数据仓库
综合
1. OneData方法论的标准:

3. 缓慢变化维(SCD)常见的解决方案
- 重写维度值
在维度表中, 仅需以当前值重写先前存在的值, 不需要触碰事实表
缺点: 如果业务需要准确的跟踪历史变化, 这种方案是没法实现的, 并且在以后想改变时非常困难的 - 插入新的维度行
可以保留历史数据,维度值变化前的事实和过去的维度值管理那,维度值变化后的事实和当前的维度值关联
缺点: 虽然此方案能够区分历史情况,但是该方式不能将变化前后记录的事实归一未变化前的维度或者归一为变化后的维度 - 添加维度列
可以保留历史数据,可以使用任何一个属性列
(有些是只保留最新的维度值和最近的维度值,也有的是维度值一有变化就新增一个属性字段,都不算是很好的解决方案) - 拉链表
这是精确跟踪缓慢变化维度属性的主要技术,因为新维度行能够自动划分事实表的历史,所以这是一项非常好的技术
4. 如果一张表的某个字段作为join的字段,但是这个字段有倾斜的非常厉害,比如性别这个字段,有男1000万个,女5万,这时候数据倾斜如何解决?
给倾斜字段加上随机前缀, 或者
5. 数据源是来自于哪里
业务库,日志数据
6. 聊一下技术架构,整个项目每个环节用的什么技术这个样子
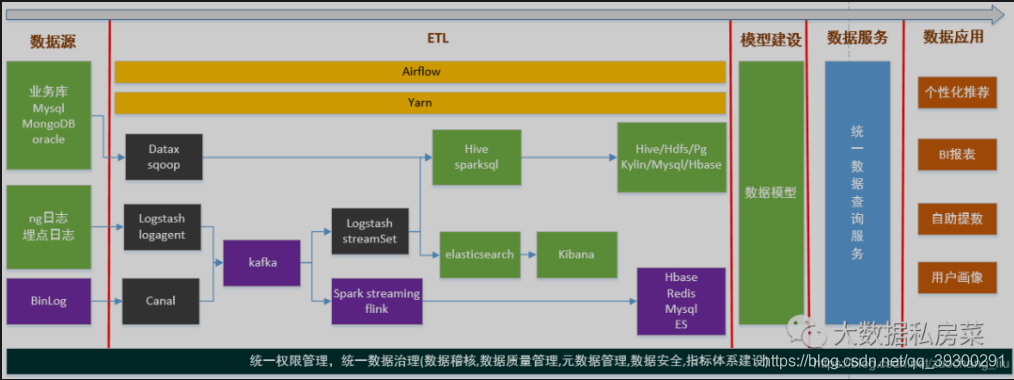
7. ods的增量能否做成通用的?
题目不明确
8. 从原理上说一下MPP和MR的区别
MPP跑的是SQL,而Hadoop底层处理的是MapReduce程序.
MPP虽然是宣称可以横向扩展Scale OUT,但是这种扩展一般是扩展到100左右,而Hadoop一般可以扩展1000+.
MPP数据库有对SQL的完整兼容和一些事务的处理能力,对于用户来说,
9. 你有什么想问我的吗?
可以问问技术架构,工作内容和数据量
9.1 数仓维度退化的影响是什么?
维度退化是指某个维度表中的所有属性都被合并到事实表中,而维度表实际上成为空表,缺少了实际意义的列,这种情况通常发生在高基数、低纬度的情况下。维度退化的影响主要包括:
-
数据冗余:事实表中包含了维度表的所有信息,导致数据冗余。
-
查询效率下降:事实表中包含较多冗余数据,会影响查询效率。
-
维护困难:因为维度表变为空表,维护起来较为困难。
因此,在数据建模时,需要根据实际情况对维度表进行合理设计,避免维度退化。如果维度表确实退化了,可以考虑对其进行优化,例如将一些常用字段抽取出来,形成一个新的维度表,或者使用聚合表等手段来避免维度表的退化。
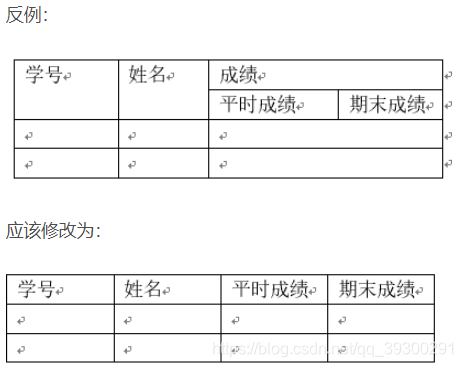
10. 三范式是哪三范?三范式常用于?
第一范式 1NF (列不可分割)
第一范式的条件:元组中的每一个分量都必须是不可分割的数据项。
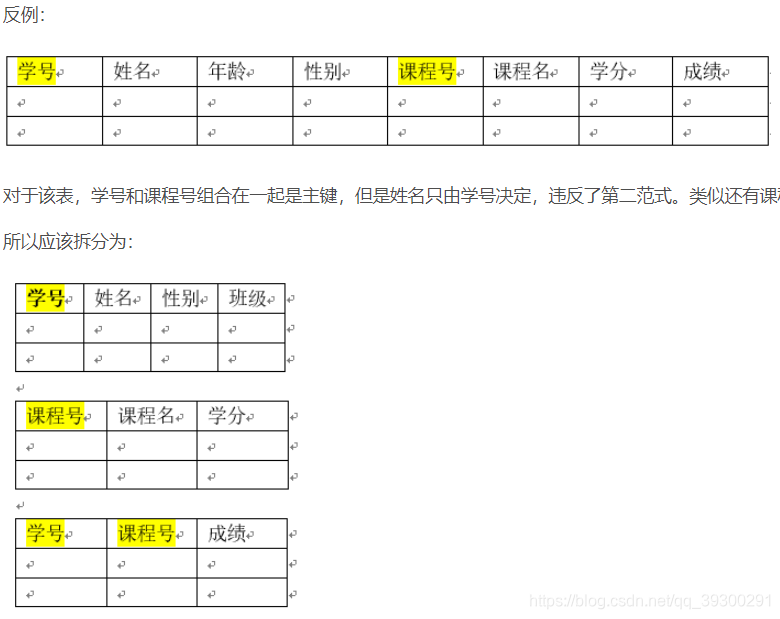
第二范式 2NF (非主属性完全依赖于主键)
第二范式的条件:在第一范式的基础上,所有的非主属性完全依赖于主键。完全依赖意味着不能依赖于主键的一部分属性。
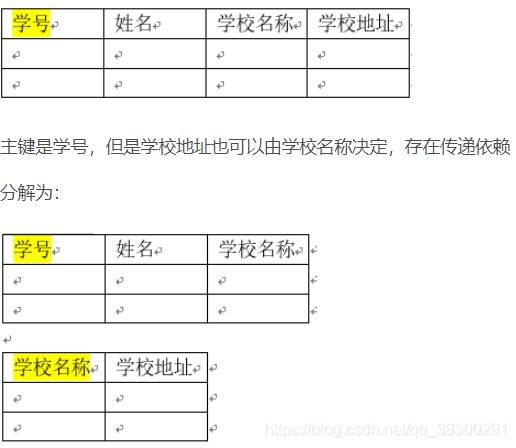
第三范式 3NF (非主(键)属性不能传递依赖于主键)
第三范式的条件:满足第二范式的基础上,非主属性都不传递依赖于主键
11. 数据血缘你们是怎么做的?
Atlas
12. 数仓-星型模型的优点与不足
优势:
1.围绕一个确定的主题,体现了数据仓库对数据结构和组织的要求。
2.简单,层级分明,便于理解
3.为OLAP提供了良好的工作条件,提高查询性能。
不足:
1.星型模型是非规范化的,它以空间来换取时间,造成数据冗余。
2.星型模型中各维度表主键的组合构成事实表的主键。当星型模型的维不能满足要求时,维的变化是非常复杂,耗时的。
3.当维的属性复杂时,处理维的层次关系比较困难
4.对“多对多”关系,星型模型无能为力。
13. 离线数仓整体流程?
flume(采集ng日志服务器) => hive (导入HDFS集群,load data到hive中) => spark (清洗过滤脱敏等,绑定全局guid,新老用户标记,集成geo地理维度) => hive (大宽表,切分主题,按主题查询) => hbase (固定报表直接导入) => kylin (多位指标统计报表查询) => presto (临时性指标查询)
14. 实时数仓整体流程?
ng日志 => flume (实时采集) => kafka (消息中间件分流离线或实时数据, 选择kafka的优点有:消峰,低延迟高吞吐,高容错,可扩展性高,解耦,可持久化到磁盘) => clickhouse(列导向数据库,是原生的向量化执行引擎,数据的压缩空间大,减少IO,写入速度非常快,非常适用于大量的数据更新,常用于OLAP. 缺点: 不支持事务,不支持真正的删除/更新)
HBASE
Hbase-Rowkey的设计?
rowkey设计原则:
- 等长、
- 唯一性、
- 散列
- 加盐(热点key需要在前缀加上随机数,使得rowkey根据随机生成的前缀分散到各个region上,可以有效避免热点问题)
- Hash(hash算法包含了MD5等算法,可以直接取rowkey的MD5值作为Rowkey)
- 字符串反转
数据采集(sqoop、flume)
1. sqoop导入hdfs的数据文件格式是什么?
在使用Sqoop将数据从关系型数据库导入到Hadoop分布式文件系统中(如HDFS),Sqoop支持多种文件格式,包括文本文件格式(TextFile)、序列化文件格式(SequenceFile)以及Avro文件格式(AvroDataFile)等。其中,文本文件格式是默认格式。
在Sqoop导入HDFS时,可以使用以下参数指定文件格式:
- -as-textfile:指定导出为文本文件格式,这也是默认的文件格式,这个参数是可选的。
- -as-sequencefile:指定导出为序列化文件格式。
- -as-avrodatafile:指定导出为Avro文件格式。
例如,以下命令可以将MySQL数据库中的表数据导入到HDFS中,文件格式为文本文件格式:
sqoop import --connect jdbc:mysql://mysql.example.com/mydatabase --username myuser --password mypassword --table mytable --target-dir /user/hadoop/myfolder --as-textfile
注意:在导入过程中,需要根据实际情况指定适合的文件格式,并针对数据文件格式进行相应的操作和编程。
KAFKA
1. kafka中生产者是如何把消息投递到哪个分区的?
org.apache.kafka.clients.producer.internals.DefaultPartitioner默认的分区策略是:
- 如果在发消息的时候指定了分区,则消息投递到指定的分区
- 如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
- 如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
2. kafka 消费者又是怎么选择分区的?
消费者以组的名义订阅主题,主题有多个分区,消费者组中有多个消费者实例:
1. 同一时刻,一条消息只能被组中的一个消费者实例消费
2. 如果分区数大于等于消费者,可根据消费者分区分配策略,一个消费者同时消费多个分区
如果分区数小于消费者,首先要知道,kafka在设计时要保证分区下消息的顺序,要做到这点首先消费者应该主动拉取(pull)数据,其次还要保证一个分区只能由一个消费者负责. 当两个消费者同时消费一个分区时,由于消费者自己可以控制读取消息的offset,就可能C1才读取到2,而C2读取到1,C1还未处理完,C2已经读到3了. 这就相当于多线程读取同一个消息,会造成消息的重复,且不能保证消息的顺序,跟主动推送(push)无异
3. 消费者分配策略:
3.1 range 分配策略是基于每个主题的
- 首先,将分区按数字顺序排行序,消费者按消费者名称的字典序排好序
- 然后,用分区总数除以消费者总数。如果能够除尽,则皆大欢喜,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区
3.2 roundrobin(轮询)
- 轮询分配策略是基于所有可用的消费者和所有可用的分区的
- 与前面的range策略最大的不同就是它不再局限于某个主题
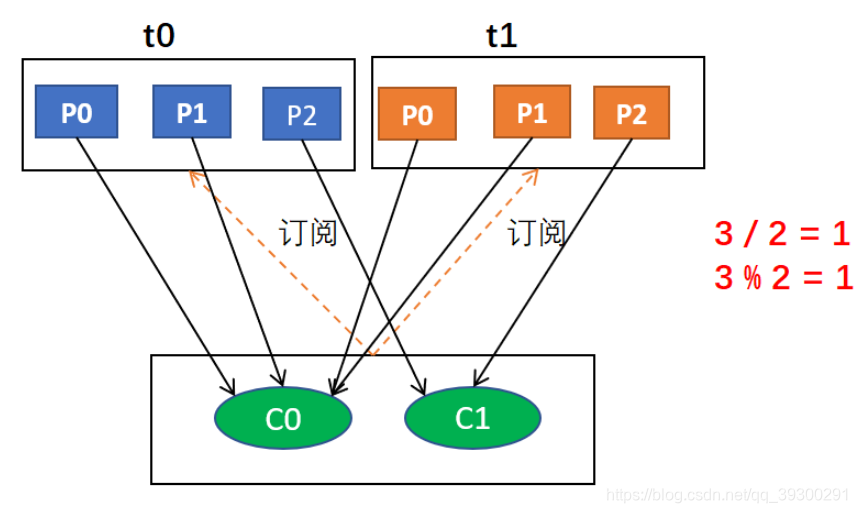
- 如果所有的消费者实例的订阅都是相同的,那么这样最好了,可用统一分配,均衡分配
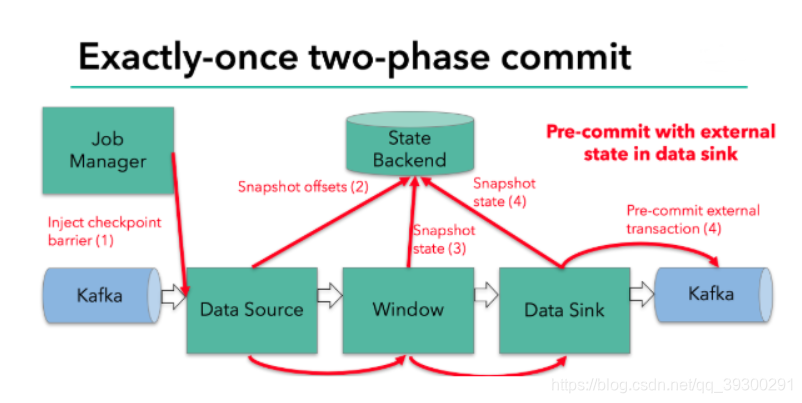
12. kafka是如何实现ExectlyOnce的?
kafka ==> kafka
分两步提交
jobmanager会协调每个TaskManager进行checkpoint操作, checkpoint默认数据保存在StateBackend中,默认StateBackend是内存级别的,也可以选择保存在外部存储系统(HDFS)中.
当checkpoint启动时,JobManager会通过RPC的方式将检查点分界线barrier发送到各个算子中,barrier会在算子间传递下去,只要算子接收到barrier,就会将算子当前的状态做快照然后持久化到Statebackend中.
当所有的SubTask都完成了checkpoint操作,会想jobmanager进行ack响应(0,1,-1).
jobmanager集齐了所有SubTask的应答,会向实现了checkPointListener的SubTask(也就是Sink)发送RPC消息,让其提交事务.
Sink中的状态是这段时间产生的数据,它会将这段时间的数据作为state保存到StateBackend中,如果checkpoint成功但是commit(提交事务)失败,这样子虽然数据已经在kafka中了,但是仍属于脏数据,不可以读,这样在任务重启时,会从StateBackend中偏移量以及之前的数据取出来,偏移量以及时最新的了,但是数据还没有提交完成,那么他就会将之前未提交成功的数据取出再提交.
source sink都可以保存状态,source可以记录偏移量,sink可以记录在这段时间产生的数据
Kafka消息数据积压,Kafka消费能力不足怎么处理?
- 如果是Kafka消费能力不足, 则可以考虑增加Topic的分区数, 并且同时提升消费组的消费者数量, 消费者数 = 分区数. (两者缺一不可)
- 如果是下游的数据处理不及时: 提高每批次拉取的数量. 批次拉取数据过少(拉取数据/处理时间<生产速度), 使处理的数据小于生产的数据, 也会造成数据积压.
kafka中哪些情景会造成消息漏消费?
先提交offset,后消费,优酷嫩恶搞造成数据的重复
kafka中的HW、LEO等分别代表什么?
LEO:每个副本的最后条消息的offset
HW:一个分区中所有副本最小的offset
topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加
bin/kafka-topic.sh --zookeeper localhost:2181/kafka --alter --topic topic-config --partitions 3
聊聊kafka Controller的作用?
负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作
kafka都有哪些特点?
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition,consumer group对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
7. kafka如何实现 ExecetlyOnce?
kafka --> kafka
分两步提交
jobmanger 会协调每个TaskManager进行checkPoint操作, checkPoint 默认数据保存在StateBackend中, 默认StateBackend是内存级别的, 也可以选择保存在外部存储系统(hdfs)中 .
当chegkpoint启动时,JobManager会通过RPC的方式将检查点分界线barrier发送到各个算子中, barrier会在算子间传递下去, 只要算子接收到barrier, 就会将算子当前的状态做快照然后持久化到stateBackEnd中 .
当所有的subtask都完成了checkPoint操作, 会向jobManager进行ack响应 .
jobManager集齐了所有subtask的应答 , 会向实现了checkPointListener的subtask(也就是sink)发送RPC消息, 让其提交事务 .
sink中的状态是这段时间的产生数据, 它会将这段时间的数据作为state保存到stateBackend中, 如果checkPoint成功但是在commit(提交事务)失败, 这样子虽然数据已经在kafka中了但是属于脏数据, 不可以读, 这样在任务重启时, 会从stateBackend中偏移量以及之前的数据取出来, 偏移量已经是最新的了, 但是数据还没有提交成, 那么他就会将之前未提交成功的数据取出在提交 .
source sink都可以保存状态 , source 可以记录偏移量 , sink可以记录在这段时间产生的数据
4. Kafka分区的目的?
分区对于kafka集群的好处是: 实现负载均衡. 分区对于消费者来说,可以提高并发度, 提高效率.
5. kafka的设计架构你知道吗?
kafka架构分为一下几个部分:
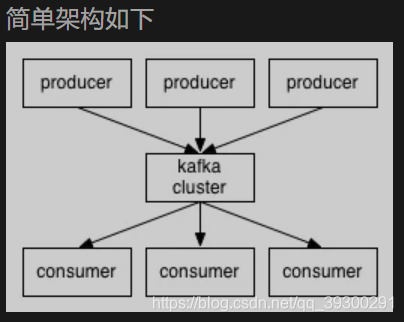
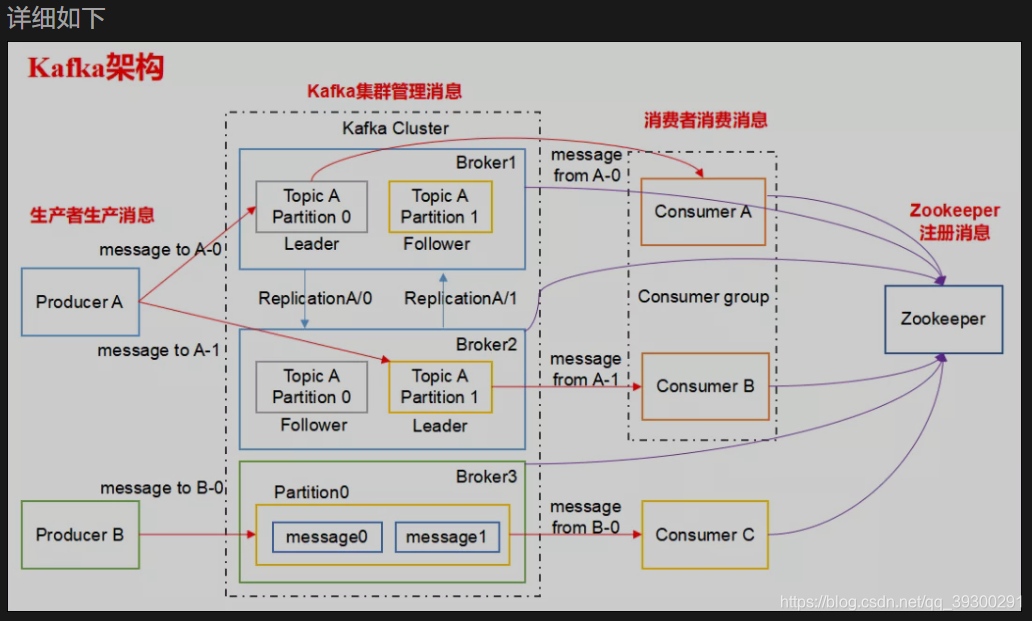
- Producer : 消息生产者,就是向kafka broker发消息的客户端.
- Consumer : 消息消费者, 向kafka broker取消息的客户端.
- Topic: 可以理解为一个队列, 一个Topic又分为一个或多个分区.
- Consumer Group : 这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段. 一个topic可以有多个Consumer Group.
- Broker : 一台kafka服务器就是一个broker. 一个集群由多个broker组成. 一个broker可以容纳多个topic.
- Partition : 为了实现扩展性, 一个非常大的topic可以分布到多个broker上,每个partition是一个有序的队列. partition中的每条消息都会被分配一个有序的id (offset). 将消息发给consumer, kafka只保证按一个partition中的消息的顺序, 不保证一个topic的整体(多个partition间)的顺序.
- Offset : kafka的存储文件都是按照offset.kafka来命名, 用offset做名字的好处是方便查找. 例如你想找位于2049的位置, 只要找到2048.kafka的文件即可. 当然the first offset 就是0000000000.offset
HIVE
1. Hive原理:
解析器将sql字符串转化成抽象的语法树,遍历语法树生成逻辑执行计划,优化器对执行计划进行优化,然后执行器将优化后的逻辑计划翻译成MapReduce任务
2. Hive执行流程
- 客户端提交查询等任务给Driver
- 编译器获得该用户的任务Plan
- 编译器Compiler根据用户任务去MetaStrore中获取需要的Hive的元数据信息
- 编译器Compiler得到元数据信息,对任务进行编译,先将HQL转换为抽象的语法树,然后将抽先的语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转换为物理的计划(MapReduce),最后选择最佳的策略
- 将最终的计划提交给Driver
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作
- 获取执行的结果
3. Hive数据倾斜优化方案:
数据倾斜的本质就是数据分配的不均匀,那么造成不均匀的原因有很多,比如热点key,非热点key分布不均匀等问题,那么需要定位到具体位置,发生原因才能对症下药. 从技术层面来说,首先怀疑是否是数据存在热点key的问题. 这里可以使用采样统计来判断是否有部分key记录过多,如果存在热点key,则可以采用单独处理或者二次聚合的方式来处理;如果不是热点key,那么有可能就是key的本身分配存在问题,那么可以选择增加随机前缀,使用group代替Distinct MapJoin的空值等一些手段,将key进行随机分区,
如果是业务层面来说,可能是提供计算口径有问题导致的数据倾斜,比如订单表和支付关联,正常100w从结果来看却是1000w或者更多,这样就需要考虑是否逻辑口径有问题了,以上两种方案,然后在结合一些参数优化就可以解决倾斜问题
3.1 hive使用mr和使用on spark的原理有什么不一样?产生的影响是什么
Hive在使用MR或Spark时的原理和影响是有所不同的。下面是它们的具体差别和影响:
- 原理不同:
Hive在使用MR时,将HiveQL语句翻译为MapReduce作业,然后将作业提交给Hadoop集群运行。而Hive在使用Spark时,将HiveQL语句转换成Spark任务进行执行。 - 影响不同:
(1)运行速度
Spark相对于MR具有更高的速度,因此可以更快地完成任务。这意味着使用Spark可以更快地向业务提供数据处理结果,同时也可以更快地进行调试和优化。
(2)资源利用率
Spark相对于MR具有更高的资源利用率,因为Spark任务可以复用执行过程中产生的结果数据,因此它们不需要在每次执行时重新计算。而MR需要重新计算所有数据,这会导致资源利用率下降。
(3)兼容性
Spark和MR的API不同,因此使用Spark进行Hive查询可能会与MR查询存在不同之处。这就需要在使用Spark时注意这些差异,确保查询结果与MR执行结果一致。
(4)开发复杂度
使用Spark可能需要使用Scala或Java等编程语言,而使用MR可能需要使用Java或Python等编程语言。因此,在选择使用哪种方式时,需要考虑开发人员的技能和开发复杂度。
综上所述,使用Spark相对于MR来说具有更高的性能和资源利用率,但需要考虑到兼容性和开发复杂度等影响,选择合适的方式进行查询和数据处理。
4. Hive大表join小表产生的问题,怎么解决?
容易产生数据倾斜,解决的话,就是将空值的key用随机值代替, 也可以将热点数据和非热点数据分开处理,最后在进行合并,然后也可以使用group by代替disitnct
5. Hive如何合并小文件?
可以在Map输入时合并小文件,这里可以配置在Reduce输出时合并小文件
Hive会在正常job结束后起一个Task来判断是否需要合并小文件,如果满足就会另外启动一个map-only job或者mapred job来完成小文件合并,这就需要配置一些参数
6. Hive中 udf udaf udtf 中有什么区别,怎么实现?
三者均为自定义函数
udf简化来说就是一对一的关系 就是用户自定义函数,是输入一行数据返回也是一行数据的自定义算子
Udaf简化来说就是多对一关系 ,就是用户自定义聚合函数,是输入多行函数返回一行数据
Udtf简化来说就是一对多的关系,就是用户自定义生成函数,是输入一行返回多行函数又被称为表生成函数
具体实现方式均需要继承对应的接口后实现里面的方法:
7. Hive元数据保存方式:
Hive元数据有三种方式保存元数据,分别为内嵌式,本地式,远程式
内嵌式则是将元数据保存到内嵌的Derby数据库当中,每次只能访问一个数据文件,不支持多会话连接
本地式则是将数据存入到本地独立的数据库当中,可支持多会话连接,
远程式则是将数据保存到远程独立的数据库当中,这样就避免每个客户端都去安装MqSQL
8. Hive四个表的区别:
内部表和外部表都是基本表,不同点就是数据的位置,在Hive中进行表的删除时内部表的数据会被一并删除。当外部表删除时,其所对应的数据文件不会被删除。故生成环境下一般都使用外部表,这样 并不会删除数据
分区表是将数据按照分区字段拆分存储的表,在hdfs中以文件夹的形式分别存放不同的分区数据
分桶表则是将分桶字段hash值分组拆分数据的表,在HDFS中表现为将单个数据拆分多个文件
分桶和分区的区别;表现形式的话分桶是文件,分区是文件夹,创建语句上的话分区是partition by 分桶是cluster by
数量上分区可增长,而分桶不可增长,作用上的话,分区只是避免全局扫描,分桶表会保持分桶查询结果到桶结构,进行join可以提高效率.
两者可结合使用,来方便数据的查询效率
10.insert into 和 override write的区别:
Insert into只是单纯的插入数据,返回会将历史数据和新插入的一起返回
Override write 会将历史数据remove后再插入数据;
11.Hive中的判断函数:
If 返回结果为true或者False
nvl:判断两值那个不为空
case when 类似于if else的多重判断
coalesce返回第一个非null值;如果所有值都为null,则返回null值
Is null判断是不是空值
Is not null判断否不是空值
12.Hive的创表语句:
建表语句的话有三种,
第一种:基础的创表语句也就是直接建表法,create table 表名(列名 属性 )row format delimited fields terminated by’分隔符’
第二种:like方式,create table 表 like表 复制表格式不包含数据
第三种:子查询方式(抽取原表的部分字段分析数据) create table 表 as select 列名from原表名
13.线上每天产生>=3g的业务日志,每天需要加载到hive的log表中,将每天的业务日志压缩后load到hive表中,最好使用那个压缩算法,说明原因?
我司通常使用snappy算法,原因是Hive的话会比较支持ORC的格式存储,因为orc的格式也是列式存储的,然后两者结合起来会更好一些,后面我了解到可以使用lzo这个因为该压缩算法可以切分,比率高,解压快非常适合日志
14.Union all 和union的区别?
union 去掉重复数据
union all 不去掉重复数据
15.说一下印象最深的一次优化场景,hive常见优化思路:
一方面可以根据存储进行优化,这里的话可以将压缩格式改变一下,也可以将小文件进行优化,另一方面就是计算方面的优化,这里的话可以进行本地化执行,JVM重用,调解MAP和Reducer个数,并行度的设置,再或者就是优化一些sql,或者是调解一下内存的分配问题
16.简述delete,drop,truncate的区别:
delete 删除行数据和整个表数据进行删除
drop 删除表内容和定义以及表结构也会删除
Truncate 摧毁表结构并重建
17Hive排序的区别;
Order by 全局排序 需要shuffle
Sort by 部分排序(及每个reducer内排序 全局不一定有序)
Distribute by 分区排序类似MR中的partition 后使用Sort by
Cluster by 当distribute by 和 sort by 所指定的字段相同时,即可以使用cluster by。
Group by 按照指定字段进行分组,相同的key到相同reduce 后续是聚合操作
17.Hive 里边字段的分隔符用的什么?为什么用\t?有遇到过字段里 边有\t 的情况吗,怎么处理的?
Hive默认字段的分隔符为ascii码中的控制符\001,建表时用fields terminated by ‘\001’,遇到\t的情况自定义InputForamt,替换其他分隔符在处理
18.Hive中MapJoin的原理:
大概流程就是:当发生MapJoin的时候,小表会被复制分发到Map端,并加载到内存当中,然后顺序扫描大表根据key在内存中依次进行关联join,避免shuffle过程,但是需要注意map join没有reduce,所有文件的数量和map的数量有关,这里要注意小文件的问题
19.Hive的row_number中distributer by和partition by的区别?
row_number() over( partition by 分组的字段 order by 排序的字段)
row_number() over( distribute by 分组的字段 sort by 排序的字段)
注意:
partition by 只能和order by 组合使用
distribute by 只能和 sort by 组合使用
20.Hive开发中遇到什么困难?
存储格式问题Parquet不支持Date
数据过滤的问题 sql做left join 操作时,on两边都是null值时,所有数据被过滤
当做join操作时,如果出现null值,可能会导致没有数据,此时需要将null字段设置为默认值
小文件的问题,需要将其合并会在控制小文件的产生,以及有可能查收中文乱码的问题
21.Hive常用函数有哪些函数?
函数的话可以分为两大类,一类为内置函数,一类为自定义函数:其中内置函数又分为数学函数,收集函数,类型转换函数,日期函数,条件函数,字符函数 内置的聚合函数,内置的表生成函数,
其中常用的有:
size 返回map或者数组中的数据类型
Cast 类型转换以免后续计算出现异常
Datediff 时间差
Date_add 添加时间
Date_sub 减少时间
Uninx_timestamp 返回日期的毫秒值
If 判断是否满条件
Cocat 字符串的合并
Count 返回条数
Sum 求和
Avg 求平均值
Hive 列转行,把某一列的数据,在一行中展示。 lateral view explode
select *from 表 lateral view explode(split(列,‘切分’)) 表名 as 列名
Hive 行转列 使用函数:concat_ws(’,’,collect_set(column))
说明:collect_list 不去重,collect_set 去重。 column 的数据类型要求是 string
select 列,concat_ws(’拼接符’,collect_list(列名)) as 别名 from 表名 group by 字段;
22.手写sql 连续活跃:
– 第二段 根据登陆时间减去排列顺序 得出用户连续登陆的分组
SELECT user_id,date_sub(login_time,rank) as login_group,min(login_time) as start_login_time
,max(login_time) as end_login_time,count(1) as continuous_days
FROM (
– 第一段首先根据用户分组,登陆时间排序,结果按照登陆时间升序排列
SELECT user_id,login_time,row_number() OVER(PARTITION BY user_id order by login_time) as rank
FROM test.user_login
) a
GROUP BY user_id,date_sub(login_time,rank)
23.Hive 中 left semi join 和 left join的区别?
Left semi join只显示左表的信息,在select后面不能出现查询右表的字段,否则报错,where条件中也不可以有右表字段出现 而left join 可以显示右表字段,并且where条件中也可以有右表字段出现 并且where中出现了右表字段则等同于join 和inner join
Left semi join 如果右边有重复的数据,对应的左表没有重复数据,那么就不会有重复的数据产生,如果两表都有则会和左表一样
而 left join 的右表有重复的数据对应左表没有则会产生重复数据,如果两表都有重复则查出的结果为两边的乘积
Left join 时where没有右表字段,那么当右表的数据不存在而左表存在,那么之后返回左表的信息
Left semi join 当右表中不存在时,不显示任何信息
24.Hive 的执行引擎,spark和MR的区别?
Spark的话是基于内存进行计算的,效率会略快 而MR是基于磁盘进行计算的效率会略慢一些,但是对于大量数据Hive on spark 可能会出现内存溢出的问题
25.Hive中的join底层MR是怎么实现的?
Join的话分为两种join一种是mapjoin这种只适合与一张小表去join一张大表的情况下,而且还会有一定的优化,大体分为两步先是将小表的数据缓存到内存中的哈希表中,读完后会将哈希表序列化为哈希文件,然后会分发的到每个Mapper的本地磁盘上进行join,这样就会减少shuffle以及reduce的操作,但是局限于只支持小表join大表的情况.
common join这种就是在没有更改配置文件以及不符合上述规则情况下进行join,整个过程包含map shuffle 以及reduce阶段.在map端输出的时候以 join on条件中的列为key,如果join多个关联键则以这些关联键组合为key map输出的value为join 之后关系的列;同时在value 中还包含tag信息,用于标明value对应那个表,按照key进行排序,shuffle阶段是将key进行哈希值后分发给不同的reduce,reduce阶段根据key进行join,并且通过tag的信息标明数据来源.
26.建好外部表以后用什么语句将数据加载到表中?
数据在本地的话:load data local inpath本地路径 into table 表名
数据在hdfs的话:load data inpath hdfs路径+文件 into表名
27.Hive和传统的数据库有什么区别?
查询语言的区别:HiveSQL是HQL语言,传统SQL是SQL语句:
数据存储的位置不同:HIVE的数据存储在Hdfs中,而传统数据库存储在块设备或者是本地文件
数据格式的不同:hive数据格式可以用户自定义,而传统sql有系统自己的定义格式
数据更新:hive不支持数据的写操作,而sql可以支持数据更新
索引区别:hive中没有索引,而sql有索引
延迟性区别:Hive延迟性率高,而mysql延迟性低
数据规模区别:hive存储规模超级大,而mysql存储一些少量数据
底层执行原理区别:HIve底层是mr 而mysql是excutor执行器
可拓展性:hive高于传统数据库
28.HIve导入数据的方式
本地导入:load data local inpath本地路径 into table 表名
hdfs导入:load data inpath hdfs路径+文件 into表名
查询导入:create table表 as select * from ods.test
查询结果导入:insert into 表 tmp.test select * from ods.test
29.怎么将字符串中的数字拆出来?
可以通过substr来进行截取字符串后将数字输出
格式1: substr(string string, int a, int b);
格式1:
1、string 需要截取的字符串
2、a 截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取)
3、b 要截取的字符串的长度
格式2:substr(string string, int a) ;
格式2:
1、string 需要截取的字符串
2、a 可以理解为从第a个字符开始截取后面所有的字符串。
33 map join的缺点
只适合进行小表join 大表,并不是很灵活
34大表join分桶的原因
提高效率.因为此时可以对两张大表的字段进行分桶,那join的话就是按照一个一个桶来join的 这样就完美解决了,但是两表必须确保分桶数量为倍数关系,否则会改变join条件,影响最终结果
35 hive去重的几种方法:
我知道大概如下几种方法.group by distinct row_number 可以取出为一的值以及collect__set是将某列转一个数组返回,并且去重
36 hive 如何取样
大概分为三种情况:
- 随机抽样
随机采样使用rand()函数和limit关键字. 其实总distribute和sort关键来用来保证抽取的数据是随机分布的,这种方式比较有效率. order by rand()也可以实现上述的功能,但性能不好SELECT name FROM employee DISTRIBUTE BY rand() SORT BY rand() LIMIT 2;
- 分桶抽样
这是一种特殊的抽样方法,适用于分桶表,并做了优化.select语句置顶要采样的具体列,当需要采样整行- 数据块抽样
随机抽样实现的话需要使用rand()函数来进行抽取,
数据块的需要使用tablesample()函数来进行取样,可以指定大小,行数.
分桶的话和数据块函数一样.但是参数会略多一些,是将rand()和tablesample 组合使用
37 row number ,rank ,dense rank 区别
三者虽然都是对分过组的数据排序加序号,三个函数都是按照分组内从1开始排序
其中,ROW_NUMBER() 是没有重复值的排序(即使两条记录相同,序号也不重复的),不会有同名次。
DENSE_RANK() 是连续的排序,两个第二名仍然跟着第三名。
RANK() 是跳跃排序,两个第二名下来就是第四名。
38 hive的复杂数据类型说一下
Array(1,2,3,4) 装的数据类型是一样的
Map(‘a’,1,‘b’,c) key的类型一样
Struct(‘a’,1,2,34,4)装的数据是完全混乱的
1.38什么情况下只会产生一个reduce任务而没有maptask?
使用了udtf聚集函数却没带group by 用来order by.
40 有多个热点值的数据group by你们是怎么处理,优化逻辑说一下
其本质是因为数据分布不均匀,我工作的时候出现过数据倾斜,印象比较深刻的有:
前端埋点出了问题:出现大量的空key,大量的null值,选择丢弃掉。
当时的解决办法有2种,都试过:
第一种:先使用粒度比较,细的先聚合,比如先市,区聚合,然后再聚合一次,分多次聚合(直接在hive里搞就行)。
第二种:用spark代码,先把北京的取出来,在北京的前面加随机数,分到不同的task里面去,做完一次聚合后,然后再把随机数丢掉,再来一次聚合,这样速度提高10几倍,最后存到hive表里。缺点要写spark代码,略微有点麻烦。
41空key你们如何给随机值:
用case when给空值分配随机的 key值,使用指定字符串加随机值
42 where和having的区别?
用的地方不一样.where用于增删改查的所有情况,但是having只能用于查询,执行顺序也不一样
where在聚合之前起作用,但是不能放在group by 之后,而having不能放在group by之前,
然后子句也有区别,where子句的条件表达式Having都可以跟,而反之不可以;
13. hive中如何合理利用分区分桶
分区: 是将表的数据在物理上分成不同的文件夹,以便于在查询时可以精准指定所要读取的分区目录,从而来降低读取的数据量
分桶: 是将表数据按置顶列的hash散列后分在了不同的文件中, 将来查询时, hive可以根据分桶结构, 快速定位到一行数据所在的分桶娃儿进件,从而来提高读取的效率
14. hive调优的参数调优
## 让可以不走mapreduce任务的, 就不走mapreduce任务
hive> set hive.fetch.task.conversion=more;
## 开启任务并行执行
set hive.exec.parallel=true;
## 同一个sql允许秉性人物的最大线程数
set hive.execparallel.thread.number=8
## 设置jvm重用
## JVM重用对hive的性能具有非常大的影响,特别是对于很难避免小文件的饿场景或者task特别多的场景,这类场景大多数执行时间都很短. jvm的启动过程可能会造成相当大的开销, 尤其是执行的job包含有成千上万个task任务的情况
set mapred.job.reuse.jvm.num.tasks=10;
## 合理设置reduce的数目
## 方法1: 调整每个reduce所接受的数据量大小
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
## 方法2: 直接设置reduce数量
set mapred.reduce.tasks = 20;
## map端聚合,降低传给reduce的数据量
set hive.map.aggr=true;
## 开启hive内置的数倾优化机制
set hive.groupby.skewindata=true;
15. hive调优的sql优化
1. where条件优化
优化前(关系型数据库不用考虑会自动优化)
```sql
select m.cid,u.id from order m join customer u on( m.cid =u.id )where m.dt='20180808';
```
优化后(where条件在map端执行而不是在reduce端执行)
```sql
select m.cid,u.id from (select * from order where dt='20180818') m join customer u on( m.cid =u.id);
```
2. union优化
尽量不要使用union (union 去掉重复的记录) 而是使用union all 然后再用group by去重
3. count distinct优化
不要使用coun(distinct cloumn),使用子查询
```sql
select count(1) from (select id from tablename group by id) tmp;
```
4. 优化子查询
消灭子查询内的group by , count(distinct), max , min 可以减少job的数量
5. join优化
开启map端join 当小表(小于25M)连接大表的时候会自动广播
> set hive.map.aggr=true;
16. hive调优中的数据倾斜
主要表现: 任务进度长时间维持在99% ,查看任务监控页面,发现只有少量(1个或几个) reduce子任务未完成. 因为其处理的数据量和其他reduce差异过大.
原因: 某个reduce的数据输入量远远大于其他reduce数据的输入量
17. hive中的join底层mapreduce是如何实现的?
hive这个的Join可分为两种情况:
- Common Join (Reduce阶段完成join)
- Map Join (Map阶段完成join)
Common Join: 如果没有开启hive.auto.convert.join=true或者不符合MapJoin的条件,那么Hive解析器会将join擦欧洲哦转换成Commin Join, 在Reduce阶段完成join. 并且整个过程包含Map, Shuffle, Reduce阶段.
- Map阶段
读取表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键.则以这些关联键的组合作为key,
Map输出的value未join之后需要输出或者作为条件的列; 同时在value中还会包含表的Tag信息,用于标明次vlaue对应的表; 按照key进行排序. - Shuffle阶段
根据key取哈希值,并将kye/value按照哈希值分发到不同的reduce中 - Reduce阶段
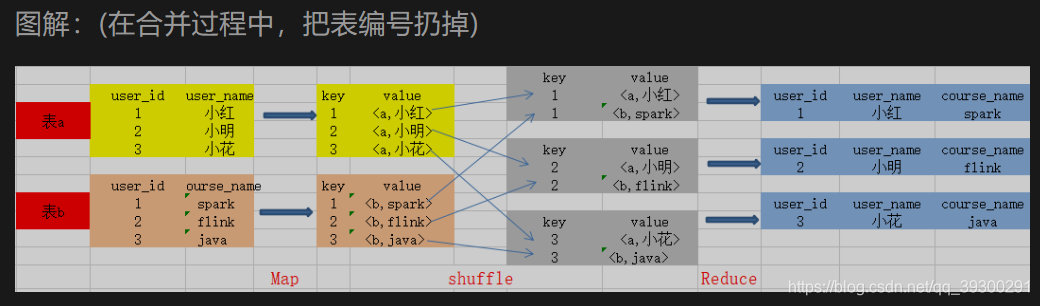
根据key的值完成join操作,并且通过Tag来识别不同表中的数据. 在合并过程中,把表编号扔掉
22. 四个by的区别?
- order by 会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序),然而只有一个Reducer会导致当输入规模较大时,消耗较长的计算时间.
- sort by 不是全局排序,其在数据进入reducer前完成排序,因此,如果用sort by进行排序并且设置mapped.reduce.task > 1 ,则sort by只会保证每个reducer的输出有序,并不是保证全局有序.(全排序实现: 先用sort by保证每个reducer输出有序, 然后再进行order by归并下前面所有的reducer输出进行单个reducer排序, 实现全局有序.)
在sort by 之前我们还有配置属性:
//配置reduce数量 set mapreduce.job.reduces=4;
- distribute by 是控制在map端如何拆分数据给reduce端的. hive会根据 distribute by后面的列, 对应reduce的个数进行分发, 默认是采用hash算法. sort by 为每个reduce产生一个排序文件. 在有些情况下, 你需要控制某个特定行应该到哪个reducer, 这通常是为了进行后续的聚集操作. distribute by刚好可以做这件事.
(因此,distribute by经常和sort by配合使用. 并且hive规定distribute by语句要写在sort by 语句之前)
注意: 当distribute by和sort by所指定的字段相同时,即可以使用cluster by.(cluster by置顶的列只能是升序,不能指定asc和desc.)
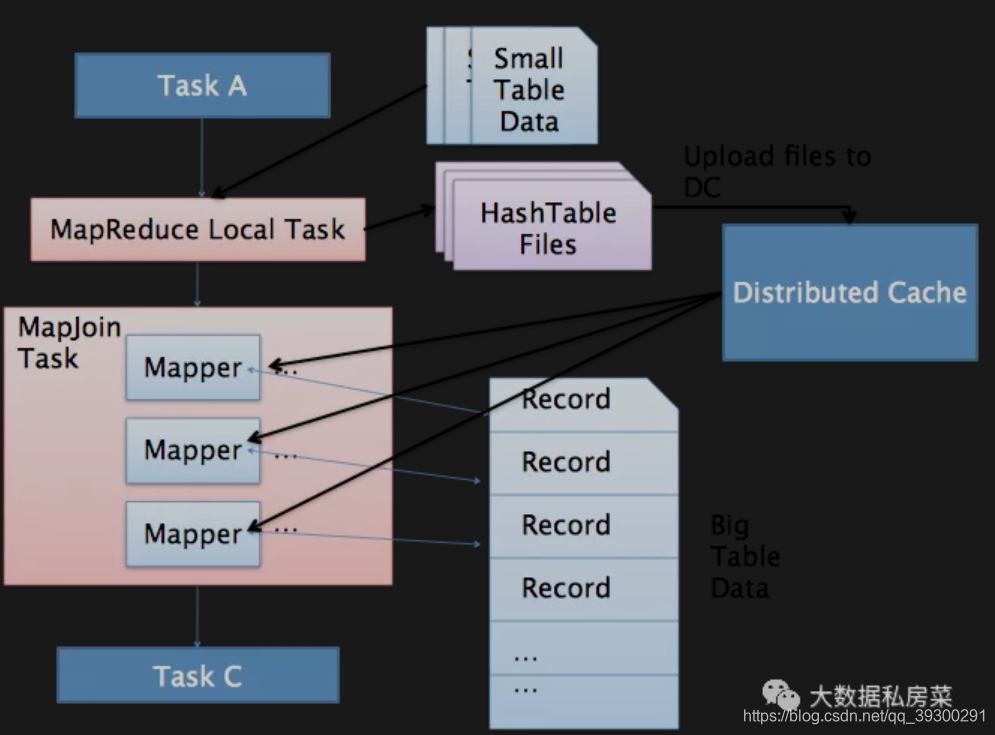
18. 什么是hive中的MapJoin?
hive中的MapJoin简单来说就是在Map阶段将小表数据从HDFS上读取到内存的哈希表中,读完后将内存的哈希表文件,在下一个阶段,当MapReduce任务启动时,会将这个哈希表文件上传到Hadoop分布式缓存中,该缓存会将这些文件发送到每个Mapper的本地磁盘上. 因此,所有Mapper都可以将此持久化的哈希表文件加载回内存,并像之前一样进行Join. 顺序扫描大表完成Join. 减少昂贵的shuffle操作及reduce操作
MapJoin分为两个阶段:
- 听过 MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会HashTableFiles进行压缩.
- MapReduce Job在Map阶段, 每个Mapper从Distribute Cache读取HashTableFiles到内存中,顺序扫描大表,在Map阶段直接进行Join,将数据传递给下一个MapReduce任务
19. left join和 left semi join的区别?
left semi join : 只展示a表的字段,因为left semi join 只传递表的join key 给map阶段
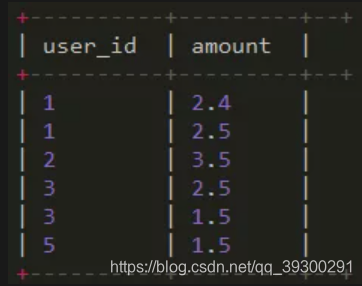
select
*
from wedw_dw.t_user t1
left semi join wedw_dw.t_order t2
on t1.user_id = t2.user_id
;
结果:
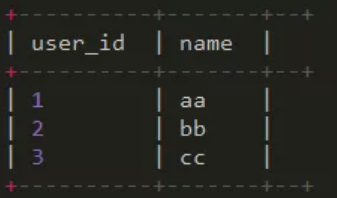
20. Hive里边字段的分隔符用的什么?为什么用\t?有遇到过字段里变有\t的情况吗,怎么处理的?为什么不用Hive默认的分隔符,默认的分隔符是什么?
hive默认的字段分隔符为ASCII码的控制符\001,建表的时候用fields terminated by ‘\001’
遇到过字段里有\t的情况,自定义InputFormat,替换为其他分隔符再做后续处理
21. Hive内部表和外部表区别及各自使用场景
- 区别:
内部表:加载数据到hive所在的HDFS目录,删除时,元数据和数据文件都删除
外部表: 不驾到数据到hive所在的HDFS目录, 删除时,只删除表结构
这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据 - 什么时候使用内部表,什么时候使用外部表
- 每天采集的ng日志和埋点日志,在存储的时候建议使用外部表,因为日志数据是采集程序实时采集进来的,一旦被误删,恢复起来非常麻烦, 而且外部表方便进行数据的共享.
- 抽取过来的业务数据,其实用外部表或者内部表问题都不大,就算被误删,回复起来也是很快的,如果需要对数据内容和元数据进行紧凑的管理,那还是建议使用内部表
- 在做统计分析时候用到的中间表,结果表可以使用内部表,因为这些数据不需要共享,使用内部表更为合适. 并且很多时候结果分区表我们只需要保留最近3天的数据,用外部表的时候删除分区时无法删除数据
22. 在Hive的row_number中,distribute by 和 partition by 的区别
row_number() over( partition by 分组字段 order by 排序字段 ) as rn
row_number() over( distribute by 分组字段 sort by 排序字段 ) as rn
注意: partition by 只能和order by组合使用
distribute by 只能和sort by 使用
SPARK
1. RDD属性?
- 有多个分区, 分区数量决定并行度
- 一个功能函数作用在分区上,函数决定计算逻辑
- RDD和RDD存在依赖关系,可以根据关系恢复失败的任务
- 分区器决定数据到那个分区当中
- 最优位置,即将Executor中的Task调度数据所在节点,要求Worker和DN部署在同一节点或者Onyarn,通过访问NN获取数据位置信息
2.算子分为那几类?(RDD支持哪几种类型操作)
大致可以分为两类,
一类为Transformation 变换/转换算子这种并不会触发提交作业并且是lazy模式,延迟执行的,
Action算子在RDD上运行计算,并返回结果给Driver或写入文件系统
3.分别列出几个常用的transformation 和action算子?
Transformation算子:map 将数据做函数运算 reducebykey聚合 groupbukey分组 sortbykey排序 union求并集 join
Action算子:count返回所有元素 collect将rdd的数据转换为数组 first第一条 max最大值 min最小 foreach
–补充: 窄依赖和宽依赖的区别?
窄依赖: 父RDD中, 每个分区内的数据, 都只会被子RDD中特定的分区所消费
宽依赖: 父RDD中, 分区内的数据, 会被子RDD内多个分区所消费
– spark中shuffle的类型
1.2 之前使用 hashShuffle , 1.2 之后使用SortShuffle 在进行shuffle时不会生成更多的小文件
- hashShuffle shuffle 时会生成横夺的小文件
- SortShuffle 也会生成中间的临时文件, 但最后会merge到一起, 同时会生成一个索引文件
4. 创建RDD的几种方式?
- 集合并行化穿件(有数据)
val arr = Aarray(1,2,3,4,5)
val rdd = sc.parallelize(arr)
val rdd = sc.makeRDD(arr)
- 读取外部文件系统, 如HDFS,或者读取本地文件(最常用的方式)(没数据)
//读取HDFS上的文件
val rdd2 = sc.textfile("hdfs://linux01:9000/data")
//读取本地文件
val rdd2 = sc.textfile("file:///root/user/data.txt")
- 从父RDD转换成新的子RDD
调用Transfomation类的方法,生成新的RDD
5.Spark 运行流程
启动spark context,后向资源管理器申请资源运行Executor并启动Standalone Executor Backend ,Executor向Spark context申请task,spark context将任务分发给executor,spark context构建dag,将dag划分为stage,将taskset发送给Taskscheduler最后由scheduler将task发送给executor运行,运行结束后释放资源
6.Spark 有哪些运行模式,
本地的local模式,standalone模式,spark on yarn模式,以及spark on mesos模式其中standalone和spark on
Yarn模式,spark on mesos为集群模式
7.Spark中coalesce和repartition的区别
- 关系:
两者都是用来改变RDD的partition数量的,
repartiton底层调用的就是coalesce方法:coalesce(num partitions,shuffle = true) - 区别:
repartition一定会发生shuffle, coalesce根据传入的参数来判断是否发何时能shuffle
一般情况下增大rdd的partiton数量使用
repartition,减少partition数量时使用coalesce
8.Sort by和 Sort by key的区别?
Sort by是对标准的RDD以及KV的RDD进行排序,并且他是在spark0.9.0之后引入的,而sort by key只是对KV的RDD 进行排序
9.Map和MapPartitions的区别
Map的话是RDD中的每一个元素进行操作
Map partition,是对RDD的每一个分区的迭代器进行操作,返回是迭代器
10.数据存入Redis 优先使用map map Partitions for each for each
Partition 那个?
使用for each partition
map,map partitions的话是转换类型有返回值
for each的话只可以迭代一个元素,
而使用for each partition的话他每一次迭代一个分区并且该方法没有返回值
11.Reduce by key 和group by key 的区别?
Reduce by key会传一个聚合函数相当于group by key+map Values,并且会有一个分区聚合,而group by key并没有
12.Cache和check point 的区别:
两者虽然都是持久化,但是cache是将公用的或者重复使用的RDD按照持久化级别进行优化
Check point就是将业务非常长的逻辑计算的中间结果优先缓存HDFS上,
为了效率我们可以在check point之前cache一下
13.Spark streaming流式统计单词数量代码
14.简述一下map和flat map区别和场景?
Map是对每一条函数进行指定操作,然后返回为每一条输入返回一个对象,而Flat Map函数则是两个操作的集合,即是”先映射后压平”操作和map一样,对每一条输入进行指定的操作,然后每一条返回一个对象,最后将所有对象合并为一个对象
15.Spark中的广播变量的用途?
使用广播变量,每个executor的内存中,只驻留一份变量副本,而不是对每个task都传输,这样就可节省网络IO提升性能
16.以下代码会报错么?如何解决?val arr=new ArrayList[String];
arr.foreach(parintln)
Val会报错,需将其改成val arr:Array[String]=new ArrayListString;arr.foreach就不会出现空指针异常了
17.说一下你用过的会产生shuffle的算子?
Distinct,去重 reducebykey 聚合 group bykey 聚合分组 aggregatebykey 按照key进行聚合 sortbykey排序算子 coalesce重分区
18.请写出创建dateset的几种方式?
可以直接通过create Dateset创建 然后也可以通过 case class 样类创建一个sql list ARRAY RDD 再转成dataset
19.描述一下RDD和DataFrame dataset的区别?
RDD的话一般不支持Spark和mlib同时使用,RDD不支持spark sql 操作
DataFrame:他和RDD以及Dataset的不同它的每一行的类型固定为row 只有通过解析才能获取各个字段的值
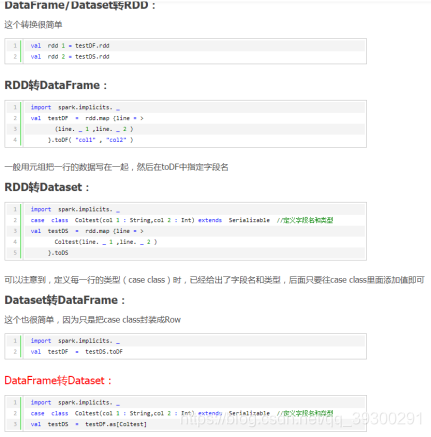
DataFrame和set一般与spark ml同时使用.也均支持spark sql 的操作.支持一些特别方便的保存方式
Dataset和dataframe拥有完全相同的成员函数,区别只是每一行的数据不同dataset的每一行不一样,而dataframe的为row类型的
19.1. 三者之间的互转
20.描述一下Spark是怎么划分stage的,描述一下shuffle?
划分思路整体就是:从后往前推,遇到宽依赖就断开,划分一个stage,遇到窄依赖就将这个RDD加入该stage
从广义上来讲就是从Map端输出数据到Reducer输入的整个过程可以广义的称为shuffle,shuffle横跨Map端和Reduce端,在Map端包括spill过程,包括输出排序,溢写合并等操作,Reduce端包括copy和sort过程,copy过程就是向各个Map任务拉取所需的数据,先回放到内存当中,达到一定程度就会输出到磁盘当中,所谓的sort就是这个合并的过程,一般都是一边copy一边sort
21.Spark在yarn上运行需要做那些关键的配置工作?如何kill某个Application?
这需要看是什么模式,两种模式的配置略有不同client模式需要设置指定内存,核数,而cluster模式并不需要指定
Cluster运行模式大致如下:首先客户端先向yarn提交job,然后ResouceManager 为该job在某一个NodeManager上启动ApplicationMaster,和Diver,AM启动后完成初始作业,diver生成一个DAG图,scheduler划分stage,AM向RM申请资源,RM返回Executor信息,AM通过rpc启动Executor,Executor向diver申请Task,Executor执行task,执行结果写入外部或者返回Driver端
可以通过命令行输入yarn application -kill 输入对应的appid 来进行杀死
22.通常来说,Spark与MR相比,Spark运行效率高一些,请说明效率跟高来源于Spark的内置那些机制.并列举spark运行模式?
23.RDD中的数据在那?
Rdd的数据存储在数据源当中,rdd只是一个抽象的数据集,我们通过RDD的操作就相当于对数据进行操作
24.如果对RDD进行cache操作后数据在哪里?
如果是第一次支持cache的话会被加载到各个Executor进程的内存中,第二次就会直接从内存中读取,而不是磁盘
25.Spark中 partition的数量有什么决定
是和Task的数量一一对应的,也可以通过参数来设置
.26.Scala里面的函数和方法有什么区别
方法不可以作为单独的表达式存在,而函数可以,并且函数必须要有参数列表,方法可以没有参数列表,函数名只代表函数的本身,方法则是调用方法
27.SparkStreaming怎么进行监控?
可以通过界面进行监控,程序监控,以及API进行监控
28.Spark 判断shuffle的依据是什么?
是通过其父RDD的一个分区中的数据可能分配到子RDD的多个分区中
29.Scala有没有多继承?可以实现多继承么?
如果是class的话可以继承一个,如果是集成trait可以多继承.
30.SparkStreaming和Flink的区别?
Spark Streaming是基于微批次准实时处理的,所以它采用DirectDstream的方式计算出每个partition要取数据的offset范围,拉取一批数据形成RDD进行批处理.而且该RDD和kafka的分区是一一对应的
Flink是真正的流式处理,他是基于事件触发机制进行处理,在kafka Consumer拉取一批数据以后,Flink将其处理之后变成逐个Record发送的事件触发式的流处理,另外Flink支持动态的发现新增topic和partition而SparkStreaming和0.8版本的kafka结合不支持,后续和0.10版本的结合支持了
31. SparkContext的作用
个人理解的话,他就是Spark功能的主要入口,它代表和spark集群的连接,能够用来在集群上创建RDD , 累加器 , 广播变量等. 每个JVM里只能存在一个处于激活状态的SparkContext, 在创建新的SparkContext之前必须调用stop()来关闭之前的SparkContext.
- 补充: DAGScheduler介绍
这在spark中是个相当重要的角色. 作为一个高级调度层, 在stage级别进行调度. DAGSchedule将一个job划分成不同的stage, 并且持续跟踪那些RDD与stage输出有实质的对应关系. 然后据此找出最有的调度方案来运行该job.
这里应该关注的是DAGScheduler是将不同的饿stage作为任务集来提交的,而且每个TaskSet任务集中的任务是相互独立的,也就是说这些任务可以给予集群上的已有数据直接运行.
stage划分,如何区分宽依赖和窄依赖
判断是 宽依赖和窄依赖可以一句是否有shuffle操作来进行,也可以从父RDD和子RDD之间的依赖关系来确定.
32.Spark Streaming读取kafka数据为什么选择直连?
因为一个RDD分区对应一个kafka分区,一个分区可以生成一个task,这个task不会丢失,会一直盯着这个分区,并且不停的读取数据
33.离线分析什么时候使用spark core 和spark sql?
可以根据数据来进行判断,如果你拉取的是格式化的数据可以使用sparksql非格式化的使用spark core进行计算 spark core在机器学习的迭代过程,可能会略快与spark sql 大概就是这样
34.Spark streaming实时数据不丢失的问题
这个问题的话,分两种情况.第一种是使用Receiver的机制保证数据的丢失,这种的是在sparkstreaming中另外启用预写日志,这样同步保存所有收到的数据到分布式的文件系统当中,以便恢复,另一种的话就是依靠Direct的方式来确保,这种是依靠checkpoint机制来确保数据不丢失,这个是在每次spark streaming消耗数据后将消费数据的offsets更新到checkpoint当中
35.简述宽窄依赖概念,group bykey reduce bykey,map,filter,union五种操作哪个是宽依赖,哪个是窄依赖
宽依赖:父RDD的一个分区被子RDD的多个分区使用:group by key reduce bykey 是宽依赖,会产生shuffle
窄依赖:父RDD的一个或者少量分区被子RDD的一个分区使用,例如 map filter union等操作,并不会产生shuffle
36.数据倾斜可能会导致那些问题,如何排查监控,设计之初要考虑那些来避免?
会导致内存溢出(OOM),导致整个任务失败.可以通过Spark的web UI来查看当前运的stage各个task分配的数量,从而进一步确定问题,亦可以通过KEY来进行统计,最开始的话可以过滤掉异常数据后进行操作,也可以提高Shuffle的并行度,这种适用于大量的key分配到同一个task上,也可以通过自定义partitioner来将key进行打散,但是这种适用与不同的key被分配到同一个Task上,也可以将Reduce端的join转化为Map端join,这样适用与某一边的数据足够小,可以被广播到各个Executor中,如果是两张表都很大的话可以使用拆分join完再union,或者将key加盐后将小表扩大N倍后join这种适用于一个数据集存在倾斜的key比较多,另外一个数据集比较平均情况下适用,
37.有1千万条短信,有重复,以文本的形式存储,一行一条,请用五分钟,找出重复最多的
这种的话之前了解过,我们可以采用哈希表的方法,将着1千万条分成若干组进行边扫描便建散列表,第一次扫描取首尾字节,中间随便两个字节作为hash code传入到表中并记录下地址和信息长度以及重复次数,同时Hash code且等长就是疑似相同,比较一下,相同记录只加一次进表中,但会将重复次数加一,一次扫描以后,已经记录了各自的重复次数,进行二次处理的,分组后每份中的top必须保证不同,可用hash来保证,也可直接按照hash值的大小来分类
38.共享变量(广播变量和累加器)
共享变量通常是向spark传递函数时,比如使用map()函数或者filter()传条件时,可以使用驱动器程序中定义变量,但是集群中运行的每个任务都会得到这些变量的一份新副本,更新这些副本也不会影响驱动器中对应变量
广播变量允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。
累加器的话就是spark中提供的一种分布式的变量机制,其原理类似于,MR即分布式改变,然后聚合这些改变,累加器常见用途就是在调试时对作业执行过程中的事件进行计数,而广播变量就是高效分发较大的对象
39.当spark涉及到数据库的操作时,如何减少Spark运行中数据库连接数
可以使用for each Partition 代替foreach在foreach partition中获取数据库连接
40.特别大的数据怎么发送到Executor中?
41.Spark 优化做过那些方面的?
通常的话就是调整一下性能方面的优化,如重新分配资源,优化并行度等,Jvm调优,shuffle调优这个也是相当的重要,因为shuffle的话会占整个spark工作的50-90的百分比,在有的话就是spark调优这个的话就就是算子方面的调优,使用foreach partition代替foreach.map的话可以使用mappartition来替换,filter和coalesce的配合使用,避免数据倾斜,将reduce bykey等进行本地的聚合
42.Flat map底层编码实现?
底层就是将RDD每一个元素执行自定义函数f,这时这个元素的结果转换成iterator最后将这些再拼接成一个新RDD也可以理解成原本的每个元素由横向执行函数f再变为纵向,一直在回调,指到RDD内没有元素为止
43.Spark 1.x和2.x的区别
Data frame和dataset一体化了,只剩下Dataset了,flat map由返回list变为返回iterator了 ,foreach RDD不再返回null
更新状态的函数opation 不可再用,Spark Streaming中的ContextFactory类废弃.并且kafka的话只提供direct方式
44.Spark Streaming如何保证7*24小时运行机制
可以开启Chekpoint机制来确保7*24小时运行机制,这样主要是为了从失败中进行恢复,而RDDcheckpint主要是为了用状态的transformation操作,能够在其生产的数据丢失时进行快速修复
45.Spark Streaming是Exactloy-once么?
默认的情况并不是,而是At-least-once,但是我们可以使用幂等性以及事务来确保exactloy-once
46.Spark和MR区别?
Spark的话运算过程中将中间数据保存到内存当中,迭代效率略高,MR在计算过程中需要将结果落地磁盘,这样必然会有磁盘的IO操作影响效率;Spark的话容错性会高一些,因为他是弹性的数据集RDD来实现高效容错,而MR出错值能重新计算,这样成本略高,Spark和MR相比更加通用和灵活,但是Spark的生态过于复杂,比如各种RDD的差别,DAG图,stage的划分等等,而MR相比较简单,对性能要求也相对较弱.比较适合长期的后台运行,总结的话就是spark生态丰富,功能强大,性能更佳,适用范围更广,MR的话,更简单,稳定性好,适合离线的海量数据的挖掘和计算
47.Spark任务为何被yarn kill掉?
我之前了解到可能是某个进程占用的物理内存超过阈值然后会被yarn kill掉
48.TopN的具体实现步骤
这里以老师和学科举例 求出每个学科的老师topN
第一种的方法,可以先reducebykey 进行聚合,然后在根据学科分组聚合,然后在每个分组当中进行排序求出top N
第二中的方法就是按照学科进行过滤,每次第一个学科的数据进行排序
第三种的话就是自己定义分区器,然后将相同学科的数据放到同一分区内,在对每个分区进行排序
第四中的话就是在reduce bykey的同时调用自定义分区器,这样可以减少shuffle,提高效率
49.怎么可以实现在一个小时Topn的固定窗口下,求出0-10 0-20?
50.怎么知道这个算子是转换算子还是行动算子?
转换算子的话是会返回一个新的RDD,行动算子并不会返回RDD而是直接存储数据或者是打印最终结果
51.有状态缓存算子?
这个的话我了解过一个状态算子比如updatesatebykey,这个的话是返回一个新的并且带有状态的Dstream
52.Spark什么时候用到内存?什么时候用到磁盘?
53.Spark的堆外内存,堆内内存
堆内内存的话
YARN
1. yarn 流程:
- client向RM提交应用程序,其中包括启动该应用的AM的必须信息,例如AM程序、启动AM的命令、用户程序等。
- RM启动一个container用于运行AM。
- 启动中的AM向RM注册自己,启动成功后与RM保持心跳。
- AM向RM发送请求,申请相应数目的container。
- RM返回AM的申请的containers信息。申请成功的container,由AM进行初始化。container的启动信息初始化后,AM与对应的NM通信,要求NM启动container。AM与NM保持心跳,从而对NM上运行的任务进行监控和管理。
- container运行期间,AM对container进行监控。container通过RPC协议向对应的AM汇报自己的进度和状态等信息。
- 应用运行期间,client直接与AM通信获取应用的状态、进度更新等信息。
- 应用运行结束后,AM向RM注销自己,并允许属于它的container被收回。
2. yarn 调度策略:
FIFO Scheduler : 不适合共享集群,大型应用会占用集群中的所有资源, 每个应用必须等待直到轮到自己运行在一个共享集群中,更适合使用容量调度器或公平调度器。
Capacity Scheduler:容量调度器允许多个组织共享一个Hadoop集群,每个组织可以分配到全部集群资源的一部分。
FairScheduler:公平调度是一种对于全局资源,对于所有应用作业来说,都均匀分配的资源分配方法
FLINK
5.1.Flink计算实时落磁盘么?
流式处理,应该不需要落磁盘
5.2.日活DAU的统计需要注意什么?
这个的话不能使用增量进行统计,并且需要进行窗口去重,避免重复计算数据
5.3.Flink调优?
这个需要先查看 Metrics来判断问题出在哪里,基本可以看出是否是并行度不够,CPU以及内存存在不合理的问题,State设置也存在问题,然后进行一些优化,然后也有可能是产生了反压,这样就要控制一下吞吐,最后的话就是需要判断是否产生了OOM
5.4.Flink容错?
这个的话就是定期进行checkpoint储存oprator state及keyedstate到statebackend
5.5.Parquent格式的好处,什么时候快,什么时候慢
5.6.Flink中checkpoint为什么状态有保存在内存中的机制,为什么开启?
这样的可以开启数据的容错,帮助程序重启后可以恢复数据,避免数据的丢失
5.7.Flink保证Exactly_Once的原理?
首先需要开启Checkpoint 并且source支持数据的重发,sink支持事务,两次提交任务,比如Kafka或者就是支持幂等性,可以覆盖之前的数据,如redis这样就可以保证Exactly_once
5.8.Flink的时间形式和窗口,形式区别,以及运用的场景?
窗口可以分为两类,一类依据条数进行划分,一类依据时间进行划分.对于时间窗口又分为三类,滚动,滑动,会话窗口
三者区别的,滚动窗口,时间对齐,并且长度固定,数据没有重叠,这种我们在做BI统计的时候进行使用
滑动窗口的话数据会存在重复,这种我们在统计最近的一个时间段内进行统计
会话窗口时间不对齐.并且数据不会存在重复了,这种的话我们是在主播数据和数据直接间隔时间过长的场景
5.9.Flink背压说一下?
这个的话普遍就是由于处理数据的速度跟不上数据的发送速度,从而导致消息的堆积,这个就是基于产生这种情况的消息处理系统,这个流程大概就是记录数据进入Flink然后Task1处理,处理后的结果被系列化进缓存区,然后Task2从缓存区读取数据,如果缓存区数据很快填满,则发送数据将会下降
5.10.Flink的WaterMark机制说一下,以及如何解决数据乱序问题?
通过当前窗口中最大的计算时间减去延迟时间所得到的Watermark与窗口原始触发时间进行对比,当Watermark大于窗口原始触发时间时则触发窗口执行
一旦出现乱序,如果只根据数据的产生时间决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。
5.11.Flink on yarn执行流程
Flink任务提交后,客户端向HDFS上传Jar包和配置,之后向ResourceManager提交任务,ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster,启动后加载Jar包和配置构建环境,然后启动JobManager,之后ApplicationMaster向ResourceManager申请资源启动TaskManager,ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager,NodeManager加载Jar包和配置构建环境并启动TaskManager,TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
5.12.Flink双流join
双流join的话大致可以分为俩种:一种就是画窗口进行join 另一种就是interval join window join又可以细分三种:滚动,滑动,会话窗口进行join,窗口join都是 利用窗口的机制,先将数据缓存在窗口的 State中,当窗口触发计算后进行join,interval join 也是利用State存储数据在处理,区别在于state中的数据有失效机制,依靠数据触发数据清理,大致就是这些
5.13.Flink任务提交的方式
这个的话有两种提交的方式,一种为命令行提交,一种为web页面提交,命令行提交的话需要指定jobmanger的所在位置,类名,以及并行度,而web页面提交的话只需要简单的点几下就好
5.14.Slot的资源分配计划
5.15.Flink消费kafka发生partition变更,fink底层是不是reblance
5.16.Checkpoint原理
这个就是连续绘制分布式的快照,而且是非常轻量级,可以连续绘制,并且对性能不会有太大影响,但是默认情况下是关闭的,然后这些快照中核心的概念之一就是barrier,这些barrier被注入到数据流与记录一起作为数据流的一部分向下流动,每个barrier都带有快照ID,并且barrier之前记录都进入该快照
5.17.Checkpoint barrier对齐原理,非对齐原理(大概是流程,不知道原理)
对齐大概的流程,是在上游多个输入的情况下,当从一个输入中接受到barrier时,会将channel设为阻塞状态,并且将后续从该channel读取到的数据暂存在缓存中,当后续所有channel的checkpoint都达到后,将数据设置为可消费状态,并且开始Checkpoint
非对齐的流程,这个的话就是在接受多个输入情况下,每一个批次的checkpoint不会产生数据缓存,会直接交个下游进行处理,checkpoint的信息会被缓存在一个CheckpointBarrierCount的类型的队列中,它会标识一次checkpoint与其channel输入的checkpointBarrier个数,当barrier个数与channel个数相同则会触发.
5.18.Checkpoint 失败的场景
这个的话,我了解到的就是可能代码对于异常没有进行处理,让其抛出或者保存起来,从而导致的,还有的话就是内存不够充足,频繁GC,超出负载限制,还有的话就是外部问题,比如网络,机器等问题
5.19.Flink两段提交的原理
JobManager向Source发送barrier,开始进入Pre-Commint阶段,如果是内部状态的话,无需执行额外操作,仅仅是写入一些已知的状态变量,当checkpoint成功时,Flink负责提交这些写入,否则就取消,然后当source接收到后,将自身状态进行保存,然后将Barrier发送给下一个operator,当中间operator都进行保存后,将其发送给sink,sink对其进行预提交,预提交后,JM通知每个operator,这轮检查点已经完成,这个时候才会向kafka进行真正的Commint,以上就是两阶段的大概流程,如果出现这两种情况的话就可能回造成回滚,pre_Commint失败,就将其恢复到最近一次checkpoint的位置,如果成功,就必须确保commint也要成功,因此所有的operator必须对checkpoint最终结果达成共识,即要么都成功,要么就回滚
5.20.onTimer同state并发操作的安全问题
5.21.Flink savepoint和checkpoint有什么区别?
Checkpoint的侧重点是容错,即Flink作业失败并重启之后,能从之前的checkpoint恢复运行,而Savepoint的侧重点是”维护”,即Flink作业需要在人工手动干预下升级,重启,迁移或测试时,现将状态整体写入,等维护后在从其中恢复
Savepoint是基于checkpoint的机制创建的其本质还是Checkpoint
Checkpoint面向的是Flink Runtime本身,而Savepoint是面向的用户
Checkpoint的频率往往会比较高,并且存储格式也是非常轻量级别的,Savepoint则是以二进制的形式进行存储,执行起来会比较慢其贵
Checkpoint支持增量的,特别是对于超大状态的作业而言可以降低成本,Savepoint并不会连续自动触发,所以它没必要支持增量
5.22.Flink算子有哪些?
Map对DataStream数据进行数据处理
Filter 用于过滤记录
Flatmap可以理解为将元素摊平,每个元素变为0个1个或者多个
Keyby根据key进行分区
Reduce归并操作
Union可以将多个流合并到一个流当中 以便对合并的流进行集中处理
Join 根据key将两个流做关联
Eventtime 指定一个解决数据乱序问题,但是无法彻底解决乱序以及延迟的问题
Watermark 用于触发窗口
Fold 给定一个初始值,将各个元素逐个进行运算
Cogroup 关联两个流,关联不上的也保留下来
Split 将一个流分为多个流
5.23.Flink map和 flatmap比较
Map调用用户自定义的mapFunction对Data-Stream数据进行处理,形成Data-Stream其中数据格式可能会发生变化,常用做对数据集内的清洗和转换,基本是一对一服务,即输入一个元素输出一个元素
Flatmap的话就是输入一个元素输出多个元素了
5.24.Flink的CK了解么,说一下大致流程?
首先的话就是暂停处理新流入数据,将新数据缓存起来,然后的话就是将算子子任务的本地状态数据拷贝到一个远程的持久化存储上,继续处理新流入的数据,包括刚才缓存的数据
5.25.窗口的状态数据什么时候清除
这个的话,我之前了解到的是可以自己设置状态的保存时间,以及在任务代码当中设置是否保存状态,如果保存他就会保存到所指定的目标目录当中,如果不保存的话,任务停掉了,状态就会丢失掉
5.26.Flink有哪些窗口,介绍一下区别,会话窗口关闭是什么控制的?
窗口的话分为时间驱动或者是数据驱动的,时间驱动的可以分为滚动,滑动,会话三类
数据窗口又分为滑动和滚动窗口 滑动窗口的话不会产生重复的数据,滚动窗口会有一部分的数据产生重复
会话窗口的话会在没有数据产生的时间后将会话断开,也就是划分为一个窗口
会话窗口的关闭是由namespace进行控制的
5.27.Flink的编程模型
5.28.Flink的状态有了解么.有哪些?
状态分为Keyed State和Operator State两种类型,这两种里面又分为Managed State以及Raw State
两者的区别的话就是Keyed事先根据key进行了分区
5.29.Flink双流join,left join左流数据来了,右流一直不来会怎么样?
之前了解过应该会将左表数据进行输出,而右流数据的话会补null
5.30.作业挂掉了,恢复上一个Checkpoint的命令
8. flink的背压机制?
产生数据流的速度如果过快, 而下游的算子消费不过来的话, 会产生背压.
解决方法: 背压的监控可以使用 Web UI(localhost:8081) 可视化监控方法 , 一但报警就能知道. 一般情况下被压问题的产生可能是由于sink这个操作符没有优化好, 做一下优化就可以了. 比如如果是写入 ClickHouse, 那么可以改成批量写入,调大批次的大小等等策略.
9. WaterMark水位线的最大延迟时间这个参数, 如果设置的过大, 可能会造成内存的压力.
解决方法: 设置最大延迟时间小一些,然后把迟到元素发送到侧输出流中去. 晚一点更新结果.
10. 滑动窗口的长度如果过长,而滑动距离很短的话,flink的性能会下降的 很厉害
解决方法: 通过时间分片的方法,将每个元素只存入一个"重叠窗口", 这样就可以减少窗口处理中状态的写入.
11. flink yarn session 和 yarn per-job 是什么
yarn session: bin/yarn-session -jm jobmanager 内存 -tm tashmanager 内存 -s 槽数量 可以通过一个jobmanager在Web UI中启动多个job, 可以让多个job使用用一个jobmanager
yarn per-job:bin/flink run -m yarn-cluster -c 主类名 -p 并行度 -yjm jobmanager内存 -ytm taskmanager 内存 -ys 一个容器的槽数量
如果要跑一个实时的任务,里面有大量的状态,要是哟并yarn session模式还是per-job模式?
答: 使用yarn per-job模式,因为job里面有大量的状态,jobmanager要单独为一个job服务,不能让一个jobmanager为多个job服务,job里面的大量的状态checkpoint, 使用yarn-session模式jobmanager压力很大.
数据仓库
7.1.什么是大数据,千万级别的数据完全可以用传统的关系型数据库集群解决问什么用到大数据平台
大数据(big data)IT行业术语,是指无法在一定时间内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才具有更强的决策力.洞察发现力和流程优化能力的海量,高增长率和多样化的信息资产
传统关系型数据库很难做数据治理,而且需要考虑到业务发展带来数据海量增长,所以搭建大数据平台来支持
7.2.什么是数仓,建设数仓碰到过什么问题
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
问题的话,就是业务的梳理,主题的划分,模型建设,开发规范方面回答
例子:
数仓建设初期我们需要了解各种业务,有些业务过于复杂对我们的要求比较高,我们就需要和业务开发进行沟通,
需要统一我们的计算口径以及对应的数据类型,以避免数据类型不太匹配.还有的就是根据最开始开发的时候需要确保一些命名规范,表的规范,还有最终根据事实表进行建模的时候需要选择什么模型,还有就是用什么来作为用户唯一标识,等等,就是扯,什么优化,集群怎么选择的,
7.3.维表和宽表的考察
维表数据一般根据ods层数据加工生成,在设计宽表的时候可以适当的用一些维度退化手法,减少事实表和为标的维表的关联.
7.4.数仓表命名规范
Ods dwd 层
表名一律小写 规则:[层次].[业务][表内容][周期+处理方式]
Dw dws层
一律小写 规则:[层次].[主题][表内容][周期+处理方式]
dw层以后表内容参考业务系统表名,做适当处理,分表规则可以没有
7.5.三范式
第一范式 :表中的每一列都是不可拆分的原子项
第二范式:满足第一范式的基础下,没有部分依赖
第三范式:满足一二范式的基础下,没有依赖传递
7.6.数据仓库模型建设可以使用范式建模么?
ODS层是符合三范式的,但是在之后建模过程中一般使用星型模型,以空间换时间
7.7.拉链表使用场景
维护历史状态,以及最新状态数据
适用情况:
1.数据量比较大
2.部分字段需要更新
3.需要查看某一时间点或者时间段的历史快照信息,如某一订单在某一时间点的状态,某一用户在过去某一时间下单数 表举例:物流表,订单表,会员等级表,用户等级表,用户级别表(青铜,白银,黄金,砖石等等不同级别有对应的福利信息)
4.更新比例和频率不是很大 如表中信息变化不是很大,每天保留一份全量,那么每天全量会保存很多不变的消息,浪费资源
优点
1.满足反应数据的历史状态
2.最大程度节省存储
7.8.数据库和数据仓库的区别
实际是在问你OLTP和OLAP的区别
数据库:是一种逻辑概念,用来存放数据的仓库,通过数据库软件来实现,数据库由许多表组成,表是二维的,一张表里面可以有很多字段,数据库的表在能够用二维表现多维关系
数据仓库,是数据库的概念升级,逻辑上理解,数据库和数据仓库没有区别,都是通过数据库软件实现存储数据的地方,只不过数据量来说,数据仓库要比数据库庞大许多,数据仓库主要用于挖掘和数据分析,辅助领导做决策
操作型处理叫联机事务处理OLTP(On-Line tran section Processing),也可以称为面向交易的处理系统,他是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询,修改,用户较为关心操作的响应时间,数据安全完整和并发支持的用户数问题,传统数据库作为数据管理的主要手段,主要用于操作型处理
分析型处理,叫联机分析处理olap (On-Line Anal ytical Processing) 一般针对某些主题的历史数据进行分析,支持管理决策
7.9.有什么维表
时间维表,用户维表,产品维表,合同维表,地理维表,等等
7.10.数据源有哪些
大体上分为内部外部数据:
内部数据又分为:业务库数据源:MySQL,mongo
日志数据:ng日志,埋点日志
外部数据:爬虫数据
7.11.你们最大的表是什么,数据量多少
Ng日志,或者XX日志,三端(APP,Web,H5)中,app日志量最大,清洗入库后大概xxxW(条)
7.12.数仓架构体系
离线:hive hadoop spark kylin
实时:kafka spark Streaming,fink hbase
7.13.你了解的调度系统有哪些,你们公司用那种
Airflow,azkaban,ooize 我们公司用的是azkaban
7.14.你们公司数仓底层怎么抽取数据
业务数据:前期使用过sqoop后期转为datax
日志数据的话用的是logstash
7.15.为什么datax抽数据比sqoop快
Datax单进程多线程
7.16.埋点数据你们是怎样接入的
Logstash–>kafka–>logstash–>hdfs
7.17.如果你们业务库表更新,你们数仓怎么处理
增量抽取
7.18.能独立搭建数仓吗?
了解过,但是独立有点费时
7.19.搭建过CDH集群吗?
搭建过,自行看星哥之前发的6.3视频(也可以说在自己电脑搭建过,公司去的时候以及完成了,分入公司时间)
7.20.对目前的流和批处理的认识?谈谈自己感受
目前流式处理和批处理共存,主要是看业务需求,批处理相对于流处理更稳定一点,但是未来肯定是批流一体的状态
7.21.你了解过那些OLAP引擎,MPP知道那些?ClickHouse了解一些吗?
OLAP:Kylin
MMP:GREENPLUM
ClickHouse了解并且使用过
7.22.Kylin简单介绍下原理
主要就是预计算,默认使用MR引擎,存储在HBASE中
7.23.数据接入进来,你们是怎样规划的,有考虑过数据的膨胀问题吗?
会根据数据量及后续业务发展来选择数据抽取方案,会考虑数据膨胀问题,所有一般选用增量抽取
7.24.简述拉链表,流水表,以及快照的含义和特点
拉链表:维护历史状态,以及更新状态数据
流水表:对于表的每一个修改都会记录,可以用于反映实际记录的变更
快照表:按日分区,记录截止日期的全量数据,有无变化都要报.每次上报的数据都是所有数据(变化+没有变化的)
一天一个分区
7.25.全量表,增量表,追加表,拉链表的区别及使用场景
全量表:每天更新所有数据信息,有无变化都需要上报 日活表,每日
增量表:新增数据,每次记录增加量,而不是总量,业务库中需要主键及创建时间,修改时间 订单表,新老用户表,产品表
拉链表:维护历史状态,以及最新数据状态,订单表,会员等级表
7.26.数仓建模方式?
选择需要进行分析决策的业务过程,业务过程可以是单个业务事件,比如交易支付,退款等,也可以是某个事件的状态,你如当前账户余额等,还可以是一系列相关业务事件组成的业务流程,具体需要看分析的是什么事件
选择粒度,在事件分析中,我们要预判所有分析需要细分的程度,从而决定选择粒度,粒度是维度的一个组合
识别维表:选择好粒度之后,就需要基于粒度设计维表,包括维度属性,用于分析时进行分组和筛选.
选择事实,确定分析需要衡量的指标
7.27.什么是事实表,什么是维表
事实表:是指存储有事实记录的表如系统日志,销售记录等,事实表,的记录在不断地动态增长.所以它的体积远大于其他表
事实表作为数据数据库建模的核心.需要根据业务过程来设计,包含了引用的维度和业务工程有关的度量
维表:是与事实表相对应订单一种表,他保存了维度的属性值,可以跟事实表做关联,相当于事实表上经常出现的属性抽取.规范出来用一张表进行管理.常见维度表有:日期表,地点表,维度是维度建模的基础和灵魂
7.28.如果数据库修改了数据,但是更新时间没有修改,这个数据能抽过来么.应该怎么处理
抽取不过来,只能通过监听binlog实时采集
7.29.缓慢变化维如何处理,几种方式
直接更新字段,我了解到三种方式:加一行,加一列,拉链表处理
7.30.Datax与sqoop的优缺点
Datax缺点:单进程多线程,单机压力大.不支持分布式.社区开源不久,不活跃
优点:能显示运行信息(运行时间,数据量,资源,脏数据,核数的等),支持流量控制
Sqoop优点:MR运行.拓展性好,分布式,社区活跃
缺点:不支持运行信息显示,不支持流量控制
7.31.Datax碰到emoji表情怎么解决
我记得抽取到表情是能正常抽取并展示,在同步MySQL的时候需要修改编码
7.32.工作碰到什么困难.怎么解决?
举例:遇到过攻克不过的问题,自己查询过博客,CSDN,以及一些内部的技术交流群.实在不行,问过组长
团队上面出现过项目需求不是清晰明确,后和运营进行过多次沟通等等,自己可以构思
7.33.如何用数据给公司带来收益
用户画像,运营平台,精准营销,推荐系统等,举例:归因分析.分析后将转换比最高的待归因事件进行更大规模的推广.提高人们的认知率,也将用户所喜欢的更加精准的进行推送,提高订单成交比
7.34.数据质量和元数据管理
数据质量:完整性,一致性,准确性,唯一性,关联性,真实性,及时性,逻辑检查,离群值检查,自定义规则,波动稽核(异方差:,数据的完整性)
元数据管理.技术元数据,存储元数据,运行元数据,计算元数据,调度元数据,运维元数据,业务元数据,维度,指标
7.35.埋点的码表如何设计
埋点管理平台输入,存储在MySQL中,字段页面ID,点位唯一ID,点位名称,点位时间,私有参数
7.36.集市层和公共层的区别
数据公共层CDM包括,DIM维度表,DWD DW和DWS,由ODS层数据加工而成,主要完成数据的加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标
数据集市,也叫数据市场,是数据仓库的一个访问层,是按主题域组织的数据集合,用于支持部门级的决策
数据集市相当于数据仓库的一个子集,通常面向特定的业务线
7.37.告警平台你们怎么做的?
基础架构组和数据平台开发组做的
7.38.说说,你从零到一搭建数仓都做了什么,你觉得最有挑战的是什么
举例:我负责过数仓当中维表的创建,以及维表的选维,和小组成员进行了技术方面的探讨,来确定技术的选型,数据质量的规范这一方面我们是进行开会探讨的.最有调整的就是业务方面的,我们需要和运营,开发进行多次的沟通来确保各种信息,对于我们了解业务方面较有挑战
7.39.数据模型如何构建,星型,雪花,星座的区别,和工作中如何使用
星型模型中有一张事实表,以及零个或多个维度表,事实表与维度表通过主键相关联,维度表之间没有关联,当所有的维度表都直接连接到”事实表”上时,整个图解像个星星,故称为星型模型.由于星型模型只有一张大表,因此它相对于其他模型更适合大数据处理,其他模型可以通过一定转换为星型模型
当有一个或者多个维表没有直接连接到事实表上,而是通过其他维表连接,其图解像多个雪花连接一起,故雪花模型
雪花模型对星型模型的扩展,他对于星型模型的维度进一步层次话,原有的各维度可能拓展为小维度表,形成一些局部的”层次区域”,这些被分解的表都连接到主维度表而不是事实表,它的优点是通过最大限度减少数据存储量以及联合较小的维表来改善查询性能,雪花模型结构除了数据冗余
星座模型是有星型模型延伸而来,星型模型是基于一张事实表而星座模型是基于多张事实表,并且共享维度表信息,这种模型往往应用于数据关系比星型模型和雪花模型更适合负责的场合,星座模型需要多个事实表,共享维度表,因而可以视为星型模型的集合,故亦被称为星系模型
7.40.如何优化整个数仓的执行时长,比如七点所有任务完成,如何优化到五点?
可以考虑将任务进行优化,任务下线运行,将模型进行优化,外部条件允许的话,可以集群扩容
7.41.数据仓库你做过什么优化
Sql方面的优化,模型的优化,开发的规范进一步优化
7.42.如何保证指标的一致性
这个的话就要从指标的建设方面进行考虑,指标就是数据加上业务场景,能够指导业务制定下一步行动方案
通常来说建设指标体系,一般分两种,自上而下,或者,自下而上,日常工作中我们通常是两种方式同时进行,我们先找到摸个系统模块所能支持的指标,再根据我们的需求去额外定义一些侧面指标,从而保证指标体系的搭建,保证一致性
7.43.了解one data么?
这个的话我了解到是阿里开发的一套方法论来确保数据的建设,大致可以从以下几点说下.统一指标,保证了指标的定义,计算口径,数据来源的一致性,统一的维度管理,保证维度定义,维度值的一致性,还有就是同一维表的管理,保证了维表以及维表主键编码的唯一性,再有就是统一数据出口,实现了维度和指标元数据信息的唯一出口,维值和指标数据的唯一出口
7.44.数据飘移如何解决
数据漂移通常来说就是同步源系统中的数据到数据仓库第一层的时候出现数据的丢失,即前一天的数据漂移到下一天
解决方法的话我之前了解到两种方法,一种就是多取一天的数据,要么就是使用多个时间戳字段限制时间来获取相对准确的数据,我一般是使用多个时间戳来进行限制,因为这样会比较准确
7.45.拉链表的设计及拉链表回滚
一般就是增加两个字段,及数据生命周期的开始时间以及结束时间,结束时间如果为’9999-12-31’则表示记录为有效状态
拉链表回滚:其本质就是找到历史的快照,历史快照可以根据起始更新时间,那你就找endtime小于你出错的数据就行了.重新导入数据,将原始拉链表数据过滤到指定日期之前即可
7.46.平台选型依据?
我们都是根据具体的业务以及需求来进行具体的分析
7.47.数仓分层,模型.每层都是做什么的,为什么这么做
数仓分层大致分为四层,第一层为ODS层,即数据的贴源层,与业务库保持一致,不做任何处理,下一层的话就是CDM层,这里面包括DIM维度表,DWD,DW和DWS 由ODS层数据加工而成,主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标
公共维度层(DIM):基于维度建模理念思想,建立企业一致性维度,降低数据计算口径和算法不统一风险,公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应
明细粒度事实层(DWD):对数据进行规范化编码转换,清洗,统一格式,脱敏等,不做横向整合
主题宽表层(DW)对DWD各种信息进行整合,输出主题宽表
公共汇总粒度事实层(DWS):以分析的主题对象做建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型
ADS层,即数据应用层,面向业务需求定制开发,存放数据产品个性化的统计指标数据,
为什么分层;清晰数据结构,减少重复开发,把复杂问题简单化,
7.48.交叉维度的解决方案?
可以采用桥接表技术进行处理,在账户维度表和用户维度表之间建立账户-用户桥接表,这个桥接表可以解决掉账户维度和用户维度之间的多对多关系,也解决掉账户维表多值维度问题
7.49.增量处理的逻辑说一下
初始化状态是全量抽取的,根据更新时间增量抽取业务库修改或者新增数据和之前的全量数据进行merge去重插入到最新的分区
7.50.从原理上说一下MPP和MR的区别
MPP跑的是SQL而Hadoop底层处理是MR程序
MPP虽然是宣称可以横向扩展Scale OUT 但是这种扩展一般是扩展100左右,而Hadoop可以扩展1000+
Mpp数据库有对MySQL的完整兼容和一些事务的处理能力,对于用户来说,在实际使用场景,如果数据扩展需求不是很大,需要处理节点不多,数据是结构化数据,习惯使用传统的RDBMS的很多特性的场景,可以考虑MPP.
如果有很多非结构化数据,或者数据量巨大,有需要拓展上千节点,这个时候Hadoop是更好的选择
7.51.报表如何展示
自研报表系统 powerBI tableau
7.52.大宽表的优点和缺点?
优点:提高查询性能,快速响应,方便使用降低成本,提高用户满意度
三缺点:由于把不同的内容放到一张表中,已经不符合三范式的规范,坏处就是数据大量冗余
另外就是灵活性差,还有就是需要了解业务全流程,这个流程过长,业务迭代过快,就有点捉襟见肘
7.53.Parquet和Orc和Rc的比较
在我们当前数据集合hive的版本环境下,在文件写入方面ORC相比RC文件优势不显著,一些场合RC文件更优,在查询检索方面,ORC则基本是更优的性能,差距大小取决具体数据集和检索模式.如果Hive能集成ORC更新的版本支持LZ4并修复一些BUG,那应该就没有使用RC的理由了
至于Parquet可以考虑在需要支持深度嵌套的数据结构场合
7.54.有一些任务需要回溯,比如历史时间需要重新执行,又遇到么?
有,这种的话需要重新跑一下任务
7.55.怎么保证每天能在固定的时间数据产出
可以将任务进行优化,将集群进行扩容,使用值班制度,定点的执行任务
7.56.数据清洗做过么?
做过, 主要是负责将Json进行解析, 数据脱敏, 空值赋默认值, 过滤掉脏数据,枚举值 比如1男2女 0成年 1没成年 数据格式的统一,一般是时间戳进行统一
7.57.什么是列式存储
列存储不同于传统的关系型数据库,其数据在表中按列存储的
列方式所带来的好处就是由于查询中的选择规则是通过列来定义的.因此整个数据库都是自动索引化的
按列存储每个字段的数据集存储,在查询只需要少数几个字段的时候大大减少读取数据量.一个数据集存储,那就更容易为这种聚集储存设计更好的压缩/解压算法
列式数据库在分析需求的时候,不仅搜索时间效率占优,其空间效率也是很明显,特别是针对动辄就是按T进行计算的在分布式中能进行压缩处理节省宝贵的内部带宽.从而提高性能
7.58.数据存在HDFS上有压缩吗?
会有压缩 优点 减少磁盘空间,降低IO, 减少网络传输.缺点,需要花费额外的时间/Cpu做压缩和解压计算
通常格式使用Snappy格式