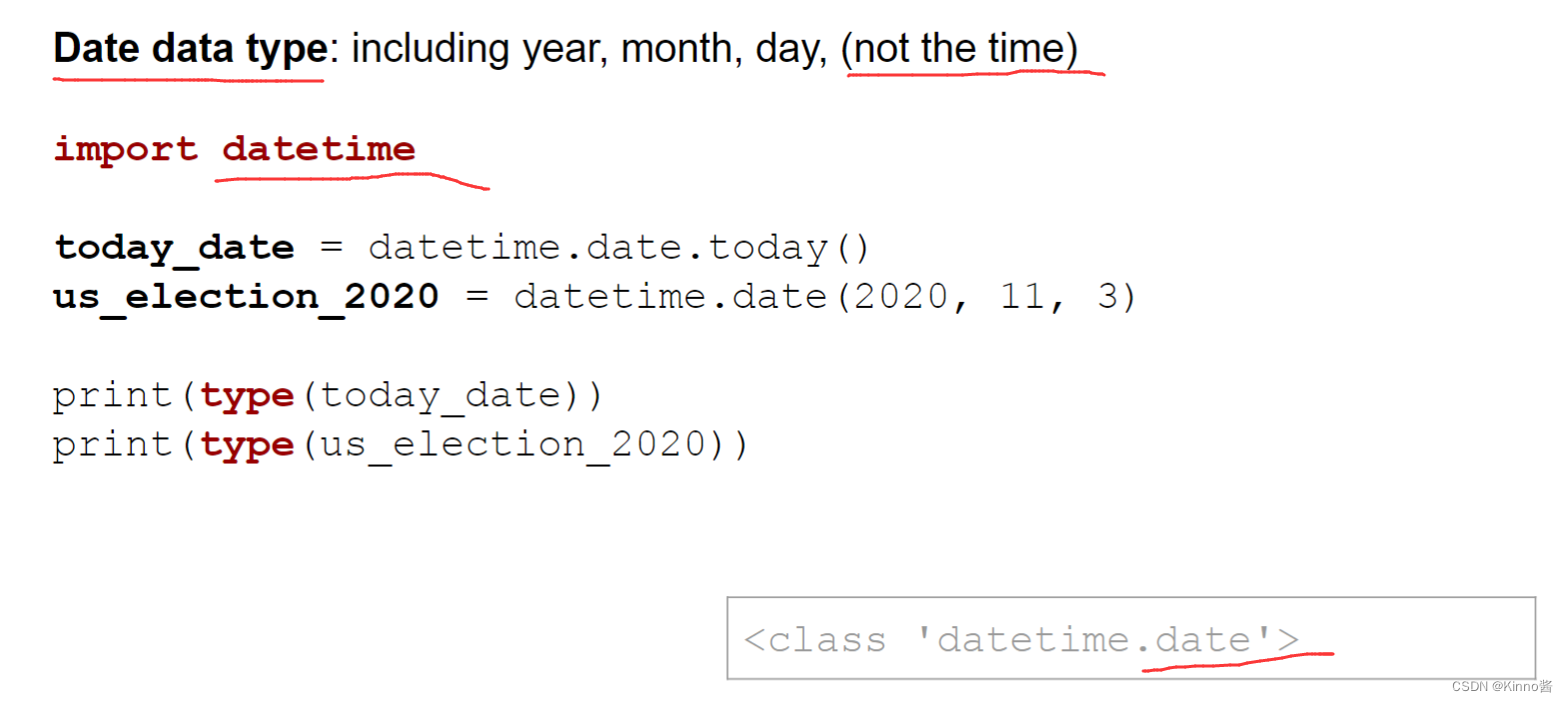
Date data type: including year, month, day, (not the time)
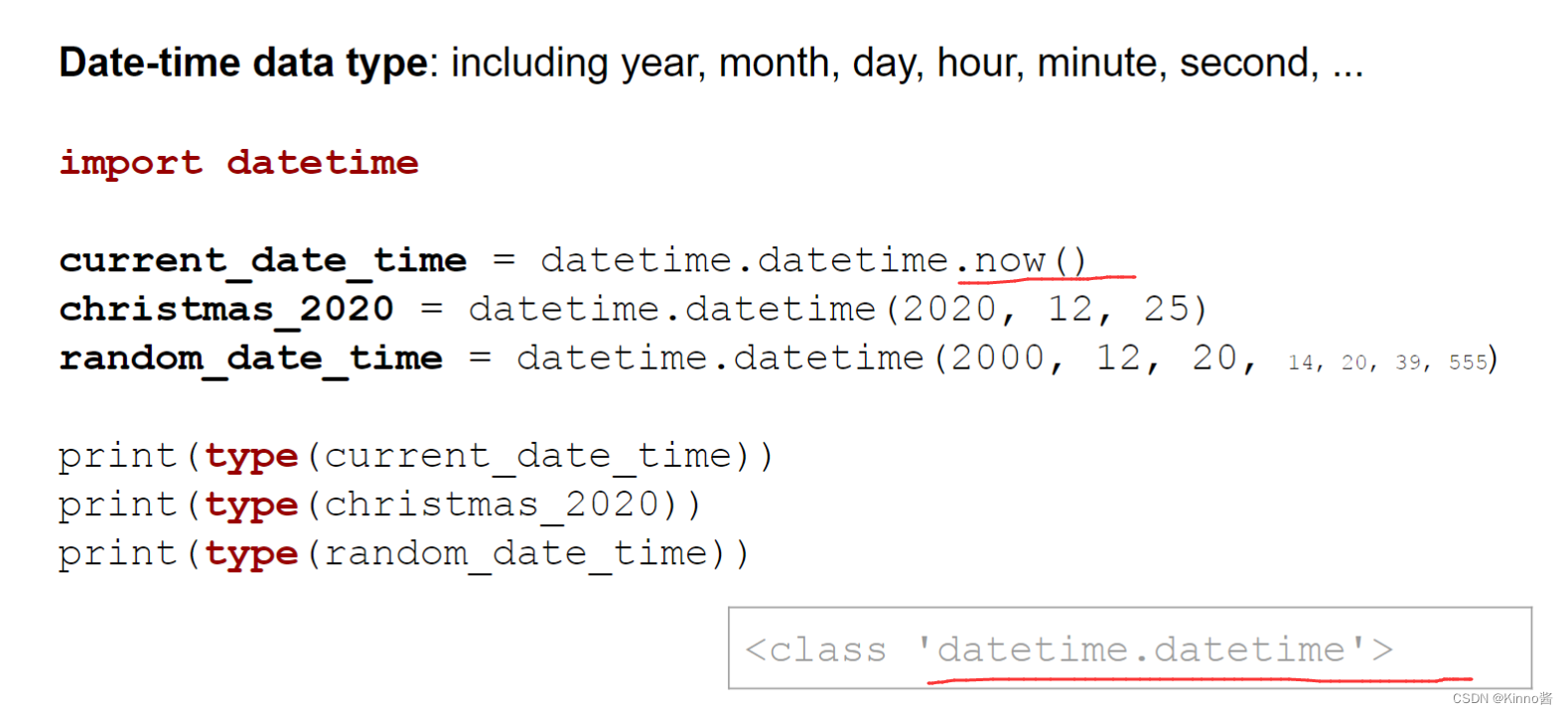
Date-time data type: including year, month, day, hour, minute, second, …
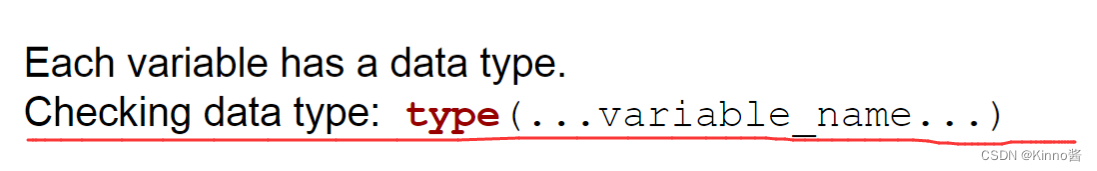


Python字符串重复(字符串乘法)

字符串和数字连接在一起print时,要强制类型转换int为str


用input()得到的用户输入,是str类型,如果要以int形式计算的话,需要强制类型转换为int

我们可以只使用一个变量user_input来节省内存

convert string type to date type
strptime

convert date to string
strftime

Multi-line code statement 换行符

在括号内,行的延续的自动的
Line continuation is automatic when the split comes while a
statement is inside parenthesis ( , brackets [ or braces {

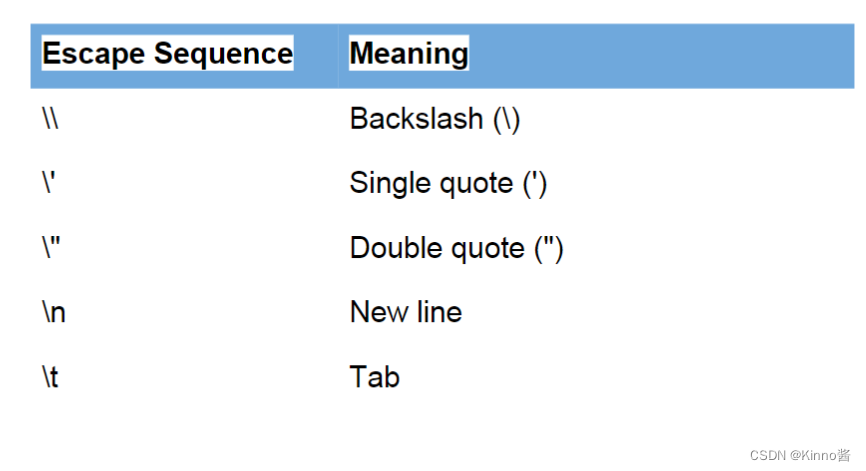
Escape sequence 转义字符



String format

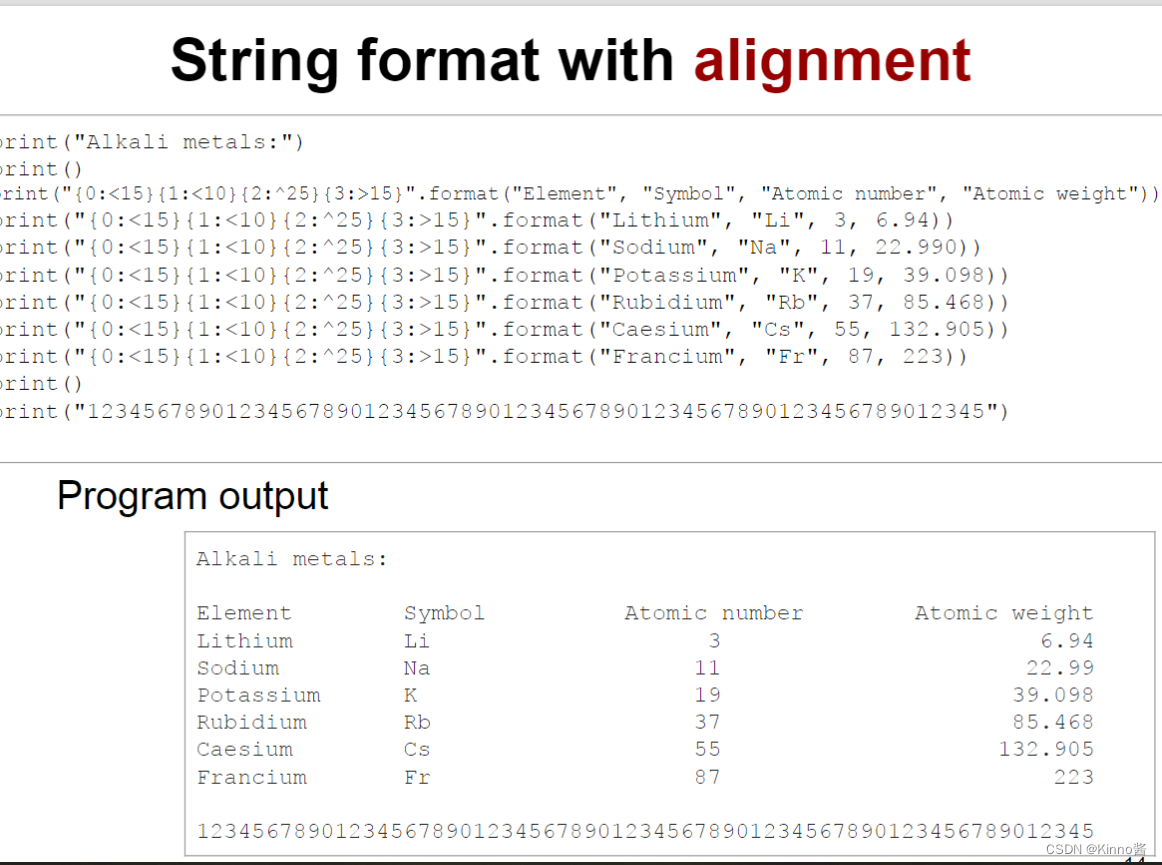
| 格式 | 意义 |
|---|---|
| <15 | left alignment, using 15 spaces |
| ^25 | center alignment, using 25 spaces |
| >15 | right alignment, using 15 spaces |
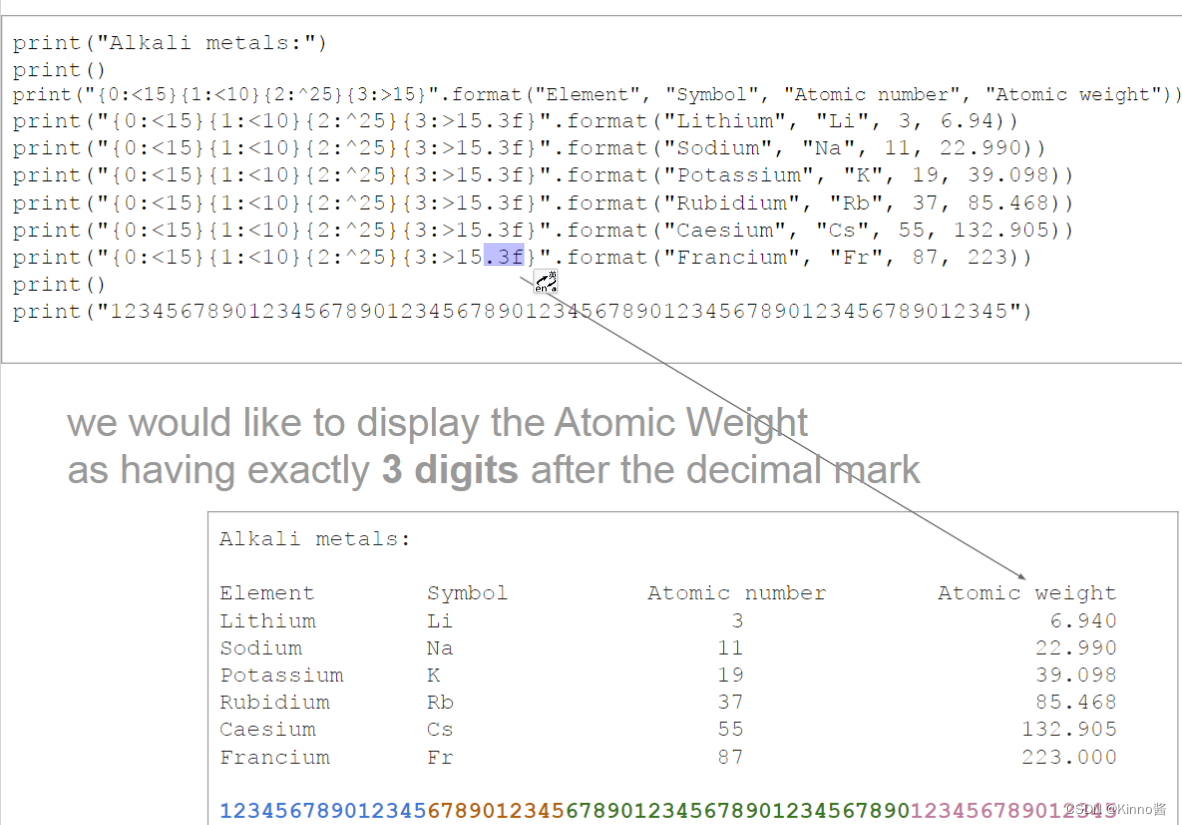
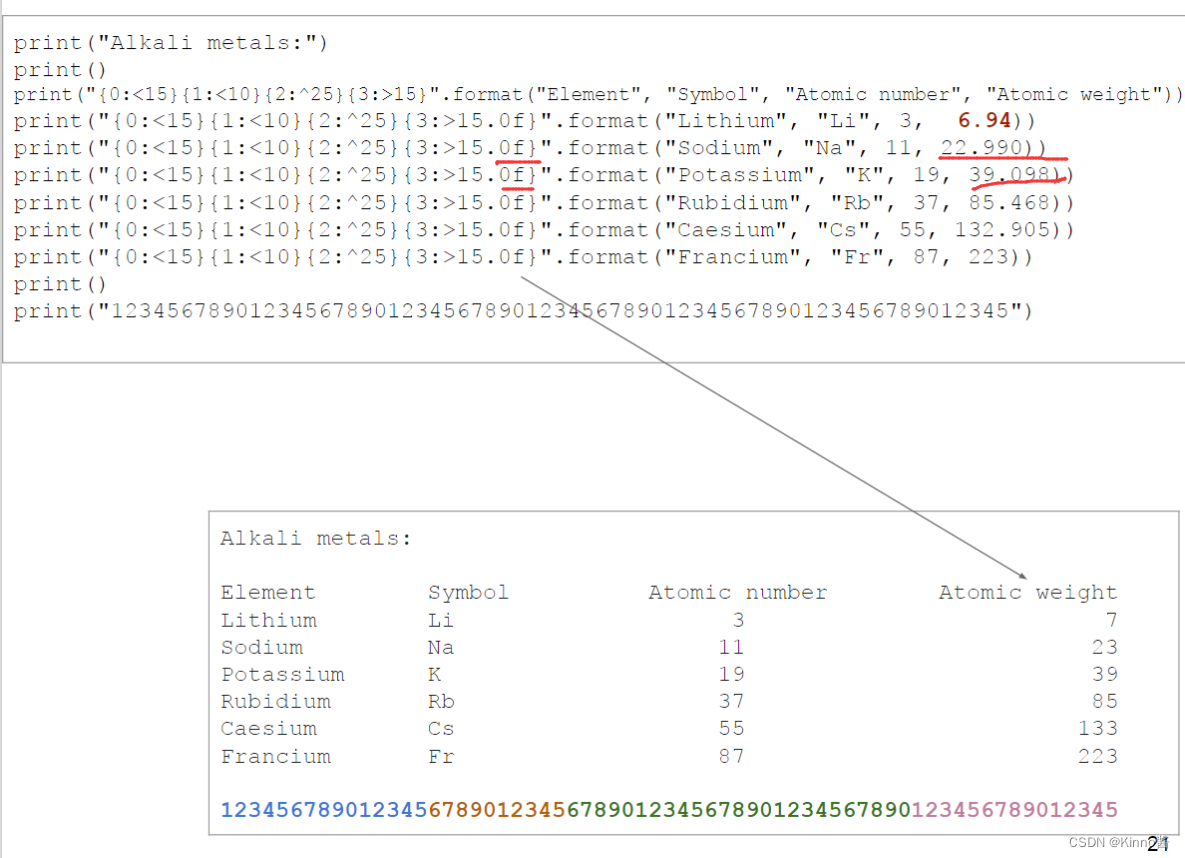
string format 中限制输入占位大小的同时小数点后位数
还可以通过这种方式实现四舍五入取整
.0f
Arithmetic operators
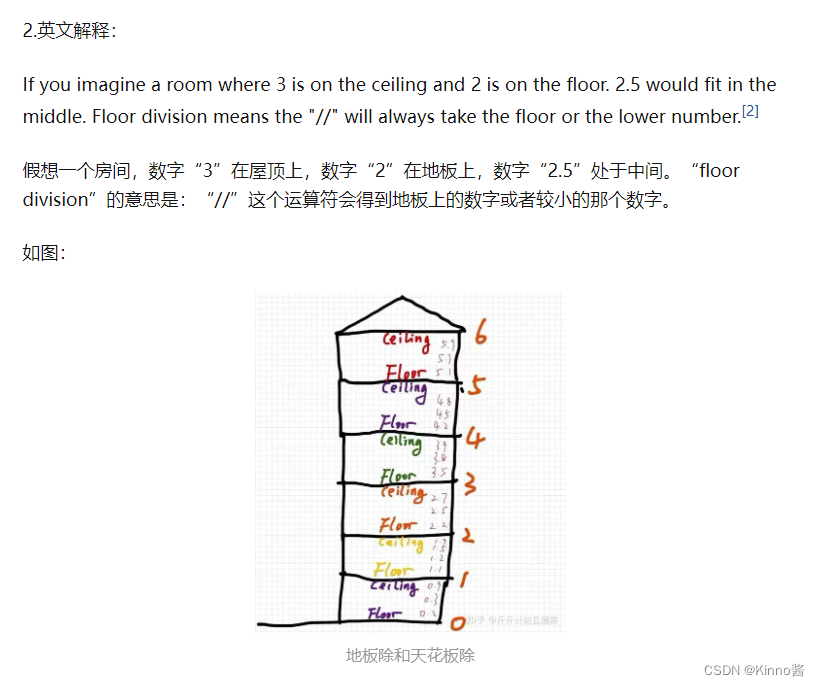
Floor division = 地板除 = 向下取整除
floor division地板除是什么意思
向下取整除,就是地板除 floor division
向上取整除,就是天花板除,ceil division

来自 https://zhuanlan.zhihu.com/p/221901326
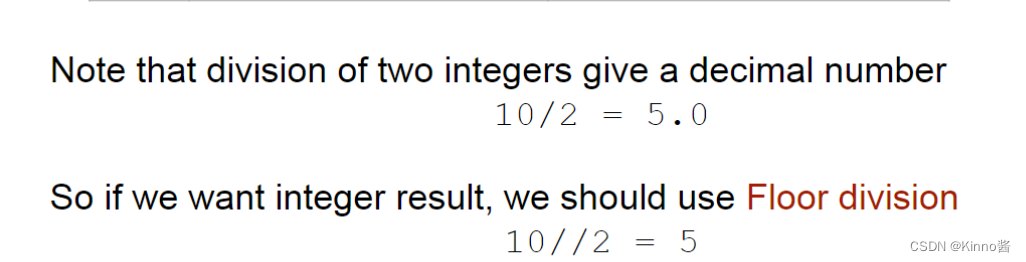

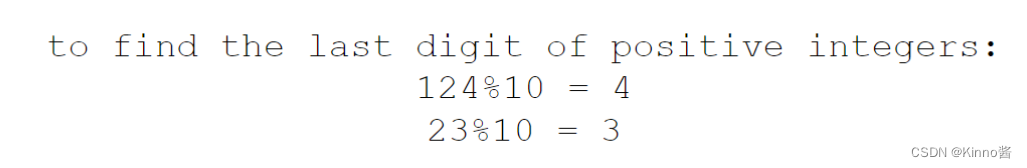
Fundamentals of the Analysis of Algorithm Efficiency
Algorithm analysis framework 算法分析框架
Analysis of algorithms means to investigate an algorithm’s efficiency with respect to resources: running time and memory space
算法分析是指研究一个算法在资源方面的效率:运行时间和内存空间。

1. Measuring Input Sizes
Efficiency is defined as a function of input size.
F(n)
2. Units for Measuring Running Time
Count the number of times an algorithm’s basic operation is executed
计算一个算法的基本操作被执行的次数
Basic operation: the operation that contributes the most to the total
running time.
例如,基本操作通常是算法最内部循环中最耗时的操作。
3. Order of growth

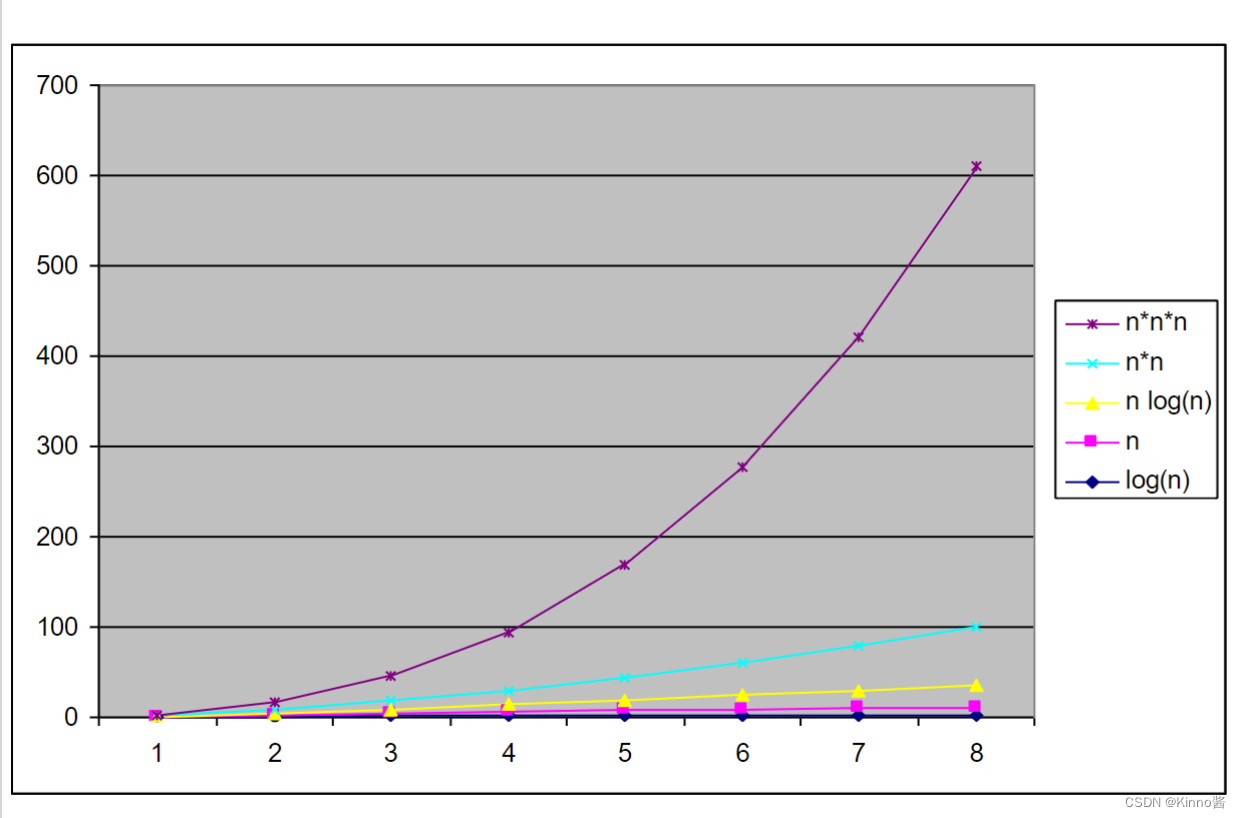
4. Worst-Case, Best-Case, and Average-Case Efficiency
==Efficiency (# of times the basic operation will be executed) ==


Average case:
Efficiency (#of times the basic operation will be executed) for a typical/random
input of size n. NOT the average of worst and best case. How to find the
average case efficiency?
平均情况。对于大小为n的典型/随机输入的效率(基本操作将被执行的次数),而不是最坏和最好情况的平均值。如何找到平均案例的效率?
Summary
算法的运行时间(空间)随着其输入大小的增加而增长的阶数为无穷大。
对于相同大小的输入,一些算法的效率可能有很大的不同

渐进式符号

no faster
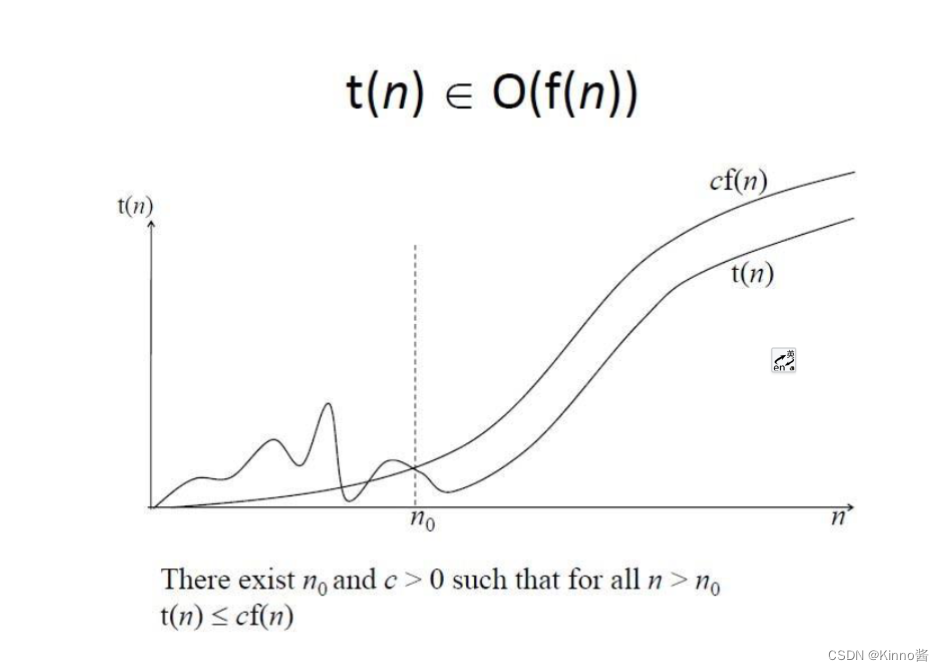

at least as fast as
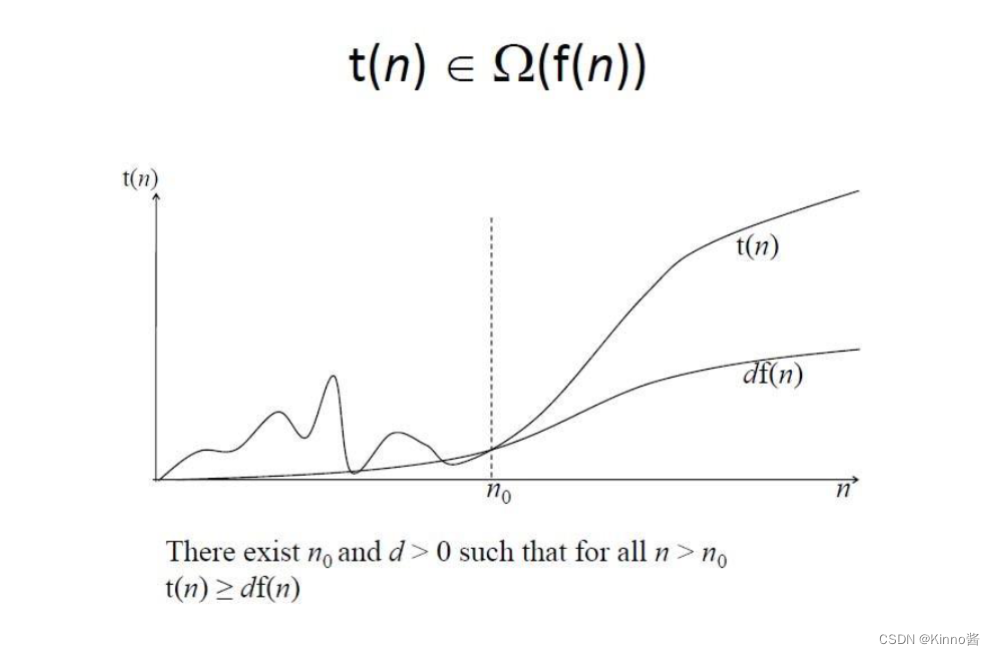

at same rate
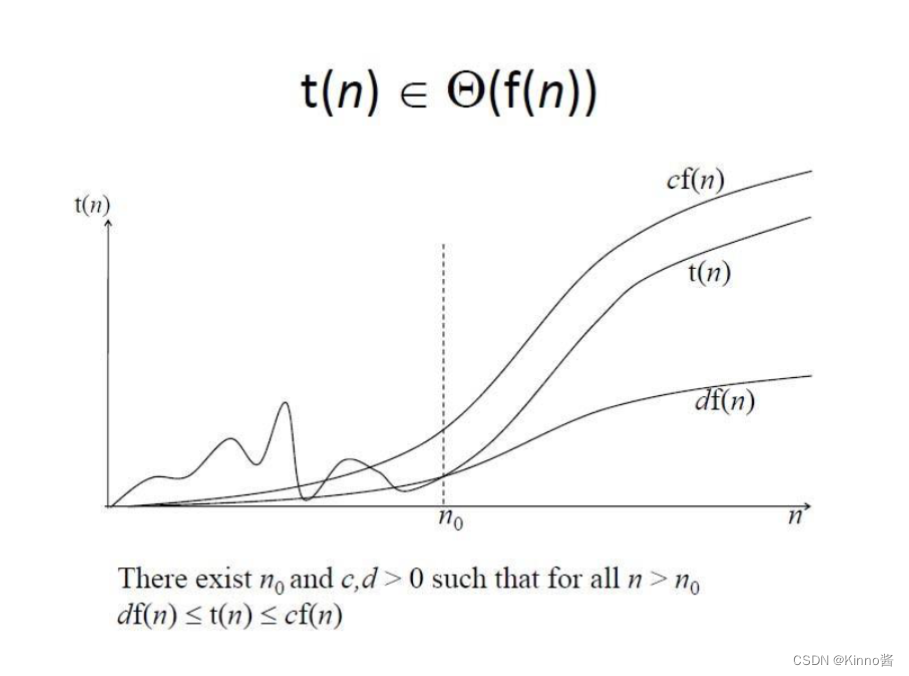

Summary

Some Properties
意义:算法的整体效率将由增长顺序较大的部分决定。


Using Limits for Comparing Orders of Growth


所有的对数函数loga n都属于同一个类别
所有相同度数k的多项式都属于同一类别
指数函数对于不同的a有不同的增长顺序

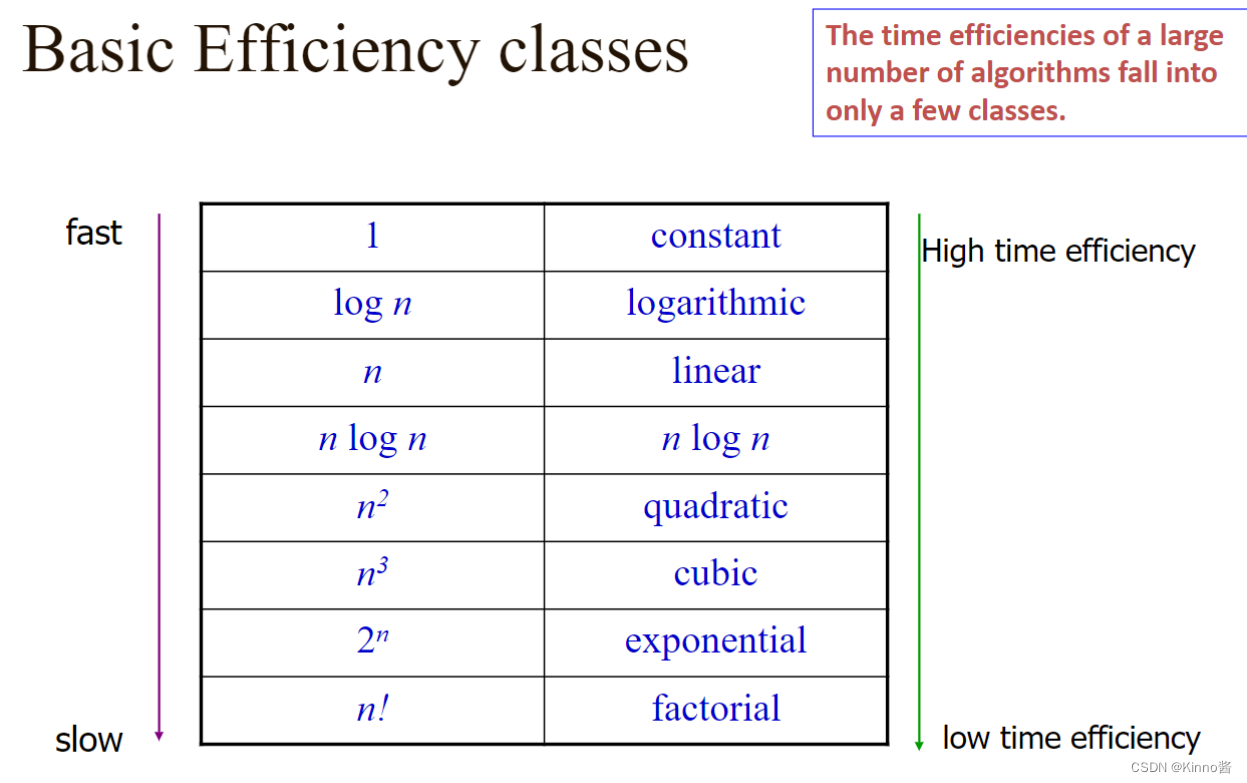
Analysis of non-recursive algorithms 非递归算法的分析

Analysis of recursive algorithms 递归算法的分析

- 计算递归调用的次数
- 解决递归问题,或通过后向替代或其他方法估计解决方案的数量级
Examples
求n!
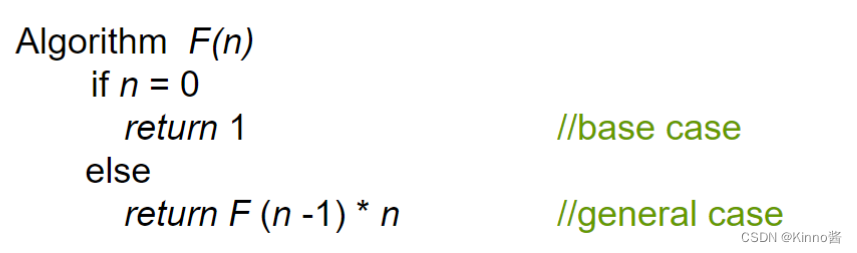

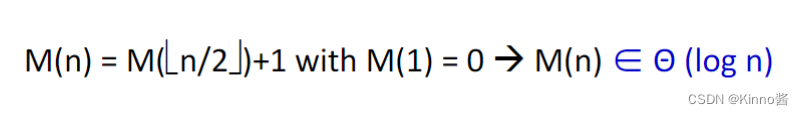
重要的递归类型


For-loop
range(0,10) 范围是左闭右开

字符串操作
字符串内容大写/小写
.upper()
.lower()

找字串位置,找不到返回-1

字符串长度

根据下标返回字符串中对应字符

切割字符串
[i:j] 范围左开右闭,从下标为i的字符到下标为j-1的字符,获得的子串长度为j-i

Data Structure
data, relationship , operation

Abstract data type (ADT)



Function 函数


四舍五入保留小数点后多少位函数

min,max函数是python内置的

random函数
左闭右闭

Class and object
对象是类的实例。
术语“对象”和“实例”可以互换使用。每个对象实例都有自己的数据值。

Instance attribute vs Class attribute
Some information belongs to individual object instance.
Some other information is common to all objects.
- Instance attribute: data belongs to individual object instance.
- Class attribute: data that is common to all objects. (Some classes do not have any class attributes.)
有些信息属于单个对象实例。
其他一些信息对于所有对象都是通用的。
- 实例属性:数据属于单个对象实例。
- 类属性:所有对象共有的数据。 (有些类没有任何类属性。)

Instance method vs Class/Static method
Instance method:
- Deal with a particular individual object instance
- The first argument (self) is always referred to the object instance
- instance method can be invoked from an object
Static / Class method:
- Do NOT deal with individual object instance
- Common to all object instances
- static/class method can be invoked from class name
实例方法:
- 处理特定的单个对象实例
- 第一个参数(self)始终引用对象实例
- 可以从对象调用实例方法
静态/类方法:
- 不处理单个对象实例
- 所有对象实例共有
- 静态/类方法可以从类名调用
Instance method


Special instance method
在 Python 中,特殊的实例方法(也称为魔术方法或魔法方法)在类中具有特殊的意义和用途。以下是你提到的几个魔术方法的解释和示例:

__init__ 方法
__init__ 方法是类的构造函数,用于初始化新创建的对象的属性。它在对象创建时自动调用。你可以使用它来设置对象的初始状态。
class TV_Program:
def __init__(self, channel, title, start_time, duration):
self.channel = channel
self.title = title
self.start_time = start_time
self.duration = duration
# 创建一个 TV_Program 对象
program = TV_Program('HBO', 'Game of Thrones', '21:00', 60)
print(program.channel) # 输出: HBO
__str__ 方法
__str__ 方法用于定义对象的“可读”字符串表示。当你使用 print() 函数或 str() 函数时,Python 会调用这个方法。这个方法应该返回一个易于阅读和理解的字符串。
class TV_Program:
def __init__(self, channel, title, start_time, duration):
self.channel = channel
self.title = title
self.start_time = start_time
self.duration = duration
def __str__(self):
return f"{self.title} on {self.channel} at {self.start_time} for {self.duration} minutes"
# 创建一个 TV_Program 对象
program = TV_Program('HBO', 'Game of Thrones', '21:00', 60)
print(program) # 输出: Game of Thrones on HBO at 21:00 for 60 minutes
__repr__ 方法
__repr__ 方法用于定义对象的“正式”字符串表示。这通常是一个详细且准确的字符串,应该尽可能包含信息,以便开发者可以重现该对象。__repr__ 方法通常在交互式解释器中调用,或者当使用 repr() 函数时调用。
class TV_Program:
def __init__(self, channel, title, start_time, duration):
self.channel = channel
self.title = title
self.start_time = start_time
self.duration = duration
def __repr__(self):
return f"TV_Program(channel='{self.channel}', title='{self.title}', start_time='{self.start_time}', duration={self.duration})"
# 创建一个 TV_Program 对象
program = TV_Program('HBO', 'Game of Thrones', '21:00', 60)
print(repr(program)) # 输出: TV_Program(channel='HBO', title='Game of Thrones', start_time='21:00', duration=60)
完整示例
class TV_Program:
def __init__(self, channel, title, start_time, duration):
self.channel = channel
self.title = title
self.start_time = start_time
self.duration = duration
def __str__(self):
return f"{self.title} on {self.channel} at {self.start_time} for {self.duration} minutes"
def __repr__(self):
return f"TV_Program(channel='{self.channel}', title='{self.title}', start_time='{self.start_time}', duration={self.duration})"
# 创建一个 TV_Program 对象
program = TV_Program('HBO', 'Game of Thrones', '21:00', 60)
print(program) # 调用 __str__ 方法
print(repr(program)) # 调用 __repr__ 方法
在这个示例中,__init__ 方法用于初始化 TV_Program 对象的属性,__str__ 方法用于提供对象的可读字符串表示,而 __repr__ 方法用于提供对象的正式字符串表示。
Static / Class method

Class method vs static method: 类方法和静态方法的区别
- The first argument (cls) of a class method is always referred to the class
在 Python 中,类方法和静态方法都是属于类的特殊方法,但它们有不同的用途和行为。以下是它们的区别和详细解释:
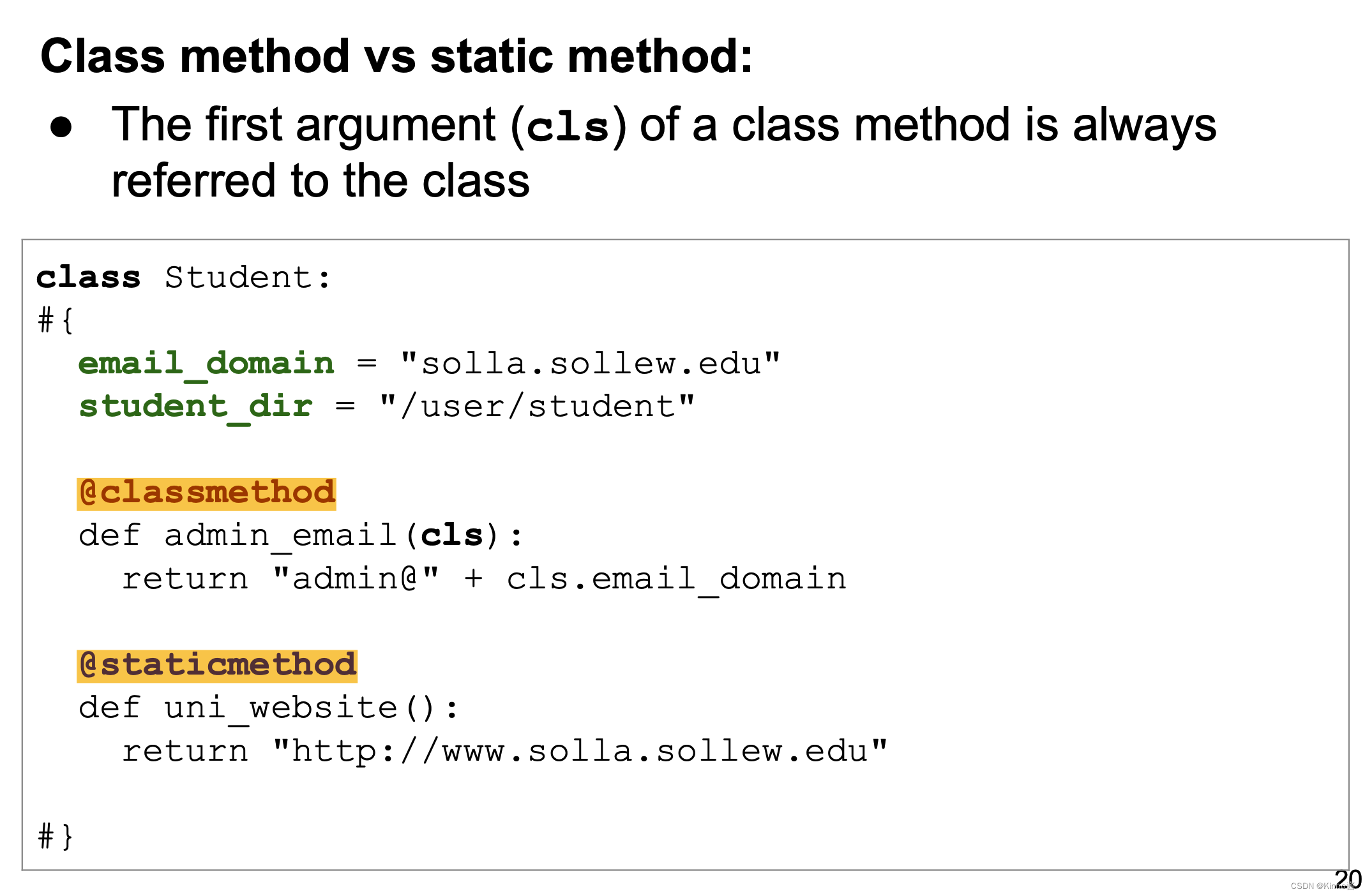
类方法(Class Method)
类方法使用 @classmethod 装饰器定义,第一个参数总是指向类本身,通常命名为 cls。类方法可以访问类的属性和方法,但不能直接访问实例属性。
特点:
- 第一个参数
cls代表类,而不是实例。 - 可以通过类名或者实例调用。
- 可以访问类属性和类方法,不能访问实例属性。
示例:
class Student:
email_domain = "solla.sollew.edu" # 类属性
@classmethod
def admin_email(cls):
return "admin@" + cls.email_domain # 访问类属性
# 调用类方法
print(Student.admin_email()) # 输出: [email protected]
# 创建实例并调用类方法
student = Student()
print(student.admin_email()) # 输出: [email protected]
静态方法(Static Method)
静态方法使用 @staticmethod 装饰器定义。静态方法没有默认的参数,它们与类和实例都无关,不能访问类属性或实例属性。静态方法通常用于一些逻辑上与类相关,但不需要访问类或实例的任何数据的方法。
特点:
- 没有默认的参数(没有
self或cls)。 - 可以通过类名或者实例调用。
- 无法访问类属性和实例属性。
示例:
class Student:
email_domain = "solla.sollew.edu" # 类属性
@staticmethod
def uni_website():
return "http://www.solla.sollew.edu" # 逻辑上与类相关,但不访问类或实例的数据
# 调用静态方法
print(Student.uni_website()) # 输出: http://www.solla.sollew.edu
# 创建实例并调用静态方法
student = Student()
print(student.uni_website()) # 输出: http://www.solla.sollew.edu
示例代码:
总结:
- 类方法 使用
@classmethod装饰,第一个参数cls代表类本身,可以通过类名或实例调用,能访问类属性和类方法。 - 静态方法 使用
@staticmethod装饰,没有默认参数,不能访问类属性或实例属性,只是逻辑上与类相关的方法。
class Student:
email_domain = "solla.sollew.edu" # 类属性
student_dir = "/user/student" # 类属性
@classmethod
def admin_email(cls):
return "admin@" + cls.email_domain # 类方法,访问类属性
@staticmethod
def uni_website():
return "http://www.solla.sollew.edu" # 静态方法,不访问类或实例数据
# 调用类方法和静态方法
print(Student.admin_email()) # 输出: [email protected]
print(Student.uni_website()) # 输出: http://www.solla.sollew.edu
# 创建实例并调用类方法和静态方法
student = Student()
print(student.admin_email()) # 输出: [email protected]
print(student.uni_website()) # 输出: http://www.solla.sollew.edu

Defining class and creating object 定义类和创建对象

Accessing object instance attributes 访问对象的实例属性

Modify object instance attributes 更改对象的实例属性

Defining an object instance method 定义对象的示例属性

类注释和函数注释

案例学习:定义一个学生类












Class inheritance 类继承



Array and Linked List
Numpy Array




Python链表实现

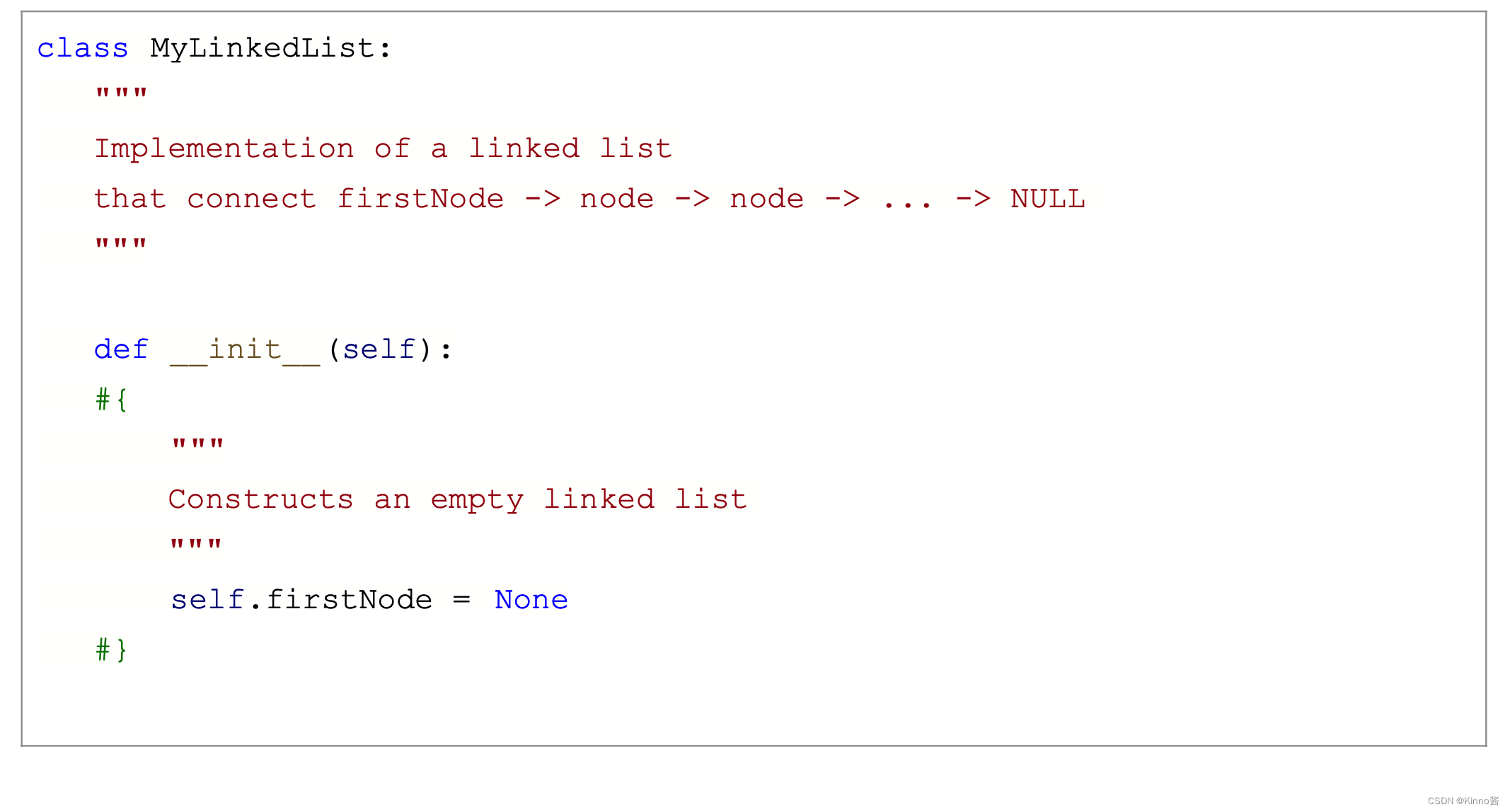
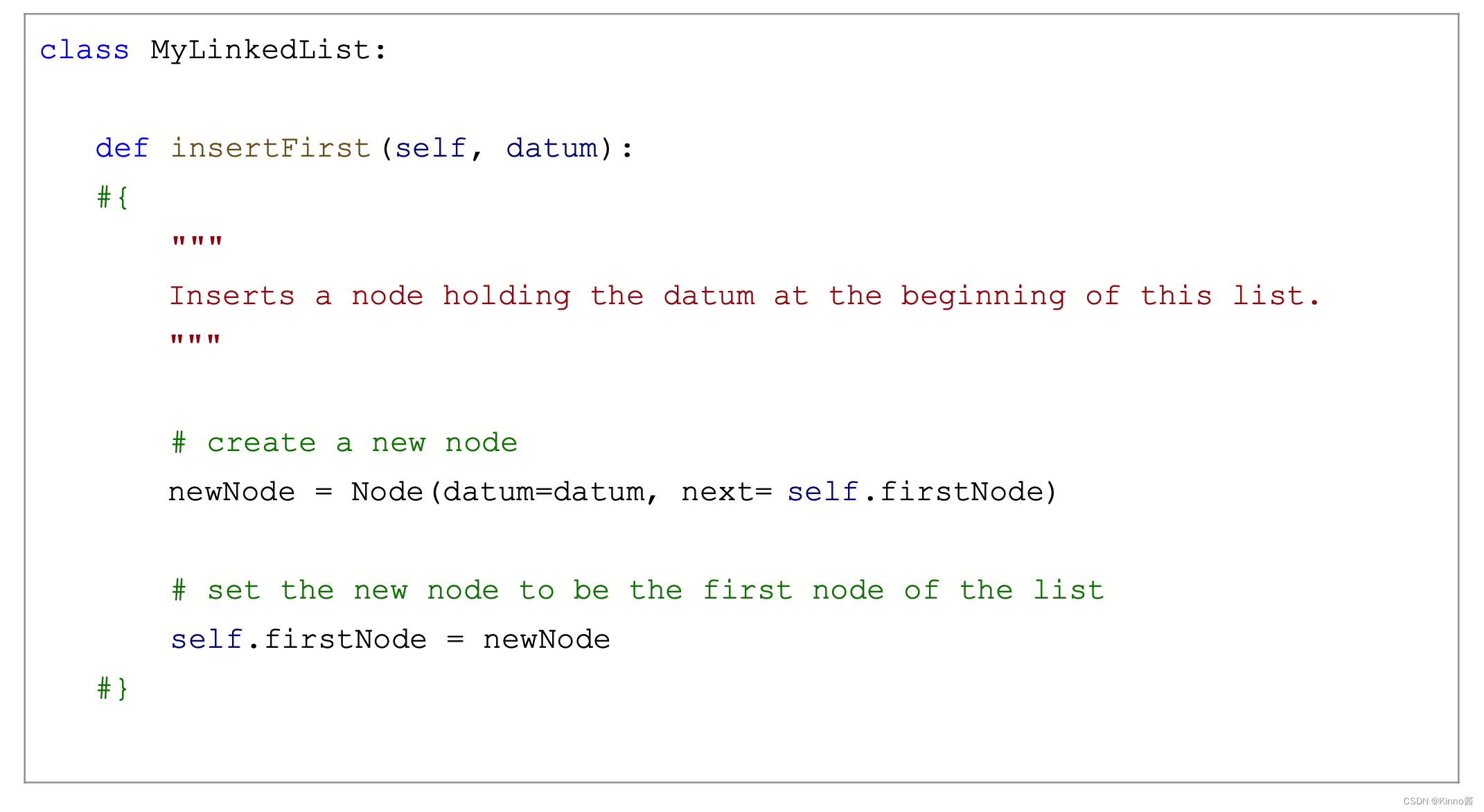

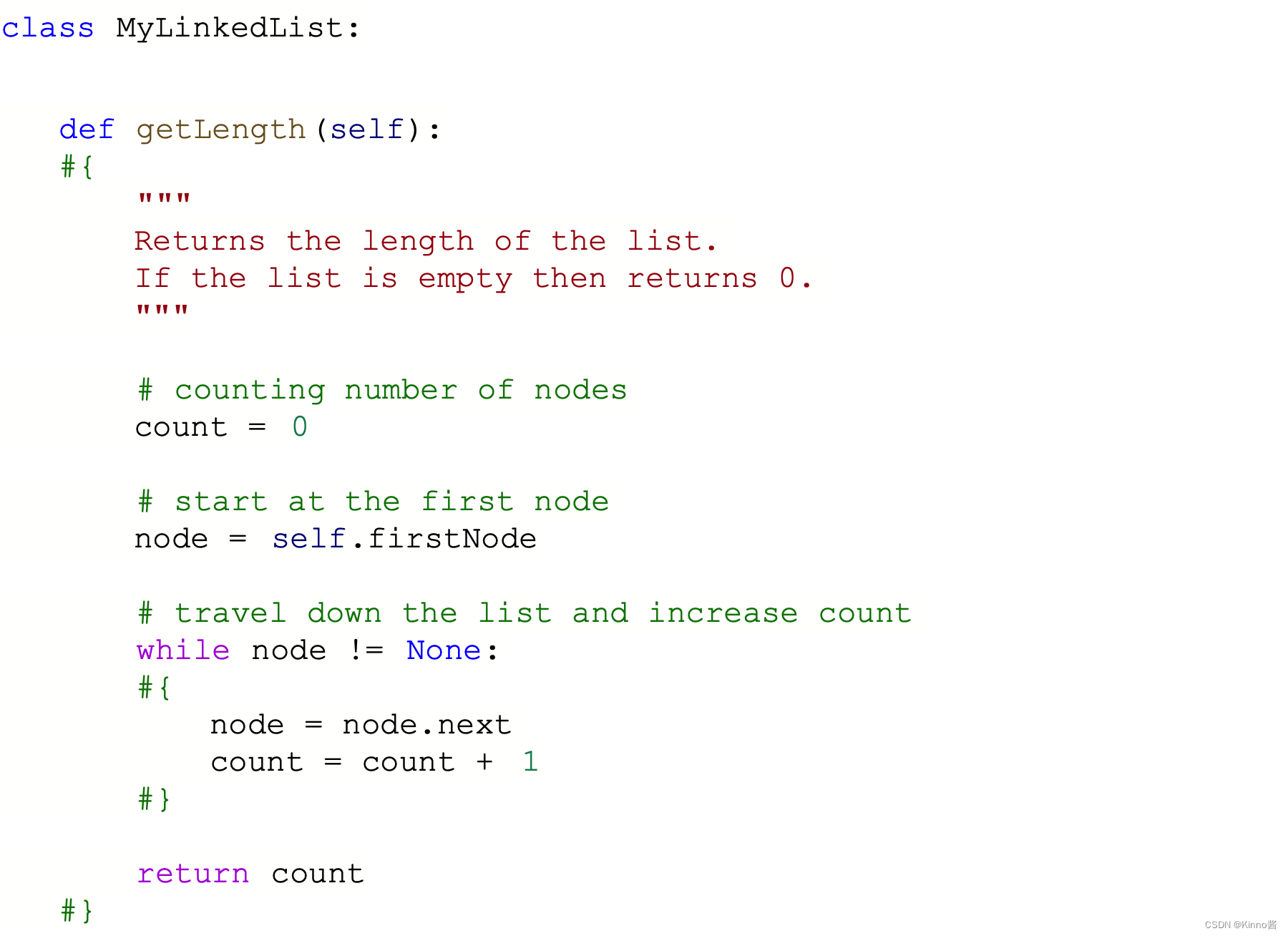


Debuging
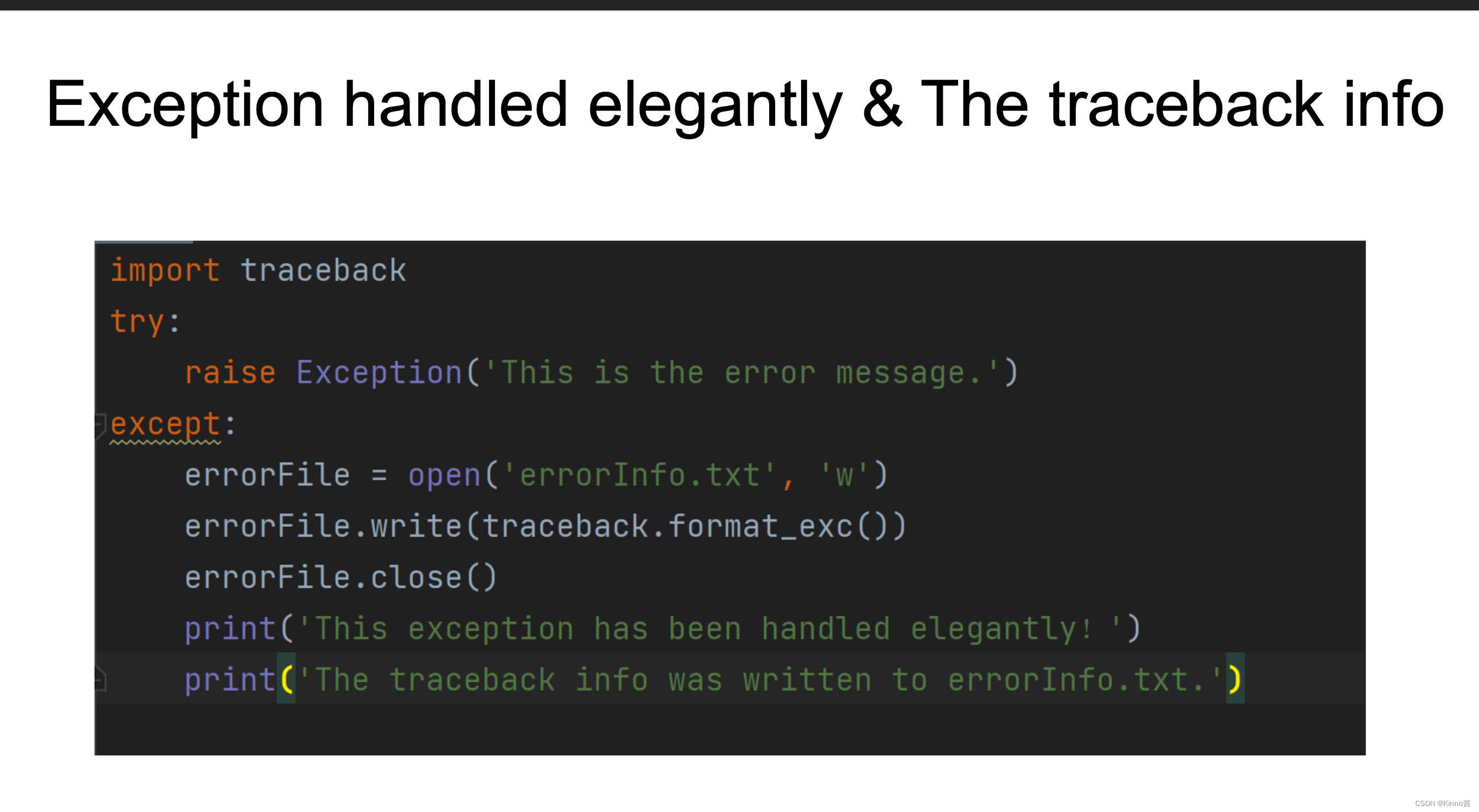
Exception&traceback
traceback库中的traceback.format_exc()获取异常追踪的详细信息

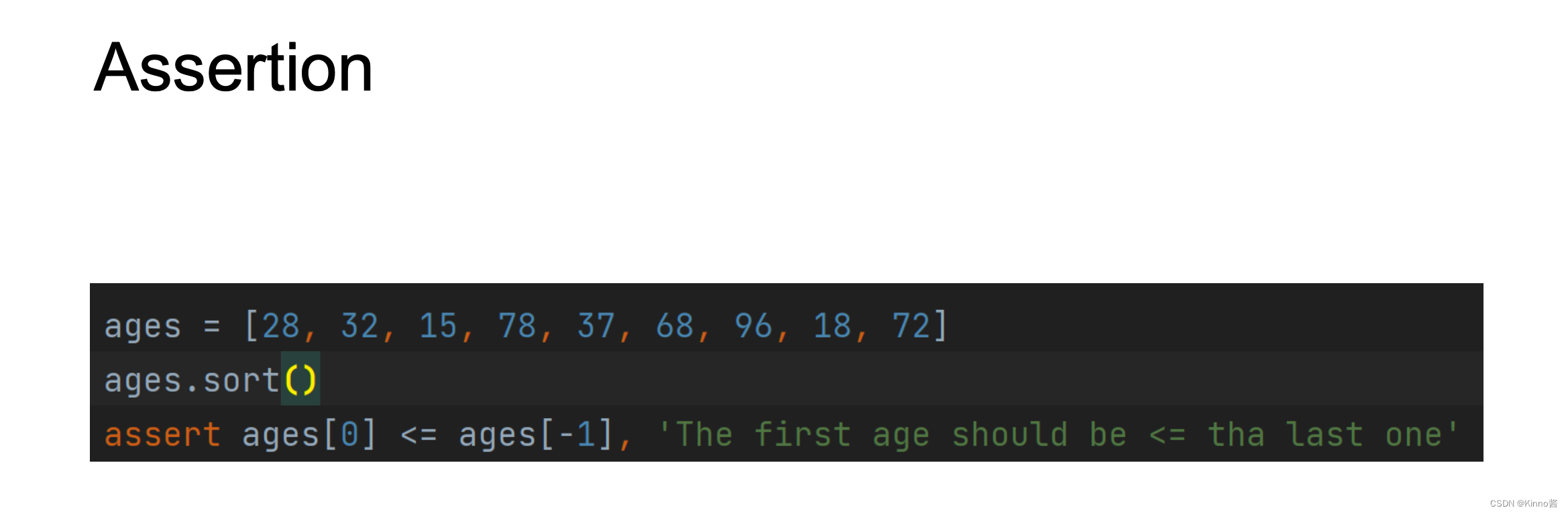
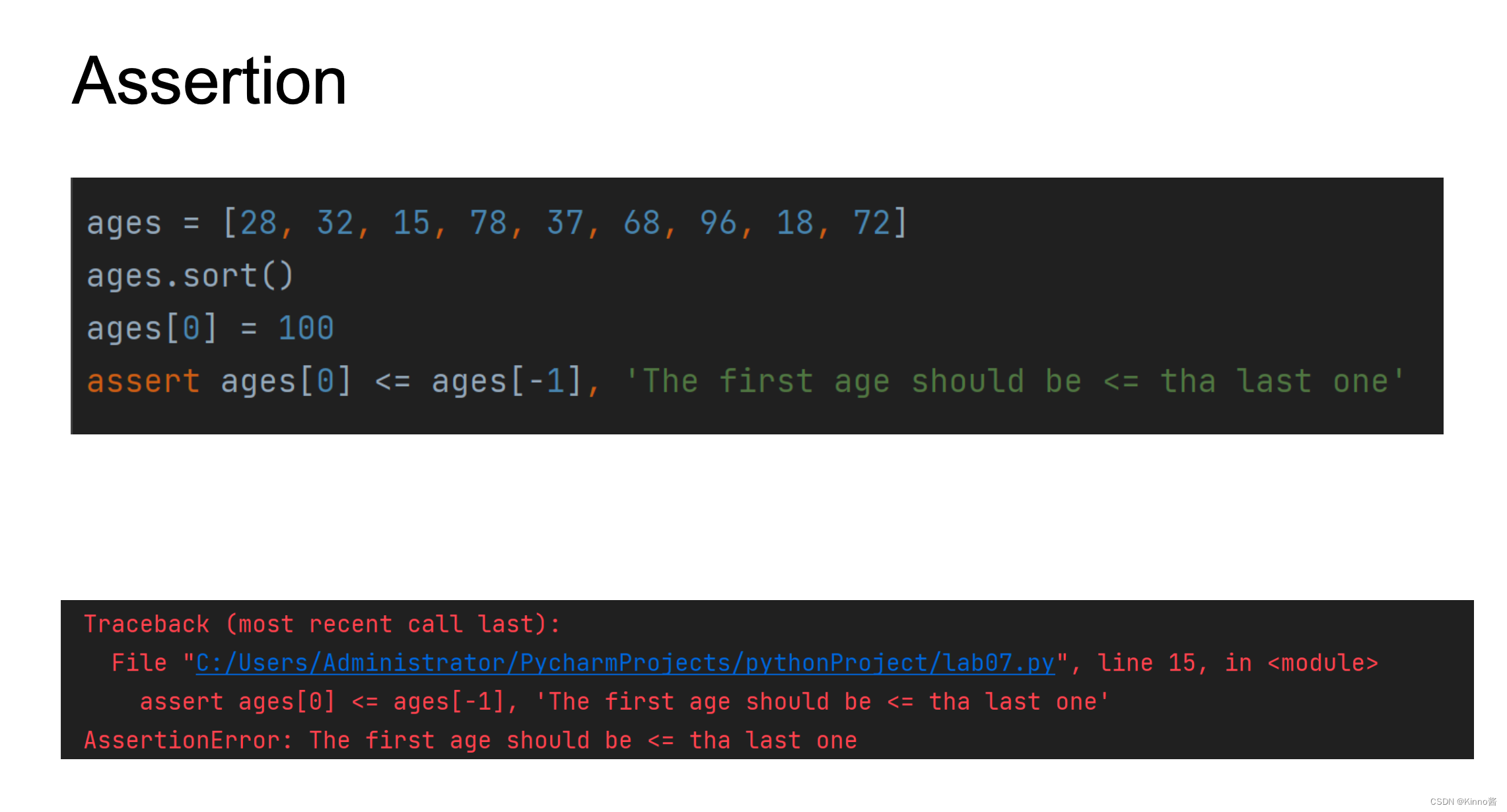
Assertion
• 它通常用于检查不可能发生的情况
• 断言语句导致终止
立即停止 → 快速失败
• 对于来自程序员而不是用户的错误
Logging
- 使用 print() 向用户显示某些变量的值显示消息
- Logging日志模块在屏幕上显示日志信息/向程序员显示信息文件
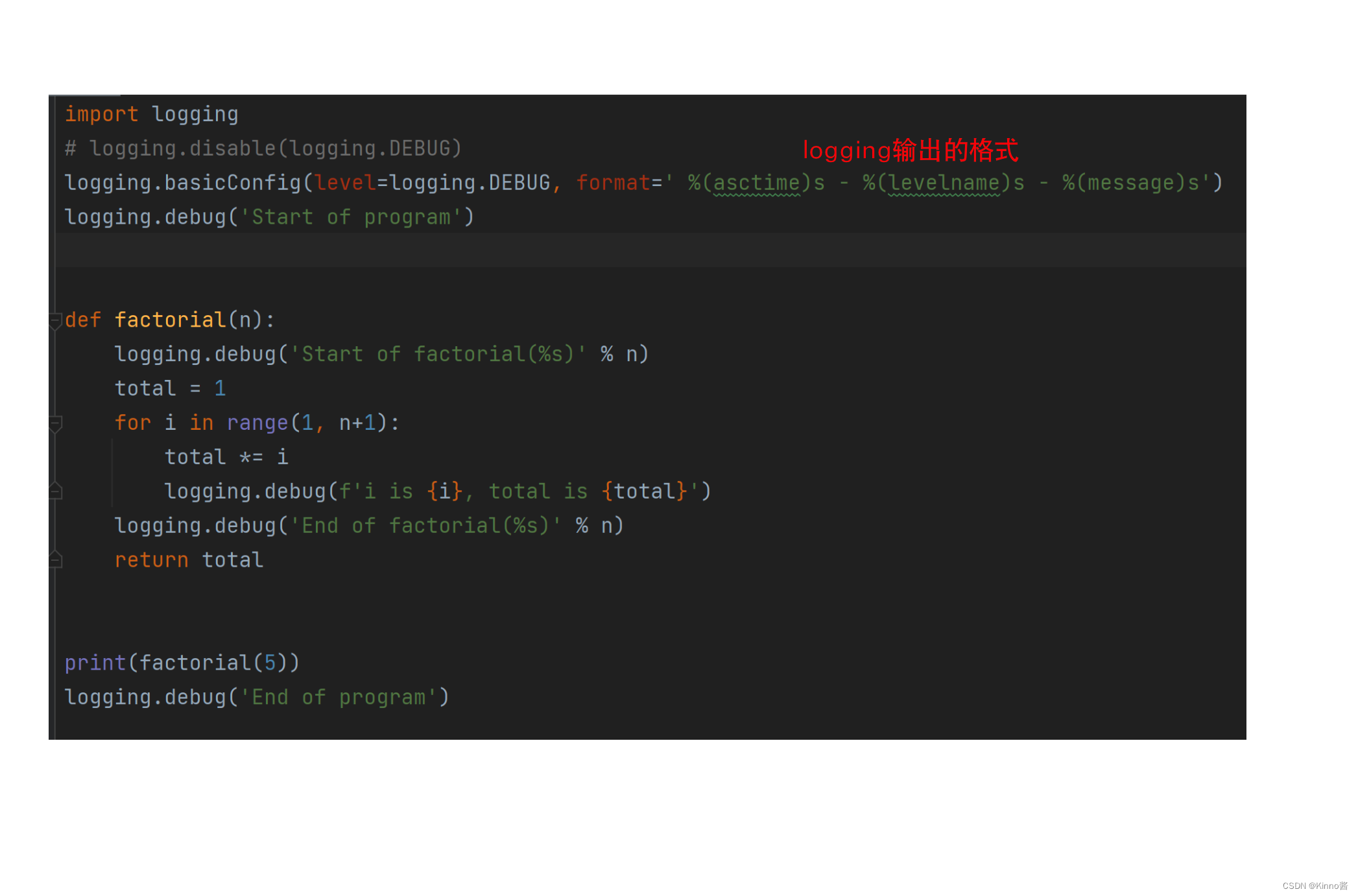
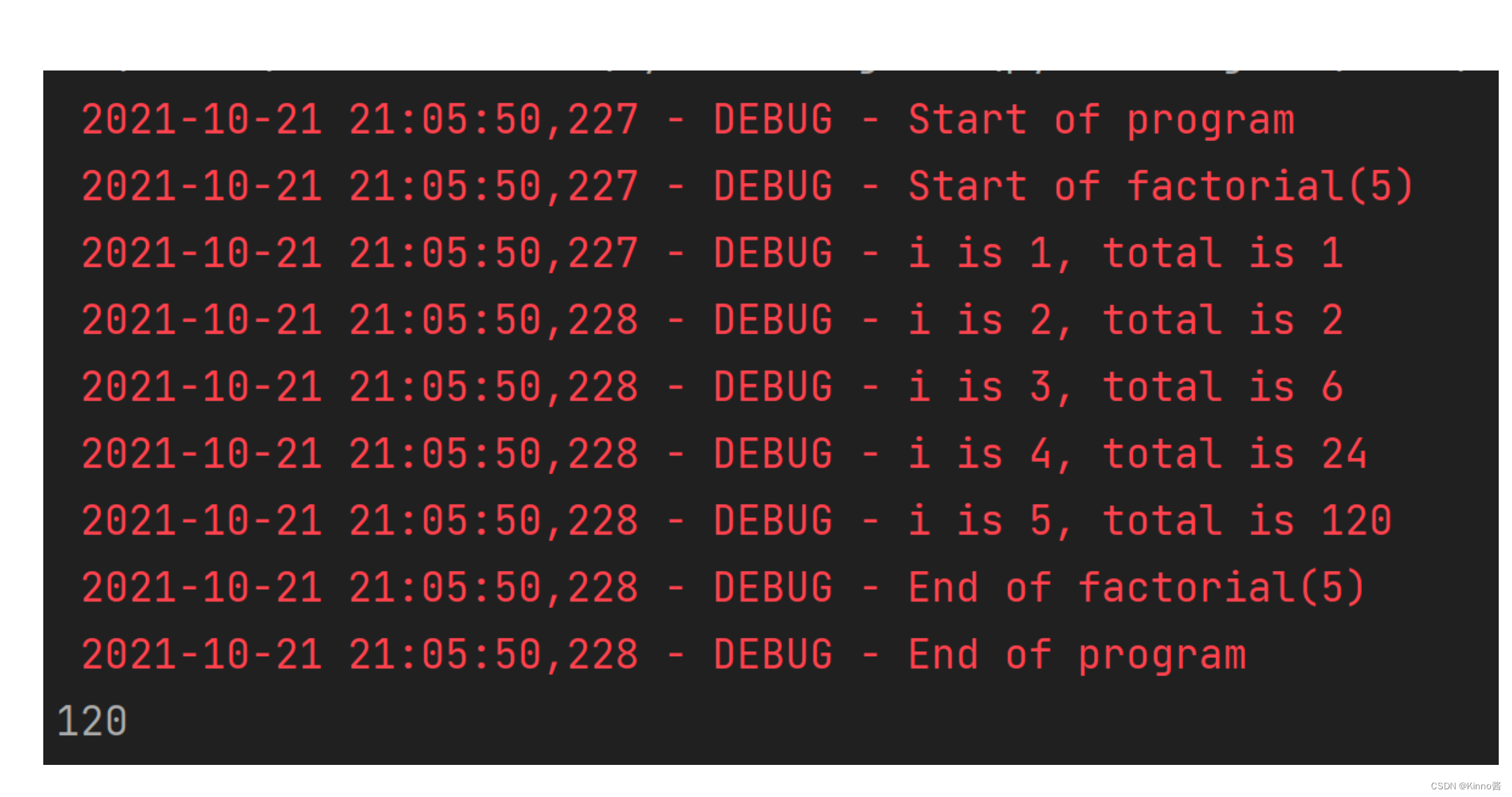

Python八股收集
is 和 == 的区别?
在 Python 中,is 和 == 用于比较对象,但它们有不同的含义和用法:
== 操作符
== 操作符用于比较两个对象的值是否相等,即它们是否包含相同的数据。无论这两个对象是否是同一个对象,只要它们的内容相同,== 比较就会返回 True。
a = [1, 2, 3]
b = [1, 2, 3]
print(a == b) # 输出: True,因为 a 和 b 的内容相同
is 操作符
is 操作符用于比较两个对象的身份是否相同,即它们是否是同一个对象。在 Python 中,每个对象都有一个唯一的身份(可以通过 id() 函数获取),is 比较的就是两个对象的身份是否相同。
a = [1, 2, 3]
b = [1, 2, 3]
print(a is b) # 输出: False,因为 a 和 b 是不同的对象,即使它们的内容相同
c = a
print(a is c) # 输出: True,因为 a 和 c 是同一个对象
总结
==比较的是对象的值(内容)。is比较的是对象的身份(是否是同一个对象)。
这两个操作符在比较对象时的行为差异在实际编程中是非常重要的,尤其是当处理可变对象(如列表、字典等)和不可变对象(如整数、字符串、元组等)时。
示例
# 比较不可变对象(如整数)
x = 1000
y = 1000
print(x == y) # 输出: True,因为 x 和 y 的值相同
print(x is y) # 输出: False,因为 x 和 y 是不同的对象
# 比较不可变对象(小整数缓存机制)
x = 10
y = 10
print(x == y) # 输出: True,因为 x 和 y 的值相同
print(x is y) # 输出: True,因为 Python 对小整数有缓存机制,x 和 y 实际上是同一个对象
# 比较可变对象(如列表)
a = [1, 2, 3]
b = [1, 2, 3]
print(a == b) # 输出: True,因为 a 和 b 的内容相同
print(a is b) # 输出: False,因为 a 和 b 是不同的对象
理解这两个操作符的区别有助于避免在代码中出现意外的行为,并能更准确地进行对象比较。
Python 基本数据类型
在 Python 中,is 和 == 用于比较对象,但它们有不同的含义和用法:
== 操作符
== 操作符用于比较两个对象的值是否相等,即它们是否包含相同的数据。无论这两个对象是否是同一个对象,只要它们的内容相同,== 比较就会返回 True。
a = [1, 2, 3]
b = [1, 2, 3]
print(a == b) # 输出: True,因为 a 和 b 的内容相同
is 操作符
is 操作符用于比较两个对象的身份是否相同,即它们是否是同一个对象。在 Python 中,每个对象都有一个唯一的身份(可以通过 id() 函数获取),is 比较的就是两个对象的身份是否相同。
a = [1, 2, 3]
b = [1, 2, 3]
print(a is b) # 输出: False,因为 a 和 b 是不同的对象,即使它们的内容相同
c = a
print(a is c) # 输出: True,因为 a 和 c 是同一个对象
总结
==比较的是对象的值(内容)。is比较的是对象的身份(是否是同一个对象)。
这两个操作符在比较对象时的行为差异在实际编程中是非常重要的,尤其是当处理可变对象(如列表、字典等)和不可变对象(如整数、字符串、元组等)时。
示例
# 比较不可变对象(如整数)
x = 1000
y = 1000
print(x == y) # 输出: True,因为 x 和 y 的值相同
print(x is y) # 输出: False,因为 x 和 y 是不同的对象
# 比较不可变对象(小整数缓存机制)
x = 10
y = 10
print(x == y) # 输出: True,因为 x 和 y 的值相同
print(x is y) # 输出: True,因为 Python 对小整数有缓存机制,x 和 y 实际上是同一个对象
# 比较可变对象(如列表)
a = [1, 2, 3]
b = [1, 2, 3]
print(a == b) # 输出: True,因为 a 和 b 的内容相同
print(a is b) # 输出: False,因为 a 和 b 是不同的对象
理解这两个操作符的区别有助于避免在代码中出现意外的行为,并能更准确地进行对象比较。 Python 的小整数缓存机制默认会缓存范围在 -5 到
256 之间的整数。这意味着对于这些范围内的整数,每次创建相同值的整数时,Python
都会使用同一个对象(即同一个内存地址)。这种缓存机制有助于提高性能,因为小整数在 Python 程序中被频繁使用。
List 和 元组 区别
在 Python 中,列表(List)和元组(Tuple)是两种常见的数据结构,它们有一些重要的区别:
列表(List)
- 可变性:列表是可变的,这意味着列表中的元素可以被修改、添加或删除。
- 语法:列表使用方括号
[]来定义。 - 方法:列表有许多内置的方法,如
append(),extend(),insert(),remove(),pop(),clear(),sort(),reverse()等,用于对列表进行操作。 - 性能:由于列表是可变的,增加了额外的管理开销,因此在需要频繁修改元素的情况下,列表的性能会受到一定影响。
元组(Tuple)
- 不可变性:元组是不可变的,一旦定义了元组中的元素,就不能修改、添加或删除。
- 语法:元组使用圆括号
()来定义。如果元组中只有一个元素,需要在元素后加一个逗号,例如(1,),以区分与普通括号表达式。 - 方法:元组的方法比列表少,仅有
count()和index(),因为它们不需要修改。 - 性能:元组由于不可变,具有更少的内存开销和更高的访问效率。在不需要修改数据的情况下,使用元组比使用列表更高效。
示例
列表
# 定义一个列表
my_list = [1, 2, 3, 4, 5]
# 修改列表中的元素
my_list[0] = 10
# 添加元素
my_list.append(6)
# 删除元素
my_list.remove(3)
print(my_list) # 输出: [10, 2, 4, 5, 6]
常用的列表方法及其功能:
append()
- 功能:在列表的末尾添加一个元素。
- 语法:
list.append(element) - 示例:
my_list = [1, 2, 3] my_list.append(4) print(my_list) # 输出: [1, 2, 3, 4]
extend()
- 功能:将一个可迭代对象中的所有元素添加到列表的末尾。
- 语法:
list.extend(iterable) - 示例:
my_list = [1, 2, 3] my_list.extend([4, 5, 6]) print(my_list) # 输出: [1, 2, 3, 4, 5, 6]
insert()
- 功能:在指定位置插入一个元素。
- 语法:
list.insert(index, element) - 示例:
my_list = [1, 2, 3] my_list.insert(1, 4) print(my_list) # 输出: [1, 4, 2, 3]
remove()
- 功能:移除列表中第一个匹配的元素。
- 语法:
list.remove(element) - 示例:
my_list = [1, 2, 3, 2, 4] my_list.remove(2) print(my_list) # 输出: [1, 3, 2, 4]
pop()
- 功能:移除并返回列表中指定位置的元素,默认为最后一个元素。
- 语法:
list.pop([index]) - 示例:
my_list = [1, 2, 3] last_element = my_list.pop() print(last_element) # 输出: 3 print(my_list) # 输出: [1, 2]
clear()
- 功能:移除列表中的所有元素。
- 语法:
list.clear() - 示例:
my_list = [1, 2, 3] my_list.clear() print(my_list) # 输出: []
sort()
- 功能:对列表中的元素进行排序。
- 语法:
list.sort(key=None, reverse=False)key:指定排序的函数(可选)。reverse:如果为True,则列表按降序排序(可选)。
- 示例:
my_list = [3, 1, 2] my_list.sort() print(my_list) # 输出: [1, 2, 3] my_list.sort(reverse=True) print(my_list) # 输出: [3, 2, 1]
reverse()
- 功能:将列表中的元素反转。
- 语法:
list.reverse() - 示例:
my_list = [1, 2, 3] my_list.reverse() print(my_list) # 输出: [3, 2, 1]
元组
# 定义一个元组
my_tuple = (1, 2, 3, 4, 5)
# 访问元组中的元素
print(my_tuple[0]) # 输出: 1
# 尝试修改元组中的元素会导致错误
# my_tuple[0] = 10 # TypeError: 'tuple' object does not support item assignment
# 元组只有两个方法
print(my_tuple.count(1)) # 输出: 1
print(my_tuple.index(3)) # 输出: 2
选择使用列表或元组的建议
- 使用列表:当需要一个可变的、可以动态修改的集合时,使用列表。例如,需要频繁添加、删除或修改元素的情况下。
- 使用元组:当需要一个不可变的、只读的集合时,使用元组。例如,作为函数参数或返回值,或需要确保数据不被修改的情况下。
Lambda 讲一下
在 Python 中,lambda 是一种创建匿名函数的方式。这些函数被称为匿名函数,因为它们不像常规函数那样使用 def 关键字来命名。lambda 函数通常用于需要一个简单函数而不想定义一个完整函数的场景。
语法
lambda 函数的语法如下:
lambda 参数列表: 表达式
- 参数列表 是函数的输入参数,可以有多个,用逗号分隔。
- 表达式 是一个返回值的单行表达式。
特性
lambda函数可以有多个参数,但只能有一个表达式。lambda函数返回表达式的计算结果。lambda函数是轻量级的,适合用于简短的操作。
示例
- 基本使用
# 定义一个 lambda 函数,它接收两个参数并返回它们的和
add = lambda x, y: x + y
print(add(3, 5)) # 输出: 8
- 在
map函数中使用
# 使用 lambda 函数将一个列表中的每个元素平方
numbers = [1, 2, 3, 4, 5]
squares = list(map(lambda x: x ** 2, numbers))
print(squares) # 输出: [1, 4, 9, 16, 25]
- 在
filter函数中使用
# 使用 lambda 函数过滤出一个列表中的偶数
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
evens = list(filter(lambda x: x % 2 == 0, numbers))
print(evens) # 输出: [2, 4, 6, 8, 10]
- 在
sorted函数中使用
# 使用 lambda 函数根据列表中的元组的第二个元素排序
pairs = [(1, 2), (3, 1), (5, 0), (2, 3)]
sorted_pairs = sorted(pairs, key=lambda x: x[1])
print(sorted_pairs) # 输出: [(5, 0), (3, 1), (1, 2), (2, 3)]
使用场景
- 临时使用:当你只需要一个一次性使用的小函数,
lambda非常方便。 - 简洁代码:当你不想为了一个简单的功能去定义一个完整的函数时,
lambda可以让你的代码更简洁。 - 内置函数:
lambda常用于内置函数(如map、filter、sorted等)的参数中,来简化代码。
注意事项
- 可读性:虽然
lambda可以让代码更简洁,但过度使用可能会使代码变得难以阅读和维护。 - 复杂逻辑:
lambda适用于简单的表达式,不适合包含复杂逻辑的函数。
post 有什么类型
数字转字符串方法
用过python哪些包
python浅拷贝与深拷贝
with 的原理
with 语句在 Python 中用于简化资源管理,例如文件操作、网络连接、数据库连接等。当使用 with 语句时,会自动处理资源的初始化和清理,确保资源在使用后被正确释放,即使在发生异常的情况下。
with 语句依赖于上下文管理器(context manager)协议,该协议由两个方法组成:
__enter__(self):在进入with块时调用。它负责资源的初始化,并返回要在with块中使用的对象。__exit__(self, exc_type, exc_value, traceback):在退出with块时调用。它负责资源的清理。无论with块是否抛出异常,都会调用此方法。
上下文管理器类的基本结构如下:
class MyContextManager:
def __enter__(self):
# 初始化资源
print("Entering the context...")
return self
def __exit__(self, exc_type, exc_value, traceback):
# 清理资源
print("Exiting the context...")
if exc_type:
print(f"An exception occurred: {exc_value}")
return True # 如果返回 True,则异常被处理,不会再次抛出
# 使用示例
with MyContextManager() as manager:
print("Inside the with block")
# 可以在这里使用 manager 进行操作
# 如果有异常,会调用 __exit__ 方法
在上述代码中,MyContextManager 类实现了上下文管理器协议。当 with 语句执行时,以下步骤会依次发生:
- 调用
__enter__方法,并返回一个对象,该对象绑定到as之后的变量(如果存在)。 - 执行
with块中的代码。 - 无论
with块中的代码是否抛出异常,都会调用__exit__方法。如果有异常发生,异常类型、异常实例及追溯信息会传递给__exit__方法。 - 如果
__exit__方法返回True,异常被认为已经处理,不会再被抛出;否则,异常会在with块外继续传播。
以下是使用 with 语句处理文件操作的例子:
with open('example.txt', 'r') as file:
content = file.read()
print(content)
# 文件会在此处自动关闭,无需显式调用 file.close()
在这个例子中,open 函数返回一个文件对象,它实现了上下文管理器协议。当 with 语句执行时:
- 调用文件对象的
__enter__方法,打开文件并返回文件对象。 - 进入
with块,执行读取文件内容的代码。 - 离开
with块时,无论是否有异常发生,都会调用文件对象的__exit__方法,关闭文件。
这种方式确保了文件在使用后总是会被正确关闭,即使读取文件内容时发生异常也不例外。
装饰器
list 怎么去除重复元素
在 Python 中,可以使用多种方法去除列表中的重复元素。以下是几种常用的方法:
方法 1:使用集合(set)
集合是无序且不允许重复元素的数据结构。可以将列表转换为集合,再将集合转换回列表,以去除重复元素。
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = list(set(original_list))
print(unique_list) # 输出:[1, 2, 3, 4, 5]
方法 2:使用字典(dict)保持顺序
从 Python 3.7 开始,字典保持插入顺序,因此可以使用字典来去除重复元素并保持原有顺序。
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = list(dict.fromkeys(original_list))
print(unique_list) # 输出:[1, 2, 3, 4, 5]
方法 3:使用列表推导式保持顺序
可以使用列表推导式和一个辅助集合来去除重复元素并保持原有顺序。
original_list = [1, 2, 2, 3, 4, 4, 5]
seen = set()
unique_list = [x for x in original_list if not (x in seen or seen.add(x))]
print(unique_list) # 输出:[1, 2, 3, 4, 5]
方法 4:使用 itertools 模块的 groupby 方法
如果列表是已排序的,可以使用 itertools.groupby 去除重复元素。
from itertools import groupby
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = [key for key, _ in groupby(original_list)]
print(unique_list) # 输出:[1, 2, 3, 4, 5]
方法 5:使用 pandas 库的 unique 函数
如果使用 pandas 库,可以利用其 unique 函数。
import pandas as pd
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = pd.unique(original_list).tolist()
print(unique_list) # 输出:[1, 2, 3, 4, 5]
选择合适的方法取决于具体需求,例如是否需要保持原有顺序,或是否有外部库的依赖等。