hadoop-3.3.3完全分布式集群搭建
前言
随着大数据的不断发展,hadoop在前段时间就已经更新到了3.x版本,与2.x版本存在着一些差异,在某大数据竞赛中也是使用的hadoop3.x的版本,本文就介绍hadoop3.x版本的完全分布式集群搭建。
环境准备
软件版本
- jdk:1.8
- hadoop:3.3.3
- 操作系统:centos7
需要的所有安装包都放在master节点的/opt目录下,安装包统一解压到/usr/local/src目录下

集群规划
采用一主两从的模式,由于一些政治问题,hadoop3.x中将之前2.x版本中的slaves改为了workers,如果你喜欢还是可以命名为slave。
| master | worker1 | worker2 | |
|---|---|---|---|
| ip | 192.168.1.101 | 192.168.1.102 | 192.168.1.103 |
| 进程 | NameNode,ResourceManager,SecondaryNameNode | DataNode,NodeManager | DataNode,NodeManager |
一、配置jdk环境变量
1. 解压jdk
tar -zxvf /opt/jdk-8u162-linux-x64.tar.gz -C /usr/local/src/

2. 修改/etc/profile文件
vi /etc/profile
# 在里面添加以下内容
export JAVA_HOME=/usr/local/src/jdk1.8.0_162
export PATH=$PATH:$JAVA_HOME/bin
# 按 esc键 输入:wq!保存并退出
# 退出编辑之后在终端输入
source /etc/profile # 刷新环境变量
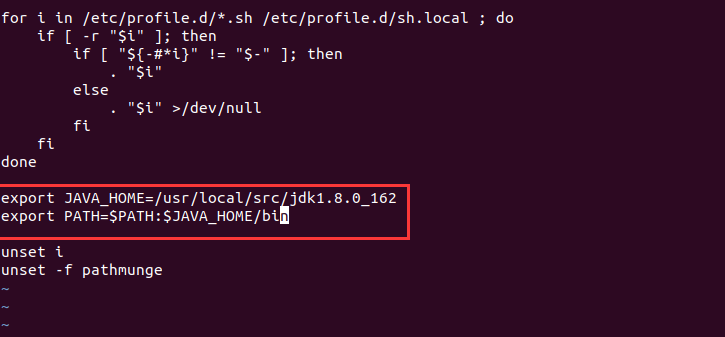
测试环境变量是否配置成功
# 在终端中输入,如果出现如图所示的内容则说明jdk安装成功
java -version

二、hadoop集群搭建
1. 关闭防火墙
# 在三个节点上执行
systemctl stop firewalld
systemctl disable firewalld
2. 修改主机名
# 修改三个节点的/etc/hosts文件,三台机器分别执行以下语句
hostnamectl set-hostname master
hostnamectl set-hostname worker1
hostnamectl set-hostname worker2
3. 添加ip映射
vi /etc/hosts
# 在/etc/hosts的末尾添加
192.168.1.101 master
192.168.1.102 worker1
192.168.1.103 worker2
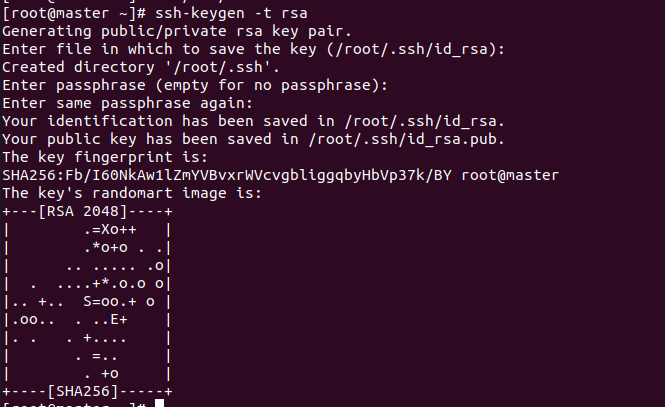
4. 配置免密登录
ssh-keygen -t rsa
然后空格四连,出现以下内容
然后把公钥复制到各个节点,第一次登陆会让你输入密码
ssh-copy-id master
ssh-copy-id worker1
ssh-copy-id worker2
先输入yes再输入密码
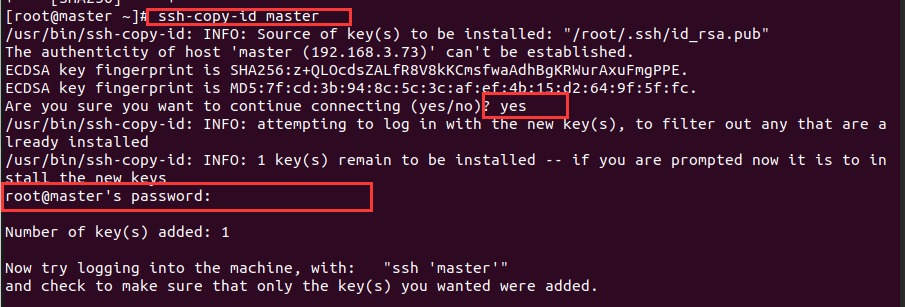
测试免密登录是否配置成功

exit # 回到master节点
5. 修改hadoop配置文件
1. 解压
tar -zxvf /opt/hadoop-3.3.3.tar.gz -C /usr/local/src
cd /usr/local/src/hadoop-3.3.3/etc/hadoop
2. 配置hadoop环境变量
vi /etc/profile
# 添加以下内容
export HADOOP_HOME=/usr/local/src/hadoop-3.3.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
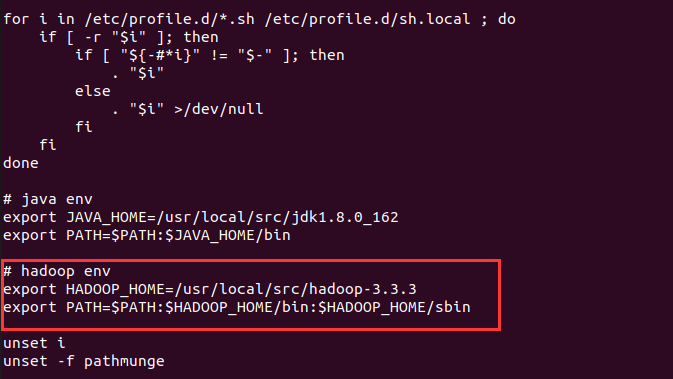
测试环境变量是否配置成功
source /etc/profile
hadoop version
# 出现以下内容说明配置成功

3. hadoop-env.sh
vi hadoop-env.sh
# 添加以下内容
export JAVA_HOME=/usr/local/src/jdk1.8.0_162
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4. core-site.xml
vi core-site.xml
<!-- 在configuration标签内添加以下内容 -->
<!-- fs.default.name已经过时了,现在一般都用fs.defaultFS-->
<!-- NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 临时文件存放位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-3.3.3/tmp</value>
</property>
5. hdfs-site.xml
vi hdfs-site.xml
<!-- 在configuration标签内添加以下内容 -->
<!-- 设置副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- namenode存放的位置,老版本是用dfs.name.dir -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/src/hadoop-3.3.3/name</value>
</property>
<!-- datanode存放的位置,老版本是dfs.data.dir -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/src/hadoop-3.3.3/data</value>
</property>
<!-- 关闭文件上传权限检查 -->
<property>
<name>dfs.permissions.enalbed</name>
<value>false</value>
</property>
<!-- namenode运行在哪儿节点,默认是0.0.0.0:9870,在hadoop3.x中端口从原先的50070改为了9870 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- secondarynamenode运行在哪个节点,默认0.0.0.0:9868 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
特别注意:在hadoop3.x中,文件系统的web界面的端口从50070改为了9870
6. yarn-site.xml
vi yarn-site
<!-- 在configuration标签内添加以下内容 -->
<!-- resourcemanager运行在哪个节点 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- nodemanager获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
7. mapred-site.xml
vi mapred-site.xml
<!-- 在configuration标签内添加以下内容 -->
<!-- 设置mapreduce在yarn平台上运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配了上面这个下面这个也得配, 不然跑mapreduce会找不到主类。MR应用程序的CLASSPATH-->
<property>
<name>mapreduce.application.classpath</name>
<value>/usr/local/src/hadoop-3.3.3/share/hadoop/mapreduce/*:/usr/local/src/hadoop-3.3.3/share/hadoop/mapreduce/lib/*</value>
</property>
8. workers
vi workers
# 删掉里面的localhost,添加以下内容,你的两个从节点的ip映射
worker1
worker2
6. 分发文件
cd /usr/local/src
# 分发jdk,$PWD:获取当前所在目录的绝对路径
scp -r jdk1.8.0_162 root@worker1:$PWD
scp -r jdk1.8.0_162 root@worker2:$PWD
# 分发hadoop
scp -r hadoop-3.3.3 root@worker1:$PWD
scp -r hadoop-3.3.3 root@worker2:$PWD
# 分发/etc/hosts
scp /etc/hosts root@worker1:/etc/
scp /etc/hosts root@worker2:/etc/
# 分发/etc/profile
scp /etc/profile root@worker1:/etc/
scp /etc/profile root@worker2:/etc/
# 然后在两个从节点上执行 source /etc/profile
7. 格式化namenode
hdfs namenode -format
8. 启动Hadoop集群并测试
1. 查看进程
# 启动hdfs
start-dfs.sh
# 启动yarn
start-yarn.sh
# 查看进程
jps
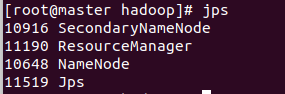
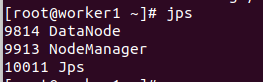
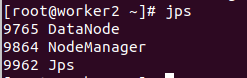
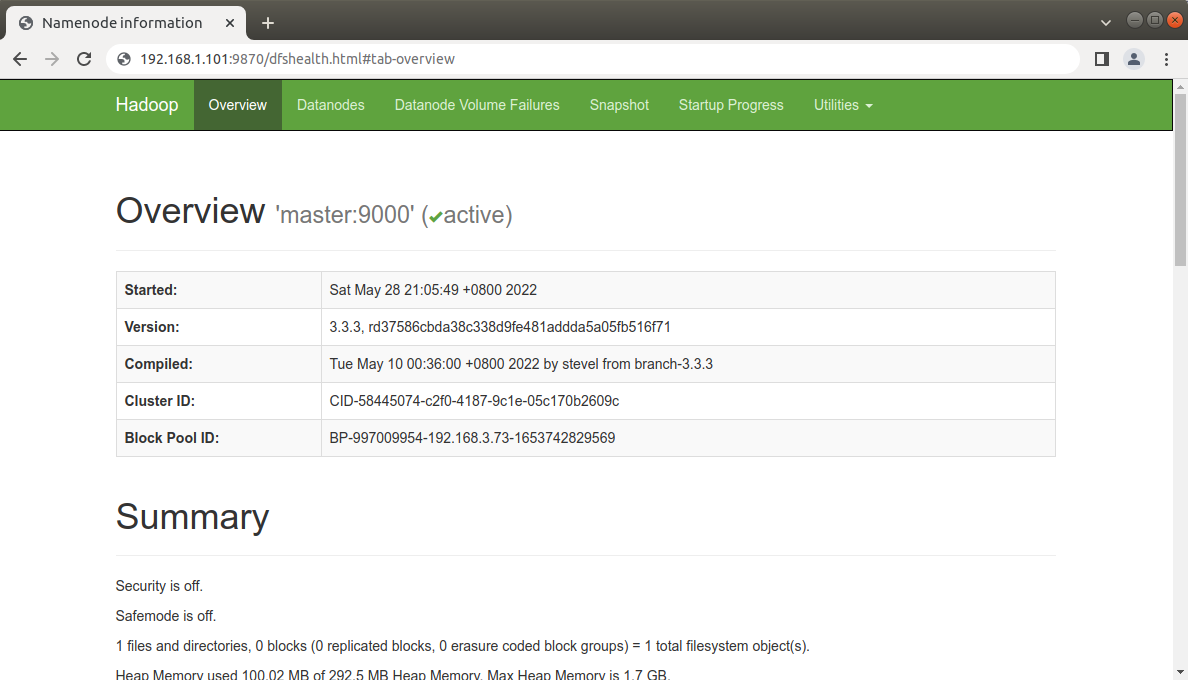
2. 访问web界面
打开浏览器输入,master的ip加上端口
3. 运行官方案例 WordCount
统计每个单词出现的频率
vi words.txt
# 添加以下内容,随意添加
hadoop hdfs hdfs hadoop
mapreduce mapreduce hadoop
hdfs hadoop yarn yarn
# 在hdfs上创建文件夹
hdfs dfs -mkdir /input
# 把words.txt上传到hdfs的input文件夹中
hdfs dfs -put words.txt /input/
# 运行wordcount
hadoop jar /usr/local/src/hadoop-3.3.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.3.jar wordcount /input/ /output
查看结果
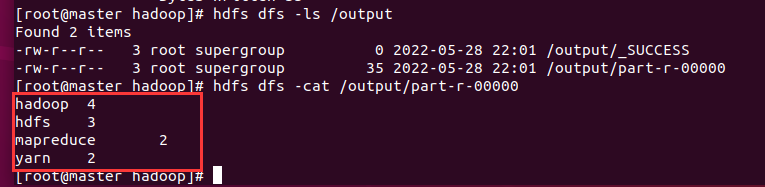
~ 集群搭建到此结束。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了hadoop-3.3.3的完全分布式集群搭建,可以看到3.x和2.x之间的一些差别,比如最常用的web端口从50070改为了9870。
hadoop集群搭建好之后为我们之后要学习的大数据框架打下了基础。