文章目录
前言
随着深度学习的发展,推荐系统中开始越来越多地用到深度学习。本篇博文介绍推荐系统中常见的深度学习模型,如DNN模型、ESMM模型、Wide & Deep模型、Deep & Cross模型和DIN模型。
一、DNN 模型
深度神经网络(Deep Neural Network, DNN)是经典的深度神经网络模型,也叫做多层感知机(Multilayer Perceptron, MLP). 最早的DNN模型来自最原始的神经网络模型隐藏层的多层叠加。网络中的激活函数可以查看这篇博文来了解。
下面简单谈谈DNN模型的优缺点:
- 深度神经网络模型对于非线性问题的处理具有优势;
- DNN模型对于特征与训练目标间的关系并不清晰的情况下的高维度特征的提取具有更大的优势,并且优于树模型、FM家族模型;
- 对类别特征的支持不好,随着类别特征的增多,甚至可能会出现维度爆炸的情况;
- 对系统算力要求较高。为了更好地提取高维度特征,模型的深度可能会使算力不足的问题进一步加剧;
- 可解释性差,随着隐藏层的增多,评估不同特征对模型的影响变得尤为困难。
二、Wide & Deep 模型
Google算法团队于 2016 年在文章《Wide & Deep Learning for Recommender Systems》首次提出Wide & Deep模型,其核心思想是结合线性模型的记忆能力和 DNN 模型的泛化能力,在训练过程中同时优化两个模型的参数,从而达到整体模型的预测能力最优。
与广义的搜索排序问题一样,推荐系统也面临这样一个挑战:如何同时实现记忆与泛化(Memorization and Generalization)。记忆可理解为:学习并利用历史数据中的高频共现物体或特征所具有的关系。而泛化则指这一关系的转移能力,以及发现在历史数据中罕见或未曾出现过的新的特征组合。基于记忆的推荐通常更集中于用户历史行为所涵盖的特定主题,而基于泛化的推荐会倾向于提升推荐物品的多样性。
在工业界的大规模线上推荐和排序系统中,广义线性模型如逻辑回归被广泛应用,因为它们简单、可扩展(scalable)且具有可解释性。这些模型常常基于独热编码(one-hot encoding)的二进制化的稀疏特征进行训练。但常常是需要手工做特征工程的。外积变换的一个局限是,它无法对训练集中未出现过的“查询-物品特征对”进行泛化。基于嵌入技术的模型,如因子分解机FM、深度神经网络等,可对未见过的“查询-物品特征对”进行泛化,这是通过对一个低维稠密嵌入向量的学习来实现的,且这种模型依赖于较少的特征工程。然而,在“查询-物品矩阵”是稀疏、高维的时候,其低维表示是难以有效学习的。
Google算法团队提出的Wide & Deep学习框架在一个模型中同时达到记忆和泛化,这是通过协同训练一个线性模型模块和一个神经网络模块完成的。模型结构示意图如下:
wide &deep模型旨在使得训练得到的模型能够同时获得记忆和泛化的能力:
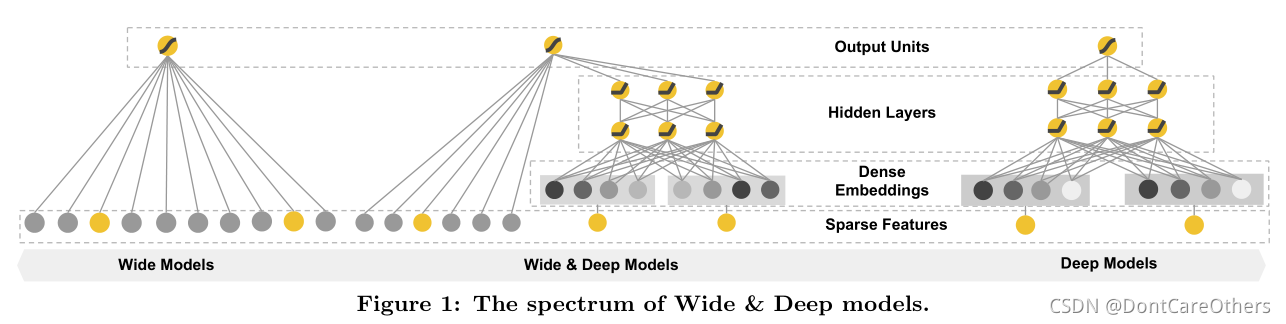
**记忆(memorization):**即从历史数据中发现item或者特征之间的相关性。这里通过大量的特征交叉产生特征交互作用的“记忆”,高效且可解释。但要泛化需要更多的特征工程。
**泛化(generalization):**即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。这里通过Embedding的方法,使用低维稠密特征的输入,可以更好的泛化训练样本中未出现的交叉特征。
wide模块和deep模块的组合依赖于对其输出的对数几率(log odds)的加权求和作为预测,随后这一预测值被输入到一个一般逻辑损失函数(logistic loss function)中进行联合训练。对Wide&Deep模型的联合训练通过同时对输出向模型的wide和deep两部分进行梯度的反向传播(back propagating)来实现的,这其中应用了小批量随机优化(mini-batch stochastic optimization)的技术。在实验中,作者使用了FTRL(Follow-the-regularized-leader)算法以及使用正则化来优化wide部分的模型,并使用AdaGrad优化deep部分。
参考资料:
- Wide&Deep论文 全文下载链接
- 论文阅读:Wide & Deep Learning for Recommender Systems
- 深度模型(八):Wide And Deep
- Wide & Deep模型的理解及实战(Tensorflow)
三、Deep & Cross 模型
Deep & Cross Network(DCN)是2017年由斯坦福与Google联合提出,其主要目的是解决“Wide & Deep模型的Wide部分的特征交互需要特征工程,而手工设计特征工程非常的繁琐”的问题。作者对Wide部分进行更改,提出了一个Cross Network来自动进行特征之间的交叉,以减少人工特征工程的繁琐工作,cross network能有效的学习bounded-degree的特征交互,且每一层都实现feature crossing,且时间复杂度和空间复杂度都是线性的,参数量较DNN而言少近一个数量级。
一个DCN模型从嵌入和堆积层开始,接着是一个交叉网络和一个与之平行的深度网络,之后是最后的组合层,它结合了两个网络的输出。完整的网络模型如下图所示:
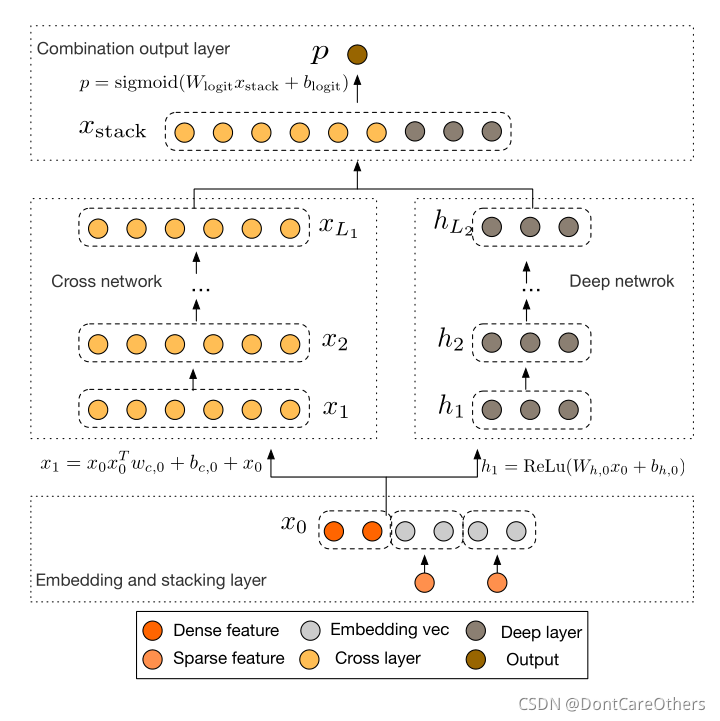
3.1 嵌入与堆叠层
对于类别特征One-Hot处理后引起的高维特征的问题,DCN对类别特征采取嵌入的方法,将这些二进制特征转换成实数值的嵌入向量,之后将得到的嵌入向量与归一化后的连续特征叠加起来得到输入特征向量
x
e
m
b
e
d
,
i
=
W
e
m
b
e
d
,
i
x
i
x_{embed,i} = W_{embed,i}x_i
xembed,i=Wembed,ixi
x
0
=
[
x
e
m
b
e
d
,
1
T
,
x
e
m
b
e
d
,
2
T
,
.
.
.
,
x
e
m
b
e
d
,
k
T
,
x
d
e
n
s
e
T
]
x_0 = [x_{embed,1}^T,x_{embed,2}^T,...,x_{embed,k}^T,x_{dense}^T]
x0=[xembed,1T,xembed,2T,...,xembed,kT,xdenseT]
其中
x
i
x_i
xi是第
i
i
i层的二元输入,
W
e
m
b
e
d
,
i
∈
R
n
e
×
n
v
W_{embed,i} \in R^{n_e \times n_v}
Wembed,i∈Rne×nv是与网络中其他参数一起优化的相应的嵌入矩阵,
n
e
,
n
v
n_e,n_v
ne,nv分别是嵌入大小和词汇大小,
x
e
m
b
e
d
,
i
x_{embed,i}
xembed,i是嵌入向量(实质上就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的Embedding向量),
x
d
e
n
s
e
T
x_{dense}^T
xdenseT是归一化后的连续特征向量,
x
0
x_0
x0就是网络的输入特征。
总结:
- 对sparse特征进行embedding,对于multi-hot的sparse特征,embedding之后再做一个简单的average pooling;
- 对dense特征归一化,然后和embedding特征拼接,作为随后Cross层与Deep层的共同输入。
3.2 交叉网络
交叉网络的核心思想是以有效的方式应用显式特征交叉,以此增加特征之间的交互力度。交叉网络由交叉层组成,每个层具有以下公式:
x
l
+
1
=
x
0
x
l
T
w
l
+
b
l
+
x
l
=
f
(
x
l
,
w
l
,
b
l
)
+
x
l
x_{l+1}=x_0 x_l^T w_l + b_l + x_l = f(x_l,w_l,b_l) + x_l
xl+1=x0xlTwl+bl+xl=f(xl,wl,bl)+xl 其中,
x
l
,
x
l
+
1
∈
R
d
x_l, x_{l+1} \in R^d
xl,xl+1∈Rd表示
l
l
l层和
l
+
1
l+1
l+1层的输入列向量,
w
l
,
b
l
∈
R
d
w_l, b_l \in R^d
wl,bl∈Rd为第
l
l
l层的权重和偏置。每个交叉层在特征交叉
f
f
f后加回其输入。映射函数
f
f
f拟合残差
x
l
+
1
−
x
l
x_{l+1}-x_l
xl+1−xl。一个交叉层的可视化如下图所示:
交叉网络的特殊结构使交叉特征的程度随着层深度的增加而增大。交叉网络的精妙之处可以参考这篇文章。
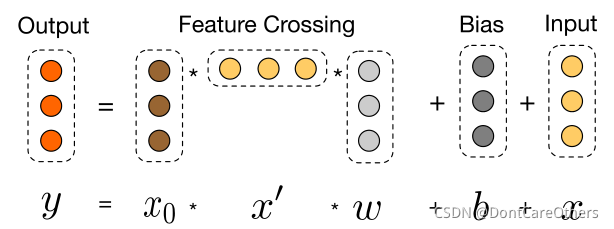
总结:
- 每层的神经元个数都相同,都等于输入 x 0 x_0 x0的维度 d d d ,也即每层的输入输出维度都是相等的;
- 受残差网络结构启发,每层的函数 f f f拟合的是 x l + 1 − x l x_l+1-x_l xl+1−xl的残差,残差网络有很多优点,其中一点是处理梯度消失的问题,使网络可以“更深”.
3.3 深度网络
深度网络就是一个全连接的前馈神经网络,每个深度层具有如下公式:
h
l
+
1
=
f
(
W
l
h
l
+
b
l
)
h_{l+1} = f(W_l h_l + b_l)
hl+1=f(Wlhl+bl) 其中
f
f
f为ReLU激活函数。
3.4 融合层
融合层链接两个网络并将连接向量输入到标准的逻辑回归函数中进行预测
p
=
σ
(
[
x
L
1
T
,
h
L
2
T
]
w
l
o
g
i
t
s
)
p = \sigma([x_{L1}^T, h_{L2}^T]w_{logits})
p=σ([xL1T,hL2T]wlogits) 其中,
x
L
1
∈
R
d
,
h
L
2
∈
R
m
x_{L1} \in R^d, h_{L2} \in R^m
xL1∈Rd,hL2∈Rm分别为cross网络和deep网络的输出,
w
∈
R
(
d
+
m
)
w \in R^{(d+m)}
w∈R(d+m)为融合层权重。
最后,二分类问题的损失函数为
l
o
s
s
=
−
1
N
∑
i
=
1
N
⟮
y
i
l
o
g
(
p
i
)
+
(
1
−
y
i
)
l
o
g
(
1
−
p
i
)
⟯
+
λ
∑
l
∥
w
l
∥
2
loss = -\frac{1}{N} \sum\limits_{i=1}^{N} \lgroup y_i log(p_i) + (1-y_i)log(1-p_i) \rgroup + \lambda \sum\limits_{l} \| w_l\|^2
loss=−N1i=1∑N⟮yilog(pi)+(1−yi)log(1−pi)⟯+λl∑∥wl∥2
总结:
- DCN结构中的Cross可以显示、自动地构造有限高阶的特征叉乘,从而在一定程度上告别人工特征叉乘(说一定程度是因为文中出于模型复杂度的考虑,仍是仅对sparse特征对应的embedding作自动叉乘,但这仍是一个有益的创新);
- Cross部分的复杂度与输入维度呈线性关系,相比DNN非常节约内存。实验结果显示了DCN的有效性,DCN用更少的参数取得比DNN更好的效果。
参考资料:
- Deep & Cross论文 全文下载链接
- 论文阅读:Deep & Cross Network for Ad Click Predictions
- 揭秘 Deep & Cross : 如何自动构造高阶交叉特征
四、DIN 模型
深度兴趣网络(Deep Interest Network, DIN)模型是阿里妈妈的精准定向检索及基础算法团队于2017年6月提出的,它针对电子商务领域(e-commerce industry)的CTR预估。
4.1 提出背景
用户在访问电商网站时,会表现出兴趣的多样性。但用户是否点击当前的商品或广告,很大程度上依赖于其历史行为,并且仅仅取决于历史行为中的一小部分。而在之前如Wide & Deep、DeepFM之类的CTR预估模型中,首先学习各个特征的embedding表示,将高维度稀疏数据转换为低维度的向量表示,然后学习低维的特征交互和高维的非线性关系,即Sparse Features -> Embedding Vector -> MLPs -> Output。但是这些研究没有针对用户历史行为特征进行建模。
阿里对于之前用户兴趣类算法给出了一个基本的模型,也就说在DIN之前,所有和用户兴趣相关的CTR预估模型都可以归结为这个基本模型。在基本模型中,可以大概分为Embedding层、Pooling和Concat层、全连接层、输出层四部分。
在基线模型中,输入的embedding为所有历史商品信息的综合表达,和当前候选广告商品交互。但是之前提过用户是否点击当前的商品或广告仅仅取决于历史行为中的一小部分,如果综合考虑所有历史信息会引入噪声。因此DIN模型在当前候选广告和用户行为之间引入注意力机制,让模型更关注和当前候选广告更相关的用户历史行为(根据当前的候选广告,来反向的激活用户历史的兴趣爱好,赋予不同历史行为不同的权重)。
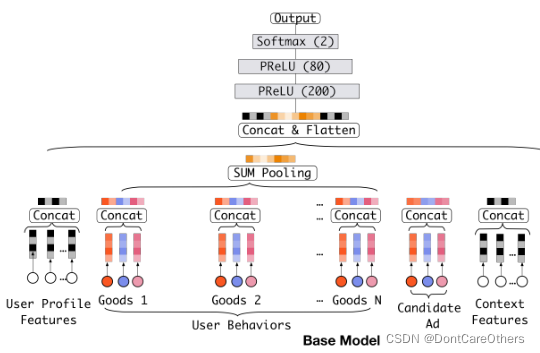
4.2 DIN 模型结构
针对互联网电子商务领域的数据特点:用户的兴趣非常的广泛(Diversity)和用户是否会点击推荐给他的商品,仅仅取决于历史行为数据中的一小部分,而不是全部(Local Activation),DIN给出了解决方案:
- 使用用户兴趣分布来表示用户多种多样的兴趣爱好;
- 使用Attention机制来实现Local Activation;
- 针对模型训练,提出了Dice激活函数,自适应正则,显著提升了模型性能与收敛速度。
DIN模型结构如下图所示:
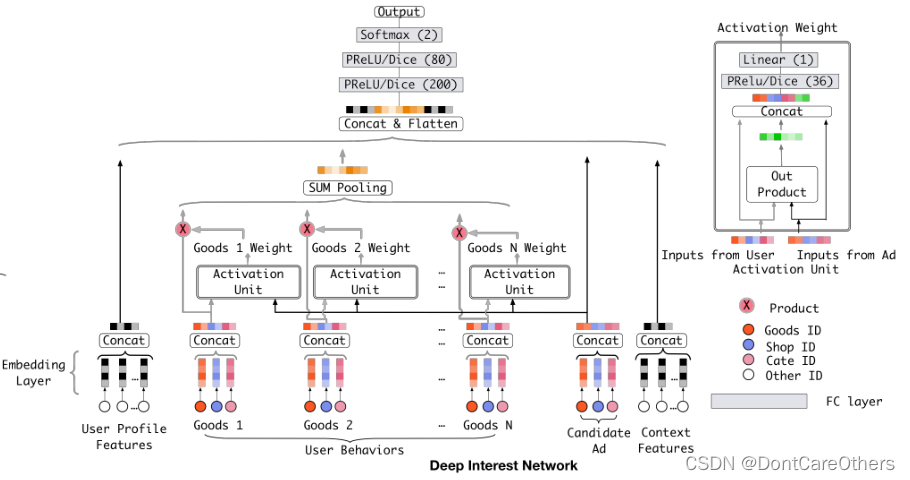
4.3 用户兴趣与注意力机制
用户Embedding Vector的维度为 k k k,它最多表示 k k k个相互独立的兴趣爱好。但是用户的兴趣爱好远远不止 k k k个,怎么办?DIN给出的方案是:用户的兴趣不是一个点,而是一个多峰的函数。一个峰就表示一个兴趣,峰值的大小表示兴趣强度。(这样即使在低维空间,也可以获得几乎无限强的表达能力。)那么针对不同的候选广告,用户的兴趣强度是不同的,也就是说随着候选广告的变化,用户的兴趣强度不断在变化。也就是说,同意用户针对不同的广告有不同的用户兴趣表示(嵌入向量不同)。
DIN在Embedding层和Pooling层之间加入Activation Unit(兴趣激活模块)赋予不同的历史行为不同的权重,得到对应的用户兴趣表示。Activation Unit的输入为用户的历史商品和当前候选商品,输出为两者之间的相关性作为历史商品的权重,将这个权重和原来历史行为的embedding结果相乘并求和,得到用户的兴趣表示。
Activation Unit用预估目标(候选广告/商品)的信息去激活用户的历史点击商品/店铺,以此提取用户与当前预估目标相关的兴趣。权重高的历史行为表明这部分兴趣和当前广告相关,权重低的则是和广告无关的“兴趣噪声”。我们通过将激活的商品和激活权重相乘,然后累加起来作为当前预估目标相关的兴趣状态表达。最后我们将这相关的兴趣表达、用户静态特征和上下文相关特征,以及ad相关的特征拼接起来,输入到后续的多层DNN网络,最后预测得到用户对于当前目标的点击概率。
加入Activation Unit后,用户的兴趣表示计算如下:
v
U
(
A
)
=
f
(
v
A
,
e
1
,
e
2
,
…
,
e
H
)
=
∑
j
=
1
H
a
(
e
j
,
v
A
)
e
j
=
∑
j
=
1
H
w
j
e
j
v_U(A) = f(v_A,e_1,e_2,\dots,e_H)=\sum\limits_{j=1}^{H}a(e_j,v_A)e_j=\sum\limits_{j=1}^{H}w_je_j
vU(A)=f(vA,e1,e2,…,eH)=j=1∑Ha(ej,vA)ej=j=1∑Hwjej 其中,
{
e
1
,
e
2
,
…
,
e
H
}
\{e_1,e_2,\dots,e_H\}
{e1,e2,…,eH}是长度为
H
H
H的用户
U
U
U的行为embedding向量,
v
A
v_A
vA是广告
A
A
A的embedding向量。这样,
v
U
(
A
)
v_U(A)
vU(A)的值随着广告的不同而变化(向量长度为
H
H
H)。外积函数
a
(
⋅
)
a(\cdot)
a(⋅)是一个输出为激活权重的前馈神经网络,把用户行为的embedding向量和广告的embedding向量这两部分输入,加上它们的out product传给后面的全连接网络。
对每一个兴趣表示不同的权值,这个权值是由用户的兴趣和待估算的广告进行匹配计算得到,也就是 a ( ⋅ ) a(\cdot) a(⋅)所学习到的。这就是本文引入注意力机制的核心点。
Activation Unit实现Attention机制,对Local Activation建模;Pooling(wighted sum)对Diversity建模。
4.4 DIN 模型细节
4.4.1 激活函数 Dice
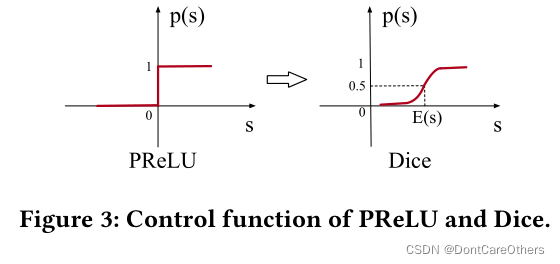
无论是ReLU还是PReLU突变点都在0,论文里认为,对于所有输入不应该都选择0点为突变点而是应该依赖于数据的。于是提出了一种data dependent的方法:Dice激活函数。形式如下:
f
(
s
)
=
p
(
s
)
⋅
s
+
(
1
−
p
(
s
)
)
⋅
α
s
,
p
(
s
)
=
1
1
+
e
−
s
−
E
(
s
)
V
a
r
(
s
)
+
ϵ
f(s)=p(s)\cdot s + (1-p(s)) \cdot \alpha s, p(s)=\frac{1}{1+e^{-\frac{s-E(s)}{\sqrt{Var(s)+\epsilon}}}}
f(s)=p(s)⋅s+(1−p(s))⋅αs,p(s)=1+e−Var(s)+ϵs−E(s)1 其中,期望和方差的计算公式如下:
E
[
y
i
]
t
+
1
′
=
E
[
y
i
]
t
′
+
α
E
[
y
i
]
t
+
1
E[y_i]_{t+1}^{'} = E[y_i]_{t}^{'} + \alpha E[y_i]_{t+1}
E[yi]t+1′=E[yi]t′+αE[yi]t+1
V
a
r
[
y
i
]
t
+
1
′
=
V
a
r
[
y
i
]
t
′
+
α
V
a
r
[
y
i
]
t
+
1
Var[y_i]_{t+1}^{'} = Var[y_i]_{t}^{'} + \alpha Var[y_i]_{t+1}
Var[yi]t+1′=Var[yi]t′+αVar[yi]t+1可以看出,
p
(
s
)
p(s)
p(s)不再是指示函数,而是变成了一个分布函数,可以看出,
E
[
s
]
E[s]
E[s]和
V
a
r
[
s
]
Var[s]
Var[s]都是根据每一层的输入数据计算得到的,所以对于不同的输入数据,
p
(
s
)
p(s)
p(s)的分布函数就会发生变化,另外也可以使整个激活函数变得很光滑。这里
ϵ
\epsilon
ϵ一般取一个很小的常量,论文中说经验上取
ϵ
=
1
e
−
8
\epsilon=1e-8
ϵ=1e−8.
4.4.2 正则化
CTR中输入稀疏而且维度高,已有的L1、L2、Dropout防止过拟合的办法,论文中尝试后效果都不是很好。用户数据符合 长尾定律long-tail law,也就是说很多的feature id只出现了几次,而一小部分feature id出现很多次。这在训练过程中增加了很多噪声,并且加重了过拟合。
对于这个问题一个简单的处理办法就是:人工的去掉出现次数比较少的feature id。缺点是:损失的信息不好评估;阈值的设定非常的粗糙。
DIN给出的解决方案是。针对feature id出现的频率,来自适应的调整他们正则化的强度:
- 对于出现频率高的,给与较小的正则化强度;
- 对于出现频率低的,给予较大的正则化强度;
- 作者实践发现出现频率高的物品无论是在模型评估还是线上收入中都有较大影响。
计算公式如下:
I
i
=
{
1
,
∃
(
x
j
,
y
j
)
∈
B
,
s
.
t
.
[
x
j
]
i
≠
0
0
,
o
t
h
e
r
w
i
s
e
s
I_i = \left\{ \begin{aligned} 1 & , \exists (x_j, y_j) \in B, s.t.[x_j]_i \neq 0\\ 0 & , otherwises \end{aligned} \right.
Ii={10,∃(xj,yj)∈B,s.t.[xj]i=0,otherwises
w
i
←
w
i
−
η
⟮
1
b
∑
(
x
j
,
y
j
)
∈
B
∂
L
(
f
(
x
j
)
,
y
j
)
∂
w
i
+
λ
1
n
i
w
i
I
i
⟯
w_i \leftarrow w_i - \eta \lgroup \frac{1}{b} \sum\limits_{(x_j,y_j) \in B} \frac{\partial L(f(x_j), y_j)}{\partial w_i} + \lambda \frac{1}{n_i} w_i I_i \rgroup
wi←wi−η⟮b1(xj,yj)∈B∑∂wi∂L(f(xj),yj)+λni1wiIi⟯ 公式推导见这篇文章。
4.4.3 评价指标 GAUC
AUC表示正样本得分比负样本得分高的概率。在CTR实际应用场景中,CTR预测常被用于对每个用户候选广告的排序。但是不同用户之间存在差异:有些用户天生就是点击率高。以往的评价指标对样本不区分用户地进行AUC的计算。DIN采用的GAUC实现了用户级别的AUC计算,在单个用户AUC的基础上,按照点击次数或展示次数进行加权平均,消除了用户偏差对模型的影响,更准确的描述了模型的表现效果。
G
A
U
C
=
∑
i
=
1
n
w
i
∗
A
U
C
i
∑
i
=
1
n
w
i
=
∑
i
=
1
n
i
m
p
e
r
s
s
i
o
n
i
∗
A
U
C
i
∑
i
=
1
n
i
m
p
e
e
r
s
s
i
o
n
i
GAUC=\frac{\sum_{i=1}^{n}w_i*AUC_i}{\sum_{i=1}^{n}w_i}=\frac{\sum_{i=1}^{n}imperssion_i*AUC_i}{\sum_{i=1}^{n}impeerssion_i}
GAUC=∑i=1nwi∑i=1nwi∗AUCi=∑i=1nimpeerssioni∑i=1nimperssioni∗AUCi关于AUC和GAUC的区别,可以看这篇文章。
4.4.4 输入数据处理
由于用户行为数据的存在,DIN模型的输入特征除了 Dense(数值型), Sparse(离散型)之外,新增了VarlenSparse(变长离散型)。而不同的类型特征会对应不同的处理方式:
- 数值型特征:将数值特征拼接,最后和处理好的离散特征拼接起来输入全连接层。
- 离散型特征:首先通过embedding层转成低维稠密向量,和处理好的变长离散特征拼接起来 输入全连接层。候选商品的embedding向量还要被用于计算和用户历史商品的相关性,对历史行为序列加权。
- 变长离散型特征:首先经过padding操作成等长向量, 然后通过embedding层得到各个历史行为的embedding向量,这些向量和候选商品embedding向量进入AttentionPoolingLayer对历史行为特征加权合并,最后得到输出。
4.5 总结
- 用户有多个兴趣爱好,访问了多个good_id,shop_id。为了降低纬度并使得商品店铺间的算术运算有意义,我们先对其进行Embedding嵌入。那么我们如何对用户多种多样的兴趣建模那?使用Pooling对Embedding Vector求和或者求平均。同时这也解决了不同用户输入长度不同的问题,得到了一个固定长度的向量。这个向量就是用户表示,是用户兴趣的代表;
- 但是,直接求sum或average损失了很多信息。所以稍加改进,针对不同的behavior id赋予不同的权重,这个权重是由当前behavior id和候选广告共同决定的。这就是Attention机制,实现了Local Activation;
- DIN使用activation unit来捕获local activation的特征,使用weighted sum pooling来捕获diversity结构;
- 在模型学习优化上,DIN提出了Dice激活函数、自适应正则 ,显著的提升了模型性能与收敛速度。
参考资料:
五、ESMM 模型
ESMM的全称是Entire Space Multi-task Model (ESMM),是阿里巴巴算法团队于2018年提出的多任务训练方法。其在信息检索、推荐系统、在线广告投放系统的CTR、CVR预估中广泛使用。
传统的CVR预估任务通常采用类似于CTR预估的技术,其存在如下问题:存在着两个主要的问题:样本选择偏差和稀疏数据。
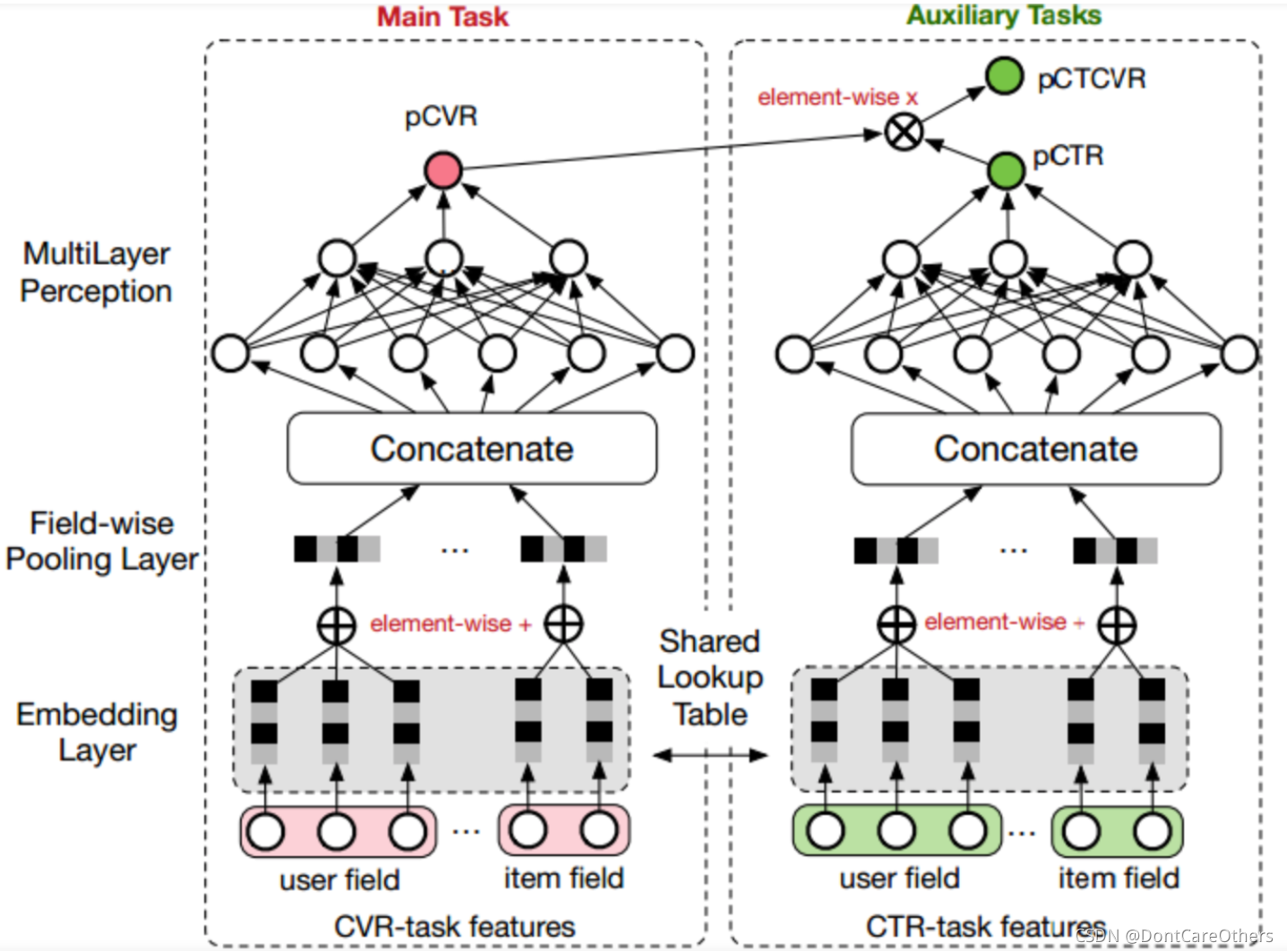
为了解决上面的两个问题,阿里提出了完整空间多任务模型ESMM。ESMM模型利用用户行为序列数据在完整样本空间建模,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。另一方面,ESMM模型首次提出了利用学习CTR和CTCVR的辅助任务迂回学习CVR的思路。ESMM模型中的BASE子网络可以替换为任意的学习模型,因此ESMM的框架可以非常容易地和其他学习模型集成,从而吸收其他学习模型的优势,进一步提升学习效果,想象空间巨大。
ESMM模型结构如下图所示:
参考资料:
总结
本篇博文主要介绍了推荐系统中常见的深度学习模型,有些模型结构不是很复杂就没有详细的展开,可以点击对应的参考资料进行学习。
有错误的地方敬请指正。