solr安装
1.下载安装solr
http://archive.apache.org/dist/lucene/solr/
2.运行solr
在solr文件根目录执行命令:
//solr根目录下
//运行solr
bin/solr start -force
//停止运行
bin/solr stop
//重启solr
bin/solr restart
//指定端口号启动(默认端口号为8983)
bin/solr start -p 8888
浏览器输入网址查看
例:192.168.120.3:8983/solr
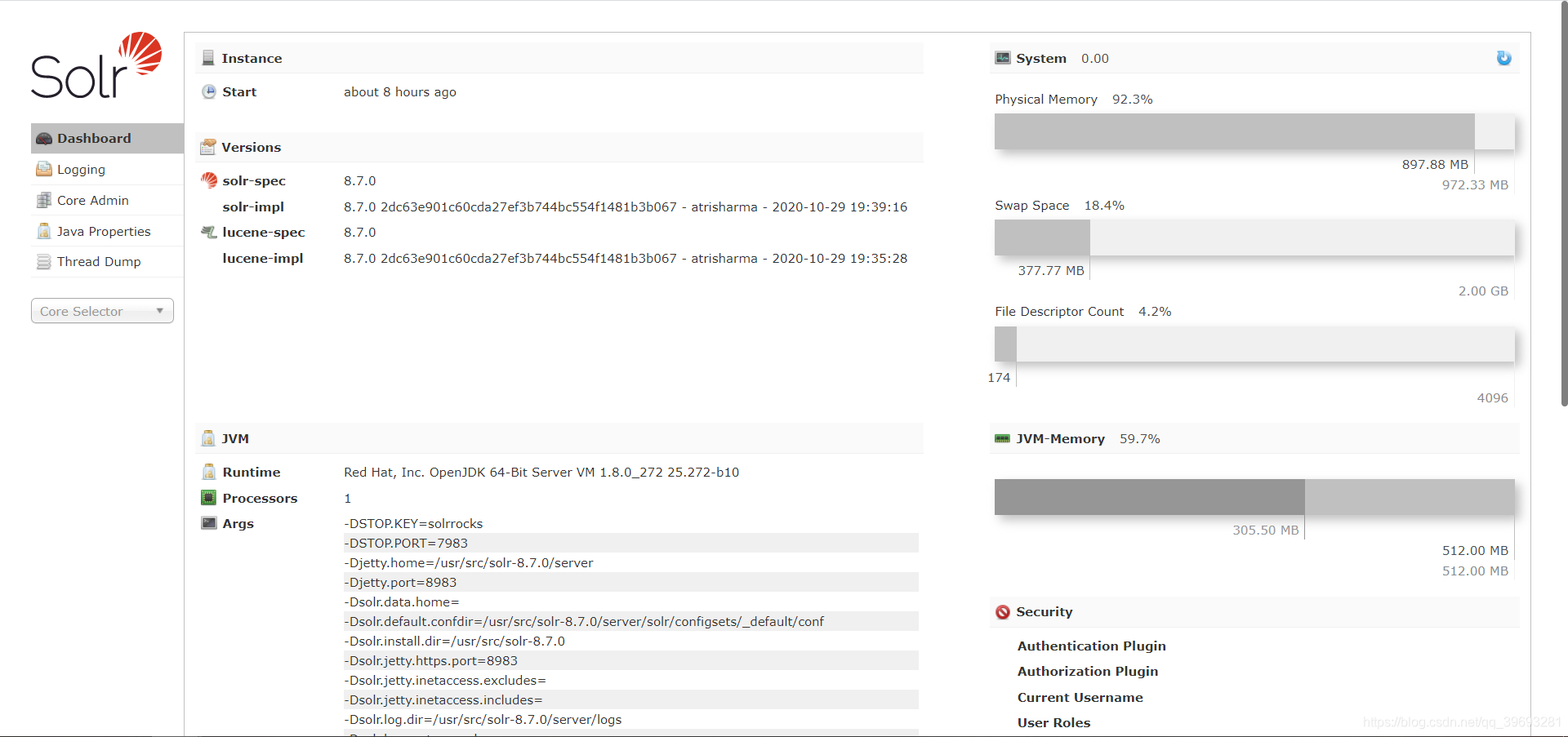
3.测试
查看结果
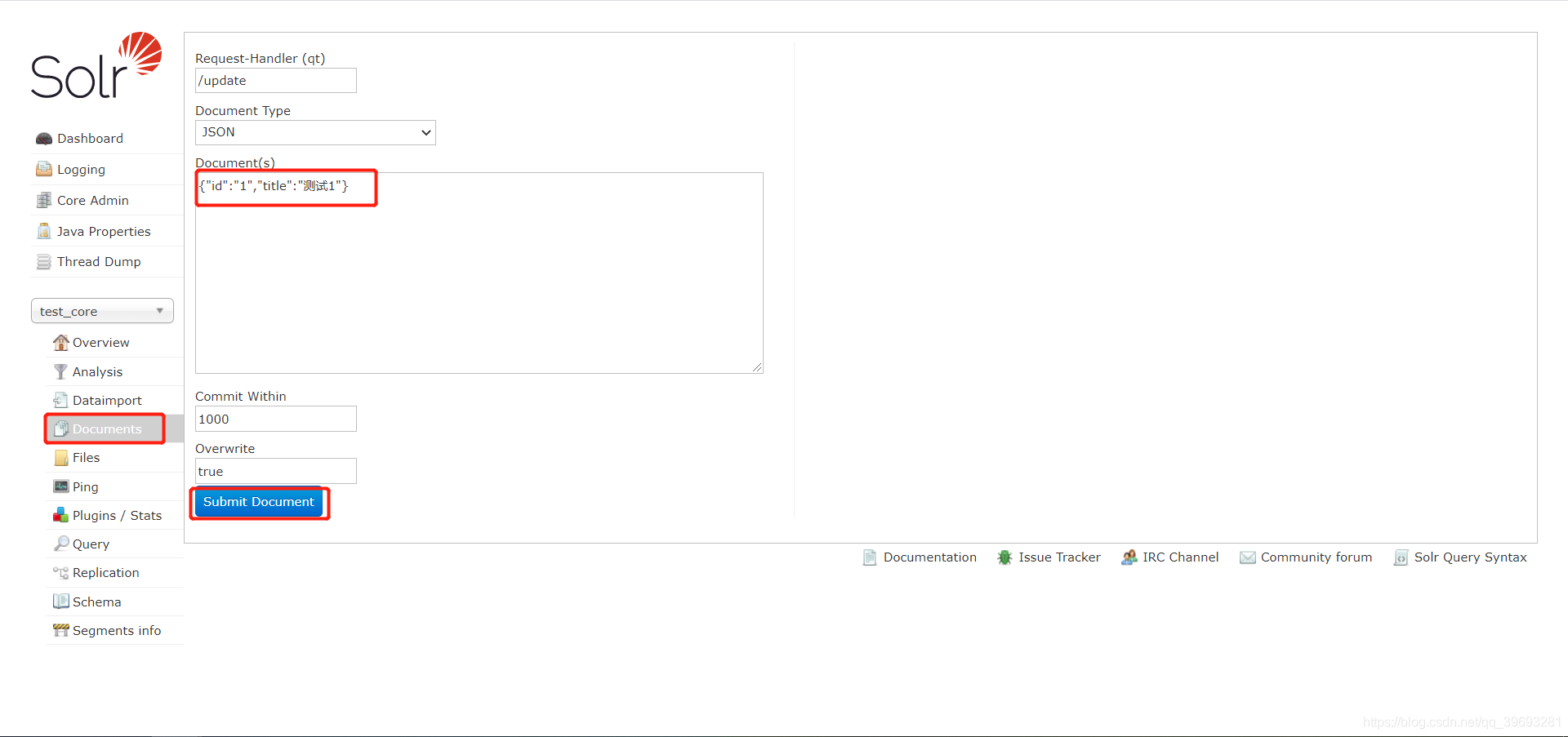
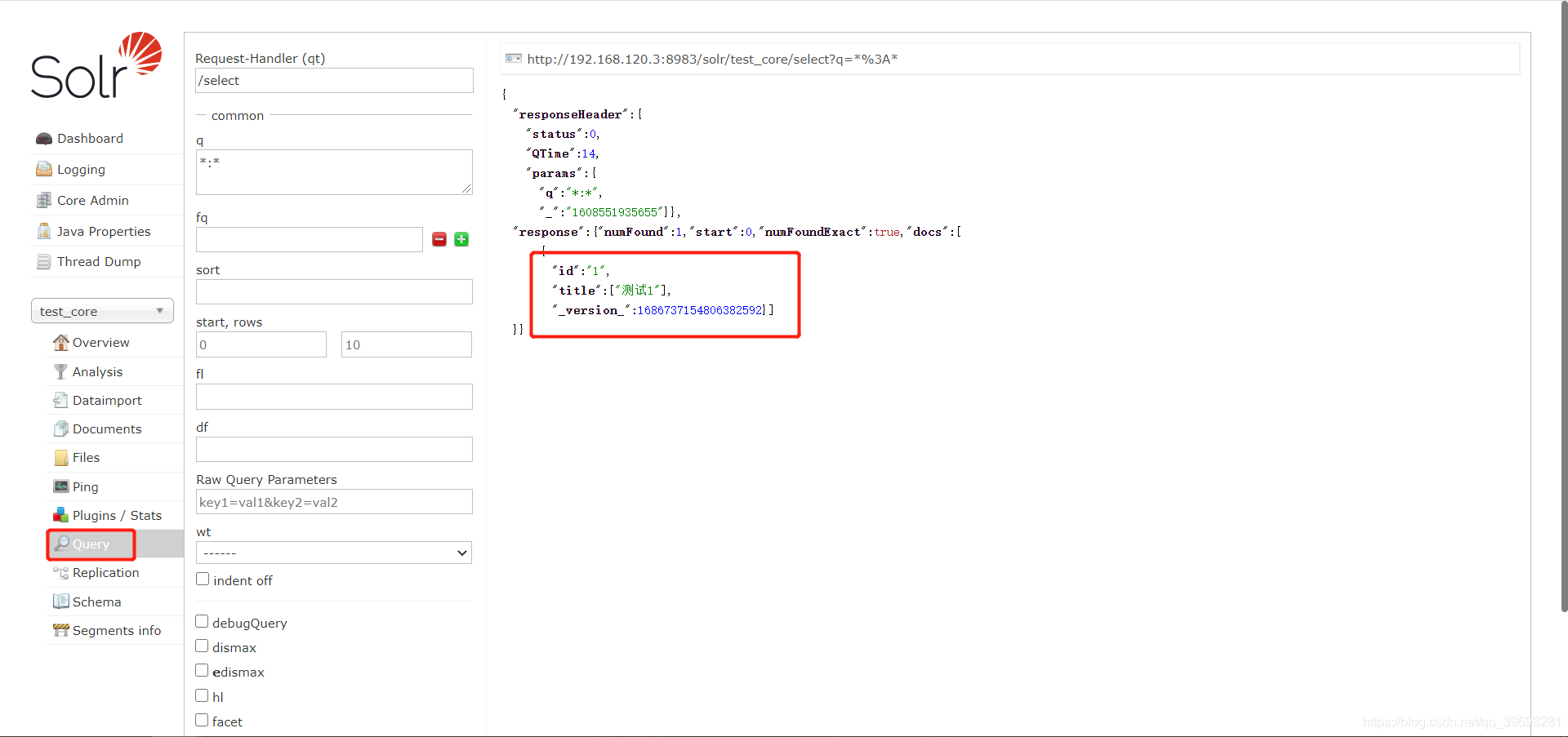
4.创建core实例
1)命令行创建
//solr根目录下
//执行命令
bin/solr create -c name
//默认创建位置为: server/solr
2)使用AdminUI页面创建
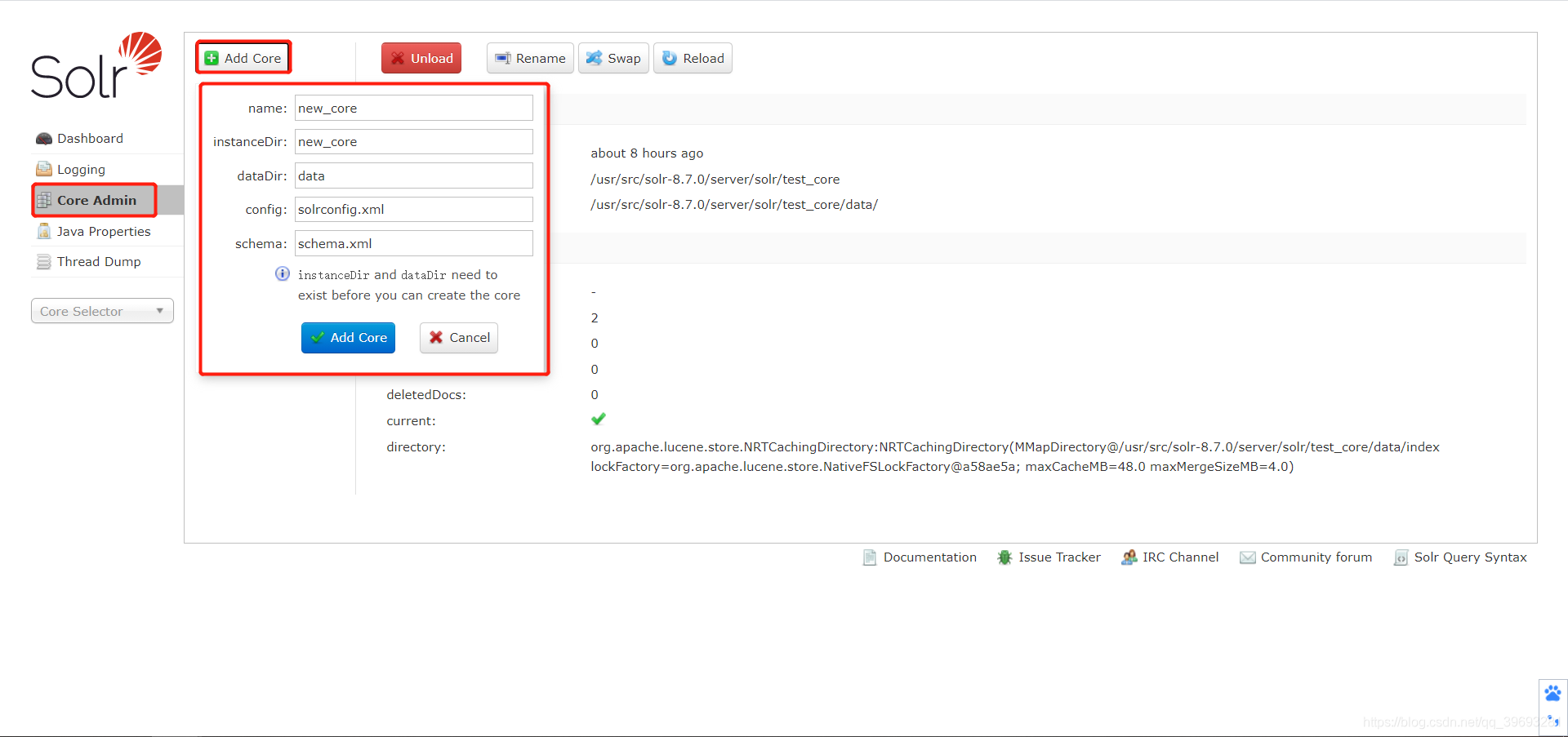
//步骤:
//1.输入内容
//2.创建core目录
mkdir server/solr/test_code
//3.复制conf目录到core目录
cp -r server/solr/configsets/_default/conf
server/solr/test_core
4.页面点击"Add Core"
IK分词器安装
1.安装配置步骤
1) 下载IK分词器jar包
项目地址:https://github.com/EugenePig/ik-analyzer-solr5
可以通过maven将项目打包
或者直接在网上搜索"IK分词器的jar包"进行下载
2) jar包放到solr项目的lib文件夹下
3) 在WEB-INF文件夹内创建classes目录
//solr根目录下
mkdir server/solr-webapp/webapp/WEB-INF/classes
4) 将项目地址中的IKAnalyzer.cfg.xml、stopword.dic、ext.dic复制到classes目录下
5) 添加配置
//solr根目录下
vi server/solr/test_core/conf/managed-schema
//添加内容:
<fieldType name ="text_ik" class ="solr.TextField">
<!-- 索引时候的分词器-->
<analyzer type ="index" isMaxWordLength ="false" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type ="query" isMaxWordLength ="true" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
//重启
6) 测试
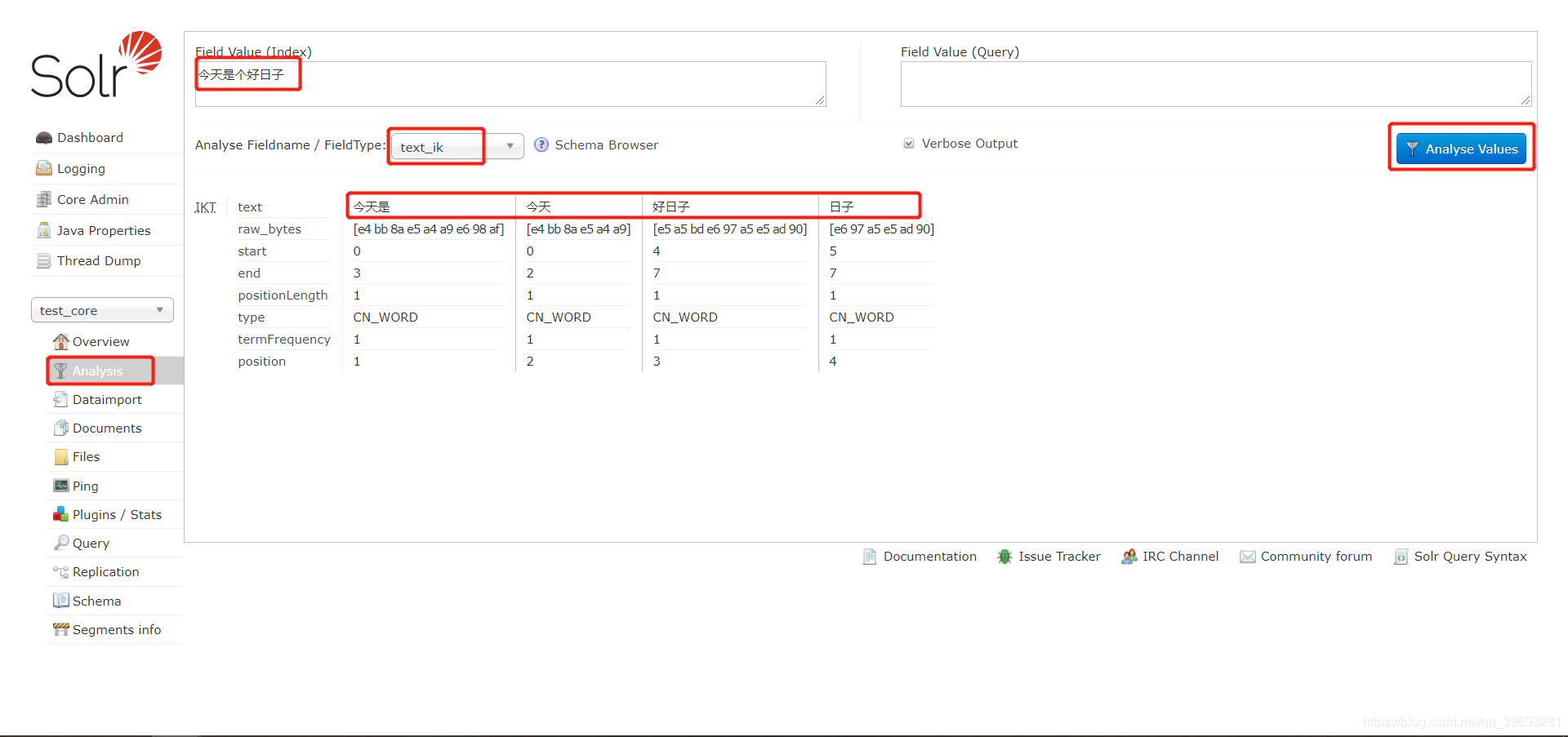
2.自定义词库
1)修改IKAnalyzer.cfg.xm
vi server/solr-webapp/webapp/WEB-INF/classes/IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
2)配置扩展词
vi ext.dic
//添加 是个好天气
//重启
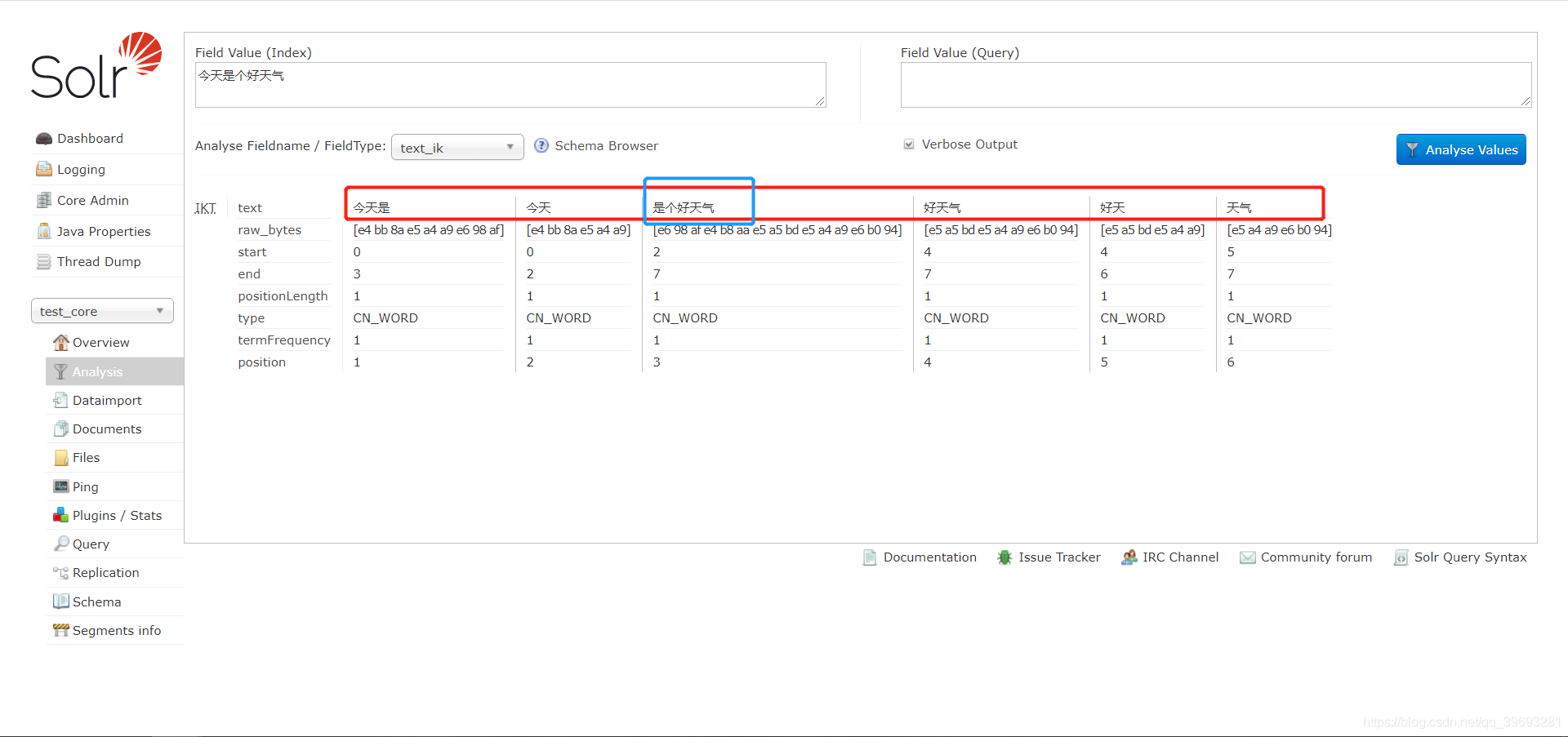
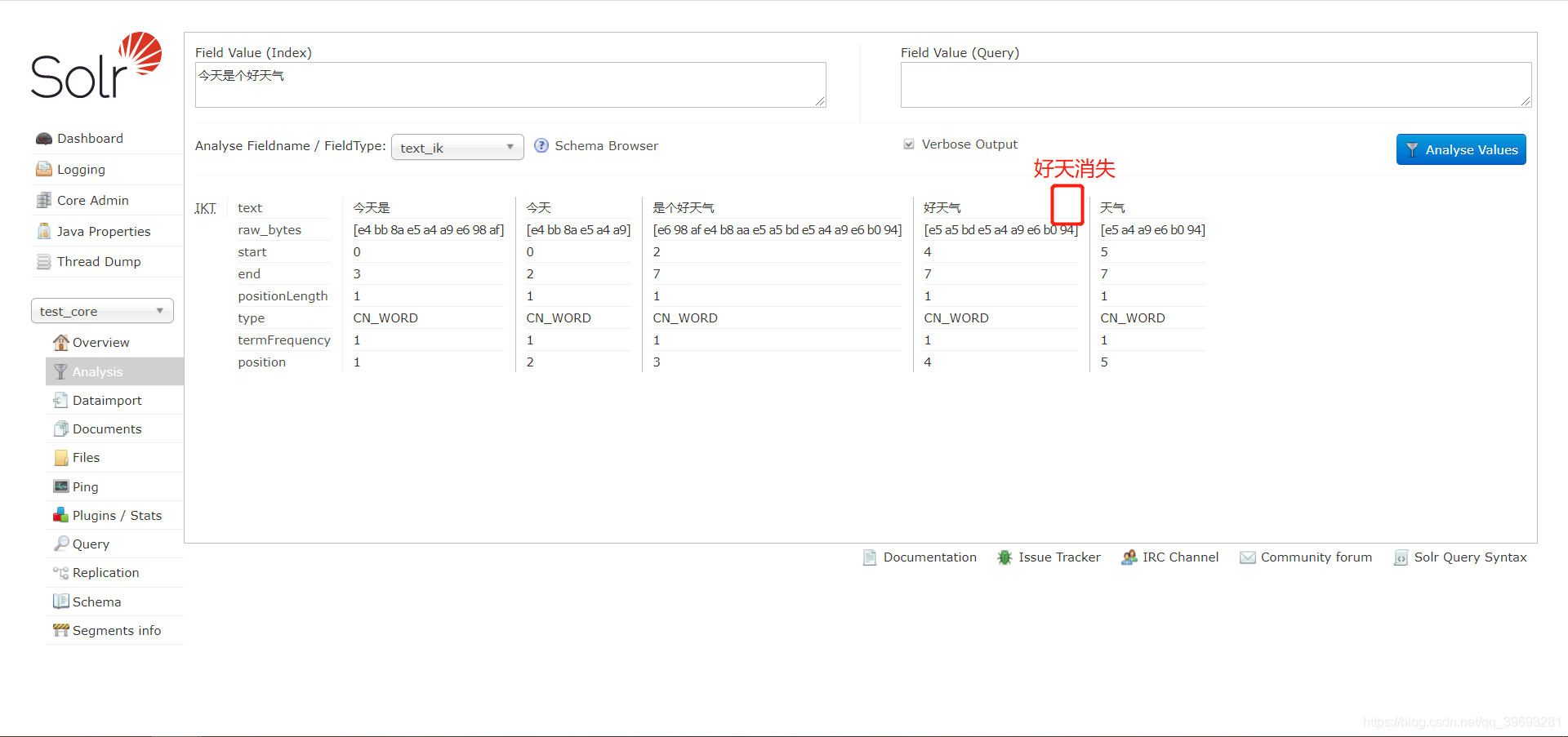
3)配置停止词
vi stopword.dic
//添加 好天
//重启
Java操作solr
1.导入坐标
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.2.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
2.创建实体类
public class Person {
@Field(value = "id")
private String id;
@Field(value = "name")
private String name;
@Field(value = "description")
private String description;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
3.创建SolrInfo配置项类
public class SolrInfo {
private String q;//solr查询参数
private String[] fq;//给query增加过滤查询条件
private String df;//设置默认搜索域,从哪个字段上查找
private Integer startRow;//设置分页参数 开始页
private Integer endRow;//设置分页参数 结束页
private Sort sort;
private boolean isHightlight;
private Hightlight hightlight = new Hightlight();
public SolrInfo(String q, String[] fq, String df, Integer startRow, Integer endRow,
Sort sort, boolean isHightlight, Hightlight hightlight) {
this.q = q;
this.fq = fq;
this.df = df;
this.startRow = startRow;
this.endRow = endRow;
this.sort = sort;
this.isHightlight = isHightlight;
this.hightlight = hightlight;
}
public SolrInfo() {
}
public String getQ() {
return q;
}
public void setQ(String q) {
this.q = q;
}
public String[] getFq() {
return fq;
}
public void setFq(String[] fq) {
this.fq = fq;
}
public String getDf() {
return df;
}
public void setDf(String df) {
this.df = df;
}
public Integer getStartRow() {
return startRow;
}
public void setStartRow(Integer startRow) {
this.startRow = startRow;
}
public Integer getEndRow() {
return endRow;
}
public void setEndRow(Integer endRow) {
this.endRow = endRow;
}
public Sort getSort() {
return sort;
}
public void setSort(Sort sort) {
this.sort = sort;
}
public boolean isHightlight() {
return isHightlight;
}
public Hightlight getHightlight() {
return hightlight;
}
public void setHightlight(Hightlight hightlight) {
this.hightlight = hightlight;
}
//设置高亮显示以及结果的样式
static class Hightlight{
private String HighlightField = "name";
private String HighlightSimplePre = "<font color='red'>";
private String HighlightSimplePost = "</font>";
public Hightlight() {
}
public Hightlight(String highlightField,
String highlightSimplePre, String highlightSimplePost) {
HighlightField = highlightField;
HighlightSimplePre = highlightSimplePre;
HighlightSimplePost = highlightSimplePost;
}
public String getHighlightField() {
return HighlightField;
}
public void setHighlightField(String highlightField) {
HighlightField = highlightField;
}
public String getHighlightSimplePre() {
return HighlightSimplePre;
}
public void setHighlightSimplePre(String highlightSimplePre) {
HighlightSimplePre = highlightSimplePre;
}
public String getHighlightSimplePost() {
return HighlightSimplePost;
}
public void setHighlightSimplePost(String highlightSimplePost) {
HighlightSimplePost = highlightSimplePost;
}
}
//设置返回结果的排序规则
static class Sort{
private String sortName;
private SolrQuery.ORDER sortOrder;
public Sort(String sortName, SolrQuery.ORDER sortOrder) {
this.sortName = sortName;
this.sortOrder = sortOrder;
}
public Sort(){
}
public String getSortName() {
return sortName;
}
public void setSortName(String sortName) {
this.sortName = sortName;
}
public SolrQuery.ORDER getSortOrder() {
return sortOrder;
}
public void setSortOrder(SolrQuery.ORDER sortOrder) {
this.sortOrder = sortOrder;
}
}
}
4. 创建SolrUtil工具类
public class SolrUtil {
//solr服务器所在的地址,test_core为自己创建的文档库目录
private final static String SOLR_URL = "http://192.168.120.3:8983/solr/test_core";
/**
* 获取客户端的连接
*
* @return
*/
public HttpSolrClient createSolrServer() {
HttpSolrClient solr = new HttpSolrClient.Builder(SOLR_URL).withConnectionTimeout(10000)
.withSocketTimeout(60000).build();
return solr;
}
/**
* 往索引库添加文档
*
* @throws SolrServerException
* @throws IOException
*/
public void addDoc(SolrInputDocument document) throws SolrServerException, IOException {
HttpSolrClient solr = this.createSolrServer();
solr.add(document);
solr.commit();
solr.close();
System.out.println("添加成功: " + document.toString());
}
/**
* 往索引库添加文档
*
* @throws SolrServerException
* @throws IOException
*/
public void addDoc(Object obj) throws SolrServerException, IOException {
SolrInputDocument document = new SolrInputDocument();
Map<String, Object> map;
if (!(obj instanceof java.util.Map)){
//hutool的BeanUtil
map = BeanUtil.beanToMap(obj);
}else {
map = (Map<String, Object>) obj;
}
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, Object> next = iterator.next();
document.addField(next.getKey(),next.getValue());
}
HttpSolrClient solr = this.createSolrServer();
solr.add(document);
solr.commit();
solr.close();
System.out.println("添加成功: " + document.toString());
}
/**
* 往索引库添加文档
*
* @throws SolrServerException
* @throws IOException
*/
public void addDoc(List<Object> lists) throws SolrServerException, IOException {
for (Object o:lists){
this.addDoc(o);
}
System.out.println("添加成功: " + lists.toString());
}
/**
* 根据ID从索引库删除文档
*
* @throws SolrServerException
* @throws IOException
*/
public void deleteDocById(String id) throws SolrServerException, IOException {
HttpSolrClient server = this.createSolrServer();
server.deleteById(id);
server.commit();
server.close();
System.out.println("删除成功: " + id);
}
/**
* 根据多个ID从索引库删除文档
*
* @throws SolrServerException
* @throws IOException
*/
public void deleteDocByIds(List<String> ids) throws SolrServerException, IOException {
HttpSolrClient server = this.createSolrServer();
server.deleteById(ids);
server.commit();
server.close();
System.out.println("删除成功: " + ids.toString());
}
/**
* 根据查询条件从索引库删除文档
*
* @throws SolrServerException
* @throws IOException
*/
public void deleteDocByQuery(String query) throws SolrServerException, IOException {
HttpSolrClient server = this.createSolrServer();
server.deleteByQuery(query);
server.commit();
server.close();
System.out.println("删除成功: " + query);
}
/**
* 根据设定的查询条件进行文档字段的高亮查询
*
* @throws Exception
*/
public Map<String,Object> queryDoc(SolrInfo solrInfo) throws Exception {
HttpSolrClient server = this.createSolrServer();
SolrQuery query = new SolrQuery();
//下面设置solr查询参数
if(!StringUtils.isEmpty(solrInfo.getQ())){
query.set("q", solrInfo.getQ());//相关查询,比如某条数据某个字段含有周、星、驰三个字 将会查询出来 ,这个作用适用于联想查询
}
//参数fq, 给query增加过滤查询条件
if (solrInfo.getFq()!=null){
query.addFilterQuery(solrInfo.getFq());
}
//参数df,给query设置默认搜索域,从哪个字段上查找
if (!StringUtils.isEmpty(solrInfo.getDf())){
query.set("df", solrInfo.getDf());
}
//参数sort,设置返回结果的排序规则
if (solrInfo.getSort() != null) {
query.setSort(solrInfo.getSort().getSortName(), solrInfo.getSort().getSortOrder());
}
//设置分页参数
if (!StringUtils.isEmpty(String.valueOf(solrInfo.getStartRow()))){
query.setStart(solrInfo.getStartRow());
}
if (!StringUtils.isEmpty(String.valueOf(solrInfo.getEndRow()))){
query.setRows(solrInfo.getEndRow());
}
//设置高亮显示以及结果的样式
if (solrInfo.isHightlight()) {
query.addHighlightField(solrInfo.getHightlight().getHighlightField());
query.setHighlightSimplePre(solrInfo.getHightlight().getHighlightSimplePre());
query.setHighlightSimplePost(solrInfo.getHightlight().getHighlightSimplePost());
}
//执行查询
QueryResponse response = server.query(query);
//获取返回结果
Map<String,Object> map = new HashMap<>();
SolrDocumentList resultList = response.getResults();
for (SolrDocument document : resultList) {
Collection<String> fieldNames = document.getFieldNames();
for (String fieldName : fieldNames) {
//判断是否高亮
if (solrInfo.isHightlight()){
Map<String, Map<String, List<String>>> hl = response.getHighlighting();
map.put("HLField",hl);
Map<String, List<String>> hlField = hl.get(document.getFieldValue("id"));
if(hlField.get(fieldName)!=null){
System.out.println(fieldName + ": " + hlField.get(fieldName).get(0));
}else{
System.out.println(fieldName + ": " + document.getFieldValue(fieldName));
}
}else{
System.out.println(fieldName + ": " + document.getFieldValue(fieldName));
}
}
}
//获取实体对象形式
List<Person> persons = response.getBeans(Person.class);
map.put("objList",persons);
return map;
}
}
5.修改关键字类型
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" luceneMatchVersion="8.7.0"/>
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" luceneMatchVersion="8.7.0"/>
</fieldType>
------------------------------
<field name="description" type="text_ik"/><!-- 设置为IK分词器类型 -->
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="name" type="text_ik"/>
<field name="title" type="text_general"/>
注:如果存储的字段值为数组形式
如:“id”:[“10”]
将配置文件对应字段的multiValued设置为false
最后记得重启solr
6.用户查询流程
- 用户设置条件进行查询
- solr会将查询内容根据分词器进行拆分后再查找
- 返回匹配的内容(包括按分词查找的结果)
- 如果设置了停止词, 返回结果不包括