关键词
PS2汉化 汉化入门 汉化教程 PS2汉化教程
引语
之所以会想要写这个主要还是打算记录自己的探索历程。所以不知不觉就会写得不伦不类的。还希望各位能包涵一下。
其实oz大佬的教程里面提及的部分这里只是简单提了一句,因为觉得“既然已经有人写过了的话就没有必要再写一遍了吧。”
开始前的准备
工具
十六进制编辑器
较为熟悉的UltraEditor什么的就略过不提,这里推荐一款免费好用的编辑器wxMEdit。个人觉得非常方便。就是介面可能会过于简陋了一些。
反汇编·反编译软件
众所周知,PS2所用的处理器是异构的MIPS,称为Emotion Engine,不过,指令集被称为r5900。可以被设为大端或小端(默认小端)。而其启动文件则是标准的ELF文件格式。
不过,偷石吧东芝试图将这块芯片卖给其他客户(似乎失败了的样子),所以如果关心这款芯片的详情的话搜索它的别名TX79就能找到。包括详细的汇编指令表和VU的控制之类的东西都~有(要了解它的汇编的话这个是必须的),然而,需要注意的是,TX79和R5900的指令集并不完全相同,我目前有遇到的如:adda.s ei di 等指令并不一致,所以不能直接将二者等同。
因此,反汇编工具毫无疑问只有两个选择:IDA Pro(超贵)和radare2(免费)。需要注意 的是,IDA对r5900的支持要比radare2完善许多。目前,我为radare2写了一个r5900的反汇编插件(基于TX79指令集);当然,这个实现非常糟糕,很容易崩溃且有性能问题,所以使用前还请好好斟酌。另外,如果实在囊中羞涩,ps2dis也是个能勉强应付的工具。ps2dis是专为了ps2反汇编的工具,但是其操作逻辑非常令人难受(嗯,对我个人而言)。
此外,反编译工具只剩下一种选择——retdec。需要注意的是,不论是IDA上的还是R2上的retdec,它都旁路了IDA/R2的反汇编插件,而是完全自己分析指令,因此,对于使用了异构指令集的R5900来说,retdec反编译的结果只能用牛头不对马嘴来形容,请尽量避免使用。
汇编器·编译器
说到编译器当然得配置MIPS的gcc交叉编译环境,架构指定为r5900就好。请自行百度过程。
当然,也可以考虑官方/非官方的PS2SDK的编译环境。
不过,gcc编译出来的结果有些时候不能直接使用(毕竟修改程序是把程序段插入到原始的程序里,连接器什么的完全没用),所以还需要一个汇编器,来微调目标代码。这里推荐asm5900(当然理论上用十六进制编辑器手动输入机器码也是可以的)。
不过,asm5900的文档说明并不十分友好,所以用起来还是有点麻烦的。
字库查找、修改工具
CrystalTools。不二之选。
不过你可能也会需要
一些其他工具……
- CRI SDK for XBOX (2003):极其罕见的CRI官方SDK泄露(于2019年)。对于PS2时代(以及一些PS3时代)的游戏非常有用。它可以用于重新生成sfd视频,如果你在开头动画里看到了sofdec,adx,criware之类标志的话多半会需要它。2022更新:前段时间Wii的SDK公开泄露了(部分),新泄露的版本可以混流AC3音轨。如有必要请想办法弄到新的泄露。
- AFS Explorer : 探索AFS文件包(如果看到了*.afs的话你会需要的)
- ps2str : 用于重新生成ipu等一系列ps2专有格式文件(IPU什么的)(官方PS2SDK组件)
- Cube Media Player :支持许多ps2视频格式(而且能从各类(朴素的)文件包中撷取出音视频)
- Total Video Audio Converter : 音视频转码软件。支持的文件格式很多。
- IPUCONV : 从ipu文件转出(ps2str的素材处理是单向的,反向的处理要用到IPUCONV)
- iso文件部分替换工具 :比如apache。现在基本找不到类似工具了。不过就算自己写也不难。(避免重新生成iso浪费时间)。
- OPTPiX iMageStudio 的ps2专版。用于处理tim/tm2图片。(已知的泄露仅有一份,注意Windows 11上可能需要管理员权限才能正常运行)
- 其他各种专门工具(如.lzr, .pak, .pac之类的,你基本找不到原始工具,请发挥自己的逆向工程技能吧)
- 最新的ps2模拟器(测试时可能需要把EE和IOP调到解释器(就是那个“世界上最慢的东西”)
- 超好的电脑(能把pcsx2开到解释器运行的那种(呃……也没那么夸张啦……能跑起来就OK))
- 以上两项可以用PS2开发机(即TOOL,不是测试机哟)代替,不过那可能比新买一台电脑还要贵(上一次在某海鲜市场见到时,不包好坏的卖1500)
所需知识和品质
- MIPS汇编知识(还需额外了解R5900相关)
- C语言、C++语言
- 计算机科学基础知识(大小端、计算机内码等)
- ISO 9660 光碟文件系统知识
- ELF文件格式
- 耐心
*关于字库生成
首选Crystal Tools
生成非单色字库的话CrystalTiles就不大好用了,这个东西可能会更好些(注:位深度只有8位和32位,可能不适合大多数情况,你可能需要编写自己的减色程序来利用其输出结果):Bitmap Font Generator
这个也不错(位深度只有1,2和4):BitFontCreator Grayscale(更适合嵌入式设计。不过是要钱的,不过有21天试用
所以总而言之,最好的方法其实是自己实现ttf字体光栅化,github上是有现成的库的,直接拿来改改就能用了,毕竟各种游戏的字体或多或少都有些差异,不一定能在别人的程序里找到对应。
小结
要汉化游戏,至少需要准备字体查看器和生成器,还需要对字库相关的程序进行逆向(有时部分乃至全部的字库部分都可以当作黑盒,需要根据实际情况而定)。此外,寻找到游戏所用编码的映射也是很重要的(不过越是现代的游戏,使用自定义编码的几率也越小,基本都倾向于使用标准编码)。
正式开始汉化吧!
首先,我们先说说几个基本的汉化方法……
一力降十会
直接逆向破解整个游戏程序,把程序的一切看个清清楚楚、明明白白。绝对不会有解决不了的问题!大不了用C/C++直接重写一遍,甚至可以直接移植到Windows上!
当然,一般人可能还是得按下面的去做……
基本方法
接下来简要说明汉化的一般方法:
文本定位
首先,我们尝试定位一段文本,作为一切工作的突破口。
对文本进行定位的话,首先祈祷游戏使用的是标准编码(Shift-JIS,ASCII,BIG5之类的)。因为如果是这样的话会简单许多。
在游戏中运行直到出现文本,立即暂停游戏。
(可选) 然后试着把内存转储出来。这是为了之后寻找字库做准备。不过,由于最新版的PCSX2模拟器默认是禁用了内存转储功能,你可能需要从git仓库克隆代码自己编译来使内存转储功能可用。 你可能需要自己从古早版本复制代码到现在版本,并作修改以启用内存转储功能。
接下来,用十六进制编辑器打开游戏光盘镜像,全局搜索你看到的字符串,用各种可能的编码都试一试。
能找到的情况
如果能搜出来,那么恭喜!这是标准编码的游戏~无形中工作量大幅减轻了呢。
既然找到了文本,那么你也能确定游戏所用的编码了。接下来,为了验证自己的发现,改动这部分内容(最好能多改动一些)确认编码是否正确,以及厂商是否有自定义出一些编码。
接下来最简单最朴素的做法就是在文本附近找其他文本,这理应没有难度。然后用wqsg或者crystal script导出、导入文本就可以了。
不能找到的情况
先抱着侥幸心理,缩短字符串的长度,再试试能不能搜出来。因为文本可能仅仅只是被压缩了,改变搜索条件完全可能搜出来。(不过,既然是压缩了的文字,逆向就是必要的)
另外,如果是在搜索英文之类的语言,也请一并注意大写不一定是编码上大写,半角字符也不一定是半角编码。什么意思呢?也就是说,虽然屏幕上显示的是“ABCD”,但内部编码可能是“abcd”。此外,日文假名的浊点也不一定是单个字符,举例而言:显示成“が”的内部编码完全可以是“が”(这个浊点是U+FF9E)。
还是不行的话……
糟糕!居然是自定义编码!接下来只好祈祷差分搜索有效了。
差分搜索或称相对搜索、差值搜索,是根据字符间潜在的编码的差值进行搜索的方法。比如说,对于ASCII下“ABCD”就有差值序列“1,1,1”,那么就在文件中查找具有相同差值的序列。很明显,“BCDE”“CDEF”也符合这个序列,因此它们都会被搜索出来;这个时候,就需要耐心仔细地去排查。
需要小小提到一下的是,“ABCD”的差值是“1,1,1”只在编码是“将字符按字母表顺序排列”时成立,如果有个反人类开发商执意要逆序甚至乱序,差值序列实际上是“-1,-1,-1”甚至“12,-8,7”也不是没有可能。考虑到开发商不至于设计出太反人类的编码,“1,1,1”的可能性会大些。
从上面的例子可以看出,由于大小写字母的编码差值不能确定(如有的编码“Z”之后完全可能就直接是“a”),搜索大小写混合的字符串是要命的事情。同理可知,搜索假名的时候,由于不知道带浊点的假名是并在一起(如SJIS)还是专门存放,甚至“没有带浊点的假名,只有一个单独的浊点字符”,因此各种可能的差值都要试一试。
接下来,如果确定了这个文本的实在位置,那么就意味着你已经猜测了一部份的编码情况:比如,你可能已经依此确定了A的编码是01,B是02……这样。接下来,改动这里的数据,比如将“01 02 03 04”改为“05 06 07 08”继续猜测并确定游戏的编码,并将结果按照下面的格式保存下来:
【编码】=【字符】(可能像这样:)
01=A
02=B
03=C
...
25=Y
26=Z
27=a
...
8001=啊
8002=阿
...
这个,就是我们所称的码表,是描述字符和游戏编码对应关系的一系列键值对。一些常见的码表是从S-JIS,GBK等编码生成的。需要注意的是,码表请务必使用Unicode保存。任何无法生成Unicode码表的码表生成器都可以被抛弃掉了,因为S-JIS和GBK间存在不兼容的字符,如果一定用GBK(Windows下记事本称本地语言为ANSI)保存S-JIS会丢失信息,请千万不要这么做。
一个常见的造成数据丢失的例子是S-JIS下的中点0x8145"・"(用于译写英语人名等、姓名间的分隔符,用法有些类似中文的分隔符“·”,如“オリカ・ネストミル”)看上去很像“·”,但实际上在GBK中没有对应码位,生成器就无法以GBK保存信息;其结果就是信息丢失。
有了码表,接下来只要在全镜像范围找文本,然后用wqsg或者crystal tools导出导入文本就可以了。
还是找不到啊……
只好开始逆向之旅喽!如果能够在转储的内存里看到字库,试着下个内存断点吧。如果能断下来,就能沿着访问这个地址的代码顺藤摸瓜找到字模选取、编码处理乃至文件载入等一系列函数。那么这时剩下的也没什么难度了。
控制符的处理
有时你会发现在常规的文本中有一些无法显示的字节。比如,在可显示文字以ASCII编码的情况下,文本中间混入了一段不可打印字符,比如:“You, must be \x01\x02the chosen one\x01\x01.”这里的\x01显然不是SOH。这时,你就可以修改(比如删去,或者改动)这里的字符,并且在游戏中观察。然后,比如说,你发现了,\x01表示改变颜色,后面的那个字节就是颜色的代码。
现在的导出工具多半有为这种控制符作处理的工具:控制符表。请按着工具的说明登记好,因为不同的工具处理的方法不同,因此这里并不直接记叙工具的详细使用方法。
需要注意的是,并不是所有的厂商都会使用这种方式,尤其是较为现代的游戏,很少会使用不可显示的字符来作控制符之用,而可能会使用类似“<CL:BL>”、“CR”、“##”之类的序列来作为控制符。
举个例子:某厂商会将双字节字符作为显示字符,而ASCII作为控制符。比如对于“ううん…。CRあたしは…。”,CR会被处理成换行。
这种时候,并不建议将它们登记到控制符表中:因为这种情况下,直接保存为普通的文本,可能还比较易读些,举例而言,如果将CR登记为控制符,那么导出结果就可能像:“そうです{控制符:4352}…か。”或者另一些工具的:“そうです{控制符:CR}…か。”远不如直接保存为“そうですCR…か。”来得简单明了。此外,鲁莽地将“4352=CR”登记入控制符表也非常糟糕。因为此时你无法确认在其他的字符串中,CR是否有其他含义(当然,这只会造成阅读上的障碍,导入时是完全不会引发任何问题的)。
比如说,就在同个游戏,控制符#1指示后的文本是以ASCII存储的,那么如果之前贸然登记了CR为控制符,导出结果可能会变成:“{#1}{控制符:4352}ITICAL DOWN!{##}”(实际上CR在这里并不作为控制符)这就可能令翻译无所适从(什么是“ITICAL”?)。因此请务必仔细研究过游戏的控制符系统后,再做决定。(并且可能会需要自己实现导出导入处理)
有时为了让翻译能读得舒服,也可以考虑在导出后,对一些文本进行标记。并在导出后/导入前替换回导入导出器可以识别的形式。
导入导出器的用法
大多导入导出器都大同小异,指定码表/控制符表后,再指定清楚导入/导出的起讫地址,(有的导出器还支持过滤掉没有对齐(存储对齐,即开始地址为2^n的整倍数)的文本)接着按下“导出”键,导出器就会自动检索可能的文本并导出。
这个过程完全自动,因此会有些非文本数据混进来,形如“/a?[”之类的文本都是没有意义的(而且也无法翻译)因此可以直接删掉(即使不删掉,因为导入时也会原样导入所以不会造成问题)。有时,还会有些有错误的起始,如“29AC7,7,xヘルプ”,这时就需要将地址后移,长度改短,如:“29AC8,6,ヘルプ”,导出后请务必注意这一点。
找到了……之后呢?(数据结构逆向方法)
第一步也是找文本,推定编码,不过接下来我们就要做些有意思的事情。
总之,现在:恭喜你找到了文本!接下来观察一下这个文本所在的偏址。然后和ISO的文件分配表比对。确认文本的位置。大体上,我们可以将文本所在位置分为三类。
在主ELF中
也就是形如SLPS_256.04这样的文件。这个文件的文件名也被登记在system.cnf中,作为启动的指导。
如果确认文本在这里的话,修改难度较大,但也不一定非常困难。
理想的处理方式是:对于每一个文本,找到指向其的指针,并标记文本所占区段为“可用”,为文本编号,然后同时导出指针的地址(注意不是文本的地址)和文本及其编号。导出末了,将所有被标记为“可用”的区段也保存下来。导入的时候重新统计各个文本的长度,依次填入被标记为“可用”的区段中,同时更新所有的指针。
术语歧义与修正:在下面的图片中,“指针表”指“含有字符串指针的结构体数组”,与wqsg中的指针表概念并不一致(后文详述wqsg的指针表概念)。为做区分,之后将“含有字符串指针的结构体数组”称作数据表。
虽然我认为这是最理想的方式,但是如果无法找到所有的指针或是错误地将其他数据识别为指针,那么有些数据将被错误地更新或不被更新。这将导致乱码甚至是游戏崩溃(理论上很难出现,但实际上,如果改动的文本被游戏系统使用,就有可能出现这种问题,编译时如有后缀优化也可能导致问题(主要出现在将文件路径等数据一并纳入移位范围时))。因此工作量实际上非常巨大。此外,有些指针并不保存在数据段中,而是在代码段中作为立即数存在,因此,除了更新数据段外,还需要更新这些立即数指针。这可以通过反汇编、汇编实现,但也可以想见这么做的工作量。
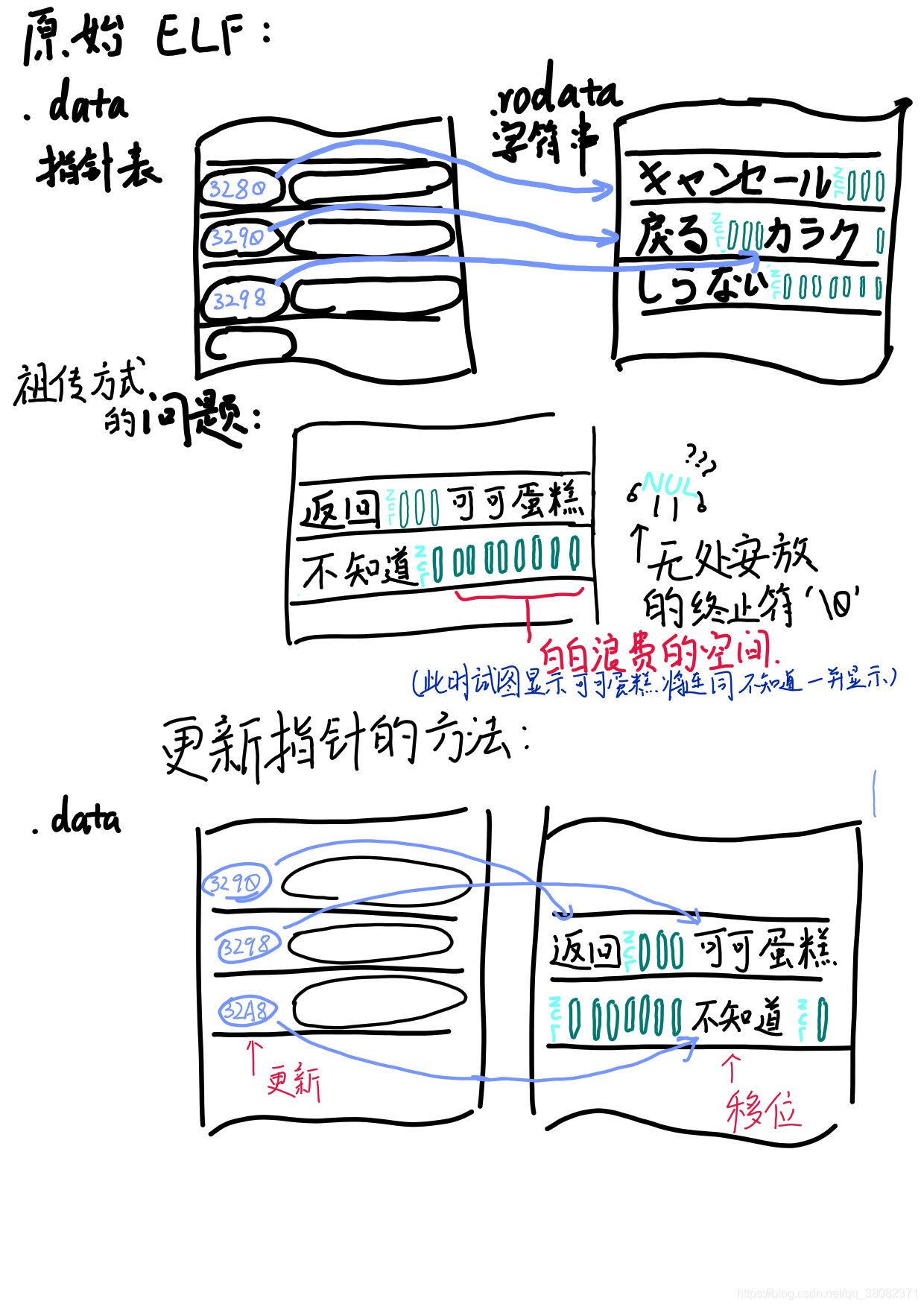
所以,还有一个折中的方法:将超长的文本移动到别的地方去,然后修改已知的指针。未知的指针仍然指向原位置,会显示成原文,因此发现此类问题时可以及时定位并修改。那么,“别的地方”是哪里呢?
就像字库那样的思路:首先查找没有的区域:当时游戏公司的开发习惯大多不好,很多废弃代码、数据遗留在ELF中,我们就可以鸠占鹊巢,往这些没用的数据上堆新的文本。
不过,有的时候可能会出现无论如何也放不下的情况,这个时候推荐对ELF进行扩容,并将内容放到那里去。(请注意这样做时一定要维护各个指针)这时,我们修改malloc()函数的起始点(一般指向ELF之PT_LOAD段尾部的主存地址),那么新的起始点和旧的起始点间的存储就能堆数据了,当然,要想让加载器把这些新数据从ELF加载到主存,我们也要修改ELF头,添加PT_LOAD段。
在ERX中
之前有说过什么是ERX吗?嗯?没有?好吧。
ERX是EE Relocatable eXecutable(即情感引擎可重定位可执行)的缩写。与之相对的是IRX(IOP Relocatable eXecutable)。不管怎样,这都相当于Windows中的DLL或Linux中的SO。
本质上依然是格式特殊的ELF文件,如果要对其反编译请确认指令集确实是r5900。
因为实际上就是ELF,因此主要的处理方法其实和主ELF没有区别(请参考上文)——依然是指针的处理或是传统的导出导入。
不过,有些厂商(GUST,说得就是你)的ERX可能是存粹的文本数据库,即,ERX里只有很少很小的函数,其作用就是返回给定id的字符串的地址。对于这样的ERX反汇编和反编译都很轻松。(关于ERX的编写编译等技术内容,请自行确认SDK文档)
由于部分ERX的结构非常简单,所以甚至有扩容的可能性。不过,如果对数据进行了移动,需要注意修改相应(甚至是所有)的.rel段,否则重链接会失败。此外,如果真的扩容了的话,也要注意修改程序头(Program header)确保新增的部分能载入到内存。当然,这种情况下,说不定直接用C重写ERX还会简单一些。
在其他数据文件中
真的是太幸运了!居然有单独的数据文件来存放脚本!这意味着(至少这部分)游戏引擎是依赖于“数据”运行的。也就是说我们可以简单地通过重新构建数据文件来实现对游戏文本的修改——而完全不需要改动游戏的代码!
这么做的优点是显而易见的:翻译的文本长度不再受原文长度限制!
而首先,我们需要先破解数据文件的结构。
通过文件结构分析
通过观察大量的类似文件,总结出文件数据结构。
优点是非常直观。而且不会因为游戏解析数据的函数过于晦涩而失败。
缺点也是显然的,那就是存在误分析的可能性。
比如说,因为看到大量数据文件的最后四个字节都是0,于是误以为数据文件的最后四个字节始终是0,然而这四个字节实际上是指示“此后还有X字节数据”用的。如果因此误分析,可能就会在利用到了这4个字节的数据文件中丢失掉大量数据。
黑盒分析
透过文件结构分析的时候,可以动手改动一部分数据,并观察程序是否能正常运行(以及结果是否符合预期)从而确定自己 的分析结果。
通过反汇编
通过找到ELF或是ERX中负责对数据文件解析的部分当然是最妙的!这使得我们有机会完全了解一个数据文件可能包含的部分,能够避免掉误将特殊结构当成一般结构分析的错误。而且,如果数据文件中存在什么控制符之类,这个过程也将使它们展露无遗。
缺点是:定位到相关函数比较困难。而且编译后的函数多半都比较难懂。
个人的例子
有的时候,这可能是更快的方法。比如,之前遇到的:GUST实现的对齐非常诡异(代码见下),而导致我一开始通过观察以为的“对齐”并不是按我所理解的那样运行。于是我的程序读取、写入数据文件时就会发生错误。
// GUST 的做法
inline int align(int val, int byte) // 也可能是宏
{
return (val < 0 ? val + byte - 1 : val) & ~(byte - 1); // 注意这里的小于关系和正常的实现相反(正负数判断错误)
}
// 其他某处
int aligned_length = align(length, 4) + 4; // 显然注意到了对齐变成了向下取整并做了该死的补救
于是乎,如果恰巧length能被4整除,这个例程计算出的aligned_length就比“一般的”对齐计算出的大4!正是这个偏差导致数据文件的生成异常。
不过,显然通过仔细的观察,应该也能发现这个问题。只“可惜”当时没有仔细检查,直接跑去翻汇编了……
编写拆包打包工具
然后根据你得出的文件结构编写工具拆包打包/导入导出吧。
对于实在找不到的时候
文本可能被加密/压缩。这个时候,只好检查各个数据文件,根据数据模式猜测哪些可能是文件包,用了哪些压缩手段。然后回到ELF里找读取函数,反汇编然后搞清楚究竟是什么。
关于反汇编有个小技巧,那就是SCEXXXSema这样的字符串。比如SCEOpenSema就是posix函数open()的底层实现。通过这个可以快速定位所有试图打开/读写/关闭文件的函数。此外,还可以用官方SDK编译一份hallo world(记得开-g3),然后就可以在反汇编里对比两边的代码,快速理清库函数,挑出游戏本身的函数!
重复验证
在导出文本之后,可以试着修改一些文本,并观察游戏显示,验证所用码表是否正确。同时也检查各个控制符的运作情况。
字库定位
首先双手合十,看看ISO目录下有冇叫做FNT.BIN/FNT.PAK/GAM.FNT之类的文件,如果有的话事情会简单许多。平常多做梦的话说不定还能看到ttf(想多了)。
如果没有的话,可以在ELF和ERX、IRX里面找找。
具体如何找呢?很简单,首先用Crystal tools打开文件。然后尝试所有的编码方式、图块大小。然后全文查找,找到就好了。
字库单独有数据文件的情况
分析数据结构,然后编写解/打包工具,大抵和上面文本数据文件的差不离多少。
好像没有诶?
那么就用 Crystal Tile 打开ELF或者ERX、IRX文件,逐个找找吧。
但是,通过屏幕上的像素数来确定字模像素数是不一定成功的。因为通常在显示前,字模会被缩放;所以只能赌运气。
基本上,只能靠着Crystal Tile一个个检查过去。一边检查一边祈祷自己这次的设置没错……运气好的话一次就找到,否则可能连着好几天都没有结果。
这部分oz大佬的文章已经写得很详细了。
怎么都找不到……
放心!不管如何字模不可能凭空冒出来。运行到游戏出现文字后,暂停游戏,把内存转储出来。然后在转储出的内存里面找。之后在对应内存地址下断点,终归能找到的。说不定还能顺藤摸瓜发现解密/解压函数呢(字库被加密的情况下)。
当然,另一个可能性是:字体程序根本不存在!
这是可能的,尤其是一些文本量低、或者是字体花俏的游戏,字体反而是不必要的东西。它们往往依靠着几张图片就能满足文字的显示需求。
当然,对于一些作品,以一张图片为字体也是可能的。
在以上两种情况,汉化工作的重心就在图片汉化和更困难的破解了。
由于图片形式的字体的实现相当自由,需要有一定的逆向工程经验才能确定相关例程并做出更改。因此请尽量寻求大佬的大腿抱(或者努力成为大腿,这只需要付出“一些”时间去钻研)。
好啦,逆向已经差不多了!
在上面的完成之后,详细你已经对游戏“如何存储文本”和“如何显示文本”有了一定的了解,并且已经可以修改字体、修改文本内容了,接下来,仔细测试所有的发现!
文本导入测试
首先按照已有的码表,按照之前讲述的方法修改一些文本,然后导入试试看有没有问题。
这个时期需要同时确认导出、导入工具的工作是否正常。
字库重生成测试
测试你的字库生成工具。确保其工作正常。游戏也能正常显示修改过的字库。
同时确定各部分是否正常。比如,如果为了保存更多的字对字库压缩了,或者是减色了而修改了游戏程序,这个时期也要同时测试修改过的字库和字库程序工作是否正常。任何会显示文字的地方都要确认一遍。错过这个时期,在之后再进行排错的工作量会非常可怖(主要是难以确定错误发生点)。
*字库重映射测试(部分需要
如果因为游戏只支持某种特定编码,那么为了表示汉字,必须对码点进行重映射。如果这样,映射关系是否正常也要及时确认。
这个时期可以先稍微尝试汉化一些无关紧要的提示信息(比如“请勿关闭电源”什么的),然后测试导入是否成功,游戏会否崩溃等。
贸然进入下一步很有可能导致一切重来。
在完成以上那些后,一部作品破解最关键的部分也就结束了。剩下的就是锦上添花——如果是文字为主的游戏的话。
图像、视频的定位、导出、标准化、重生成和导入及对应工具的测试
其实和上面讲述的方法没有太大区别呢。请一定细心而耐心哦。大多时候,你都可以用业已完成的工具或者SDK来对图片和视频进行修改。比如IPUConv; ps2str; OPTPiX等等等等。
所以,在这一步可以试着多上网找找资料,因为现在已经是2021年了,不少格式已经不是秘密。没有必要自己从头造轮子。
显然,这一个部分很难有什么通用的技巧,因为这是相当自由的部分,各个厂商基本都有对这类多媒体资产自成体系的处理方式。因此,如果某部作品的开发商还有一些其他的游戏,而且已被汉化(或者英化、俄化),可以联系那个游戏的汉化组/破解者寻求帮助。
另外,这里额外提供一个视频的汉化方法,或者说思路(因为视频格式往往极度复杂,不是简单就能分析出来的):无论怎样,游戏始终有渲染循环,即使播放影片时,渲染的任务移交给播放器依然有着渲染循环。因此,我们可以找到渲染循环的尾部,添加函数跳转,在视频的一帧显示之后,通过字库或者自己实现的方法,在画面缓冲区中绘制字幕,从而实现软字幕。当然这有点困难,但往往比弄清楚一种私有视频格式要来得容易。
此外一些小厂也有直接依赖官方工具链的。对于这种情况,由于格式广泛而很容易找到现成的轮子。(HFU啦、TIM啦、TM2啦、IPU啦……甚至MP3、WAV等等都有可能)
不过,对于多媒体的基础处理,大抵是压缩和打包。关于这点以后详述。
最后,测试工具链!
请确保工具链工作正常哦。否则之后的工作可能会打水漂的!
开始翻译
终于,破解的事情已经全部完成,将提取出的文本交给翻译吧。
如果文本的控制符颇多,可能还要为翻译们准备一个好用的编辑器呀。
导入并测试
翻译也结束了!接下来把游戏找人通几遍测试一下,修复发现的问题就完成啦!
发布补丁
除了PatchMaker之外,xdelta3也是个不错的二进制差分补丁工具,稍微推荐一下。
发布汉化的ISO
这里不是很推荐……因为整个ISO有点大了。
依然是推荐玩家自己从光盘上提取ISO然后打补丁会好些。
结语
不知不觉就写完了。最后几部分写得非常快,内容也很少,主要是因为方法和之前的都是大同小异的,所以也就没有展开写了。按照这个流程,绝大多数简单的游戏都可以被搞定的。总之就是这样啦。
嗯,又看了一遍,果然乱七八糟的……
附录、杂谈
文件包
一般文件包的头部都会描述文件包的内容。比如文件地址索引表,大小之类的东西。一般能够轻松找出来。
不过也可能分开来存放,比如专门一个文件用来存储索引表,另一个放数据的情况也不是没有。
此外也有把索引表直接塞进ELF里的情况(比如GUST)。
压缩文件、加密文件
如果碰到压缩文件,而且格式特殊就只好去找ELF/ERX中对应的解压解密函数。靠文件分析就能搞定的情况基本没有(例外是用了通用格式的,比如deflate、gz之类)。
加密文件复杂一些,因为真的上加密的游戏很少会搞出密钥泄露的蠢事(SCE除外)。除了暴力破解外,另一个思路是根据ELF中的算法解密所有的文件,然后旁路掉解密函数(或者为了减少异常,将解密函数改成空函数),使程序直接加载解密了的文件。之后用解密了的文件替换ISO内的原文件。
SFD
Sofdec的私有视频容器(实质是MPEG-PS,音频轨是adx,视频轨是m1v)。目前网络上除了Sega Dreamcast Movie Maker和PES Video Converter之外似乎并没有其他的工具。 还有CRI SDK/XBOX可用。这是CRIWARE为XBOX开发的工具。但是打包sfd的功能比Sega DC SDK 要好很多。虽然,XBOX的CRI SDK直到19年才泄露。这个SDK已知的小问题:不能混流AC3。
其中PES Video Converter可以从sfd中拆出音频轨sfa或adx。这样就可以用sega工具无损混流。 现在当然还是推荐更新的SDK,虽然手册没说,但其可以支持ADX的混流。
sega工具只支持混流m1v和sfa到sfd。其自带的压制功能不如不用。请尽量使用ffmpeg进行m1v的压制。
sfa
Sofdec的私有音频格式。是文件头特殊的ADX。
杂记
这家公司现在依然存在,并且多款知名游戏依然使用其音视频中间件。