前言:
上海人工智能实验室搭建的实验平台功能特别齐全,感觉可以替代谷歌的Colab作为大模型的实验平台了。(除了后台离开一段时间后会自动bash,导致之前配置好的环境丢失。实验平台:https://studio.intern-ai.org.cn/
实验教程:https://github.com/InternLM/tutorial/blob/main/helloworld/hello_world.md
轻松玩转书生·浦语大模型趣味Demo课后作业
1. 基础作业
1.1 使用 InternLM-Chat-7B 模型生成 300 字的小故事:
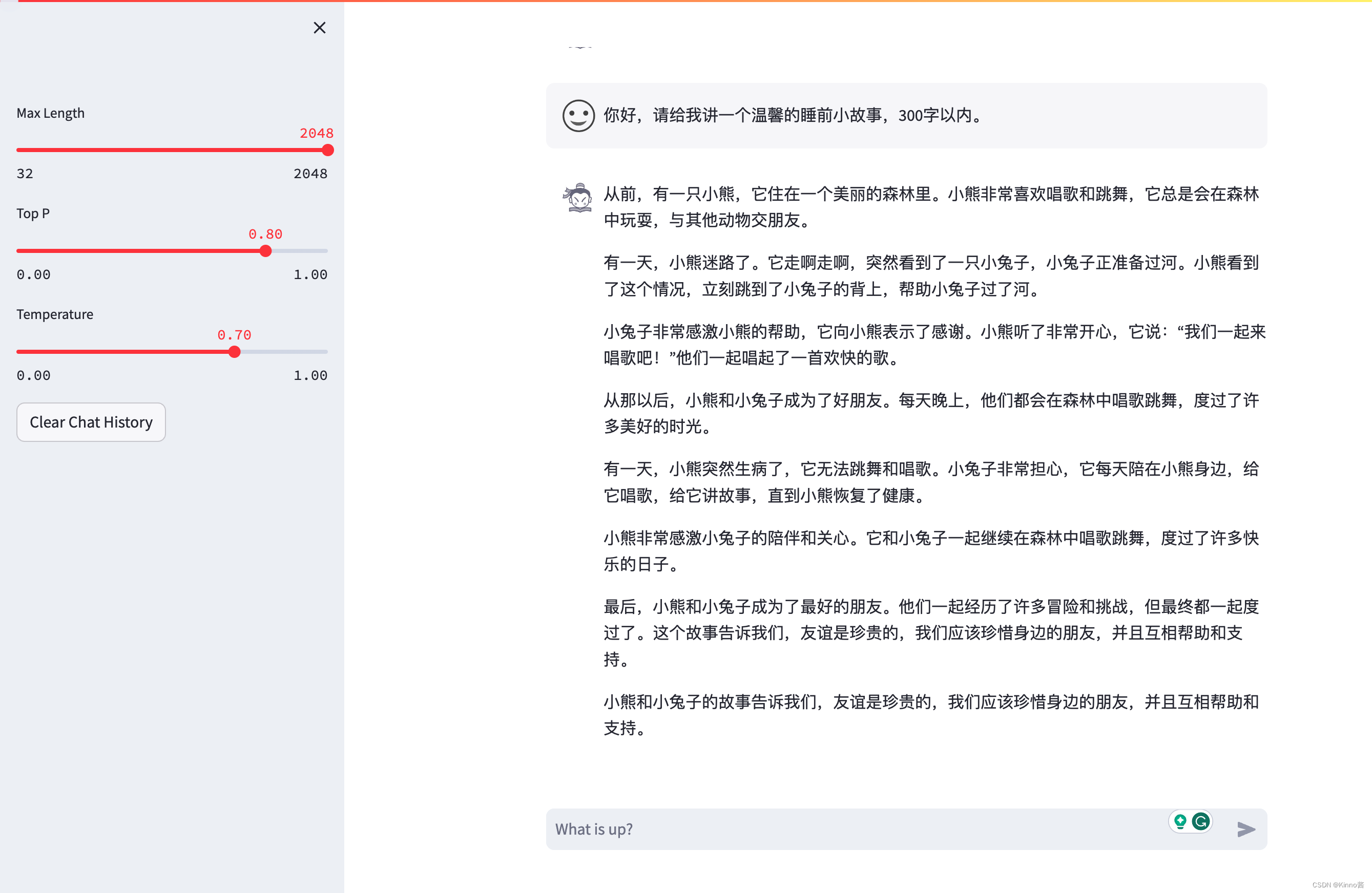
1.2 熟悉 hugging face 下载功能,使用 huggingface_hub python 包,下载 InternLM-20B 的 config.json 文件到本地
- 使用 Hugging Face 官方提供的 huggingface-cli 命令行工具,在本机的conda环境中安装依赖:
pip install -U huggingface_hub
- 使用python下载
internlm-7b
- 下载
config.json

- 查看
config.json
下载后的内容被保存在本地缓存目录中,查看文件的内容。

2. 进阶作业
2.1 完成 Lagent 工具调用 Demo 创作部署
Step1: 本地机连接服务器端口
Step2: 观察显存占用
- 在模型加载完成后,显存占用是14578MiB
- 在网页端向模型提出问题后,显存占用是75.54%,并且GPU也占用了24%,说明模型分析问题时会利用到GPU。
模型分析与输出回答时,最高显存占用为80.64%

Step3: 观察结果
模型后台端:
可以看到模型回答用户问题时自带的一些prompt。
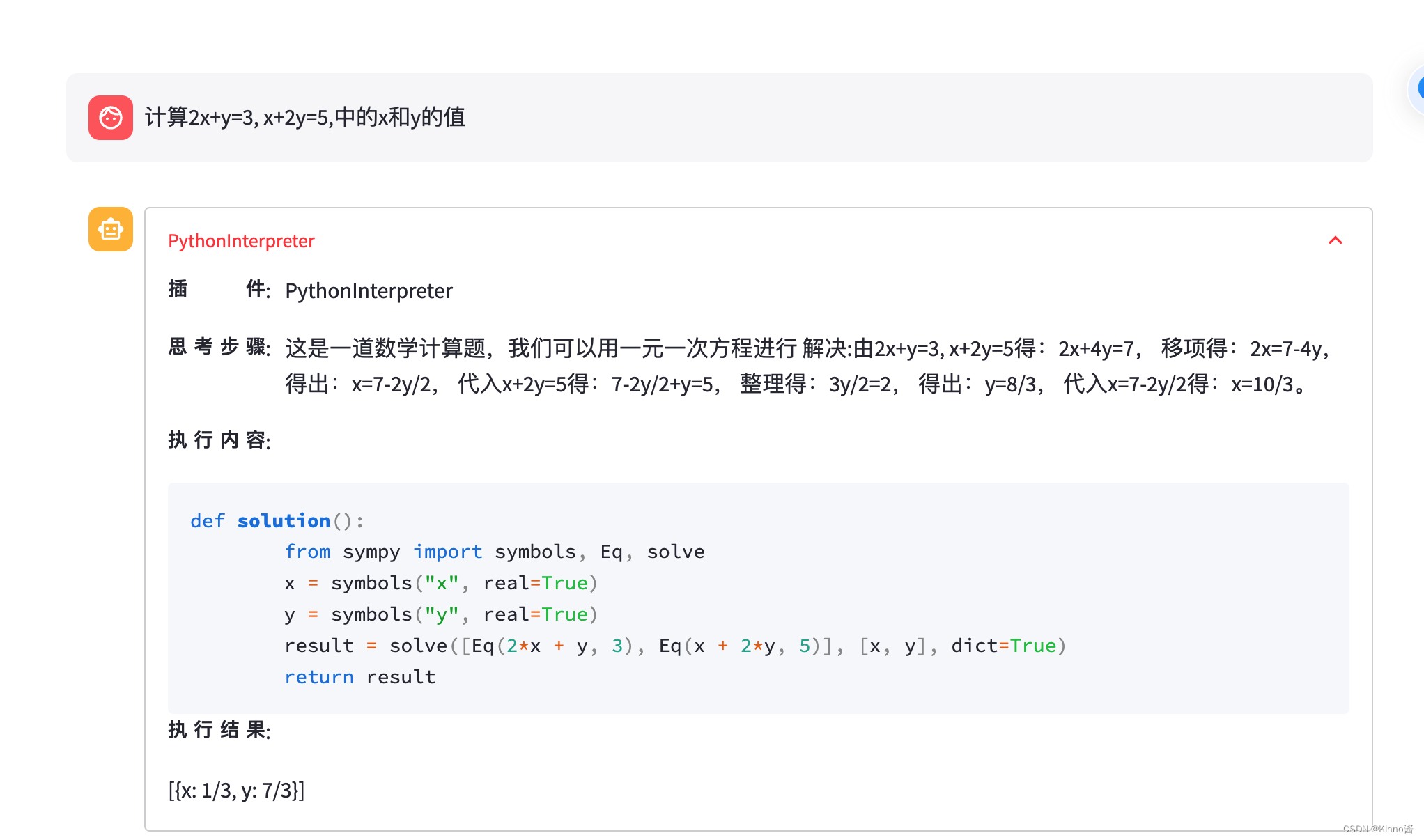
网页端:
利用python代码解决简单的方程问题,效果不错。

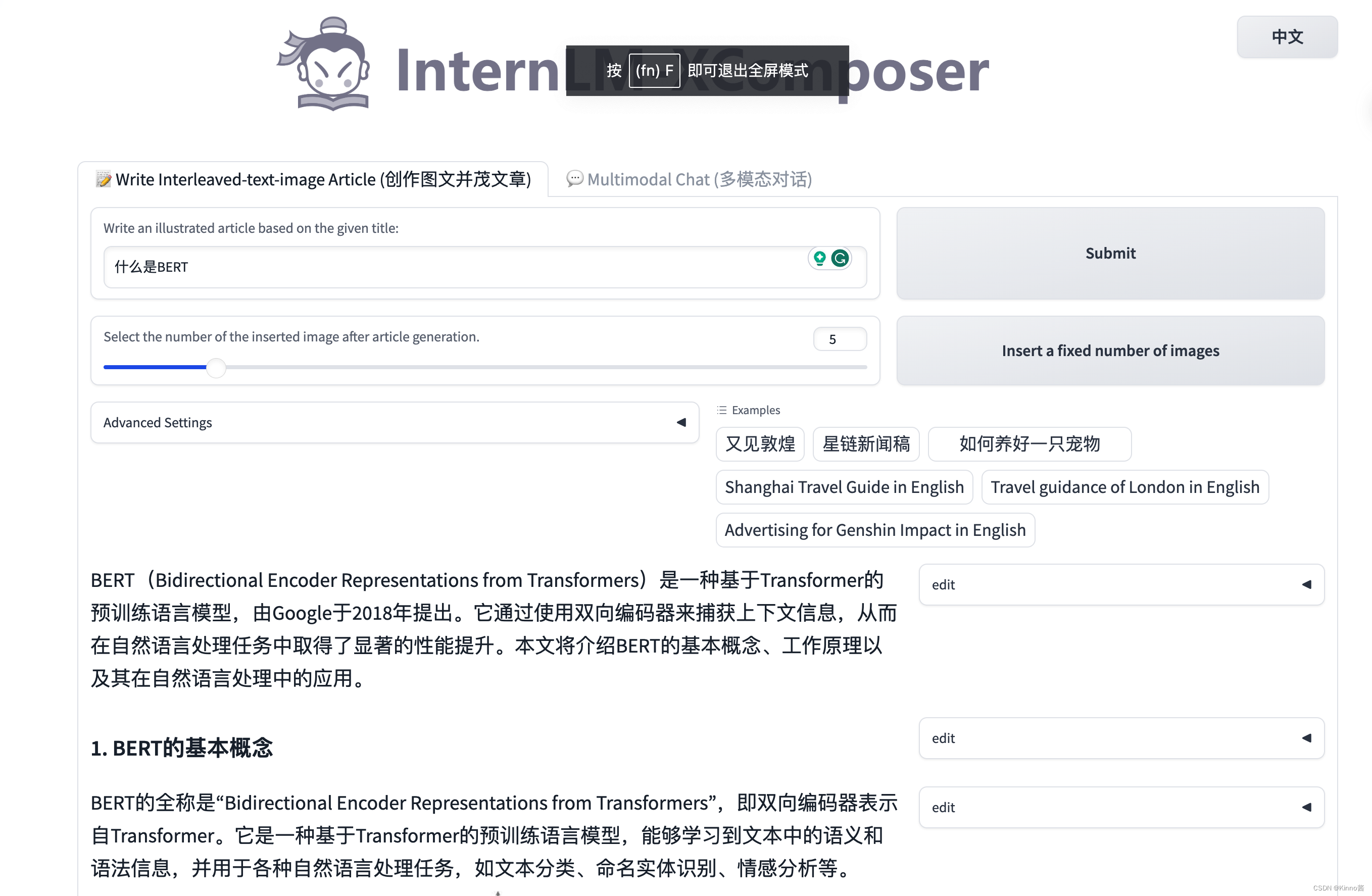
2.2 完成浦语·灵笔的图文理解及创作部署
图文并茂文章- Step1: 本地机连接服务器端口
同上
图文并茂文章- Step2: 观察显存占用
模型加载完成后的显存占用为18538MiB(45.27%)
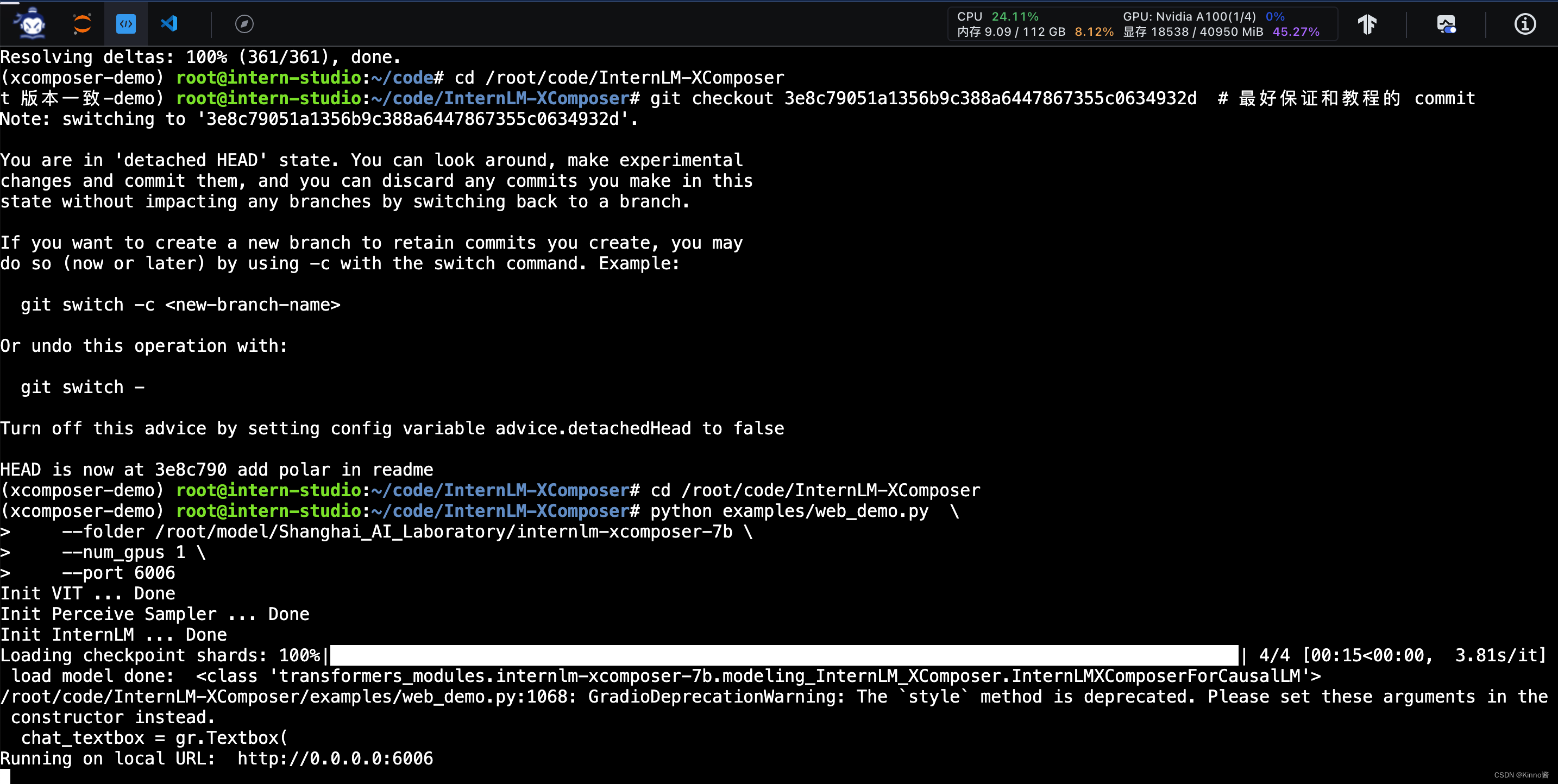
加载模型进行分析时(init步骤)的显存占用为29114MiB(71.1%),GPU占用为39%
图文并茂文章- Step3: 观察结果
可以观察得出,模型的思维链是先生成文本再寻找插图图片的位置,并且插入的图片能做到符合上下文内容
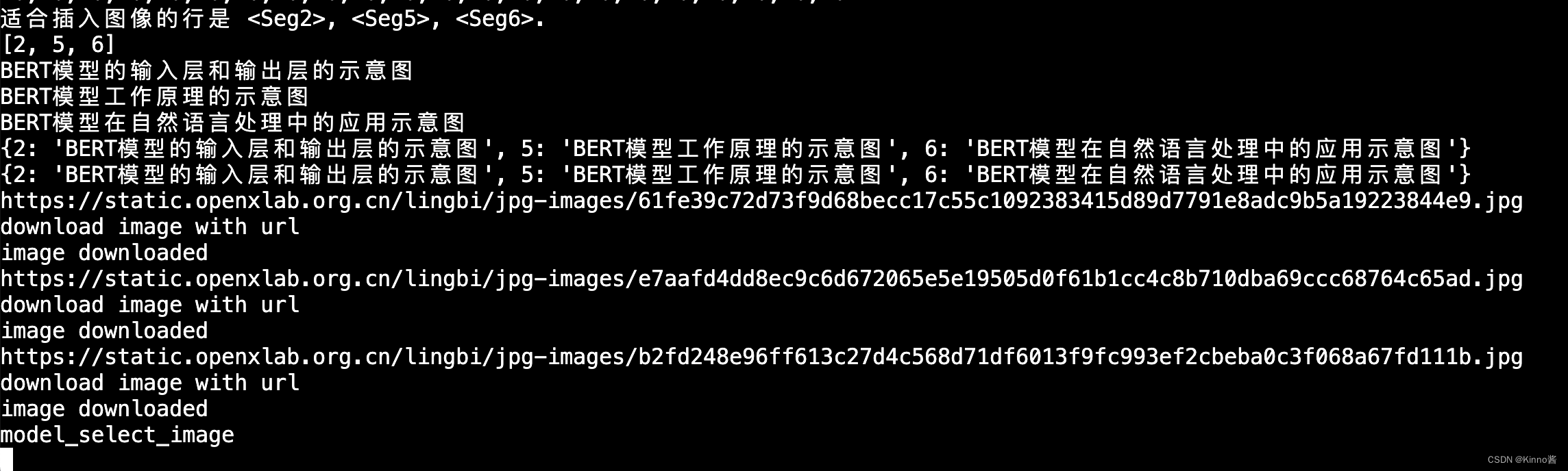
加载图片资源
在输出出现胡言乱语与迭代错误后,能做到到达输出上限后自动停止。这里是想用word2vec向我解释,但不知为何之后陷入循环了。
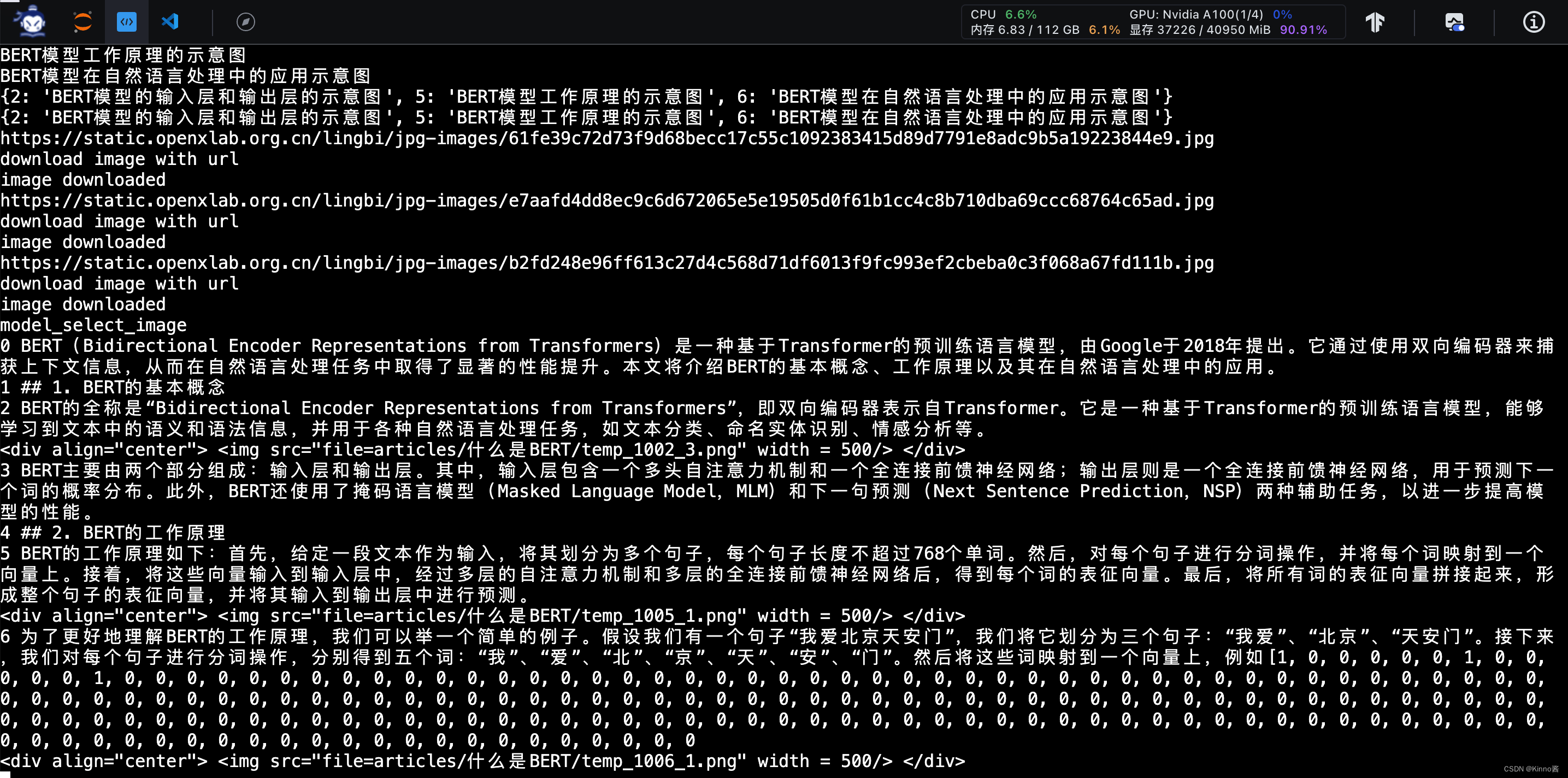
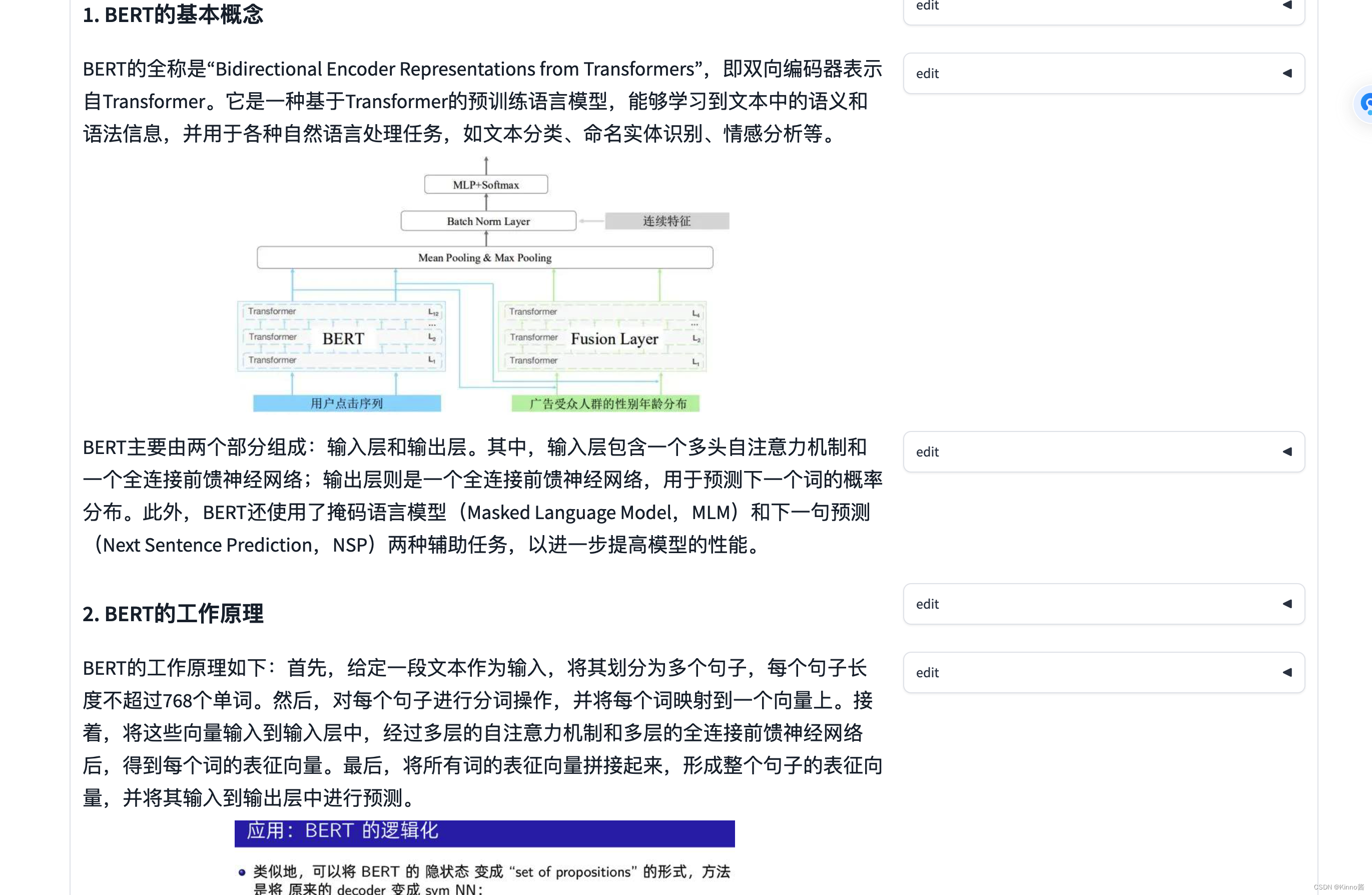
搜索得知图片直接来自于互联网,不是模型多模态生成的,这确保了图片的专业性和准确性,但是也带来了一定的版权风险。
这张图片互联网上没有搜索得到,推测可能是训练数据集中来自某些科研机构或者大学的教学PPT。
以下是网页端的输出结果:


多模态对话 Step1: 本地机连接服务器端口
同上
多模态对话- Step2: 观察显存占用
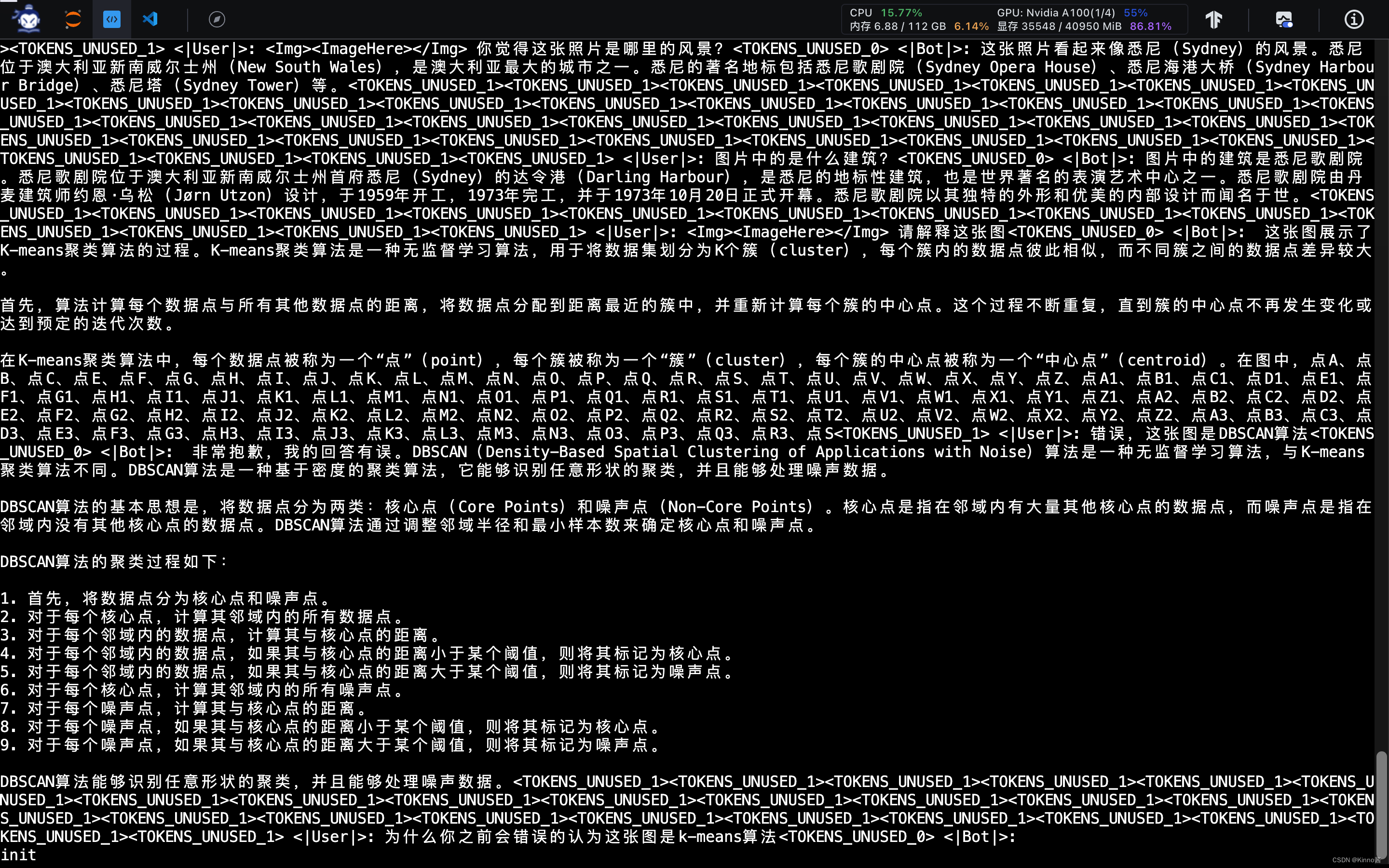
多模态对话- Step3: 观察结果
对于专业知识的图片分析错误
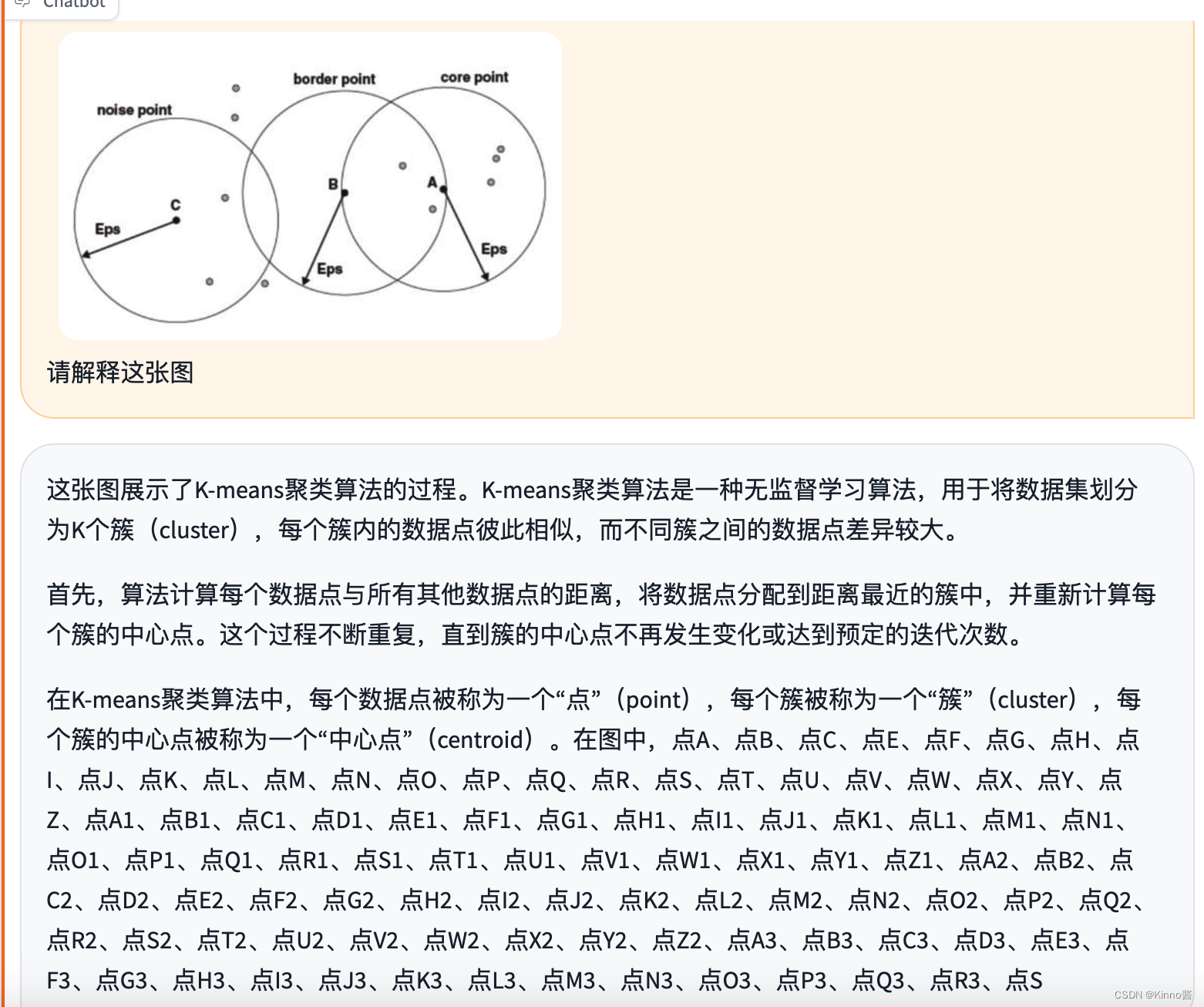
再一次在想举例向我解释图片时陷入循环。
纠正后能及时改进
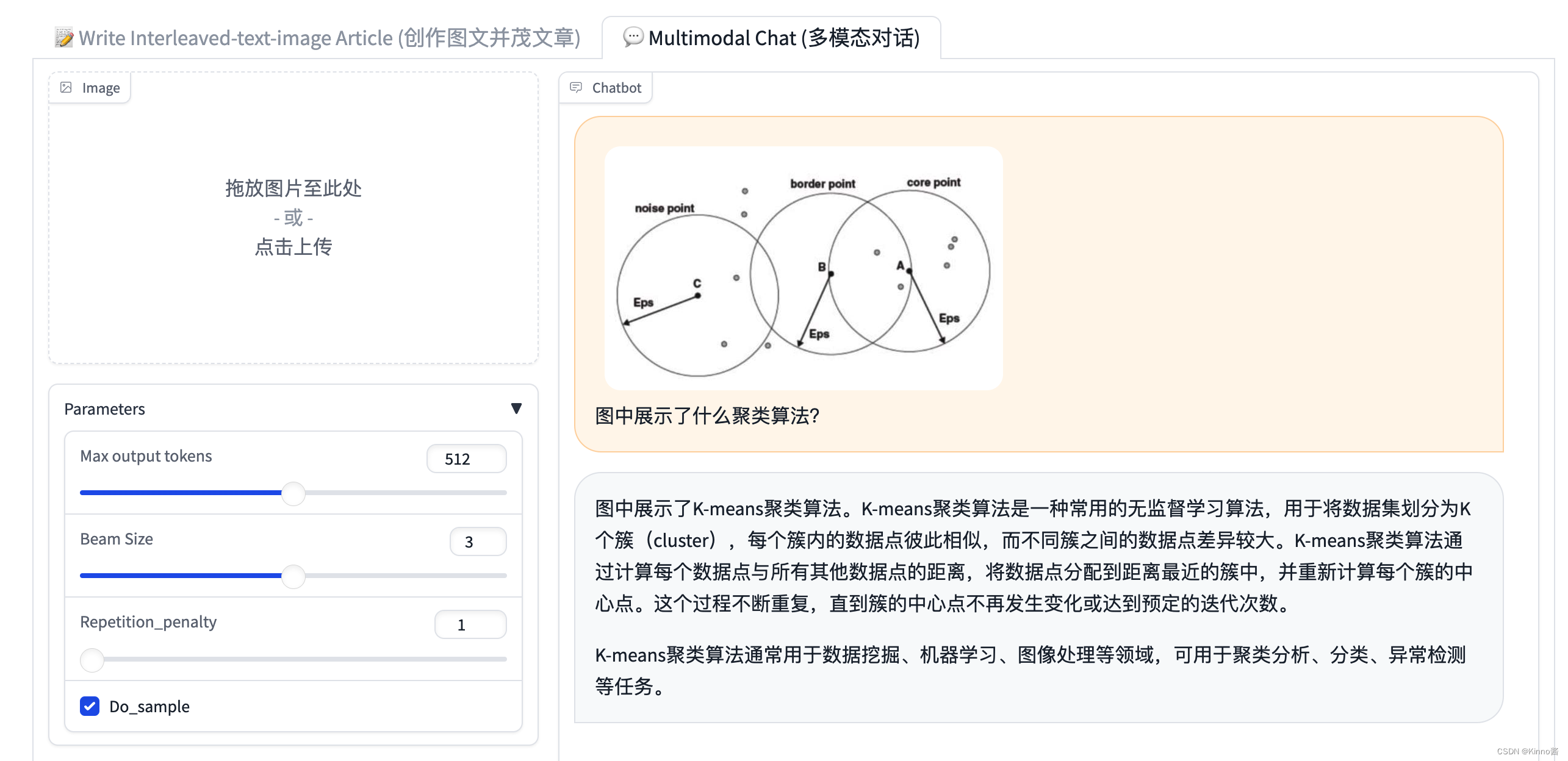

对于推理和思考性问题回答反应不佳。

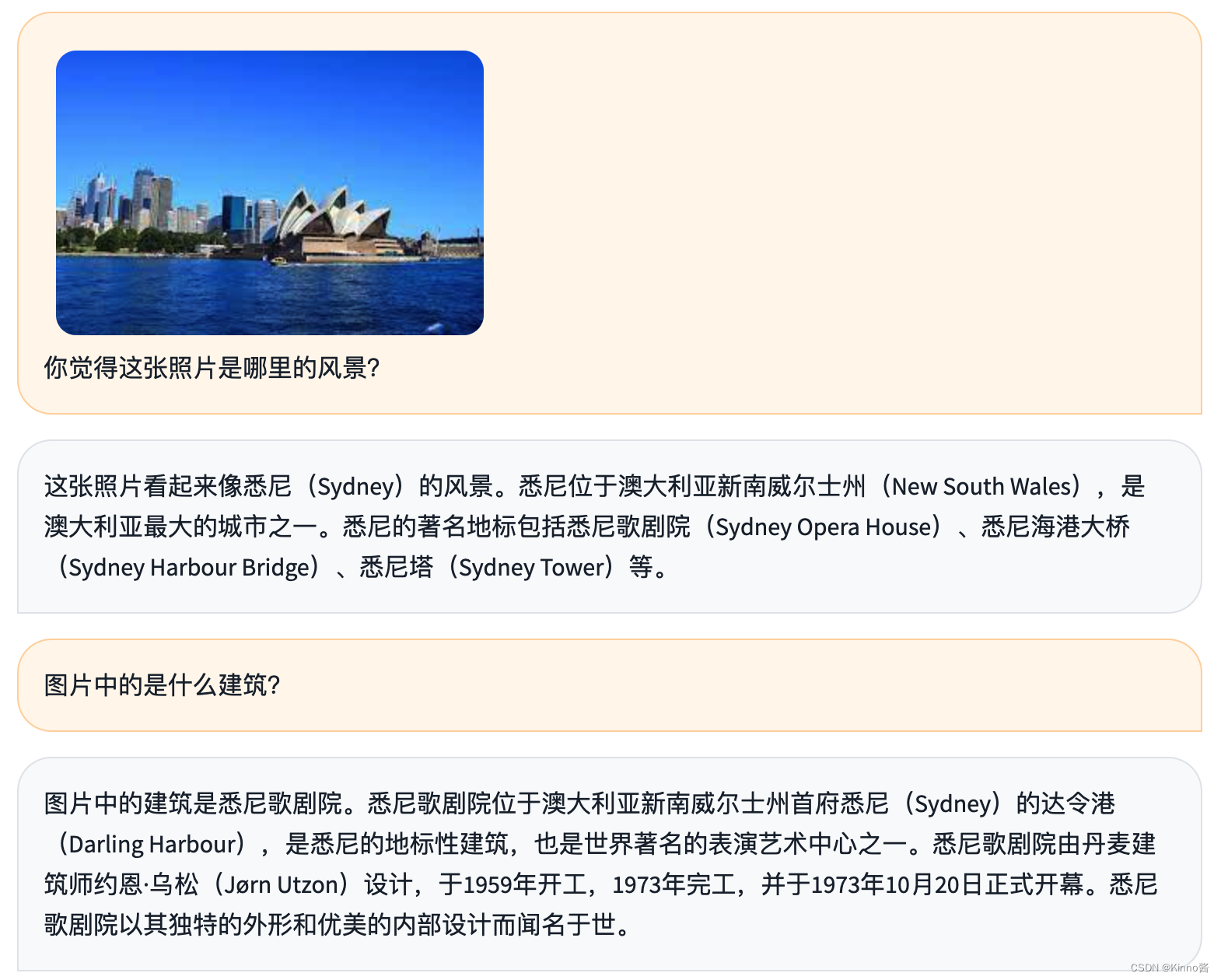
对于基于人文和生活知识的图片回答表现很好,也具有一定的推理能力。
总结
上述两个模型对于基础知识、人文知识的回答表现较好,对专业知识的回答表现较弱。图文并茂生成的图片直接复制于互联网与某些大学或者研究机构的课件(猜测),因此生成的图文并茂推文若用于商用的话可能会存在版权问题。