GRPO,一种新的强化学习方法,是DeepSeek R1使用到的训练方法。
今天的这篇博客文章,笔者会从零开始,层层递进地为各位介绍一种在强化学习中极具实用价值的技术——GRPO(Group Relative Policy Optimization)。如果你是第一次听说这个概念,也不必慌张,笔者会带领你从最基础的强化学习背景知识讲起,一步步剖析其来龙去脉,然后再结合实例讲解 GRPO 在实际应用中的思路和操作示例,最后再和其他近似方法对比,看看它和当下主流的 PPO(近端策略优化)等方法究竟有何区别与联系。
强烈推荐看完此帖子后再阅读另一帖——适当练习,强化记忆:【DeepSeek】大模型强化学习训练GRPO算法,你学会了吗?
GRPO原论文链接:https://arxiv.org/abs/2402.03300
GRPO中译文链接:https://blog.csdn.net/qq_38961840/article/details/145384346
为什么需要关注强化学习与策略优化?
在正式开始介绍 GRPO 之前,笔者想先谈谈一个较为根本的问题:为什么需要策略优化?又为什么要在意强化学习? 其实,无论是做推荐系统、对话系统,还是在数学推理、大语言模型对齐(alignment)场景里,最终我们都希望模型能输出“更优”或“更符合某些偏好”的序列。深度强化学习(DRL)借用“奖励”(reward)来衡量我们希望的目标,从而对生成的过程进行引导。策略优化(Policy Optimization)则是其中一个关键方法论。
在语言模型的应用中,比如要让模型解出数学题、满足人类对话偏好(例如避免不良输出,或给出更详细解释),我们往往先用大规模的无监督或自监督训练打下基础,然后通过一些“监督微调”(SFT)再进一步让模型学会初步符合需求。然而,SFT 有时难以将人类或某些高层目标的偏好显式地整合进去。这时,“强化学习微调”就登场了。PPO 是其中的代表性算法,但它同样有自己的痛点,比如要维护额外的大价值网络,对内存与计算的需求在大模型场景中不容忽视。GRPO 正是在此背景下闪亮登场。
回顾:强化学习中的基本概念
智能体、环境与交互
在传统的强化学习框架中,我们通常有一个“智能体”(Agent)和一个“环境”(Environment)。智能体每一步会基于自身策略 π(s) 去决定一个动作 a,然后环境会根据这个动作给出新的状态和一个奖励 r,智能体收集这个奖励并继续下一步。这种循环往复构成了一个时间序列过程,直到到达终止条件(如达成目标或超时等)。
不过在语言模型(尤其是大型语言模型,LLM)当中,我们也可以把一个“问题”(例如一段文本提示 prompt)当作环境给的状态,然后模型(智能体)产出下一 token(动作),再不断重复,直到生成一段完整的回答;人类或额外的奖励模型再给予一个整段回答的质量分,或在每个 token(或步骤)时刻给出一个局部奖励。虽然大语言模型看似和传统强化学习中的“马尔可夫决策过程(MDP)”有一些差别,但本质上也可以抽象为状态—动作—奖励—状态—动作的机制。
状态、动作、奖励、策略
- 状态 s:对于语言模型来说,可以把已经生成的token序列(以及当前问题)视为一种压缩后的状态;在传统RL里则是环境观测到的一些向量或特征。
- 动作 a:在语言模型生成场景,动作可以是“在词表 vocabulary 里选出下一个 token”;在机器人或游戏环境中就是“移动、旋转、跳跃”等操作。
- 奖励 r:衡量好坏程度的指标。在语言模型对齐中,常见做法是训练一个奖励模型来打分;或者直接用规则判断回答是否正确等。
- 策略 π:智能体在状态 s 下如何选动作 a 的概率分布函数 π(a|s)。在语言模型里,这就是产生每个 token 的条件分布。
价值函数与优势函数:为什么需要它们
在 PPO 等典型策略梯度方法中,我们通常还会引入一个价值函数(Value Function),它大致表示在当前状态下,未来能期望得到多少奖励;或者更进一步,我们可以在每个动作之后去看“优势函数(Advantage Function)”,衡量“这个动作比平均水平好多少”。为什么要搞价值函数或优势函数?因为在训练时,如果只有奖励的直接指引,每个样本都可能方差很大,收敛缓慢。价值函数的引入可以降低训练方差,提升训练效率。
从传统方法到近端策略优化(PPO)的发展脉络
策略梯度与Actor-Critic范式
**策略梯度方法(Policy Gradient)**是强化学习中一种比较直接的做法:我们直接对策略函数 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 进行建模,计算相应的梯度来最大化期望回报。它不用像价值迭代一样枚举所有状态-动作组合,也不用像Q-learning那样先学Q再做贪心决策。策略梯度可以很好地适应高维连Continuous动作空间,以及更灵活的策略表示。
不过,如果单纯用 REINFORCE 等策略梯度方法,每一步更新都可能有很大方差,甚至出现不稳定现象。为此,研究者们提出了Actor-Critic框架:将“策略”叫做Actor,将“价值函数”叫做Critic,两者共同训练,让Critic起到估计价值、降低方差的作用。
PPO的核心思路:clip与优势函数
后来又有了近端策略优化(PPO),它是在 Actor-Critic 的基础上,为了避免策略更新太猛导致训练不稳定,引入了一个剪切 (clip) 技巧,即把
π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} πθold(at∣st)πθ(at∣st)
这个概率比率给夹在 [ 1 − ε , 1 + ε ] [1-\varepsilon, 1+\varepsilon] [1−ε,1+ε] 区间内。这样就能防止每次更新过度,从而保持相对稳定。但要在实践中实现 PPO,需要在每个时间步都有一个价值网络去估计优势函数
A t = r t + γ V ψ ( s t + 1 ) − V ψ ( s t ) A_t = r_t + \gamma V_{\psi}(s_{t+1}) - V_{\psi}(s_t) At=rt+γVψ(st+1)−Vψ(st)
或者更常用的是广义优势估计(GAE),来让更新时的方差更小。可问题在于,当我们的模型规模急剧增加——如在数十亿甚至千亿参数的语言模型上搞 PPO,就会发现训练资源消耗巨大。因为这个价值网络本身通常要和策略网络“同样大”或近似大,并且需要在每个token都计算价值,从而带来可观的内存占用与计算代价。
PPO的局限性:模型规模与价值网络的负担
小模型时代,这也许还好,但是在当代的 LLM 背景下,我们需要极度节省训练内存与计算资源。尤其当你要做 RLHF(Reinforcement Learning from Human Feedback)或者别的对齐强化学习时,还要搭建奖励模型 Reward Model、价值网络 Critic Model,再加上本身的策略模型 Actor Model,算力负担往往让人头痛。
这就是 GRPO 的问题背景:如何在保证PPO那样的收益(稳定、可控等)前提下,减少对昂贵价值网络的依赖? 这背后的核心思路就是:用“分组输出相互比较”的方式来估计基线(Baseline),从而免去对价值网络的需求。
GRPO(分组相对策略优化)是什么?
GRPO提出的动机:为何需要它
基于上节的对 PPO 的简要回顾,你应该能感受到 PPO 在大模型时代的痛点。要不就牺牲训练速度和成本,要不就需要想其他方法来绕过价值网络的全程参与。而 GRPO(全称 Group Relative Policy Optimization)正是对这一问题做出了一种解答。
核心动机:在许多实际应用中,奖励只有在序列末端才给一个分数(称之为 Result/Oucome Supervision),或在每一步给一些局部分数(Process Supervision)。不管怎么样,这个奖励本身往往是离散且比较稀疏的,要让价值网络去学习每个token的价值,可能并不划算。而如果我们在同一个问题 q 上采样多份输出 o 1 , o 2 , … , o G o_1, o_2, \ldots, o_G o1,o2,…,oG,对它们进行奖励对比,就能更好地推断哪些输出更好。由此,就能对每个输出的所有 token 做相对评分,无须明确地学到一个价值函数。
在数理推理、数学解题等场景,这个技巧尤其管用,因为常常会基于同一个题目 q 生成多个候选输出,有对有错,或者优劣程度不同。那就把它们的奖励进行一个分组内的比较,以获取相对差异,然后把相对优势视为更新策略的依据。
GRPO的关键点一:分组采样与相对奖励
GRPO 中,“分组”非常关键:我们会在一个问题 q 上,采样 GRPO 份输出 o 1 , o 2 , … , o G o_1, o_2, \ldots, o_G o1,o2,…,oG。然后把这组输出一起送进奖励模型(或规则),得到奖励分 r 1 , r 2 , … , r G r_1, r_2, \ldots, r_G r1,r2,…,rG。下一步干嘛呢?我们并不是单纯地对每个输出和一个固定基线比较,而是先把 r = { r 1 , r 2 , … , r G } \mathbf{r} = \{r_1, r_2, \ldots, r_G\} r={r1,r2,…,rG} 做一个归一化(如减去平均值再除以标准差),从而得出分组内的相对水平。这样就形成了相对奖励 r ~ i \tilde{r}_i r~i。最后我们会把这个相对奖励赋给该输出对应的所有 token 的优势函数。
简单来说:多生成几份答案,一起比较,再根据排名或分数差更新,能更直接、简洁地反映同一问题下的优劣关系,而不需要用一个显式的价值网络去学习所有中间时刻的估计。
GRPO的关键点二:无需价值网络的高效策略优化
因为不再需要在每个 token 上拟合一个价值函数,我们就能大幅节省内存——不必再维护和 Actor 同样大的 Critic 模型。这不仅是存储层面的解放,也是训练过程中的显著加速。
当然,GRPO 也会引入一些新的代价:我们要为每个问题采样一组输出(不止一条),意味着推理时要多花点算力去生成候选答案。这种方法和“自洽性采样(Self-consistency)”思路也有点类似,如果你了解一些数学题多候选合并判断的做法,就能感受到其中的相通之处。
GRPO的原理拆解
数学公式:和PPO的对比
图 1: PPO 和 GRPO 的对比。 GRPO 放弃了价值模型,从分组得分中估计,显著减少了训练资源
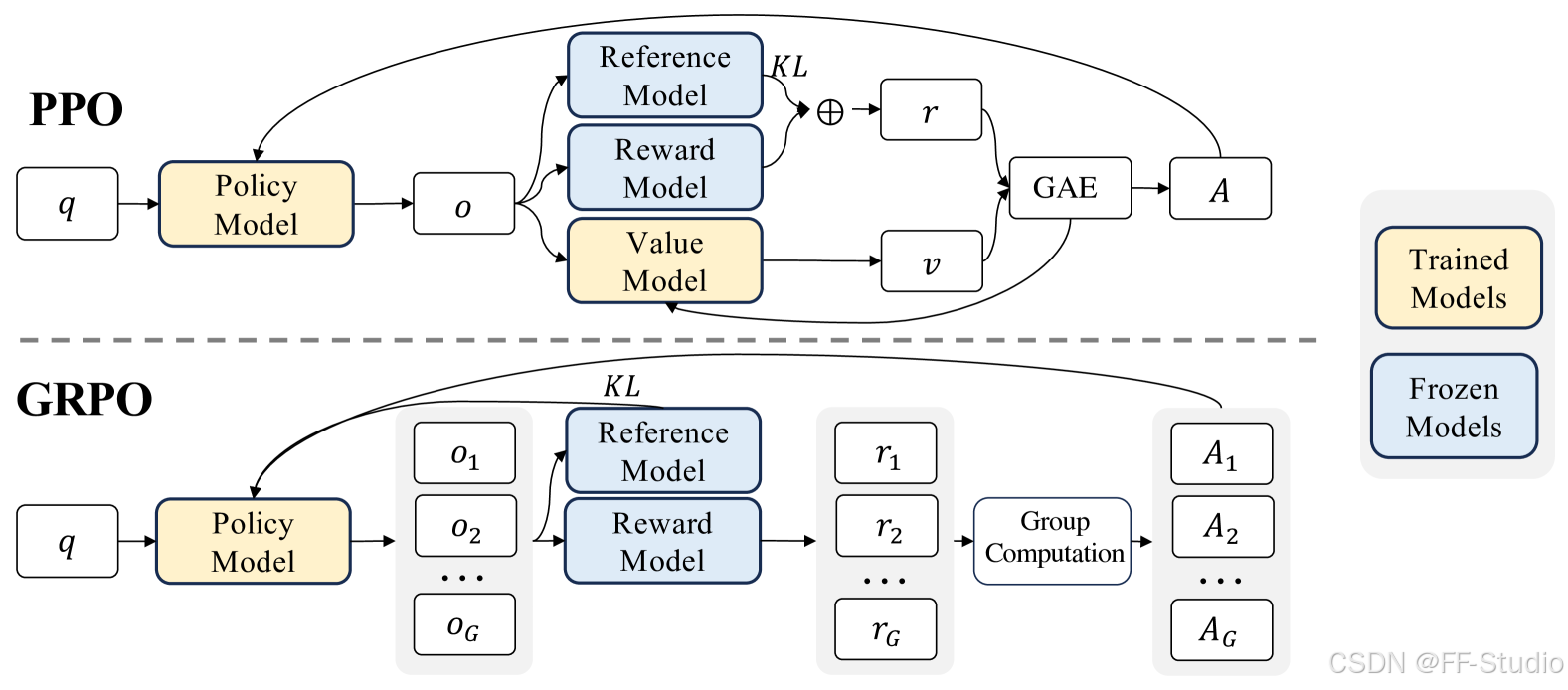
先让我们写下一个 PPO 的核心目标函数回顾一下:在 PPO 的简化推导里,假设一次只更新一步,那么
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] [ 1 ∥ o ∥ ∑ t = 1 ∥ o ∥ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t ] \mathcal{J}^{\mathrm{PPO}}(\theta) = \mathbb{E}_{[q \sim P(Q),\, o \sim \pi_{\theta_{\mathrm{old}}}(O \mid q)]} \Biggl[ \frac{1}{\|o\|} \sum_{t=1}^{\|o\|} \frac{\pi_{\theta}(o_t \mid q, o_{<t})}{\pi_{\theta_{\mathrm{old}}}(o_t \mid q, o_{<t})} \, A_t \Biggr] JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)][∥o∥1t=1∑∥o∥πθold(ot∣q,o<t)πθ(ot∣q,o<t)At]
其中
- q q q 是从一个训练集问题分布 P ( Q ) P(Q) P(Q) 中采样来的问题;
- o o o 是在旧策略 π θ o l d \pi_{\theta_{\mathrm{old}}} πθold 下生成的输出序列;
- ∥ o ∥ \|o\| ∥o∥ 是输出序列的长度(token数);
- A t A_t At 是优势函数,需要一个单独价值网络 V ψ V_\psi Vψ 来估计。
而 GRPO 做的事情则是:同样从问题分布中取到 q q q,但这一次我们会针对同一个 q q q 采样出一组输出 { o 1 , … , o G } \{o_1, \ldots, o_G\} {o1,…,oG}。对每个输出 o i o_i oi 做奖励打分 r i r_i ri。然后相对化后,将它当作对各 token 的优势函数。最后也类似 PPO 的做法去最大化一个带有 ratio 的目标,只不过“价值函数”被分组相对奖励给替代了。用更直观的话说:
J G R P O ( θ ) = E [ 1 G ∑ i = 1 G 1 ∥ o i ∥ ∑ t = 1 ∥ o i ∥ min [ r r a t i o , clip ( r r a t i o , 1 − ε , 1 + ε ) ] ⋅ A ^ i , t ] − (KL 正则项) \mathcal{J}^{\mathrm{GRPO}}(\theta) = \mathbb{E} \Biggl[ \frac{1}{G} \sum_{i=1}^{G} \frac{1}{\|o_i\|} \sum_{t=1}^{\|o_i\|} \min\bigl[ r_{\mathrm{ratio}},\, \operatorname{clip}(r_{\mathrm{ratio}},\, 1-\varepsilon,\, 1+\varepsilon) \bigr] \cdot \hat{A}_{i,t} \biggr] - \text{(KL 正则项)} JGRPO(θ)=E[G1i=1∑G∥oi∥1t=1∑∥oi∥min[rratio,clip(rratio,1−ε,1+ε)]⋅A^i,t]−(KL 正则项)
其中
- r r a t i o = π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) r_{\mathrm{ratio}} = \frac{\pi_{\theta}(o_{i,t}\mid q, o_{i,<t})}{\pi_{\theta_{\mathrm{old}}}(o_{i,t}\mid q, o_{i,<t})} rratio=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),
- A ^ i , t \hat{A}_{i,t} A^i,t 是分组相对意义上的“优势”,我们下节会具体解释它是怎么来的;
- KL 正则用来限制策略和一个参考策略(通常是初始 SFT 模型或当前 θ o l d \theta_{\mathrm{old}} θold)之间不要差异过大,以防训练崩坏。
分组得分与基线估计
那么 A ^ i , t \hat{A}_{i,t} A^i,t到底怎么来?就是分组相对奖励:我们先把每个 o i o_i oi的奖励 r i r_i ri 做如下归一化
r ~ i = r i − m e a n ( r ) s t d ( r ) \tilde{r}_i = \frac{r_i - \mathrm{mean}(\mathbf{r})}{\mathrm{std}(\mathbf{r})} r~i=std(r)ri−mean(r)
然后令
A ^ i , t = r ~ i \hat{A}_{i,t} = \tilde{r}_i A^i,t=r~i
也就是说,输出 o i o_i oi 的所有 token 共享同一个分数 r ~ i \tilde{r}_i r~i。它们的好坏相对于该分组内的平均水平来衡量,而不依赖外部价值网络去“拆分”或“插值”。这样我们就得到了一个无价值网络的优势函数,核心思路就是基于相互间的比较与排序。
如果用的是过程监督(process supervision),即在推理过程中的每个关键步骤都打分,那么就会略有不同。那时每个步骤都有一个局部奖励,就可以把它依时间序列累加或折算成与 token 对应的优势,这在后文示例里我们会详细展示。
一步步理解损失函数
让我们把 PPO/GRPO 都视为一种“Actor 优化”过程,每个 token 的梯度大致长这样:
∇ θ J ( θ ) = E [ ( gradient coefficient ) ⋅ ∇ θ log π θ ( o t ∣ q , o < t ) ] \nabla_{\theta} \mathcal{J}(\theta) = \mathbb{E}\bigl[ (\text{gradient coefficient}) \cdot \nabla_{\theta} \log \pi_{\theta}(o_t \mid q, o_{<t}) \bigr] ∇θJ(θ)=E[(gradient coefficient)⋅∇θlogπθ(ot∣q,o<t)]
在 PPO 里,gradient coefficient 里往往含有优势 A t A_t At 以及 ratio 等信息;而在 GRPO 里,gradient coefficient 变成了以分组奖励为基础的一些值。之所以说 GRPO 是 PPO 的一个变体,是因为它同样维持了 ratio 的范式,只不过优势函数来自“分组内相对奖励”,而非价值网络。
惩罚项与KL正则
最后补充一句,PPO 中常见的 KL 惩罚手段或者 clipping 手段,在 GRPO 中都可以保留,以避免训练过程中的策略分布出现暴走。当然,也有一些更精细的做法,比如把 per-token KL 正则直接加到损失中,而不是只在奖励函数 r r r 里扣一个 β ⋅ log π θ π r e f \beta \cdot \log \frac{\pi_\theta}{\pi_{\mathrm{ref}}} β⋅logπrefπθ。这在各家实现时略有不同,但思路都类似。
实例讲解:如何用GRPO来解决一个简单问题
有了上文的理论基础后,笔者想通过一个简化的实例,帮助你把 GRPO 的实施逻辑走一遍。我们会从最基本的样本生成到分组打分再到反向传播,都捋顺顺。
实验场景与环境:示例说明
假设笔者有一个文本对话场景:系统给定一个问题 q q q,模型需要给出回答 o o o。我们有一个奖励模型来判断回答的好坏(比如回答是否准确、是否违反某些安全规范等),返回一个数值分 r r r。为简单起见,就不考虑过程监督,先考虑结果监督(Outcome Supervision)的情境。
在这个设定下,每个问题 q q q 提供的“回合”只有一次——即输出一段文本 o o o,即可拿到一个终端奖励 r r r。要做 GRPO,我们至少要对同一个 q q q 生成 G R P O GRPO GRPO 条回复 o 1 , o 2 , . . . , o G o_1, o_2, ..., o_G o1,o2,...,oG。
过程监督VS结果监督:过程奖励与末端奖励的对比
- 结果监督(Outcome Supervision):只有输出序列结束才打一个奖励,如回答对/错、得分多少。GRPO 则把这个 r r r 同样分配给序列里每个 token。
- 过程监督(Process Supervision):对中间推理步骤也有打分(比如计算正确一步就+1,错误一步就-1)。那就得收集多个时刻的奖励,然后累加到每个 token 或步骤上,再做分组相对化。
在绝大多数简单场景下,初学者往往更容易先实现结果监督的版本,这也正好方便讲解 GRPO 的主干思路。
分组采样的实现:batch内如何分组?
在实际操作中,我们往往会在一个 batch 中包含若干个问题 q q q,对每个问题生成 G R P O GRPO GRPO 个答案。也就是说 batch 大小 = B B B,每个问题生成 G R P O GRPO GRPO 个候选,那么一次前向推理要生成 B ∗ G R P O B*GRPO B∗GRPO 条候选。然后,每个候选都送奖励模型 R M \mathrm{RM} RM 得到分数 r i r_i ri。注意这样做推理开销不小,如果 G R P O GRPO GRPO 较大,会显著地增加生成次数,但换来的好处是,我们不再需要价值网络了。
实际伪代码示例
我们以结果监督为例,先给出一个简化版的伪代码,帮助你更好理解 GRPO 的操作流程。假设 π θ \pi_\theta πθ 是当前策略模型, π ref \pi_{\text{ref}} πref 是参考模型(一般初始可设为和 π θ \pi_\theta πθ 同一个拷贝,用于算 KL 正则), R M \mathrm{RM} RM 是奖励模型。
# 请注意这只是简化的示例,忽略了各种超参数细节
# GPRO 伪代码 (结果监督)
for iteration in range(N_iterations):
# 1) 设置参考模型 pi_ref <- pi_theta
pi_ref = clone(pi_theta)
for step in range(M_steps_per_iter):
# 2) 从训练集中取一批问题 D_b
D_b = sample_batch(train_dataset, batch_size=B)
# 3) 让旧策略 pi_theta 生成 G 个输出
# o_i 表示第 i 个候选答案
batch_outs = []
for q in D_b:
outs_for_q = []
for i in range(G):
o_i = sample(pi_theta, q)
outs_for_q.append(o_i)
batch_outs.append(outs_for_q)
# 4) 对每个输出用奖励模型 RM 打分
# r_i = RM(q, o_i)
# 同时做分组归一化
# r_i_tilde = (r_i - mean(r)) / std(r)
# 赋值给 A_i (整条序列的优势)
# 这里只是一种写法:对 batch 内每个 q 都做
for outs_for_q in batch_outs:
# outs_for_q 大小是 G
r_list = [RM(q, o_i) for o_i in outs_for_q]
mean_r = mean(r_list)
std_r = std(r_list)
if std_r == 0: std_r = 1e-8 # 避免除0
for i, o_i in enumerate(outs_for_q):
r_tilde = (r_list[i] - mean_r) / std_r
# 把这个 r_tilde 记为 A(o_i) 用于后续计算
# 也可以存在某个 data structure 里
# 5) 根据 GPRO 目标函数做梯度更新
# 关键是每个 token 的优势都用 A(o_i)
# 并加上 KL 正则
loss = compute_gpro_loss(pi_theta, pi_ref, batch_outs, r_tilde_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
在这个伪代码里,我们可以看到最关键的部分就是每个问题都采样 G R P O GRPO GRPO 个输出,分别打分,然后在该分组里做归一化。每个输出 o i o_i oi 的所有 token 共享一个相同的优势值 A ^ i , t = r ~ i \hat{A}_{i,t} = \tilde{r}_i A^i,t=r~i。然后再像 PPO 那样做 ratio + clip 的梯度更新。
这便完成了结果监督版本的 GRPO 训练循环。相比 PPO,差别在于:不再需要一个大型的价值网络来估计优劣,而是由分组对比来获得相对优势。
GRPO的高级实践
迭代式强化学习:奖励模型的更新与回放机制
在实际用 GRPO 的时候,如果你的奖励模型 RM 也是学习得来的,那么你就会发现:当策略模型变强时,RM 所得到的训练样本分布会越来越“难”,这时 RM 自身也需要更新。这样就会出现迭代强化学习流程:先用当前 RM 来指导一轮策略更新,然后再用新策略生成的数据来更新 RM。为了避免灾难性遗忘,可以保留一部分旧数据(回放机制 replay buffer),让 RM 每次都在新旧数据上共同训练,这样 RM 不会完全忘记之前的问题特征。
与RFT、DPO、PPO的比较与兼容
如果你关注过 RFT(Rejection Sampling Fine-tuning)或 DPO(Direct Preference Optimization)等方法,可能会好奇,GRPO 跟它们的差别在哪?
- RFT:基于同一个模型生成多条输出,再筛选掉错误或低质量的,用剩下的做微调。它不显式区分好答案与更好答案的幅度差异,也不怎么更新策略分布对错的概率比例;可以算是比 GRPO 简单但也少了细粒度的奖励。
- DPO:需要成对比较 o+、o-,然后做一个 pairwise 的对比损失,和 GRPO 的思路也有差异;DPO 主要是无需单独的 RL 优化器,但它也需要 pairwise preference 的训练集。
- PPO:最常见的 RL 算法,需要维护价值网络 Critic;而 GRPO 则尝试通过分组相对奖励来免去价值网络的需求。
在实际应用中,你或许会发现 GRPO 和 PPO 并不是对立关系。相反,如果你想在某些场景继续用价值网络的估计,或者想把“分组相对奖励”与“价值函数估计”结合起来,也能做成一个“混合式”的算法。
如何在大模型中使用GRPO:大模型的内存与计算优化
- 内存节省:因为不用价值网络了,一下子省下了你那数十亿参数的 Critic;即使你要训练奖励模型 RM,也通常比 Critic 规模小得多,因为后者常常要和 Actor 同规模。
- 计算优化:采样 GRPO 条输出会增加推理开销,但假如你本来就打算做多样性生成或自洽采样,那么这点代价在许多场景可以接受。并且在实践中,你可以对 GRPO 做折中:不一定要搞到 64、128 这样大的值,有时候 8、16 就能提供足够稳定的信号了。
GRPO在数学推理中的应用
聊到这里,你或许会问,“为什么在数学推理上特别推荐 GRPO?” 答案是:数学推理往往需要对问题进行多次思考和尝试,然后选出最优或最正确的答案;在强化学习调优模型时,如果采用 PPO,需要把每一步的中间推理步骤都拟合一个价值,这个操作很昂贵且可能噪声很大。而 GRPO 只需在每个问题末端对最终答案进行打分,并做分组对比即可。
DeepSeekMath的背景:数学预训练与指令微调
以DeepSeekMath为例,这是一个在大规模数学数据(包括 Common Crawl 中挖掘到的 1200 亿数学相关 tokens)上持续训练的 7B 参数级大模型,然后再用数学指令微调(CoT、PoT 等)进行强化。最终它在竞赛级别的 MATH 数据集上超过了 50% 的准确率,且优于众多同类开源模型。DeepSeekMath 在最后一步引入了强化学习,其中就包含了类似 GRPO 的思路:使用分组对比来为每个采样解答分配一个相对奖励。
为什么GRPO能帮助数学推理的性能提升
- 多候选比较:数学题经常一题多解,或者一题多错。对同一个题目生成多条解答,然后让奖励模型或规则判断优劣,就能充分地分辨出优质解答,策略更新也更“有的放矢”。
- 减少价值网络负担:数学推理往往需要对中间推理步骤给出价值估计,训练一个庞大的 Critic 不但开销大,还不一定效果好;分组相对法则让我们可以只在最终结论处打分就足够了。
- 更快收敛:当你一次就能对同一个题目生成多条回答,批量比较之后再更新策略,训练效率比采样单条回答要高一些。
领域内与领域外的表现:GSM8K与MATH只是起点
在 DeepSeekMath 或其他类似模型的实验中,常见的领域内任务就是GSM8K(小学奥数题库)与MATH(高难度竞赛级别数学题),这二者在训练集中已经比较常见,或在微调数据中直接出现。当我们用 GRPO 对这些任务做强化学习时,能大幅提升Top1 准确率,还能间接提升Maj@K(使用多候选投票后的准确率)。更有趣的是,某些领域外(Out-of-domain)任务也常能收益于这种训练,因为分组对比的过程让模型的输出分布“更稳健”,不再容易随机输出无关或浅层错误。
常见问题答疑 (FAQ)
GRPO和PPO的训练时长、资源对比?
在传统 PPO 里,你需要并行维护一个与 Actor 模型同规模的价值网络,并且对每条生成序列都要算价值函数,还要做 backprop。在 GRPO 里,取而代之的是多生成的开销(分组 GRPO 条)。至于哪种方式更省资源,要看你把 GRPO 设多大,还要看你的价值网络是否可以小规模近似。整体上,如果 GRPO 取一个适中的值,GRPO 通常能省掉 Critic 带来的大规模网络开销,显著降低内存占用,所以对大模型场景往往非常划算。
如果奖励模型精度不高会怎样?
如果奖励模型 RM 本身不靠谱,GRPO 就会有问题,因为它基本完全依赖 RM 的评分来区分哪个输出好。可以把不靠谱的奖励模型理解成 PPO 里一个“瞎子价值网络”,一样会引导错误。所以说在 RLHF 场景下,如何拿到足够精确的奖励模型是关键。如果 RM 噪声很大,你至少要做大量分组采样(让噪声平均化),或引入一些更新机制来持续标注数据纠偏。
能不能只做离线版本的GRPO?
可以——如果你已经有一个固定的语料,其中包含每个问题的多个候选回答,以及相应的奖励分,甚至比较关系,那就可以做一个离线版的 GRPO:直接把这些现成分组拿来计算目标函数更新策略。不过,这和在线的强化学习还是有区别,在线能不断地探索新的输出,离线则只能在已有数据里学习。如果你的数据够丰富,离线也能取得不错的效果,称之为Offline RL思路。但若你想持续提升模型性能,在线还是更灵活。
总结与展望
在这篇(异常冗长的)博客里,笔者从最基本的强化学习概念与 PPO 的发展脉络说起,一步步引出了 GRPO(Group Relative Policy Optimization)在大模型微调,尤其是数学推理、语言对齐、对话生成等场景中的强大价值。通过对其关键点(分组采样、相对奖励、免价值网络)及简化伪代码示例,大家应该已经对 GRPO 的动机和实现过程有了一个系统性认识。
回顾要点:
- PPO 需要价值网络 Critic,但 GRPO 则用“分组内相互比较”的方法来估计优势,从而免去高昂的价值网络需求;
- GRPO 同样保留了 PPO 的 ratio 范式与 KL 正则等机制,训练稳定性与可控性良好;
- 在大规模模型(例如 7B, 70B 甚至更大)上实施强化学习时,内存和计算经常成为瓶颈,GRPO 的思路能节省大量资源;
- 对于多候选本来就不可避免的应用场景(如数学推理一题多答,对话生成一问多答),GRPO 的采样成本不会显得过于昂贵,反而能有效利用多候选的互相比较来改进策略。
未来工作:
- 进一步研究如何在分组奖励中结合细粒度的过程监督(Process Supervision),让每一步推理都能得到更准确的反馈;
- 探索奖励模型不确定性时,GRPO 的鲁棒性提升方案,比如对噪声标注或不完善RM加入 Bayesian 推理;
- 与其他对齐策略(RFT、DPO 等)深度整合,形成更加通用的框架——毕竟它们都可以被看作某种简化或变体的强化学习。
强化学习依旧在不断演化,无论是对话对齐、信息检索、代码生成还是学术数学推理领域,如何设计更优的策略优化方法,一直是开放问题。希望本篇万字长文能够在你脑海中埋下一颗种子。即便今天就只带走了“GRPO 不用价值网络,还挺省事”这个印象,也算是个好开始。如果你对更细节的实现或研究方向感兴趣,欢迎继续深入阅读相关资料或尝试自己动手做实验。
在笔者看来,在不远的将来,我们或许会看到更多更灵活、更高效的算法出现。毕竟,人类对“奖励信号”如何最有效地指导大模型还有很多的挖掘空间。让我们拭目以待吧。
参考文献
以下列出部分在这篇博客中提到或隐含引用的文献和资源,以供进一步阅读和探索。很多思路都可以在这些论文或项目中找到更详细的技术细节。
- [Schulman et al. 2017] Schulman, J. 等. Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347, 2017.
- [Ouyang et al. 2022] Ouyang, L. 等. Training language models to follow instructions with human feedback. NeurIPS, 2022.
- [Rafailov et al. 2023] Rafailov, R. 等. Direct Preference Optimization (DPO). 2023.
- [Yuan et al. 2023] Yuan, Z. 等. Rejection Sampling Fine-Tuning (RFT). 2023.
- [DeepSeekMath 项目] https://github.com/deepseek-ai/DeepSeek-Math
- 其他更多参考文献参见笔者在正文中提到的相关引文。