概述
Stream是Java8的一大亮点,是对容器对象功能的增强,它专注于对容器对象进行各种非常便利、高效的 聚合操作(aggregate operation)或者大批量数据操作。Stream API借助于同样新出现的Lambda表达式,极大的提高编程效率和程序可读性。
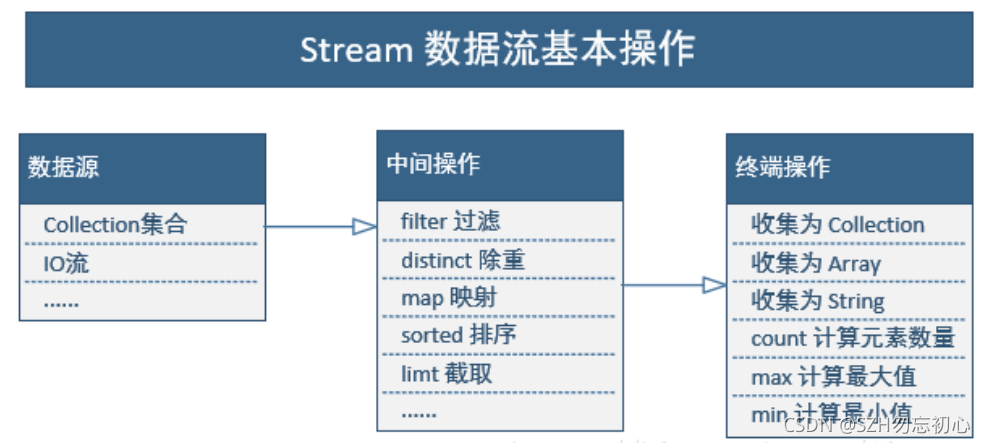
1. 流的常用创建方法:
//1.通过集合获取
Stream<User> stream = userList.stream();// 获取顺序流
Stream<User> userStream = userList.parallelStream();// 获取并行流(并发环境下会存在问题) -> userList = Collections.synchronizedList(new ArrayList<>());
//2.通过数组获取
int[] arr = new int[]{1,2,3,4,5,6};
Stream<Integer> intStream = (Stream<Integer>) Arrays.stream(arr);
//3.使用Stream中的静态方法:of()、iterate()、generate()
Stream<Integer> stream1 = Stream.of(1,2,3,4,5,6);
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
stream2.forEach(System.out::println); // 0 2 4 6 8 10
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
stream3.forEach(System.out::println);
2. 流的中间操作:
2.1 筛选与切片
- filter:过滤流中的某些元素
- limit(n):获取n个元素
- skip(n):跳过n元素,配合limit(n)可实现分页
- distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素
2.2 映射
- map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
- flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
2.3 排序
- sorted():自然排序,流中元素需实现Comparable接口
- sorted(Comparator com):定制排序,自定义Comparator排序器
3. 流的终止操作
3.1 匹配、聚合操作
- allMatch:接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false
- noneMatch:接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false
- anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false
- findFirst:返回流中第一个元素,返回值Optional类型
- findAny:返回流中的任意元素,返回值Optional类型
- count:返回流中元素的总个数
- max:返回流中元素最大值
- min:返回流中元素最小值
//1.学生总数
Long count = list.stream().collect(Collectors.counting());
//2.最大年龄 (最小的minBy同理)
Integer maxAge = list.stream().map(Student::getAge).collect(Collectors.maxBy(Integer::compare)).get();
//3.所有人的年龄
Integer sumAge = list.stream().collect(Collectors.summingInt(Student::getAge));
//4.平均年龄
Double averageAge = list.stream().collect(Collectors.averagingDouble(Student::getAge));
//5.总数+最大+最小+平均
DoubleSummaryStatistics statistics = list.stream().collect(Collectors.summarizingDouble(Student::getAge));
System.out.println("count:" + statistics.getCount() + ",max:" + statistics.getMax() + ",sum:" + statistics.getSum() + ",average:" + statistics.getAverage());
3.2 规约操作
- Optional reduce(BinaryOperator accumulator):第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素
3.3 收集操作
- collect:接收一个Collector实例,将流中元素收集成另外一个数据结构。
//装成list
List<Integer> ageList = list.stream().map(Student::getAge).collect(Collectors.toList());
//转成set
Set<Integer> ageSet = list.stream().map(Student::getAge).collect(Collectors.toSet());
//转成map,注:key不能相同,否则报错
Map<String, Integer> studentMap = list.stream().collect(Collectors.toMap(Student::getName, Student::getAge));
//字符串分隔符连接
String joinName = list.stream().map(Student::getName).collect(Collectors.joining(",", "(", ")"));
//分组
Map<Integer, List<User>> ageMap = list.stream().collect(Collectors.groupingBy(User::getAge));
List<User> users = ageMap.get(15);
//多重分组,先根据类型分再根据年龄分
Map<Integer, Map<Integer, List<Student>>> typeAgeMap = list.stream().collect(Collectors.groupingBy(Student::getType, Collectors.groupingBy(Student::getAge)));
排序
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
//@Data : 注在类上,提供类的get、set、equals、hashCode、canEqual、toString方法
//@AllArgsConstructor : 注在类上,提供类的全参构造
//@NoArgsConstructor : 注在类上,提供类的无参构造
//@Setter : 注在属性上,提供 set 方法
//@Getter : 注在属性上,提供 get 方法
//@EqualsAndHashCode : 注在类上,提供对应的 equals 和 hashCode 方法
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private long id;
private String name;
private String username;
private long pid;
private int sort;
}
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
User u1 = new User(1L, "张三1", "张三111", 0L, 1);
User u2 = new User(2L, "张三2", "张三222", 0L, 5);
User u3 = new User(3L, "张三3", "张三333", 0L, 4);
User u4 = new User(4L, "张三4", "张三444", 0L, 3);
User u5 = new User(5L, "张三5", "张三555", 0L, 2);
// 集合就是存储
List<User> userList = Arrays.asList(u1, u2, u3, u4, u5);
// 排序(升序)
List<User> collect = userList.stream().sorted(new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
return o1.getSort() - o2.getSort();
}
}).collect(Collectors.toList());
collect.forEach(System.out::println);
}
}
//返回 对象集合以类属性一升序排序
list.stream().sorted(Comparator.comparing(类::属性一));
//返回 对象集合以类属性一降序排序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed());//先以属性一升序,结果进行属性一降序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()));//以属性一降序
//返回 对象集合以类属性一升序 属性二升序
list.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二));
//返回 对象集合以类属性一降序 属性二升序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二));//先以属性一升序,升序结果进行属性一降序,再进行属性二升序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二));//先以属性一降序,再进行属性二升序
过滤
// 过滤符合条件的元素返回集合
List<User> collect = userList.stream().filter(user -> user.getId().equals(2L)).collect(Collectors.toList());
map: 改变集合中每个元素的信息
//添加__ssss的后缀
List<String> userList1 = userList.stream().map(user -> user.getName().concat("__ssss")).collect(Collectors.toList());
reduce:计算
// map + reduce 求和集合中sort这一列的总和
Integer reduce = userList.stream().map(User::getSort).reduce(0, (o1, o2) -> o1 + o2);
// 购物车: 单价*数量
Long reduce1 = userList.stream().map(user -> {
return user.getSort()*user.getId();
}).reduce(0L, (o1, o2) -> o1 + o2);
//添加__ssss的后缀
List<User> userList1 = userList.stream().map(user -> {
user.setName(user.getName().concat("_ssss"));
return user;
}).collect(Collectors.toList());
forEach循环遍历
//forEach
userList.stream().forEach(user -> {
System.out.println(user);
});
// 简写
userList.forEach(System.out::println);
普通去重
protected final <T> List<T> removeDuplicates(List<T> list) {
return new ArrayList(new LinkedHashSet(list));
}
distinct去重
distinct可以去重,如果集合是对象,就需要对象返回相同的hashcode并且equals方法的返回值是true。
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private long id;
private String name;
private String username;
private long pid;
private int sort;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
pid == user.pid &&
sort == user.sort &&
Objects.equals(name, user.name) &&
Objects.equals(username, user.username);
}
@Override
public int hashCode() {
return Objects.hash(id, name, username, pid, sort);
}
}
//distinct
List<User> userList= userList.stream().distinct().collect(Collectors.toList());
// 集合根据实体类中的单个字段姓名name去重复
userList = userList.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getName))),
ArrayList::new)
);
// 根据实体类中多个属性去重复
seqAloneFieldList = markDefEntity.getMarkFieldEntityList().stream().filter(item -> item.isSeqAlone() == true && item.getMarkFieldType().equals(MarkFieldTypeEnum.SERIAL_NUMBER) == false)
.sorted(Comparator.comparing(MarkFieldEntity::getMarkFieldType).thenComparing(MarkFieldEntity::getRelateObjValue))
.collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(o -> o.getMarkFieldType() + ";" + o.getRelateObjValue()))), ArrayList::new));
max & min
// max & min
Optional<User> maxUserOptional = userList.stream().max(new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
return o1.getSort() - o2.getSort();
}
});
if(maxUserOptional.isPresent()){
System.out.println(maxUserOptional.get());
}
findFirst: 返回集合中的第一个元素
// findFirst
Optional<User> firstUserOptional = userList.stream().findFirst();
if(firstUserOptional.isPresent()){
System.out.println(firstUserOptional.get());
}
groupingBy分组器
- 对List作分组操做
// 根据某一个属性分组
Map<String, List<Employee>> employeesByCity =
employees.stream().collect(Collectors.groupingBy(Employee::getCity));
- 统计每一个分组的count
Map<String, Long> employeesByCity =
employees.stream().collect(Collectors.groupingBy(Employee::getCity, Collectors.counting()));
System.out.println(employeesByCity);
assertEquals(employeesByCity.get("London").longValue(), 2L);
- groupingBy操做计算List集合计算分组平均值
Map<String, Double> employeesByCity =
employees.stream().collect(Collectors.groupingBy(Employee::getCity, Collectors.averagingInt(Employee::getSales)));
System.out.println(employeesByCity);
assertEquals(employeesByCity.get("London").intValue(), 175);
- groupingBy操做计算总和sum
Map<String, Long> employeesByCity =
employees.stream().collect(Collectors.groupingBy(Employee::getCity, Collectors.summingLong(Employee::getSales)));
分页
List<T> pageList = list.stream().sorted()
.skip((pageNum - 1) * pageSize) // 跳过前面多少条
.limit(pageSize)// 从(pageNum - 1) * pageSize之后取出pageSize条
.collect(Collectors.toList());
// 处理最终返回前5条,后面6条
if(preCodeList.size() > 11 ) {
List<String> preFiveList = preCodeList.stream().limit(5).collect(Collectors.toList());
List<String> lastSixList = preCodeList.stream().skip(preCodeList.size()-6).collect(Collectors.toList());
preCodeList.clear();
preCodeList.addAll(preFiveList);
preCodeList.addAll(lastSixList);
}
removeIf
userList.removeIf(user -> user.getId() == 0);