yolov8-pose关键点检测
DOTA数据格式mAP计算工具:DOTA_devkit。
下载地址:https://github.com/978326187/DOTA_devkit
可参考:
https://blog.csdn.net/qq_40890765/article/details/126253925
一、使用dota_evaluation_task1.py文件计算mAP值。
DOTA格式
.
├── images
└── labelTxt
安装教程:(建议在Linux系统中进行环境安装,Windows问题重重)
1、首先安装swig;
pip isntall swig -i https://pypi.doubanio.com/simple
或者sudo apt-get install swig
2、为python创建c++扩展模块。
注意:必须在DOTA_devkit-master文件夹下运行以下命令进行编译:
swig -c++ -python polyiou.i
python setup.py build_ext --inplace
数据准备
detpath = r'/home/zhangxiao/DOTA_devkit-master/map_test/predict_rusult/Task1_ship.txt' # Path to detectionsdetpath.format(classname) should produce the detection results file.
annopath = r'/home/zhangxiao/DOTA_devkit-master/map_test/gt/SSDD_orient_annotation/{:s}.txt' # change the directory to the path of val/labelTxt, if you want to do evaluation on the valset
imagesetfile = r'/home/zhangxiao/DOTA_devkit-master/map_test/test_img_name.txt'
注意:文件夹需要修改的部分要特别注意:只要改前面文件夹的部分,后面/{:S}.txt或者/Task1_{:S}.txt不用动
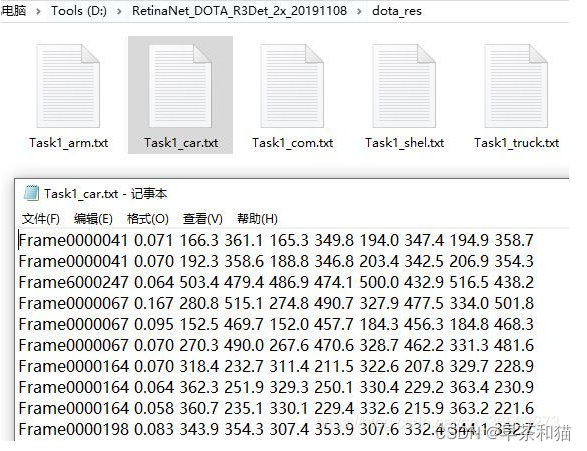
输出的每个类别的结果文件如下:
每个类有一个txt文件,在txt文件内,一行对应一个目标,第一个参数是图片名称,第二个是置信度,后面八个是旋转框四个点坐标。
注意:所有的置信度都会被列出来,在评估的时候,P-R曲线是置信度由大到小计算的。另外,可以通过ovthresh设置预测框和标签iou的阈值,在上面提到的评估脚本里,很容易找到,这个值越大,说明需要越大的iou才能被列为TP。
2、annopath:测试集标注文件的路径,包含每张图片的txt格式的标注文件,注意:标注文件名称必须与图片名称相同,且不能是数据集裁剪后的图片,具体解释见3、imagesetfile;
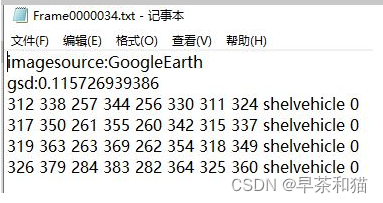
前两行是遥感数据的名称,不用管,可以去掉;
第三行shelvehicle是标注框的类别,0表示是否是困难样本标志;
名词解释:
imagesource:图像数据来源;
gsd:地面采样距离(一个图像像素的物理尺寸,单位为m),缺少该注释则为null;
poly:四边形边框的四点坐标,其中(x1,y1)用于表示OBB的顶点起点的位置,四个顶点按照顺时针进行排列(顶点顺序对于部分需要检测目标具体方位的场景非常重要)。如下图所示是OBB label的可视化形式,黄点代表四边形边框的起点,它指的是(a)飞机的左上角、(b)扇形棒球区域的中心、(c)大型车辆的左上角;
category:目标所属类别;
diffcult:该目标实例的检测难度,1为高,0为低。
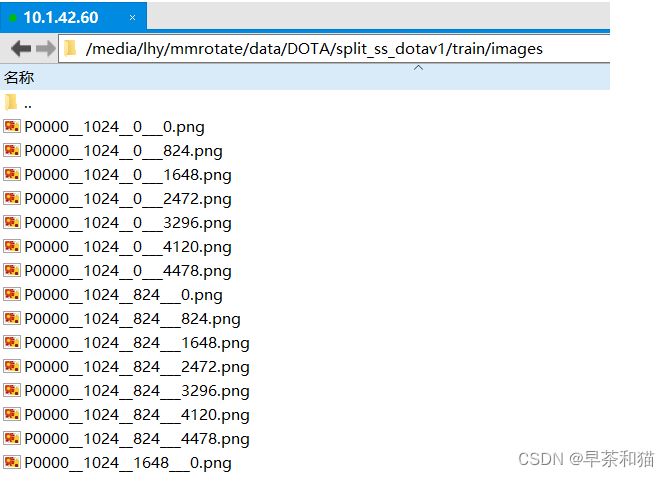
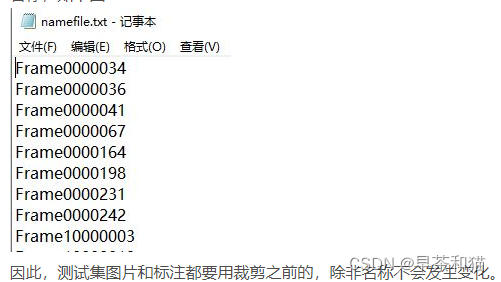
3、imagesetfile:测试集图片名称的路径,通过data_tools下的name2list.py文件提取图像名称,存入test_image_list.txt;(图中为namefile.txt)
是一个txt,列出了所有图片的名称,一行一个,没有后缀。
注意:数据集裁剪后的图片名称不能用,因为发生了变化,如下图:

yolov8_obb测试并保存结果
根据上述,我们需要获得
1、对应格式是每个类别的测试结果txt文件
2、测试图片的名称(去后缀)
3、测试图片的labeTxt的标签路径
运行eval_rotate_PR_V8.py,并将模型的测试结果进行存储。
#保存txt文件用于DOTA评估,可参考https://blog.csdn.net/qq_40890765/article/details/126253925
with open('datasets/dota/det_txt'+'/Task_{}.txt'.format(cls_name_list[cls_i]),'a') as f:
f.write(img_name.split('.')[0])
f.write(' ')
f.write(str(pred[pred_i, 5]))
f.write(' ')
f.write(str(pred_poly[0]))
f.write(' ')
f.write(str(pred_poly[1]))
f.write(' ')
f.write(str(pred_poly[2]))
f.write(' ')
f.write(str(pred_poly[3]))
f.write(' ')
f.write(str(pred_poly[4]))
f.write(' ')
f.write(str(pred_poly[5]))
f.write(' ')
f.write(str(pred_poly[6]))
f.write(' ')
f.write(str(pred_poly[7]))
f.write(' ')
f.write('\n')
f.close()
得到第一个,对应格式是每个类别的测试结果txt文件
得到第二个,测试图片的名称(去后缀)
import os
save_path='datasets/dota'
img_path='datasets/DOTAv1/val/images'
with open(save_path+'/imgnamefile.txt','w') as f:
for filename1 in os.listdir(img_path):
f.write(filename1.split('.')[0]+'\n')
得到第三个,测试图片的labeTxt的标签路径
运行dota_evaluation_task1.py文件,计算mAP值。确保下面的路径是准确的。
def parse_args():
parser = argparse.ArgumentParser(description='MMDet test (and eval) a model')
parser.add_argument('--detpath', default='/datasets/dota/det_txt/Task_{:s}.txt', help='test config file path')
parser.add_argument('--annopath', default='/datasets/DOTAv1/val/labelTxt/{:s}.txt', help='checkpoint file')
parser.add_argument('--imagesetfile', default='/datasets/dota/imgnamefile.txt', help='checkpoint file')
args = parser.parse_args()
return args
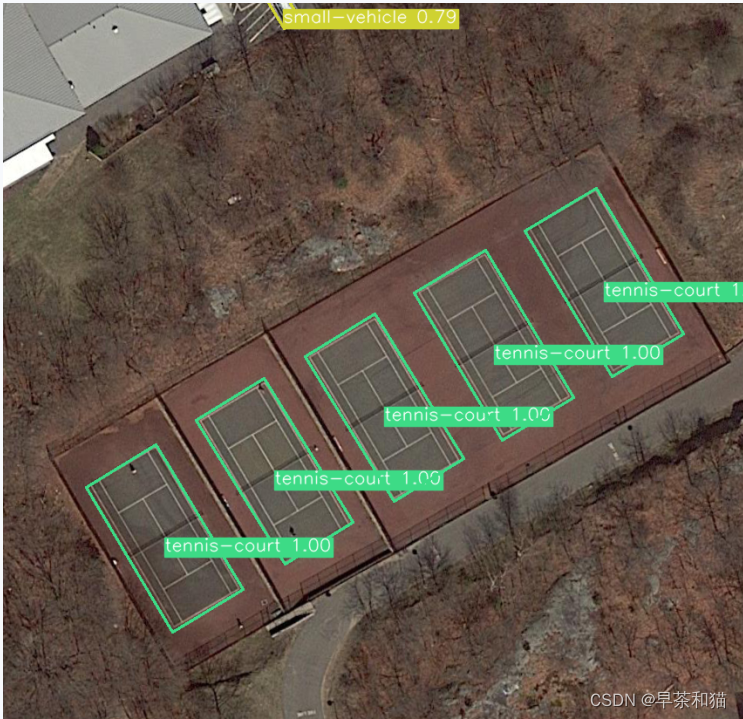
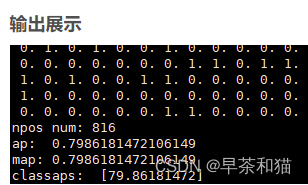
一些测试结果