Yolov8_obb模型压缩之模型剪枝
一、 剪枝原理和pipleline
参考:
yolov5模型压缩之模型剪枝
模型压缩(二)yolov5剪枝
本次使用稀疏训练对channel维度进行剪枝,来自论文Learning Efficient Convolutional Networks Through Network Slimming。其实原理很容易理解,我们知道bn层中存在两个可训练参数γ , β ,输入经过bn获得归一化后的分布。当γ , β趋于0时,输入相当于乘上了0,那么,该channel上的卷积将只能输出0,毫无意义。因此,我们可以认为剔除这样的冗余channel对模型性能影响甚微。普通网络训练时,由于初始化,γ 一般分布在1附近。为了使γ 趋于0,可以通过添加L1正则来约束,使得系数稀疏化,论文中将添加γL1正则的训练称为稀疏训练。
整个剪枝的过程如下图所示,首先初始化网络,对bn层的参数添加L1正则并对网络训练。统计网络中的γ,设置剪枝率对网络进行裁剪。最后,将裁减完的网络finetune,完成剪枝工作。
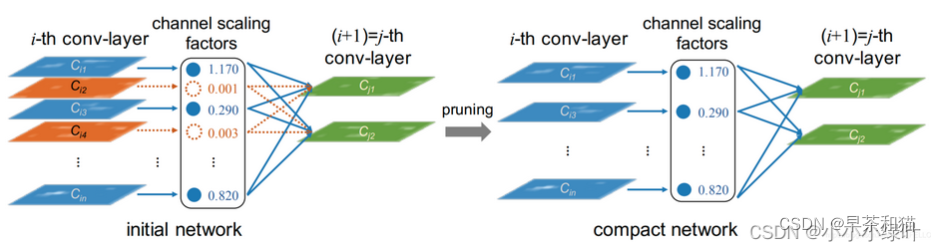

二、 剪枝代码讲解
1、稀疏训练
上一章介绍了稀疏训练的原理,下面看一下代码是如何实现的。代码如下所示,首先,我们需要设置稀疏系数,稀疏系数对整个网络剪枝性能至关重要,设置太小的系数,γ趋于0的程度不高,无法对网络进行高强度的剪枝,但设置过大,会影响网络性能,大幅降低map。因此,我们需要通过实验找到合适的稀疏系数。
bn层的训练参数包括γ , β ,即代码中的m.weight,m.bias,loss.backward之后,在这两个参数的梯度上添加L1正则的梯度即可。
# # ============================= sparsity training ========================== #
srtmp = opt.sr*(1 - 0.9*epoch/epochs)
if opt.st:
#用来存放不参与剪枝的卷积层,这里并没有用到
ignore_bn_list = []
for k, m in model.named_modules():
if isinstance(m, nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp * torch.sign(m.weight.data)) # L1
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.bias.data)) # L1
# # ============================= sparsity training ========================== #
2、网络剪枝
上一步获得稀疏训练后的网络,接下来,我们需要将γ趋于0的channel裁剪掉。首先,统计所有BN层的γ,并对齐排序,找到剪枝率对应的阈值thre
根据阈值来分隔,可能存在某一BN层所有通道均小于阈值,如果将其过滤掉,会造成层层之间的断开,此时需要做判断进行限制,使得每层最少有一个通道得以保留。
解决方法:获取每个bn层的权重的最大值,然后在这些最大值中取最小值与设定的阈值进行对比,如果小于阈值,则提示修改。
model_list = {}
ignore_bn_list = []
#保存的模型不能去除bn层
for i, layer in model.named_modules():
if opt.close_head:
# v8输出头不剪枝则打开,然后对args的传参去除new_channels,不想剪枝那一层往ignore_bn_list添加哪一层
if isinstance(layer, Detect_v8):
ignore_bn_list.append(i+".cv2.0.0.bn")
ignore_bn_list.append(i+".cv2.0.1.bn")
ignore_bn_list.append(i+".cv2.1.0.bn")
ignore_bn_list.append(i+".cv2.1.1.bn")
ignore_bn_list.append(i+".cv2.2.0.bn")
ignore_bn_list.append(i+".cv2.2.1.bn")
ignore_bn_list.append(i+".cv3.0.0.bn")
ignore_bn_list.append(i+".cv3.0.1.bn")
ignore_bn_list.append(i+".cv3.1.0.bn")
ignore_bn_list.append(i+".cv3.1.1.bn")
ignore_bn_list.append(i+".cv3.2.0.bn")
ignore_bn_list.append(i+".cv3.2.1.bn")
ignore_bn_list.append(i+".cv4.0.0.bn")
ignore_bn_list.append(i+".cv4.0.1.bn")
ignore_bn_list.append(i+".cv4.1.0.bn")
ignore_bn_list.append(i+".cv4.1.1.bn")
ignore_bn_list.append(i+".cv4.2.0.bn")
ignore_bn_list.append(i+".cv4.2.1.bn")
if isinstance(layer, torch.nn.BatchNorm2d):
if i not in ignore_bn_list:
model_list[i] = layer
model_list = {k:v for k,v in model_list.items() if k not in ignore_bn_list}
prune_conv_list = [layer.replace("bn", "conv") for layer in model_list.keys()]
bn_weights = gather_bn_weights(model_list)
sorted_bn = torch.sort(bn_weights)[0]
# 避免剪掉所有channel的最高阈值(每个BN层的gamma的最大值的最小值即为阈值上限)
highest_thre = []
for bnlayer in model_list.values():
highest_thre.append(bnlayer.weight.data.abs().max().item())
highest_thre = min(highest_thre)
# 找到highest_thre对应的下标对应的百分比
percent_limit = (sorted_bn == highest_thre).nonzero()[0, 0].item() / len(bn_weights)
print(f'Suggested Gamma threshold should be less than {highest_thre:.4f}.')
print(f'The corresponding prune ratio is {percent_limit:.3f}, but you can set higher.')
# assert opt.percent < percent_limit, f"Prune ratio should less than {percent_limit}, otherwise it may cause error!!!"
# model_copy = deepcopy(model)
thre_index = int(len(sorted_bn) * opt.percent)
thre = sorted_bn[thre_index]
print('thre',thre)
print(f'Gamma value that less than {thre:.4f} are set to zero!')
print("=" * 94)
print(f"|\t{'layer name':<25}{'|':<10}{'origin channels':<20}{'|':<10}{'remaining channels':<20}|")
remain_num = 0
modelstate = model.state_dict()
由于,剪枝后的网络与原网络channel不能对齐,因此,我们需要重新定义网络,并解析网络。重构的网络结构需要重新定义,因为需要导入更多的参数。
# ============================== save pruned model config yaml =================================#
pruned_yaml = {}
nc = model.model[-1].nc
with open(cfg, encoding='ascii', errors='ignore') as f:
model_yamls = yaml.safe_load(f) # model dict
# # Define model
pruned_yaml["nc"] = model.model[-1].nc
pruned_yaml["depth_multiple"] = model_yamls["depth_multiple"]
pruned_yaml["width_multiple"] = model_yamls["width_multiple"]
# yolov5s
pruned_yaml["backbone"] = [
[-1, 1, Conv, [64, 3, 2,]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C2fPruned, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C2fPruned, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 6, C2fPruned, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C2fPruned, [1024]],
[-1, 1, SPPFPruned, [1024, 5]], # 9
]
pruned_yaml["head"] = [
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C2fPruned, [512, False]], # 13
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C2fPruned, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P4
[-1, 3, C2fPruned, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 9], 1, Concat, [1]], # cat head P5
[-1, 3, C2fPruned, [1024, False]], # 23 (P5/32-large)
[[15, 18, 21], 1, Detect_v8, [nc]], # Detect(P3, P4, P5)
]
# ============================================================================== #
模型重构:根据阈值获取每一bn层的mask,这里加了一些逻辑,目的是让剪枝后的channel保证是8的倍数,即复合前端加速要求。
maskbndict = {}
for bnname, bnlayer in model.named_modules():
if isinstance(bnlayer, nn.BatchNorm2d):
bn_module = bnlayer
#获取bn_mask并处理为8的整数倍
mask = obtain_bn_mask(bn_module, thre)
if bnname in ignore_bn_list:
mask = torch.ones(bnlayer.weight.data.size()).cuda()
maskbndict[bnname] = mask
remain_num += int(mask.sum())
bn_module.weight.data.mul_(mask)
bn_module.bias.data.mul_(mask)
# print("bn_module:", bn_module.bias)
print(f"|\t{bnname:<25}{'|':<10}{bn_module.weight.data.size()[0]:<20}{'|':<10}{int(mask.sum()):<20}|")
assert int(mask.sum()) > 0, "Current remaining channel must greater than 0!!! please set prune percent to lower thesh, or you can retrain a more sparse model..."
print("=" * 94)
def obtain_bn_mask(bn_module, thre):
thre = thre.cuda()
mask = bn_module.weight.data.abs().ge(thre).float()
if int(mask.sum())%8==0:
return mask
else:
x=0
num=8-(int(mask.sum())%8)
for i in range(len(mask)):
if mask[i]==0:
mask[i]=1
x=x+1
if x==num:
break
return mask
也可设置成4的倍数
def obtain_bn_mask(bn_module, thre):
thre = thre.cuda()
bn_layer = bn_module.weight.data.abs()
temp = abs(torch.sort(bn_layer)[0][3::4] - thre)
thre_temp = torch.sort(bn_layer)[0][3::4][temp.argmin()]
if int(temp.argmin()) == 0 and thre_temp > thre:
thre = -1
else:
thre = thre_temp
thre_index = int(bn_layer.shape[0] * 0.9)
if thre_index % 4 != 0:
thre_index -= thre_index % 4
thre_perbn = torch.sort(bn_layer)[0][thre_index - 1]
if thre_perbn < thre:
thre = min(thre, thre_perbn)
mask = bn_module.weight.data.abs().gt(thre).float()
return mask
根据获得的bn层mask重构剪枝后的模型,举例原始模型的某一卷积层是从32卷积到64层,经过稀疏训练之后通过阈值过滤到我们认为对模型精度几乎没有影响的通道数,如果过滤之后得到56层,我们需要再构建剪枝模型时候,重新将该层卷积的传入参数和传出参数改成32,56。以此类推完成对每一层的剪枝。
def parse_pruned_model(maskbndict, d, ch): # model_dict, input_channels(3)
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
nc, gd, gw = d['nc'], d['depth_multiple'], d['width_multiple']
fromlayer = []
from_to_map = {}
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
# print('d---',d)
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
named_m_base = "model.{}".format(i)
if m in [Conv]:
named_m_bn = named_m_base + ".bn"
bnc = int(maskbndict[named_m_bn].sum())
c1, c2 = ch[f], bnc
args = [c1, c2, *args[1:]]
layertmp = named_m_bn
if i>0:
from_to_map[layertmp] = fromlayer[f]
fromlayer.append(named_m_bn)
elif m in [C2fPruned]:
#model.4和6的cf2为n=2层数更多需要注意规则
if named_m_base == 'model.4' or named_m_base == 'model.6':
args_list=[]
for q in range(n):
named_m_cv1_bn = named_m_base + ".{}.cv1.bn".format(q)
named_m_cv2_bn = named_m_base + ".{}.cv2.bn".format(q)
from_to_map[named_m_cv2_bn] = fromlayer[f]
cv1in = ch[f]
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
c3fromlayer = [named_m_cv1_bn]
named_m_bottle_cv1_bn = named_m_base + ".{}.m.0.cv1.bn".format(q)
named_m_bottle_cv2_bn = named_m_base + ".{}.m.0.cv2.bn".format(q)
bottle_cv1out = int(maskbndict[named_m_bottle_cv1_bn].sum())
bottle_cv2out = int(maskbndict[named_m_bottle_cv2_bn].sum())
bottle_args = []
#Bottleneck_C2f的传参,int(cv1in/2)是该模块的split操作
bottle_args.append([int(cv1out/2), bottle_cv1out, bottle_cv2out])
from_to_map[named_m_bottle_cv1_bn] = c3fromlayer[0]
from_to_map[named_m_bottle_cv2_bn] = named_m_bottle_cv1_bn
c3fromlayer.append(named_m_bottle_cv2_bn)
from_to_map[named_m_cv2_bn] = [c3fromlayer[-1], named_m_cv1_bn]
if q ==0:
args = [cv1in, cv1out, cv2out, n, args[-1]]
args.insert(3, bottle_args)
args_list.append(args)
from_to_map[named_m_cv1_bn] = fromlayer[f]
else:
args = [args_list[0][2], cv1out, cv2out, n, args[-1]]
args.insert(3, bottle_args)
args_list.append(args)
from_to_map[named_m_cv1_bn] = named_m_base + ".0.cv2.bn"
c2 = cv2out
fromlayer.append(named_m_cv2_bn)
print('args_list',args_list)
n = 2
else :
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
from_to_map[named_m_cv1_bn] = fromlayer[f]
fromlayer.append(named_m_cv2_bn)
cv1in = ch[f]
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
args = [cv1in, cv1out, cv2out, n, args[-1]]
bottle_args = []
c3fromlayer = [named_m_cv1_bn]
for p in range(n):
named_m_bottle_cv1_bn = named_m_base + ".m.{}.cv1.bn".format(p)
named_m_bottle_cv2_bn = named_m_base + ".m.{}.cv2.bn".format(p)
bottle_cv1out = int(maskbndict[named_m_bottle_cv1_bn].sum())
bottle_cv2out = int(maskbndict[named_m_bottle_cv2_bn].sum())
bottle_args.append([int(cv1out/2), bottle_cv1out, bottle_cv2out])
from_to_map[named_m_bottle_cv1_bn] = c3fromlayer[p]
from_to_map[named_m_bottle_cv2_bn] = named_m_bottle_cv1_bn
c3fromlayer.append(named_m_bottle_cv2_bn)
args.insert(3, bottle_args)
c2 = cv2out
n = 1
from_to_map[named_m_cv2_bn] = [c3fromlayer[-1], named_m_cv1_bn]
# print('from_to_map',from_to_map)
elif m in [SPPFPruned]:
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
cv1in = ch[f]
from_to_map[named_m_cv1_bn] = fromlayer[f]
from_to_map[named_m_cv2_bn] = [named_m_cv1_bn]*4
fromlayer.append(named_m_cv2_bn)
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
args = [cv1in, cv1out, cv2out, *args[1:]]
c2 = cv2out
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
inputtmp = [fromlayer[x] for x in f]
fromlayer.append(inputtmp)
elif m is Detect_v8:
from_to_map[named_m_base + ".m.0"] = fromlayer[f[0]]
from_to_map[named_m_base + ".m.1"] = fromlayer[f[1]]
from_to_map[named_m_base + ".m.2"] = fromlayer[f[2]]
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
if isinstance(f, int):
c2 = ch[f]
fromtmp = fromlayer[-1]
fromlayer.append(fromtmp)
else:
# #yolov8输出头接了连续3个输出卷积层 ,判断m is Detect_v8时并不是true,目前没找到原因。
#记录该层的输入bn层,即上一层的输出通道数
from_to_map[named_m_base + ".cv2.0.0.bn"] = fromlayer[f[0]]
from_to_map[named_m_base + ".cv2.0.1.bn"] = named_m_base + ".cv2.0.0.bn"
from_to_map[named_m_base + ".cv2.0.2.bn"] = named_m_base + ".cv2.0.1.bn"
from_to_map[named_m_base + ".cv2.1.0.bn"] = fromlayer[f[1]]
from_to_map[named_m_base + ".cv2.1.1.bn"] = named_m_base + ".cv2.1.0.bn"
from_to_map[named_m_base + ".cv2.1.2.bn"] = named_m_base + ".cv2.1.1.bn"
from_to_map[named_m_base + ".cv2.2.0.bn"] = fromlayer[f[2]]
from_to_map[named_m_base + ".cv2.2.1.bn"] = named_m_base + ".cv2.2.0.bn"
from_to_map[named_m_base + ".cv2.2.2.bn"] = named_m_base + ".cv2.2.1.bn"
from_to_map[named_m_base + ".cv3.0.0.bn"] = fromlayer[f[0]]
from_to_map[named_m_base + ".cv3.0.1.bn"] = named_m_base + ".cv3.0.0.bn"
from_to_map[named_m_base + ".cv3.0.2.bn"] = named_m_base + ".cv3.0.1.bn"
from_to_map[named_m_base + ".cv3.1.0.bn"] = fromlayer[f[1]]
from_to_map[named_m_base + ".cv3.1.1.bn"] = named_m_base + ".cv3.1.0.bn"
from_to_map[named_m_base + ".cv3.1.2.bn"] = named_m_base + ".cv3.1.1.bn"
from_to_map[named_m_base + ".cv3.2.0.bn"] = fromlayer[f[2]]
from_to_map[named_m_base + ".cv3.2.1.bn"] = named_m_base + ".cv3.2.0.bn"
from_to_map[named_m_base + ".cv3.2.2.bn"] = named_m_base + ".cv3.2.1.bn"
from_to_map[named_m_base + ".cv4.0.0.bn"] = fromlayer[f[0]]
from_to_map[named_m_base + ".cv4.0.1.bn"] = named_m_base + ".cv4.0.0.bn"
from_to_map[named_m_base + ".cv4.0.2.bn"] = named_m_base + ".cv4.0.1.bn"
from_to_map[named_m_base + ".cv4.1.0.bn"] = fromlayer[f[1]]
from_to_map[named_m_base + ".cv4.1.1.bn"] = named_m_base + ".cv4.1.0.bn"
from_to_map[named_m_base + ".cv4.1.2.bn"] = named_m_base + ".cv4.1.1.bn"
from_to_map[named_m_base + ".cv4.2.0.bn"] = fromlayer[f[2]]
from_to_map[named_m_base + ".cv4.2.1.bn"] = named_m_base + ".cv4.2.0.bn"
from_to_map[named_m_base + ".cv4.2.2.bn"] = named_m_base + ".cv4.2.1.bn"
#保存剪枝后的新通道数,如果不剪枝v8输出头则关闭
cv2_out1 = int(maskbndict[named_m_base + ".cv2.0.0.bn"].sum())
cv2_out2 = int(maskbndict[named_m_base + ".cv2.0.1.bn"].sum())
cv2_out3 = int(maskbndict[named_m_base + ".cv2.1.0.bn"].sum())
cv2_out4 = int(maskbndict[named_m_base + ".cv2.1.1.bn"].sum())
cv2_out5 = int(maskbndict[named_m_base + ".cv2.2.0.bn"].sum())
cv2_out6 = int(maskbndict[named_m_base + ".cv2.2.1.bn"].sum())
cv2_list=[[cv2_out1,cv2_out2],[cv2_out3,cv2_out4],[cv2_out5,cv2_out6]]
cv3_out1 = int(maskbndict[named_m_base + ".cv3.0.0.bn"].sum())
cv3_out2 = int(maskbndict[named_m_base + ".cv3.0.1.bn"].sum())
cv3_out3 = int(maskbndict[named_m_base + ".cv3.1.0.bn"].sum())
cv3_out4 = int(maskbndict[named_m_base + ".cv3.1.1.bn"].sum())
cv3_out5 = int(maskbndict[named_m_base + ".cv3.2.0.bn"].sum())
cv3_out6 = int(maskbndict[named_m_base + ".cv3.2.1.bn"].sum())
cv3_list=[[cv3_out1,cv3_out2],[cv3_out3,cv3_out4],[cv3_out5,cv3_out6]]
cv4_out1 = int(maskbndict[named_m_base + ".cv4.0.0.bn"].sum())
cv4_out2 = int(maskbndict[named_m_base + ".cv4.0.1.bn"].sum())
cv4_out3 = int(maskbndict[named_m_base + ".cv4.1.0.bn"].sum())
cv4_out4 = int(maskbndict[named_m_base + ".cv4.1.1.bn"].sum())
cv4_out5 = int(maskbndict[named_m_base + ".cv4.2.0.bn"].sum())
cv4_out6 = int(maskbndict[named_m_base + ".cv4.2.1.bn"].sum())
cv4_list=[[cv4_out1,cv4_out2],[cv4_out3,cv4_out4],[cv4_out5,cv4_out6]]
#传入yolo.py中的Detect_v8函数的参数,如果不剪枝输出头,则new_channel通道数为0
args=[2,[ch[f[0]],ch[f[1]],ch[f[2]]],[cv2_list,cv3_list,cv4_list]]
m_ = nn.Sequential(*(m(*args_list[i_p]) for i_p in range(n))) if n > 1 else m(*args) # module
# print('m_',m_)
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
# print('ch',ch)
# print('from_to_map',from_to_map)
return nn.Sequential(*layers), sorted(save), from_to_map
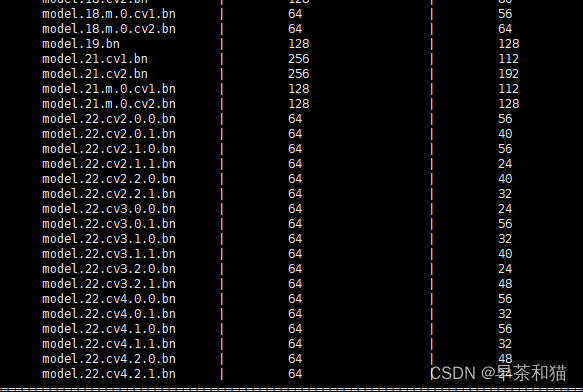
如果对yolov8输出头的卷积层进行剪枝,效果如下
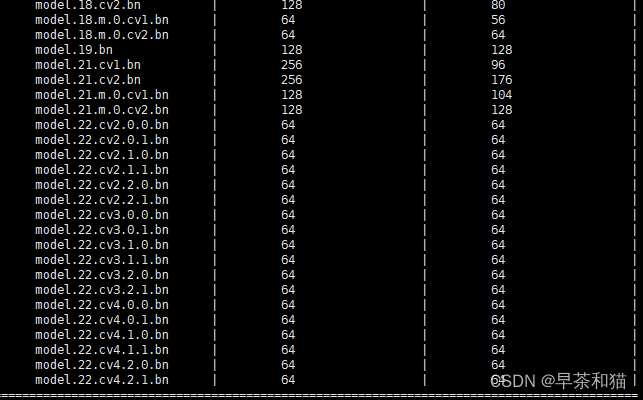
如果不想对输出头卷积层进行剪枝,可通过参数close_head来关闭对输出头卷积层通道数的剪枝,效果如下:
参数拷贝,重构并解析网络后,我们需要对解析后的网络填充参数,即找到解析后网络对应于原网络的各层参数,并clone赋值给重构后的网络,代码如下:
#读取剪枝后的模型
pruned_model = ModelPruned(maskbndict=maskbndict, cfg=pruned_yaml, ch=3).cuda()
# Compatibility updates
for m in pruned_model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect_v8, Model]:
m.inplace = True # pytorch 1.7.0 compatibility
elif type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
from_to_map = pruned_model.from_to_map
pruned_model_state = pruned_model.state_dict()
print('pruned_model_state',len(pruned_model_state.keys()))
print('modelstate',len(modelstate.keys()))
# print('pruned_model_state',pruned_model_state.keys())
assert pruned_model_state.keys() == modelstate.keys()
# ======================================================================================= #
changed_state = []
for ((layername, layer),(pruned_layername, pruned_layer)) in zip(model.named_modules(), pruned_model.named_modules()):
assert layername == pruned_layername
if isinstance(layer, nn.Conv2d) and not layername.startswith("model.22"):
convname = layername[:-4]+"bn"
if convname in from_to_map.keys():
former = from_to_map[convname]
if isinstance(former, str):
#convname model.4.0.m.0.cv1.bn,former model.4.0.cv1.bn
#layer Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4]+"bn"].cpu().numpy())))
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
# 判断是不是c2f中的bot块,如果是需要split一半,直接获取一半的输入通道数(可能这块的操作不够完美)
if former[8:]=='cv1.bn' or former[10:]=='cv1.bn' or former[9:]=='cv1.bn' or former[11:]=='cv1.bn':
len_indix=int(len(in_idx)/2)
in_idx=np.arange(len_indix)
w = layer.weight.data[:, in_idx, :, :].clone()
if len(w.shape) ==3: # remain only 1 channel.
w = w.unsqueeze(1)
w = w[out_idx, :, :, :].clone()
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(former, list):
orignin = [modelstate[i+".weight"].shape[0] for i in former]
formerin = []
for it in range(len(former)):
name = former[it]
tmp = [i for i in range(maskbndict[name].shape[0]) if maskbndict[name][i] == 1]
if it > 0:
tmp = [k + sum(orignin[:it]) for k in tmp]
formerin.extend(tmp)
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
pruned_layer.weight.data = w[:,formerin, :, :].clone()
changed_state.append(layername + ".weight")
else:
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
assert len(w.shape) == 4
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(layer,nn.BatchNorm2d):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername].cpu().numpy())))
pruned_layer.weight.data = layer.weight.data[out_idx].clone()
pruned_layer.bias.data = layer.bias.data[out_idx].clone()
pruned_layer.running_mean = layer.running_mean[out_idx].clone()
pruned_layer.running_var = layer.running_var[out_idx].clone()
if isinstance(layer, nn.Conv2d) and layername.startswith("model.22"):
convname = layername[:-4]+"bn"
print('convname',convname)
if convname in from_to_map.keys():
former = from_to_map[convname]
print('former',former)
if isinstance(former, str):
#convname model.4.0.m.0.cv1.bn,former model.4.0.cv1.bn
#layer Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4]+"bn"].cpu().numpy())))
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
w = layer.weight.data[:, in_idx, :, :].clone()
if len(w.shape) ==3: # remain only 1 channel.
w = w.unsqueeze(1)
w = w[out_idx, :, :, :].clone()
pruned_layer.weight.data = w.clone()
missing = [i for i in pruned_model_state.keys() if i not in changed_state]
pruned_model.eval()
pruned_model.names = model.names
# =====================================保存剪枝前后的模型============================================ #
torch.save({"model": model}, "prune/orign_model.pt")
model = pruned_model
torch.save({"model":model}, "prune/pruned_model.pt")
2、模型微调
读取剪枝后的模型,进行重新训练即可。
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = ckpt["model"]
maskbndict = ckpt['model'].maskbndict
#读取剪枝后的模型
model = ModelPruned(maskbndict, ckpt['model'].yaml, ch=3, nc=nc).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
LOGGER.info('No pruned weights loaded, please set the right pruned weight path ...') # report
return