这几天利用好好工作摸鱼的时间梳理了一遍 Zookeeper 相关的内容。今天就给大家分享一下我这几天摸鱼的成果,本文主要内容包括 Zookeeper的配置安装、基本命令和ava API 的使用以及Zookeeper内部数据的存储方式以及Znode的特点、Watch 机制的详细介绍,最后聊了一下Zookeeper的应用场景,通篇文章都是理论+图解+代码实操,坚持看完相信你肯定会有所收获。
1、安装和配置
1.1、首先下载安装包
#下载安装包
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.2/apache-zookeeper-3.9.2-bin.tar.gz
## 解压软件包
tar zxvf apache-zookeeper-3.9.2-bin.tar.gz
## 重命名后放到指定目录下
mv apache-zookeeper-3.9.2-bin zookeeper-3.9.2
mv zookeeper-3.9.2 /usr/local/ 这里按照习惯我放到了/usr/local 目录下了。
1.2、修改配置
官方文档连接: ZooKeeper: Because Coordinating Distributed Systems is a Zoo

这里我们参照官方文档上的说明 新建一个数据目录,然后修改zoo.cfg配置文件
这里解释一下几个参数:
tickTime: ZooKeeper使用的基本时间单位(毫秒)。它用于执行心跳,最小会话超时将是tickTime的两倍。
dataDir: 存储内存中数据快照的路径
clientPort: 监听客户端连接的端口 这里我是将原来的 文件复制了一份然后在原来的基础上修改,内容如下
[root@VM-4-9-centos zookeeper-3.9.2]# cat conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/zookeeper/data
# the port at which the clients will connect
clientPort=9009
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
keeper.jute.maxbuffer=104857600
[root@VM-4-9-centos zookeeper-3.9.2]# 需要注意的是 这里我将自己的端口改成了9009 大家可以自己设置
1.3、启动服务
启动服务和查看服务状态的命令主要有以下几个
# 启动 ZooKeeper 服务
./zkServer.sh start
# 查看 ZooKeeper 服务状态
./zkServer.sh status
# 停止 ZooKeeper 服务
./zkServer.sh stop
# 重启 ZooKeeper 服务
./zkServer.sh restart
命令实操:
[root@localhost zookeeper-3.9.2]# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.9.2/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@localhost zookeeper-3.9.2]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.9.2/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
[root@localhost zookeeper-3.9.2]# 2、客户端主要命令
2.1、连接客户端
# 格式 -server ip:port
/zkCli.sh -server 127.0.0.1:2181
# 断开连接
quit
连接成功的效果如下

2.2、CRUD命令
对于Zookeeper常用的命令 我梳理成了下面的一张表格,主要就以下几个
| 命令 | 释义 |
| create /node_path node_value | 创建节点 并在设置节点上的数值 |
| set /node_path node_value | 给/node_path 节点设置 值 |
| get /node_path node_value | 获取/node_path 节点的数值 |
| delete /node_path | 删除节点(单个节点) 节点下不能 有子节点 |
| deleteall /node_path | 删除节点(包括该节点下的子节点) |
| create -e /node_path | 创建临时节点 该节点只在当前会话中生效 |
| create -s /node_path | 创建顺序节点 |
我们登录到控制台,实操一下上面的命令
WatchedEvent state:SyncConnected type:None path:null zxid: -1
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] create /demo
Created /demo
[zk: localhost:2181(CONNECTED) 2] ls /
[demo, zookeeper]
[zk: localhost:2181(CONNECTED) 3] set /demo value
[zk: localhost:2181(CONNECTED) 4] get /demo
value
[zk: localhost:2181(CONNECTED) 5] delete /demo
[zk: localhost:2181(CONNECTED) 6] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 7] create /tom
Created /tom
[zk: localhost:2181(CONNECTED) 8] create /tom/jerry
Created /tom/jerry
[zk: localhost:2181(CONNECTED) 9] ls /
[tom, zookeeper]
[zk: localhost:2181(CONNECTED) 10]
[zk: localhost:2181(CONNECTED) 10] ls /tom
[jerry]
[zk: localhost:2181(CONNECTED) 11] delete /tom
Node not empty: /tom
[zk: localhost:2181(CONNECTED) 12] deleteall /tom
[zk: localhost:2181(CONNECTED) 13] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 14] 完整的命令大家可以参照官方文档:ZooKeeper: Because Coordinating Distributed Systems is a Zoo
3、Zookeeper数据模型
到这里大家可能并不太理解 Zookeeper 到底是怎么组织数据的,这里我们可以查看文档的数据模型章节

上面大概的意思就是
ZooKeeper 的命名空间是有一个层次结构的,类似分布式文件系统。唯一的区别是名称空间中的每个节点都可以有与其关联的数据以及子节点。这就类似在文件系统,它既是一个文件也是一个目录。到节点的路径总是斜杠分隔的路径。
支持所有的unicode字符,但是有几个比较特殊
1、空字符 (\u0000) 不能使用
2、\u0001 - \u001F and \u007F \u009F 、\ud800 - uF8FF, \uFFF0 - uFFFF这几个字符也不能使用
3、最后 zookeeper 作为保留令牌 也不能使用。
到这里我们就可以把 zookeeper中的数据模型理解成下图所示的样子

需要注意的是 每个节点上可以存放数据,但是数据大小不能超过1M。
4、Java API
前面我们知道了 Zookeeper 的数据组织形式 也知道了 基本的CRUD命令了,下面我们就来学习一个操作Zookeeper的Java API 首先 引入依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.9.2</version>
</dependency>
然后我们新建一个工程,测试代码如下
public class ZooKeeperPractice {
private static final int SESSION_TIMEOUT = 3000;
private static ZooKeeper zooKeeper;
public static void main(String[] args) {
try {
// 创建 ZooKeeper 实例
zooKeeper = new ZooKeeper("ip:port", SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("Watch event: " + event);
}
});
String path = "/myZnode"; // 节点路径
// String data = "Hello ZooKeeper"; // 节点数据
// 创建节点
// createNode(path, data);
// 获取节点数据
getNodeData(path);
// 删除节点
// deleteNode(path);
} catch (IOException | KeeperException | InterruptedException e) {
e.printStackTrace();
} finally {
try {
if (zooKeeper != null) {
zooKeeper.close();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private static void createNode(String path, String data) throws KeeperException, InterruptedException {
// 创建持久节点
String createdPath = zooKeeper.create(path, data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.err.println("Node created: " + createdPath);
}
private static void getNodeData(String path) throws KeeperException, InterruptedException {
byte[] data = zooKeeper.getData(path, false, null);
System.err.println("Node data: " + new String(data));
}
private static void deleteNode(String path) throws KeeperException, InterruptedException {
zooKeeper.delete(path, -1); // -1 表示删除最新版本的节点
System.err.println("Node deleted: " + path);
}
}
先将创建节点的代码注释放开,运行上述代码 我们即可查看zookeeper里面创建的节点和节点存储的数值了,接着getNodeData 方法可以获取该节点的数值。
5、Zookeeper的Watch机制
5.1、Watch机制概述
Zookeeper 的 Watch 机制主要是用于监控节点状态变化的机制。简而言之就是它允许客户端在zookeeper上注册某个节点的事件监听器,当该节点发生了变更的时候Zookeeper会通知到该客户端。 这个功能就很厉害了,我们先来做一个小案例,体会下这个过程,之后那你就能很快的理解这个机制的工作原理了
5.2、Watch机制原理
直接上代码。 首先我们编写一个类,这个类的功能是创建一个临时节点,并且隔段时间修改一次这个节点上存放的数值,最后等待一段时间后结束整个会话。相关代码如下
public class EventRegister {
private ZooKeeper zooKeeper;
private String eventNodePath;
public EventRegister(String zkAddr, String eventNodePath) throws IOException {
this.zooKeeper = new ZooKeeper(zkAddr, 3000, null);
this.eventNodePath = eventNodePath;
}
// 注册事件
public void registerEvent(String eventData) {
try {
String createdPath = zooKeeper.create(eventNodePath, eventData.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("Event registered at path: " + createdPath);
} catch (Exception e) {
e.printStackTrace();
}
}
// 修改节点的值
public void updateServiceData(String newServiceData) {
try {
zooKeeper.setData(eventNodePath, newServiceData.getBytes(), -1);
System.out.println("Service data updated to: " + newServiceData);
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
// 关闭 ZooKeeper 连接
public void close() {
try {
zooKeeper.close();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String zkAddr = "ip:port"; //修改成自己的ip和端口
String eventNodePath = "/test_node";
// 事件数据
try {
// 创建注册器并注册事件
EventRegister eventRegister = new EventRegister(zkAddr, eventNodePath);
eventRegister.registerEvent("hi i'm tom" );
System.out.println("Event registration completed.");
//模拟10s后修改节点数据
Thread.sleep(10000);
eventRegister.updateServiceData("fuck i'm jerry");
//模拟2后修改节点数据
Thread.sleep(4000);
eventRegister.updateServiceData("你们见鬼去吧 ");
//30后下线
Thread.sleep(30000);
// 关闭连接
eventRegister.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
接着我们还需要一个Watcher监听类,这个类需要实现的功能是监听上面创建的临时节点,每当节点的值发生了变更后zookeeper就会下发通知,接着就重新获取该节点的值,相关代码如下
public class EventListener implements Watcher {
private ZooKeeper zooKeeper;
private String eventNodePath;
public EventListener(String zkAddr, String eventNodePath) throws IOException {
this.zooKeeper = new ZooKeeper(zkAddr, 3000, this);
this.eventNodePath = eventNodePath;
// 初始时设置 watcher
watchEventNode();
}
// 处理事件
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
System.out.println("服务下线了: " + eventNodePath);
} else if (event.getType() == Event.EventType.NodeDataChanged) {
System.out.println("服务变更了: " + eventNodePath);
}
// 重新设置 watcher
watchEventNode();
}
// 监视事件节点
private void watchEventNode() {
try {
byte[] data = zooKeeper.getData(eventNodePath, this, null);
System.out.println("节点中最新版本的数据内容: " + new String(data));
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 关闭 ZooKeeper 连接
public void close() {
try {
zooKeeper.close();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String zkAddr = "ip:port"; //修改成自己的ip和端口
String eventNodePath = "/test_node"; // 事件节点路径
// 创建并启动监听器
try {
EventListener eventListener = new EventListener(zkAddr, eventNodePath);
// 模拟事件监听一段时间
Thread.sleep(10000000);
// 关闭连接
eventListener.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
完成上述代码后,我们先启动 EventRegister,等待 2s 后再启动 EventListener 然后观察他们的控制台的输出。
我们查看上述控制台的信息,发现每一次test_node上的数据的变更zookeeper都会通知EventListener,并且EventListener也能获取到最新的值,EventRegister会话结束后临时节点被删除也能感知到。到这里相信你已经理解了这种机制了。Zookeeper 之所以被广泛的应用就是因为他的这个特有的机制。
相信大家很容易就理解了上面的这个小案例的代码,不过这里我还是推荐大家去看看官方文档上给出的案例,相信你肯定会有更深刻的理解 地址: zookeeper.apache.org/doc/current…
6、Zookeeper 的应用场景
从上面的案例中我们可以知道 Zookeeper 的监听机制大致的工作流程,这里给大家梳理成2张图


上面两张图就是Zookeeper的Watch机制的流程了。那么基于这种机制我们就可以好好聊聊 zookeeper的应用场景了
6.1 分布式配置中心
假设我们有一个应用,服务端是由3个服务节点组成的集群,某一天我们需要修改服务端的某项配置的时候,我们需要 分别在3个节点上修改,假如后期应用体量变大了 服务端需要扩容,增加到了100个节点,那我们想修改某个配置的时候 就需要去修改100个节点,想想就头皮发麻。这个时候我们就可以使用 Zookeeper 来管理这些配置了
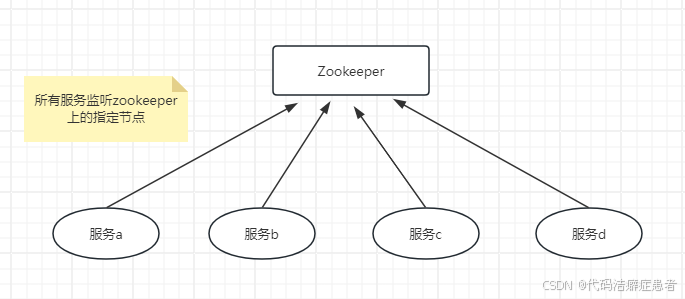

6.2、统一集群管理
在一个服务端集群的环境中 我们需要实时的掌握每个服务的状态,当某个节点发生了变更或者故障的时候我们要能及时的发现并作出对应的措施,这个时候我们同样的也可以使用Zookeeper来实现。实现步骤也很简单,如下图所示

每个服务启动的时候向zookeeper注册一个临时节点,监控服务分别监听所有服务的节点,当某个节点发生了故障断开会话,这个时候它所对应的临时节点就不存在了。这个时候Zookeeper就会通知监控中心,我们就能捕获到异常的服务了。
6.3、服务注册中心
这个相信大家对注册中心都不陌生,早些年 Zookeeper 配合 Dubbo 构建分布式系统有很多成功的案例, 同样的Zookeeper作为服务注册中心的原理也是类似的,服务提供者将自己的服务地址、方法签名存到Zookeeper上指定的节点,服务消费者从这个节点上拉取服务提供者的元信息,进行远程调用。当某个服务挂掉了,Zookeeper就会通知监控中心。
6.4、分布式锁
在分布式环境中如果多个服务实例需要访问 某个共享资源,这个时候我们就需要引入分布式锁了,同样的Zookeeper也是一个不错的选择。实现原理是临时顺序节点+watch机制。还记得主要命令的那个章节里介绍的 临时节点和顺序节点吗,同样的其实还有一个临时顺序节点,他就是分布式锁的最佳实践。 直接上代码吧
public class DistributedLock implements Watcher {
private static final String LOCK_NODE = "/lock"; // 锁节点
private final ZooKeeper zooKeeper;
private String lockId; // 当前实例的锁节点 ID
public DistributedLock(String zkHost) throws IOException {
this.zooKeeper = new ZooKeeper(zkHost, 3000, this);
}
@Override
public void process(WatchedEvent event) {
// 处理事件(可根据需要实现)
}
public boolean lock() throws KeeperException, InterruptedException {
// 创建临时顺序节点
lockId = zooKeeper.create(LOCK_NODE + "/lock-", new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 检查是否为最小节点
return tryLock();
}
// 尝试获取锁
private boolean tryLock() throws KeeperException, InterruptedException {
// 获取当前锁节点的所有子节点
List<String> children = zooKeeper.getChildren(LOCK_NODE, false);
if (children.isEmpty()) {
return true; // 成功获取锁
}
// 检查自己是否为最小节点
String minNode = getMinNode(children);
return minNode != null && lockId.equals(LOCK_NODE + "/" + minNode);
}
// 获取最小的节点名称
private String getMinNode(List<String> children) {
return children.stream()
.sorted() // 按节点名称排序
.findFirst()
.orElse(null);
}
// 释放锁
public void unlock() throws KeeperException, InterruptedException {
if (lockId != null) {
zooKeeper.delete(lockId, -1);
lockId = null; // 清空锁 ID
}
}
public void close() throws InterruptedException {
zooKeeper.close();
}
}
相比长篇大论的文字,相信大家肯定觉得还是代码好理解,上面的代码就是 在Zookeeper的/lock 节点下创建一个临时的顺序节点,当有一次请求过来的时候就会新创建一个节点,然后判断自己的节点是不是顺序值最小的。如果是就算是获取到了锁,处理完后业务逻辑后,就将该节点删掉也就是释放了锁。后面的请求进来了也是同样的判断。 下面再来写一段测试一下这个过程
@RestController
public class UserInfoController {
private final DistributedLock distributedLock;
public UserInfoController(DistributedLock distributedLock) {
this.distributedLock = distributedLock;
}
@RequestMapping("/getUserInfo")
public Map getUserInfo() throws InterruptedException, KeeperException {
Map jerry = new HashMap<String, Object>();
String msg = "";
if (distributedLock.lock()) {
msg = "当前线程: " + Thread.currentThread().getId() + " 获取到锁";
try {
jerry.put("name", Thread.currentThread().getName());
jerry.put("age", 18);
jerry.put("sex", "男");
jerry.put("address", "深圳");
} finally {
distributedLock.unlock();
}
} else
msg = "当前线程: " + Thread.currentThread().getName() + " 没有获取到锁";
jerry.put("msg", msg);
return jerry;
}
}
@SpringBootApplication
public class JerryStoreApplication {
public static void main(String[] args) {
SpringApplication.run(JerryStoreApplication.class, args);
System.out.println("jerry-store started");
}
@Bean
public DistributedLock distributedLock() throws IOException {
return new DistributedLock("ip:port");
}
}
然后我们可以利用jemter工具 进行测试 就能看到明显的过程了。
7、总结
本文从Zookeeper安装开始,由基础命令、JavaAPI的使用逐步过渡到Zookeeper的监听机制的特性,然后又通过多个代码示例讲解了 Zookeeper怎么实现分布式配置中心、统一集群管理和服务注册中心的,最后又通过临时顺序节点和Watch机制实现了一个简单的分布式锁。
到这里你肯定已经对Zookeeper 有了一定的认知了,假设面试官问你 有没有用过Zookeeper 之类的问题 相信你肯定知道怎么去回答了。甚至可以按照本文的脉络去回答 它是什么,怎么用、能做什么,具体怎么去落地的大致流程了。