摘要
Transformer注意力机制中的设计选择,包括弱归纳偏置和平方计算复杂度,限制了它在建模长序列中的应用。本文提出了Mega,一种简单且理论上有基础的单头门控注意力机制,该机制配备了(指数)移动平均,旨在将位置感知的局部依赖的归纳偏置引入到位置无关的注意力机制中。我们进一步提出了Mega的一个变种,该变种提供了线性时间和空间复杂度,但仅导致极小的质量损失,通过高效地将整个序列分成多个固定长度的块来实现。在一系列序列建模基准测试上,包括长程竞技场、神经机器翻译、自回归语言建模、图像和语音分类,广泛的实验表明,Mega在这些任务上相较于其他序列模型(包括Transformer的变种和近期的状态空间模型)取得了显著的提升。
1. 引言
设计一个统一的模型来捕捉顺序数据中的长程依赖关系,适用于多种不同的模态,如语言、音频、图像和视频,是序列建模中的一个核心且具有挑战性的问题。为此,已经开发了许多不同的架构,包括卷积神经网络(CNNs)(Kim, 2014; Strubell等, 2017)、循环神经网络(RNNs)(Goller和Kuchler, 1996; Hochreiter和Schmidhuber, 1997; Cho等, 2014)、Transformer(Vaswani等, 2017)以及最近的状态空间模型(SSMs)(Gu等, 2022a; Mehta等, 2022)。
在这些模型中,Transformer架构因其在广泛的语言和视觉任务上取得的显著经验性成功而脱颖而出,包括机器翻译(Vaswani等, 2017; Ott等, 2018)、语言理解(Devlin等, 2019; Liu等, 2019)、图像识别(Dosovitskiy等, 2020; Touvron等, 2021)和基因序列建模(Madani等, 2020; Jumper等, 2021),其主要得益于概念上吸引人的注意力机制(Bahdanau等, 2015; Luong等, 2015; Vaswani等, 2017),该机制直接建模输入标记之间的相互作用。
注意力机制提供了捕捉上下文信息的关键,它通过建模输入序列中每个时间步长的标记之间的成对交互来实现。然而,注意力机制的设计有两个常见缺点:i) 弱归纳偏置;ii) 平方计算复杂度。首先,注意力机制没有假设标记之间依赖关系的模式(例如位置归纳偏置),而是直接从数据中学习预测成对的注意力权重。其次,计算和存储注意力权重的成本是输入序列长度的平方。最近的研究已显示,在长序列任务中应用Transformer的局限性,既体现在准确性上,也体现在效率上(Tay等, 2020)。
在本研究中,我们提出了一种配备移动平均的门控注意力机制(Mega),旨在同时解决这两个问题。其关键思想是通过利用经典的指数移动平均(EMA)方法(Hunter, 1986),在时间步维度上将归纳偏置引入注意力机制。EMA捕捉了随着时间指数衰减的局部依赖关系(见图1),并广泛应用于时间序列数据建模(§2)。我们引入了一种具有可学习系数的多维衰减形式的EMA(§3.1),随后通过将EMA与单头门控注意力(Hua等, 2022)的变种结合,开发了配备移动平均的门控注意力机制(§3.2)。从理论上讲,我们证明了单头门控注意力与最常用的多头注意力具有相同的表达能力(§3.3)。得益于融入的移动平均机制,我们进一步提出了一个具有线性复杂度的Mega变种,称为Mega-chunk,它通过将输入序列简单地分成固定块来最小化上下文信息的损失(§3.5)。
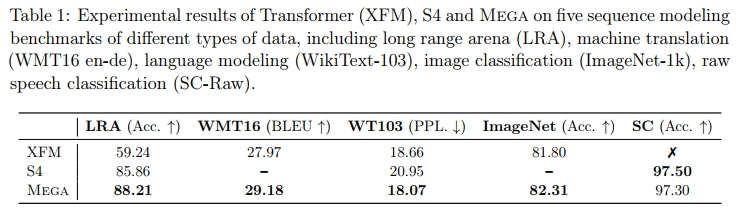
在实验中,通过在各种数据类型上的五个序列建模任务,包括长上下文序列建模、神经机器翻译、自回归语言建模、图像和语音分类,我们展示了Mega在有效性和效率上显著超过了多种强基准模型(§4)(见表1)。这些改进展示了通过不同归纳偏置模式建模长短期依赖关系的重要性。

2. 背景
在本节中,我们设置了符号表示,简要回顾了两种广泛使用的序列建模方法——自注意力机制和指数移动平均(EMA)——并讨论了将它们结合的动机。我们使用 X = x 1 , x 2 , … , x n ∈ R n × d \boldsymbol{X}={\mathbf{x}_1,\mathbf{x}_2,\ldots,\mathbf{x}_n}\in\mathbb{R}^{n\times d} X=x1,x2,…,xn∈Rn×d 来表示长度为 n n n 的输入表示序列。令 Y = y 1 , y 2 , … , y n ∈ R n × d \boldsymbol{Y}={\mathbf{y}_1,\mathbf{y}_2,\ldots,\mathbf{y}_n}\in\mathbb{R}^{n\times d} Y=y1,y2,…,yn∈Rn×d 为每一层的输出表示序列,其长度与输入序列 X \boldsymbol{X} X 相同,均为 n n n。在本文中,我们假设输入和输出序列的表示具有相同的维度 d d d。
2.1 自注意力机制
传统的自注意力机制是一个函数:
Y = A t t n ( X ) = f ( Q K T τ ( X ) ) V Y = Attn ( X ) = f ( Q K T τ ( X ) ) V ( 1 ) Y=Attn(X)=f(QKTτ(X))VY=\operatorname{Attn}(X)=f\left(\frac{QK^T}{\tau(X)}\right)V \qquad{(1)} Y=Attn(X)=f(QKTτ(X))VY=Attn(X)=f(τ(X)QKT)V(1)
其中,Attn : R n × d → R n × d :\mathbb{R}^n\times d\to\mathbb{R}^{n\times d} :Rn×d→Rn×d 是自注意力函数。 Q = X W q + b q , K = X W k + b k Q=XW_q+b_q,\boldsymbol{K}=\boldsymbol{X}W_k+b_k Q=XWq+bq,K=XWk+bk 和 V = X W v + b v \boldsymbol{V}=\boldsymbol{X}W_v+b_v V=XWv+bv 是查询、键和值的序列,具有可学习的参数 W q , W k , W v ∈ R d × d W_q,W_k,W_v\in\mathbb{R}^{d\times d} Wq,Wk,Wv∈Rd×d, b q , b k , b v ∈ R d b_q,b_k,b_v\in\mathbb{R}^d bq,bk,bv∈Rd。 f ( ⋅ ) f(\cdot) f(⋅) 是注意力函数,例如软最大函数 f softmax ( ⋅ ) f_\text{softmax}(\cdot) fsoftmax(⋅)(Bahdanau等, 2015),或最近提出的平方ReLU函数 f r e l u 2 ( ⋅ ) f_{\mathrm{relu}^{2}}(\cdot) frelu2(⋅)(So等, 2021;Hua等, 2022)。 τ ( X ) \tau(\boldsymbol{X}) τ(X) 是一个缩放项,通常对于 f softmax ( ⋅ ) f_\text{softmax}(\cdot) fsoftmax(⋅) 设置为 τ ( X ) = d \tau(\boldsymbol{X})=\sqrt{d} τ(X)=d,对于 f r e l u 2 ( ⋅ ) f_\mathrm{relu^2}(\cdot) frelu2(⋅) 设置为 τ ( X ) = n \tau(\boldsymbol{X})=n τ(X)=n。常用的多头注意力变体将注意力函数并行执行 h h h 次。
我们可以根据公式(1)定义一个矩阵 A = f ( Q K T τ ( X ) ) ∈ R n × n \boldsymbol{A}=f\left(\frac{Q\boldsymbol{K}^T}{\tau(\boldsymbol{X})}\right)\in\mathbb{R}^{n\times n} A=f(τ(X)QKT)∈Rn×n,该矩阵称为注意力矩阵,表示了输入序列中每一对标记之间的依赖关系强度。由于它建模了成对的依赖关系权重,因此 A \boldsymbol{A} A 矩阵原则上提供了一个灵活且强大的机制,能够学习长距离的依赖关系,并具有最小的归纳偏置。然而,实际上,直接从数据中识别所有依赖关系模式是一个具有挑战性的任务,尤其是在处理长序列时。此外,使用 h h h 个注意力头计算 A \boldsymbol{A} A 的时间和空间复杂度为 O ( h n 2 ) O(hn^2) O(hn2),而序列长度的平方依赖关系成为一个显著的瓶颈。
2.2 指数移动平均(EMA)
移动平均是一种经典的序列数据建模方法,广泛用于时间序列数据中,以平滑短期波动并突出长期趋势或周期。指数移动平均(EMA)(Winters, 1960;Hunter, 1986)是移动平均的一个特例,应用递减的权重因子。形式上,EMA递归地计算输出序列
Y
Y
Y:
y
t
=
α
⊙
x
t
+
(
1
−
α
)
⊙
y
t
−
1
y
t
=
α
⊙
x
t
+
(
1
−
α
)
⊙
y
t
−
1
(2)
yt=α⊙xt+(1−α)⊙yt−1y_t = \alpha \odot x_t + (1 - \alpha) \odot y_{t-1}\tag{2}
yt=α⊙xt+(1−α)⊙yt−1yt=α⊙xt+(1−α)⊙yt−1(2)
其中,
α
∈
(
0
,
1
)
d
\alpha \in (0, 1)^d
α∈(0,1)d 是EMA系数,表示权重衰减的程度,
⊙
\odot
⊙ 是元素逐项相乘。较高的
α
\alpha
α 会更快地降低旧观测值的权重(见图1)。
使用EMA在学习成对依赖关系时施加了强烈的归纳偏置:两个标记之间的依赖权重随着时间的推移以输入无关的衰减因子 α \alpha α 指数下降。这个属性有利于局部依赖,并限制了长距离依赖。尽管在公式(2)中采用了递归的形式,EMA的计算可以表示为 n n n 个独立的卷积运算,可以通过快速傅里叶变换(FFT)高效地计算(详细信息请见附录A)。
2.3 为什么将注意力机制与EMA结合?
如第2.1节和第2.2节所述,尽管EMA和注意力机制在序列建模中有广泛的应用并取得了显著成功,但它们各自也有其局限性。通过利用它们各自的特点以互相补充,我们提出将EMA嵌入到注意力矩阵A的计算中。由此得到的模型既能享受强归纳偏置的优势,又能保持学习复杂依赖模式的能力。此外,这种集成方法使得我们可以设计出一种计算上高效的分块注意力机制,相对于序列长度具有线性复杂度(§3.5)。
3. 移动平均驱动的门控注意力(Mega)
在本节中,我们详细介绍我们提出的方法——移动平均驱动的门控注意力(Mega)。首先,我们介绍多维衰减EMA(§3.1),它是与Mega中的单头门控注意力结合的关键组件(§3.2),并讨论Mega与三个密切相关的模型:GRU(Cho et al., 2014)、Flash(Hua et al., 2022)和S4(Gu et al., 2022a)之间的关系。我们还为单头门控注意力的设计提供理论依据(§3.3)。接着,我们描述每个Mega模块的详细架构,包括前馈层和归一化层(§3.4)。最后,我们介绍Mega-chunk,它是Mega的一个变体,简单地将输入序列分割成固定的块,从而将时间和空间复杂度从二次复杂度降低到线性复杂度(§3.5)。
3.1 多维衰减EMA
MEGA引入了标准EMA的修改版,称为多维衰减EMA,以提高其灵活性和能力。
衰减EMA。以往的研究(McKenzie和Gardner Jr,2010;Svetunkov,2016)表明,通过放宽先前和当前观测值的耦合权重(公式(2)中的
α
\boldsymbol{\alpha}
α与
1
−
α
1-\boldsymbol{\alpha}
1−α)可以生成更加稳健的依赖建模。受到此启发,MEGA允许对前一个时间步的影响进行衰减:
y
t
=
α
⊙
x
t
+
(
1
−
α
⊙
δ
)
⊙
y
t
−
1
,
y
t
=
α
⊙
x
t
+
(
1
−
α
⊙
δ
)
⊙
y
t
−
1
(3)
yt=α⊙xt+(1−α⊙δ)⊙yt−1,\mathbf{y}t=\mathbf{\alpha}\odot\mathbf{x}t+(1-\mathbf{\alpha}\odot\mathbf{\delta})\odot\mathbf{y}_{t-1}\tag{3}
yt=α⊙xt+(1−α⊙δ)⊙yt−1,yt=α⊙xt+(1−α⊙δ)⊙yt−1(3)
其中,
δ
∈
(
0
,
1
)
d
\delta \in (0,1)^d
δ∈(0,1)d 是衰减因子。
多维衰减EMA。为了进一步提高EMA的表达能力,我们引入了EMA的多维变体。具体来说,我们首先通过扩展矩阵
β
∈
R
d
×
h
\beta\in\mathbb{R}^{d\times h}
β∈Rd×h将输入序列
X
\boldsymbol{X}
X的每个维度单独扩展为
h
h
h个维度。形式上,对于每个维度
j
∈
1
,
2
,
…
,
d
j \in {1, 2, \ldots, d}
j∈1,2,…,d,我们有:
u
t
(
j
)
=
β
j
x
t
,
j
(4)
ut(j)=β_jx_{t,j}\tag{4}
ut(j)=βjxt,j(4)
其中,
β
j
∈
R
h
\beta_j \in \mathbb{R}^h
βj∈Rh是
β
\beta
β的第
j
j
j行,
u
t
(
j
)
∈
R
h
\mathbf{u}_t^{(j)} \in \mathbb{R}^h
ut(j)∈Rh是时间步
t
t
t下第
j
j
j维度的扩展后的
h
h
h维向量。
相应地,我们将
α
\boldsymbol{\alpha}
α和
δ
\boldsymbol{\delta}
δ的形状从一维向量扩展为二维矩阵,即
α
,
δ
∈
R
d
×
h
\boldsymbol{\alpha}, \boldsymbol{\delta} \in \mathbb{R}^{d\times h}
α,δ∈Rd×h,其中
α
j
,
δ
j
∈
R
h
\boldsymbol{\alpha}_j, \boldsymbol{\delta}_j \in \mathbb{R}^h
αj,δj∈Rh分别表示
α
\boldsymbol{\alpha}
α和
δ
\boldsymbol{\delta}
δ的第
j
j
j行。然后,对于每个维度
j
j
j,将衰减EMA应用于
h
h
h维隐藏空间:
h
t
(
j
)
=
α
j
⊙
u
t
j
+
(
1
−
α
j
⊙
δ
j
)
⊙
h
t
−
1
j
h_t(j)=α_j⊙u_t^j+(1−α_j⊙δ_j)⊙h_{t−1}^j
ht(j)=αj⊙utj+(1−αj⊙δj)⊙ht−1j
y t , j = η j T h t ( j ) (5) \mathbf{y}_{t,j}=\eta_j^T\mathbf{h}_t^{(j)}\tag{5} yt,j=ηjTht(j)(5)
其中, h t ( j ) ∈ R h \mathbf{h}_t^{(j)} \in \mathbb{R}^h ht(j)∈Rh是时间步 t t t下第 j j j维度的EMA隐藏状态, η ∈ R d × h \boldsymbol{\eta} \in \mathbb{R}^{d\times h} η∈Rd×h是一个投影矩阵,用于将 h h h维隐藏状态映射回1维输出 y t , j ∈ R \mathbf{y}_{t,j} \in \mathbb{R} yt,j∈R。 η j ∈ R h \boldsymbol{\eta}_j \in \mathbb{R}^h ηj∈Rh是 η \boldsymbol{\eta} η的第 j j j行。由(5)得到的输出 Y \boldsymbol{Y} Y表示为 Y = Δ \boldsymbol{Y} \overset\Delta{\operatorname*{=}} Y=Δ EMA ( X ) (\boldsymbol{X}) (X)。因为我们不需要显式地计算 h t ( j ) \mathbf{h}t^{(j)} ht(j)来得到输出 y t , j \mathbf{y}_{t,j} yt,j,所以时间和空间复杂度与标准EMA(公式(2))相似(详细内容见附录A)。实验结果表明,它的效果得到了提升(§4)。
3.2 移动平均装备门控注意力
Mega中的门控注意力机制采用了门控递归单元(GRU; Cho等人,2014)和门控注意力单元(GAU; Hua等人,2022)作为骨干架构,并将基于EMA的子层嵌入到注意力矩阵的计算中。形式上,我们首先使用(5)中的输出计算GAU中的共享表示:
X
′
=
E
M
A
(
X
)
∈
R
n
×
d
(
6
)
Z
=
ϕ
s
i
l
u
(
X
′
W
z
+
b
z
)
∈
R
n
×
z
(
7
)
\begin{aligned} & X^{\prime}=\mathrm{EMA}(X) & & \in\mathbb{R}^{n\times d} & & \mathrm{(6)} \\ & \boldsymbol{Z}=\phi_{\mathrm{silu}}(\boldsymbol{X}^{\prime}W_{z}+b_{z}) & & \in\mathbb{R}^{n\times z} & & \mathrm{(7)} \end{aligned}
X′=EMA(X)Z=ϕsilu(X′Wz+bz)∈Rn×d∈Rn×z(6)(7)
其中,
X
′
X'
X′ 可以视为更新后的或上下文化的输入,因为它通过EMA编码了上下文信息。
Z
Z
Z 是共享表示,具有
z
z
z 维度,投影矩阵为
W
z
∈
R
d
×
z
W_z \in \mathbb{R}^{d \times z}
Wz∈Rd×z,偏置项为
b
z
∈
R
z
b_z \in \mathbb{R}^z
bz∈Rz。
ϕ
s
i
l
u
\phi_{silu}
ϕsilu 是自门控激活函数(SiLU)(Ramachandran等人,2017;Elfving等人,2018)。继GAU之后,查询和键序列通过对
Z
Z
Z应用每维标量和偏移量来计算,而值序列则来自原始的
X
X
X:
C
!
=
κ
q
⊙
Z
+
μ
q
∈
R
n
×
z
(
8
)
K
=
κ
k
⊙
Z
+
μ
k
∈
R
n
×
z
(
9
)
V
=
ϕ
s
i
l
u
(
X
W
v
+
b
v
)
∈
R
n
×
v
(
10
)
\begin{gathered} \mathrm{C}!=\kappa_{q}\odot Z+\mu_{q}\in\mathbb{R}^{n\times z}\left(8\right) \\ \mathrm{K}=\kappa_{k}\odot Z+\mu_{k}\in\mathbb{R}^{n\times z}\mathrm{(9)} \\ \mathrm{V}=\phi_{\mathrm{silu}}(XW_{v}+b_{v})\in\mathbb{R}^{n\times v}\mathrm{(10)} \end{gathered}
C!=κq⊙Z+μq∈Rn×z(8)K=κk⊙Z+μk∈Rn×z(9)V=ϕsilu(XWv+bv)∈Rn×v(10)
其中,
κ
q
,
μ
q
,
κ
k
,
μ
k
∈
R
2
\kappa_q, \mu_q, \kappa_k, \mu_k \in \mathbb{R}^2
κq,μq,κk,μk∈R2 是查询和键的可学习标量和偏移量。
v
v
v 是值序列的扩展中间维度。注意力的输出计算如下:
O
=
f
(
Q
K
T
τ
(
X
)
+
b
r
e
l
)
V
∈
R
n
×
v
(11)
O=f\left(\frac{QK^T}{\tau(X)}+b_{\mathrm{rel}}\right)V\in\mathbb{R}^{n\times v}\tag{11}
O=f(τ(X)QKT+brel)V∈Rn×v(11)
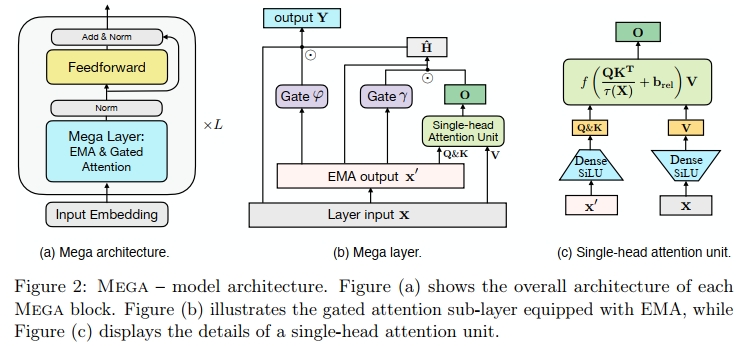
图形规范显示在图 2 © 中。
b
r
e
l
∈
R
n
×
n
b_{rel} \in \mathbb{R}^{n\times n}
brel∈Rn×n 是相对位置偏差。我们选择
b
r
e
l
b_{rel}
brel来自现有的方法,包括T5(Raffel 等人,2020),RoPE(Sutton 等人,2021),TUPE(Ke 等人,2020)和ALiBi(Press 等人,2021)。随后,MEGA 引入了重置门
γ
\gamma
γ、更新门
φ
\varphi
φ,并计算候选激活输出
H
^
\hat{H}
H^:
γ
=
ϕ
s
i
l
u
(
X
′
W
γ
+
b
γ
)
∈
R
n
×
v
(12)
\gamma=\phi_\mathrm{silu}(\boldsymbol{X}^{\prime}W_\gamma+b_\gamma)\quad\in\mathbb{R}^{n\times v}\tag{12}
γ=ϕsilu(X′Wγ+bγ)∈Rn×v(12)
φ = ϕ s i g m o i d ( X ′ W φ + b φ ) ∈ R n × d (13) \varphi=\phi_{\mathrm{sigmoid}}(\boldsymbol{X}^{\prime}W_\varphi+b_\varphi)\quad\in\mathbb{R}^{n\times d}\tag{13} φ=ϕsigmoid(X′Wφ+bφ)∈Rn×d(13)
H ^ = ϕ s i l u ( X ′ W h + ( γ ⊙ O ) U h + b h ) ∈ R n × d (14) \hat{\boldsymbol{H}}=\phi_{\mathrm{silu}}(\boldsymbol{X}^{\prime}W_{h}+(\gamma\odot\boldsymbol{O})U_{h}+b_{h})\quad\in\mathbb{R}^{n\times d}\tag{14} H^=ϕsilu(X′Wh+(γ⊙O)Uh+bh)∈Rn×d(14)
最终输出
Y
Y
Y 是通过更新门
φ
\varphi
φ 计算得到的:
Y
=
φ
⊙
H
^
+
(
1
−
φ
)
⊙
X
∈
R
n
×
d
(15)
Y=\varphi\odot\hat{H}+(1-\varphi)\odot X\quad\in\mathbb{R}^{n\times d}\tag{15}
Y=φ⊙H^+(1−φ)⊙X∈Rn×d(15)
Mega子层的图形架构如图2(b)所示。拉普拉斯注意力函数。如第2.1节所述,softmax函数是最常见的注意力函数f(·)。So等人(2021)最近通过架构搜索技术引入了平方ReLU函数frelu2(·),该函数在语言任务上表现出更快的收敛速度和具有竞争力的泛化性能(Hua等人,2022)。然而,frelu2(·)的一个问题是其范围和梯度都没有界限,导致模型训练不稳定(有关详细信息,请参见附录C.1)。为了应对这个问题,我们提出了一种基于拉普拉斯函数的新注意力函数。
f
lplace
(
x
;
μ
,
σ
)
=
0.5
×
[
1
+
erf
(
x
−
μ
σ
2
)
]
(16)
f_{\text{lplace}}(x;\mu,\sigma) = 0.5 \times [1 + \text{erf}\left(\frac{x-\mu}{\sigma\sqrt{2}}\right)] \tag{16}
flplace(x;μ,σ)=0.5×[1+erf(σ2x−μ)](16)
其中,erf() 是误差函数。μ 和 σ 是我们调整的两个系数,用来逼近
f
r
e
l
u
2
f_{relu^2}
frelu2,从而得到
μ
=
1
/
2
\mu=\sqrt{1/2}
μ=1/2 和
σ
=
1
/
4
π
\sigma=\sqrt{1/4\pi}
σ=1/4π。拉普拉斯函数的推导和可视化请参见附录C。
与GRU、Flash和S4的关系与区别。重置门γ、更新门’以及候选激活输出H^的计算(公式12-14)让人联想到GRU(Cho等人,2014)。主要区别在于,在GRU中,两个门是应用于当前和前一个时间步的隐藏状态之间,而在Mega中,它们是应用于EMA和门控注意力子层的输出之间。此外,公式(15)中的输出门控机制类似于Parisotto等人(2020)和Xu等人(2020)提出的门控残差连接,用以减少输出Y的方差。
共享表示Z的计算,以及公式(7-10)中查询、键和值的序列,受到Flash中GAU的启发(Hua等人,2022)。Mega通过从EMA输出X0而不是原始输入X计算公式(7)中的Z,将EMA整合到GAU中,并将GAU输出与X0结合用于公式(14)中的候选激活H^。与Flash相比的实验结果表明了这一设计选择的有效性(第4.1节)。
多维衰减EMA可以看作是状态空间模型的简化变种。从这个角度来看,Mega与S4(Gu等人,2022a)也有紧密的关系,后者是一个具有结构化状态矩阵的状态空间模型。S4利用HiPPO框架(Gu等人,2020)来初始化其低秩结构化状态矩阵,而S4中卷积核的计算需要复杂的快速傅里叶变换(FFT)。Mega中的EMA子层对状态矩阵进行了对角化,并将对角元素限制在(0,1)范围内。因此,卷积核将是一个范德蒙德积,可以以高效且数值稳定的方式进行计算。类似的对角化在并行工作S4D(Gu等人,2022b)中也有使用。此外,不像S4和S4D,Mega中的参数初始化不依赖于HiPPO框架。
3.3 单头门控注意力的理论依据
实验证明,单头门控注意力在性能上与普通的多头注意力相当(Liu等人,2021;Hua等人,2022),但对其理论见解并未进行讨论。在这一节中,我们提供了单头门控注意力表达能力的理论依据。为了便于后续分析,我们简化了多头注意力的符号表示。具体来说,我们将查询、键和值的序列表示为输入序列的三种变换的输出:
Q
=
Q
(
X
)
,
K
=
K
(
X
)
,
V
=
V
(
X
)
(17)
Q=\mathcal{Q}(X),\quad K=\mathcal{K}(X),\quad V=\mathcal{V}(X)\tag{17}
Q=Q(X),K=K(X),V=V(X)(17)
其中,
Q
,
K
,
V
\mathcal{Q}, \mathcal{K}, \mathcal{V}
Q,K,V 是三个变换,例如线性投影。设
q
∈
Q
=
q
1
,
…
,
q
n
\boldsymbol{q} \in \boldsymbol{Q} = {\boldsymbol{q}_1, \ldots, \boldsymbol{q}_n}
q∈Q=q1,…,qn 是一个单一的查询向量(
q
∈
R
d
\boldsymbol{q} \in \mathbb{R}^d
q∈Rd),并且
a
=
A
(
q
,
K
)
\boldsymbol{a} = \mathcal{A}(\boldsymbol{q}, \boldsymbol{K})
a=A(q,K) 表示
q
\boldsymbol{q}
q 对应的注意力权重,其中
A
\mathcal{A}
A 是注意力变换,即公式(11)中的
f
(
⋅
)
f(\cdot)
f(⋅)。
对于多头注意力,一个常见的实现方法是将查询向量拆分成
h
h
h 个头,在模型维度上进行分割:
q
=
[
q
(
1
)
⋮
q
(
h
)
]
(18)
\boldsymbol{q}= \begin{bmatrix} \boldsymbol{q}^{(1)} \\ \vdots \\ \boldsymbol{q}^{(h)} \end{bmatrix}\tag{18}
q=
q(1)⋮q(h)
(18)
其中,
q
(
i
)
∈
R
d
/
h
\boldsymbol{q}^{(i)} \in \mathbb{R}^{d/h}
q(i)∈Rd/h,且
i
∈
1
,
…
,
h
i \in {1, \ldots, h}
i∈1,…,h 是第
i
i
i 个头的查询向量。
K
\boldsymbol{K}
K 和
V
\boldsymbol{V}
V 也按相同方式进行分割。第
i
i
i 个头的注意力权重为
a
(
i
)
=
A
(
q
(
i
)
,
K
(
i
)
)
a^{(i)} = \mathcal{A}(\boldsymbol{q}^{(i)}, \boldsymbol{K}^{(i)})
a(i)=A(q(i),K(i))。然后,单头和多头注意力的输出分别为:
O
S
H
A
=
a
T
V
=
[
a
T
V
(
1
)
⋮
a
T
V
(
h
)
]
,
O
M
H
A
=
[
a
(
1
)
T
V
(
1
)
⋮
a
(
h
)
T
V
(
h
)
]
(19)
O_{\mathrm{SHA}}=\boldsymbol{a}^T\boldsymbol{V}= \begin{bmatrix} \boldsymbol{a}^T\boldsymbol{V}^{(1)} \\ \vdots \\ \boldsymbol{a}^T\boldsymbol{V}^{(h)} \end{bmatrix},\quad\boldsymbol{O}_{\mathrm{MHA}}= \begin{bmatrix} \boldsymbol{a}^{(1)^T}\boldsymbol{V}^{(1)} \\ \vdots \\ \boldsymbol{a}^{(h)^T}\boldsymbol{V}^{(h)} \end{bmatrix}\tag{19}
OSHA=aTV=
aTV(1)⋮aTV(h)
,OMHA=
a(1)TV(1)⋮a(h)TV(h)
(19)
很容易看出,
O
M
H
A
O_\mathrm{MHA}
OMHA 比
O
S
H
A
O_\mathrm{SHA}
OSHA 更具表达能力,因为
O
M
H
A
O_\mathrm{MHA}
OMHA 利用了
h
h
h 组注意力权重。
在单头门控注意力中,我们为每个 q \boldsymbol{q} q 引入一个门控向量 γ = G ( X ) \gamma = \mathcal{G}(\boldsymbol{X}) γ=G(X),单头门控注意力的输出为 O S H G A = O S H A ⊙ γ O_{\mathrm{SHGA}} = O_{\mathrm{SHA}} \odot \gamma OSHGA=OSHA⊙γ。以下定理揭示了 O S H G A O_\mathrm{SHGA} OSHGA 和 O M H A O_\mathrm{MHA} OMHA 在表达能力上的等价性(证明见附录B):
定理 1 假设变换
G
\mathcal{G}
G 是一个
a
a
a 型的普适逼近器。那么,对于每个
X
\boldsymbol{X}
X,存在一个
γ
=
G
(
X
)
\boldsymbol{\gamma} = \mathcal{G}(\boldsymbol{X})
γ=G(X),使得
O
S
H
G
A
=
O
M
H
A
(20)
O_\mathrm{SHGA}=O_\mathrm{MHA}\tag{20}
OSHGA=OMHA(20)
定理 1 表明,通过简单地引入门控向量,
O
S
H
G
A
O_\mathrm{SHGA}
OSHGA 与
O
M
H
A
O_\mathrm{MHA}
OMHA 在表达能力上是等价的。实际上,变换
G
\mathcal{G}
G 通常通过一个(浅层)神经网络来建模,其逼近的普适性已经得到广泛研究(Hornik等人,1989;Yarotsky,2017;Park等人,2020)。
3.4 Mega块
Mega层(带有移动平均的门控注意力)可作为Transformer中常规注意力的替代层。它后面跟随逐位置的前馈网络(FFNs)和归一化层,组成一个Mega块。由于门控残差连接已经包含在公式(15)中,我们省略了原始的残差连接,直接对
Y
Y
Y 应用归一化层:具体而言,
Y
=
N
o
r
m
(
M
e
g
a
(
X
)
)
Y
′
=
N
o
r
m
(
F
F
N
(
Y
)
+
Y
)
(21)
\begin{aligned} & \mathbf{Y}=\mathrm{Norm}(\mathrm{Mega}(\boldsymbol{X})) \\ & \mathbf{Y}^{\prime}=\mathrm{Norm}(\mathrm{FFN}(\boldsymbol{Y})+\boldsymbol{Y}) \end{aligned}\tag{21}
Y=Norm(Mega(X))Y′=Norm(FFN(Y)+Y)(21)
在这里,Y₀ 是 Mega block 的输出。Mega block 的整体架构如图 2 (a) 所示。在 Transformer 中,FFN(前馈网络)的隐藏维度通常设置为
d
F
F
N
=
4
d
d_{FFN} = 4d
dFFN=4d。为了保持与每个 Transformer block 相似的模型规模,我们将 FFN 的隐藏维度减小为$ d_{FFN }= 2d$,并将公式(10)中值序列的扩展维度 v 设置为 2d,除非另有说明。
3.5 Mega-chunk:具有线性复杂度的 Mega
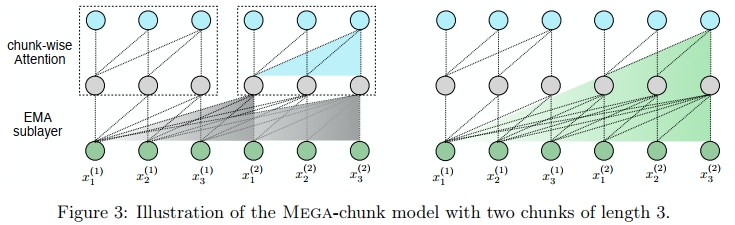
到目前为止,我们只关注在注意力机制中引入更强的归纳偏差,而注意力机制本身仍然具有平方的计算复杂度。在本节中,我们提出了 Mega-chunk,Mega 的一个变种,具有线性复杂度,它通过将注意力应用于每个固定长度的局部块来简化计算。
具体来说,我们首先将(8-10)式中的查询、键和值序列划分为长度为 c c c 的块。例如, Q = Q 1 , … , Q k Q={Q_1,\ldots,Q_k} Q=Q1,…,Qk,其中 k = n / c k=n/c k=n/c 是块的数量。注意力操作(11)分别应用于每个块,从而使计算复杂度为 O ( k c 2 ) = O ( n c ) O(kc^{2})=O(nc) O(kc2)=O(nc),相对于 n n n。然而,这种方法存在一个关键的限制,即它会丧失来自其他块的上下文信息。幸运的是,MEGA 中的 EMA 子层通过捕捉每个 token 附近的局部上下文信息来缓解这一问题,这些输出被用作注意力子层的输入。因此,块级注意力所利用的有效上下文可以超越块边界。图 3 展示了一个 MEGA-chunk 块所能捕捉到的最大依赖长度。
4. 实验
为了评估 Mega,我们在五个基准序列建模任务上进行了实验,涵盖了各种数据类型,并与当前在每个任务上的最先进模型进行了比较。所有带有 z 的数字表示我们复现的基准模型的结果。更详细的描述、结果和分析见附录 D。
4.1 长上下文序列建模
我们从在最近由 Tay 等人(2021)提出的长范围竞技场(LRA)基准上的评估开始,这个基准旨在评估长上下文场景下的序列模型。他们在这个基准中收集了六个任务,分别是 ListOps(Nangia 和 Bowman, 2018)、字节级文本分类(Text;Maas 等人, 2011)、字节级文档检索(Retrieval;Radev 等人, 2013)、基于像素序列的图像分类(Image;Krizhevsky 等人, 2009)、Pathfinder(Linsley 等人, 2018)及其极长版本(Path-X;Tay 等人, 2021)。这些任务包括了从 1K 到 16K token 的输入序列,涵盖了多种数据类型和模态。
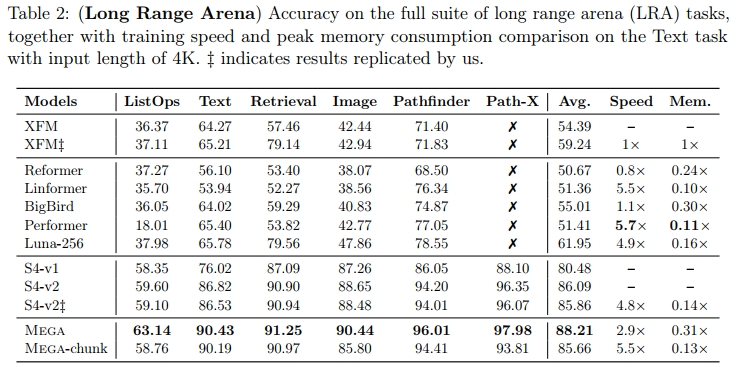
表 2 比较了 Mega 与几个基准模型的表现,包括 Transformer 及其高效变体,以及最先进的 S4 模型(包括版本 1(Gu 等人,2022a)和版本 2(Gu 等人,2022b))。为了确保公平比较,我们在每个任务上调整了层数和模型维度,使得 Mega 的参数数量与 S4-v1 相似。对于每个实验,我们报告了 5 次不同随机种子的平均结果。调优信息和模型细节见附录 D.1。
在所有六个任务中,Mega 明显优于所有基准模型。我们还在每个任务上评估了 Mega-chunk,通过将所有任务的块大小设为 c = 128,除了 Path-X,其中 c = 4096。我们观察到 Mega-chunk 始终表现良好,尤其在三个语言任务上表现突出。我们还检查了 Mega 在字节级分类任务(输入长度为 4K)上的速度和内存效率。Mega-chunk 的效率非常高,速度是普通 Transformer 的 5.5 倍,内存消耗仅为 Transformer 的 13%。有趣的是,具有完整注意力域的 Mega 在效率上也明显优于 Transformer,得益于单头门控注意力。
多维阻尼 EMA 的分析
为了展示 Mega 中多维阻尼 EMA 组件的有效性,我们对两个 LRA 任务(字节级文本分类(Text)和像素序列图像分类(Image))进行了消融实验。我们训练了具有不同 EMA 维度 $h ∈ {0, 1, 2, 4, 8, 16, 32} $的 Mega 模型,其中 h = 0 表示移除 EMA 组件。从图 4 左侧的图像中,我们可以看到,在没有 EMA 组件的情况下,两个任务的模型准确率迅速下降。同时,通过使用一维 EMA(h = 1),Mega 在两个任务上都获得了显著提升,证明了通过 EMA 引入归纳偏差的重要性。
块大小的分析
我们进一步分析了块大小 c 对同两个任务的影响,通过改变 c ∈ {16, 32, 64, 128, 256, 512, 1},其中 1 表示原始的没有分块的 Mega。图 4 右侧的图像显示,图像数据对块大小比文本数据更敏感。在 Text 任务中,即使是小块大小 c = 16 的 Mega-chunk 也能达到约 90% 的准确率。在 Image 任务中,Mega-chunk 使用 c = 16 取得了约 75% 的准确率,这仍然远超普通 Transformer 模型。
注意力函数的分析
最后,我们评估了不同注意力函数的性能。表 3 显示了三种注意力函数在相同两个任务上的准确率。在文本数据上,softmax 获得了最佳准确率,而在图像数据上表现最差。laplace 函数在图像数据上获得了最佳准确率,并且在文本数据上也表现得相当有竞争力,始终优于
r
e
l
u
2
relu^2
relu2。在以下实验中,我们对语言任务使用 softmax,对视觉和语音任务使用 laplace。
4.2 原始语音分类
为了评估 Mega 在长范围建模语音信号方面的能力,我们将 Mega 应用于原始语音分类(长度为 16000),而不是使用传统的预处理方法(例如转换为 MFCC 特征)。按照 Gu 等人(2022a)的方法,我们在 Speech Commands 数据集的 SC10 子集上进行语音分类(Warden,2018)。我们使用 Mega-chunk 变体,块大小设为 c = 1000,因为 Mega 和 Transformer 的计算无法适应 GPU 内存。如表 4 所示,我们的 Mega-chunk(base)模型,具有 30 万个参数,能够达到 96.92 的准确率,略低于最先进的 S4 方法的 97.50。然而,通过增加 0.18M 参数,Mega-chunk(big)模型的表现与 S4 相当。
4.3 自回归语言建模
我们在两个已建立的语言建模基准上评估 Mega——WikiText-103(Merity 等人,2017)和 enwik8(Hutter,2006),这两个任务都是预测下一个 token。WikiText-103 是一个词级别的语言建模数据集,包含来自 Wikipedia 文章的 1.03 亿个训练 token。根据之前的工作(Baevski 和 Auli,2018;Dai 等人,2019),我们采用了自适应 softmax 和输入嵌入,并使用 26 万词汇表。Enwik8 是一个字符级别的语言建模基准,包含来自未处理的 Wikipedia 文章的 1 亿个 token,词汇表大小约为 200。在测试时,我们将测试数据分割成多个段,并按顺序处理每个段。在表 5 中,我们与之前的顶级模型进行了比较,
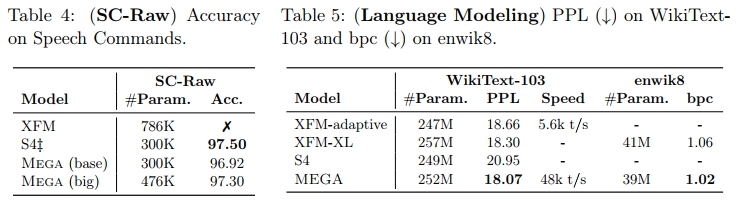
这些模型旨在利用更长的上下文,包括 Transformers(Baevski 和 Auli,2018;Al-Rfou 等人,2019)(XFM-adaptive),Transformer-XL(Dai 等人,2019)(XFM-XL)和 S4(Gu 等人,2022a)。在 WikiText-103 和 enwik8 上,我们获得了非常具有竞争力的结果,显著超越了基准模型,同时相比 Transformer 模型享有更快(9 倍)的推理速度。由于 EMA 层的递归设计,Mega 在推理时也能自然地实现长度外推,适应比训练时更长的序列。此外,由于在训练中使用了旋转位置嵌入(Su 等人,2021),我们还可以对 Mega 的注意力块大小进行外推。我们在附录 D.3 中详细描述了这些内容,并提供了使用不同测试时块大小和段长度的完整结果。
4.4 神经机器翻译
为了评估 Mega 在序列到序列建模上的表现,我们在一个标准的机器翻译基准上进行了实验,即 WMT 2016 英语-德语新闻翻译(WMT’16),该数据集包含 450 万句对的训练数据。按照 Ott 等人(2018)的方法,我们在 newstest13 上进行验证,并在 newstest14 上进行测试。Mega 模型的架构紧跟 Transformer-base:6 个编码器和解码器层,模型维度 d = 512。
表 6 展示了 WMT’16 测试集的 BLEU 分数,包括两个方向:EN→DE 和 DE→EN。对于每个实验,我们报告了 5 个不同随机种子的平均结果,包括标记化的 BLEU 分数和 SacreBLEU(Post,2018)分数。Mega-base 明显优于 Transformer-base,BLEU 分数提高了超过 1.1。我们还报告了使用 Laplace 注意力函数的 Mega 的结果,尽管它略微但持续地逊色于 Softmax。
4.5 图像分类
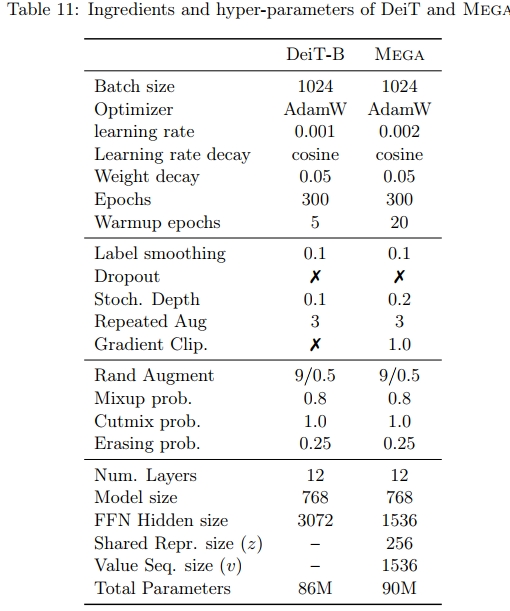
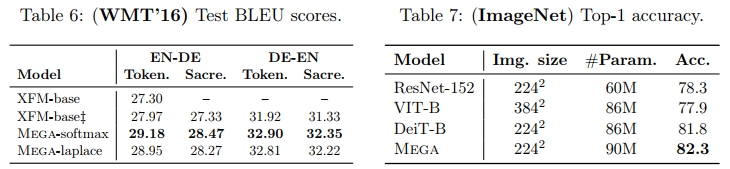
为了评估 Mega 在大规模图像分类任务上的表现,我们在 Imagenet-1k(Deng 等人,2009)数据集上进行了实验,该数据集包含 128 万张训练图像和 5 万张验证图像,来自 1000 个类别。表 7 中报告了在验证集上的 Top-1 准确率,以评估不同模型的表现。Mega 相较于 DeiT-B(Touvron 等人,2021)获得了大约 0.5% 的准确率提升。我们大部分遵循 DeiT 的方法,应用了多种数据增强和正则化方法来促进训练过程,包括 Cutmix(Yun 等人,2019)、Mixup(Zhang 等人,2017)、随机深度(Huang 等人,2016)、重复增强(Hoffer 等人,2020)、Rand-Augment(Cubuk 等人,2020)和随机擦除(Zhong 等人,2020)。这些方法主要针对优化 DeiT 的性能进行了高度调优,可能对于 Mega 来说并不是最优的。探索适合 Mega 的最佳数据增强和正则化方法是未来工作的一个有趣方向。更多的训练细节见附录 D.5。
5. 相关工作
最近有许多技术被提出,以解决 Transformer 模型的两个问题;由于篇幅限制,这里仅提到其中的一些。
归纳偏差
为了将更强的归纳偏差引入注意力机制,一个研究方向集中于通过高级位置编码方法注入位置信息,包括绝对和相对位置嵌入(Vaswani 等人,2017;Huang 等人,2020;Ke 等人,2020),以及相对位置偏置(Su 等人,2021;Press 等人,2021)。另一个研究方向将注意力机制与其他具有内在强归纳偏差的神经架构相结合,如卷积(Gehring 等人,2017;Dai 等人,2021)和递归(Dai 等人,2019;Rae 等人,2020;Lei,2021)。
计算效率
最近出现了许多先进的 Transformer 模型变体(“xformers”)(Tay 等人,2020,2021),旨在提高时间和内存效率。流行的技术包括稀疏注意力模式(Parmar 等人,2018;Beltagy 等人,2020;Kitaev 等人,2020),注意力矩阵的低秩近似(Wang 等人,2020;Ma 等人,2021),以及通过核化近似(Choromanski 等人,2020;Peng 等人,2021)。尽管这些模型在长序列上展示了更好的渐进复杂度,但它们在中等长度序列上的效率提升不明显,其性能仍落后于常规注意力的 Transformer 模型。
具有连续核的卷积神经网络
由于 EMA 及更一般的状态空间模型(如 S4)可以视为序列长度等于核大小的卷积变换,Mega 也与具有连续核的 CNN(卷积神经网络)相关,包括 CKConv(Romero 等人,2021)、FlexConv(Romero 等人,2022a)和 CCNN(Romero 等人,2022b)。
6. 结论
我们介绍了 Mega,这是一种简单、高效且有效的神经架构,可作为常规多头注意力的替代方案。通过利用经典的指数移动平均(EMA)方法,Mega 能够将更强的归纳偏差融入注意力机制。此外,EMA 方法还使得 Mega-chunk 的设计成为可能,Mega-chunk 是 Mega 的一个高效变种,具有线性复杂度。在五个涉及各种数据类型的序列建模任务中,Mega 显著超越了包括之前的最先进系统在内的多种强基准模型。这些改进为未来将 Mega 应用于多模态建模提供了潜在方向。
附录:Mega:带有移动平均门控注意力的模型
附录 A. 多维阻尼 EMA 的高效计算
注意,不同维度的多维阻尼 EMA 计算彼此完全独立。在不失一般性的情况下,我们设定 d = 1,并在以下公式中省略维度索引 j。我们将初始隐藏状态表示为 h0h_0。在(5)中定义的多维阻尼 EMA 可以向量化为以下公式:
h
t
=
α
⊙
u
t
+
(
1
−
α
⊙
δ
)
⊙
h
t
−
1
(22)
\mathbf{h}_t=\mathbf{\alpha}\odot\mathbf{u}_t+(1-\mathbf{\alpha}\odot\mathbf{\delta})\odot\mathbf{h}_{t-1}\tag{22}
ht=α⊙ut+(1−α⊙δ)⊙ht−1(22)
y t = η T h t (23) \mathbf{y}_t=\mathbf{\eta}^T\mathbf{h}_t\tag{23} yt=ηTht(23)
其中 α、δ 和 η ∈ R h η ∈ ℝ^h η∈Rh, u t = β x t ∈ R h u_t = βx_t ∈ ℝ^h ut=βxt∈Rh, h t ∈ R h h_t ∈ ℝ^h ht∈Rh 是时刻 t 的 EMA 隐藏状态。我们设 φ = 1 − α ⊙ δ φ = 1 - α ⊙ δ φ=1−α⊙δ。然后,明确展开上述两个方程得到:
h 1 = ϕ ⊙ h 0 + α ⊙ β x 1 \mathbf{h}_1=\phi\odot\mathbf{h}_0+\alpha\odot\beta\mathbf{x}_1 h1=ϕ⊙h0+α⊙βx1 h 2 = ϕ 2 ⊙ h 0 + ϕ ⊙ α ⊙ β x 1 + α ⊙ β x 2 \mathbf{h}_2=\phi^2\odot\mathbf{h}_0+\phi\odot\alpha\odot\beta\mathbf{x}_1+\alpha\odot\beta\mathbf{x}_2 h2=ϕ2⊙h0+ϕ⊙α⊙βx1+α⊙βx2
y 1 = η T ϕ ⊙ h 0 + η T α ⊙ β x 1 \mathbf{y}_1=\eta^T\phi\odot\mathbf{h}_0+\eta^T\alpha\odot\beta\mathbf{x}_1 y1=ηTϕ⊙h0+ηTα⊙βx1 y 2 = η T ϕ 2 ⊙ h 0 + η T ϕ ⊙ α ⊙ β x 1 + η T α ⊙ β x 2 \mathbf{y}_{2}=\boldsymbol{\eta}^{T}\boldsymbol{\phi}^{2}\odot\mathbf{h}_{0}+\boldsymbol{\eta}^{T}\boldsymbol{\phi}\odot\boldsymbol{\alpha}\odot\boldsymbol{\beta}\mathbf{x}_{1}+\boldsymbol{\eta}^{T}\boldsymbol{\alpha}\odot\boldsymbol{\beta}\mathbf{x}_{2} y2=ηTϕ2⊙h0+ηTϕ⊙α⊙βx1+ηTα⊙βx2
这可以写成一个向量化的公式:
y
t
=
η
T
ϕ
t
⊙
h
0
+
η
T
ϕ
t
−
1
⊙
α
⊙
β
x
1
+
…
+
η
T
α
⊙
β
x
t
(24)
\mathbf{y}t=\mathbf{\eta}^T\mathbf{\phi}^t\odot\mathbf{h}0+\mathbf{\eta}^T\mathbf{\phi}^{t-1}\odot\mathbf{\alpha}\odot\mathbf{\beta}\mathbf{x}1+\ldots+\mathbf{\eta}^T\mathbf{\alpha}\odot\mathbf{\beta}\mathbf{x}t\tag{24}
yt=ηTϕt⊙h0+ηTϕt−1⊙α⊙βx1+…+ηTα⊙βxt(24)
y = K ∗ x + η T ϕ t ⊙ h 0 (25) \mathbf{y}=\mathcal{K}*\mathbf{x}+\eta^T\phi^t\odot\mathbf{h}_0\tag{25} y=K∗x+ηTϕt⊙h0(25)
其中 * 是具有核 $K ∈ ℝ^n $的卷积变换:
K
=
(
η
T
(
α
⊙
β
)
,
η
T
(
ϕ
⊙
α
⊙
β
)
,
…
,
η
T
(
ϕ
t
⊙
α
⊙
β
)
)
(26)
\mathcal{K}= \begin{pmatrix} \eta^T(\alpha\odot\beta), & \eta^T(\phi\odot\alpha\odot\beta), & \ldots, & \eta^T(\phi^t\odot\alpha\odot\beta) \end{pmatrix}\tag{26}
K=(ηT(α⊙β),ηT(ϕ⊙α⊙β),…,ηT(ϕt⊙α⊙β))(26)
在提出的多维阻尼 EMA 中,K 可以通过 Vandermonde 乘积高效计算。给定 K 后,可以通过 FFT 高效计算公式 (25) 中的输出 y。
附录 B. 定理 1 的证明
证明:我们将 γ 分成 h 个头,方式与 Q、K 和 V 相同:
γ
=
[
γ
(
1
)
⋮
γ
(
h
)
]
\gamma= \begin{bmatrix} \gamma^{(1)} \\ \vdots \\ \gamma^{(h)} \end{bmatrix}
γ=
γ(1)⋮γ(h)
然后我们得到:
O
S
H
G
A
=
a
T
V
⊙
γ
=
[
a
T
V
(
1
)
⊙
γ
(
1
)
⋮
a
T
V
(
h
)
⊙
γ
(
h
)
]
O_{\mathrm{SHGA}}=a^TV\odot\gamma= \begin{bmatrix} a^TV^{(1)}\odot\gamma^{(1)} \\ \vdots \\ a^TV^{(h)}\odot\gamma^{(h)} \end{bmatrix}
OSHGA=aTV⊙γ=
aTV(1)⊙γ(1)⋮aTV(h)⊙γ(h)
为了证明定理 1,我们需要找到 γ,使得:
a
T
V
(
i
)
⊙
γ
(
i
)
=
a
(
i
)
T
V
(
i
)
⟺
γ
(
i
)
=
a
(
i
)
T
V
(
i
)
⊘
a
T
V
(
i
)
,
∀
i
∈
{
1
,
…
,
h
}
a^T\boldsymbol{V}^{(i)}\odot\boldsymbol{\gamma}^{(i)}=\boldsymbol{a}^{(i)^T}\boldsymbol{V}^{(i)}\Longleftrightarrow\boldsymbol{\gamma}^{(i)}=\boldsymbol{a}^{(i)^T}\boldsymbol{V}^{(i)}\oslash\boldsymbol{a}^T\boldsymbol{V}^{(i)},\forall i\in\{1,\ldots,h\}
aTV(i)⊙γ(i)=a(i)TV(i)⟺γ(i)=a(i)TV(i)⊘aTV(i),∀i∈{1,…,h}
其中 ∅ 是逐元素除法操作。由于 G(X) 是一个通用逼近器,并且 Q、K、V 和
a
a
a 都是从 X 转换而来,理论上 γ 可以恢复
a
(
i
)
a^{(i)}
a(i)TV(i)∅
a
T
V
(
i
)
,
∀
X
a^TV^{(i)}, \forall X
aTV(i),∀X。
附录 C. 拉普拉斯注意力函数
为了使用(16)中的拉普拉斯函数近似平方 ReLU 函数,我们需要选择合适的系数 μ 和 σ。我们通过在
x
=
2
x=\sqrt{2}
x=2 时解以下两个方程来推导 μ 和 σ 的值:
f
r
e
l
u
2
(
2
)
=
f
l
a
p
l
a
c
e
(
2
)
(27)
f_{\mathrm{relu}2}(\sqrt{2})=f_{\mathrm{laplace}}(\sqrt{2})\tag{27}
frelu2(2)=flaplace(2)(27)
f r e l u 2 ′ ( 2 ) = f l a p l a c e ′ ( 2 ) (28) f_{\mathrm{relu}2}^{\prime}(\sqrt{2})=f_{\mathrm{laplace}}^{\prime}(\sqrt{2})\tag{28} frelu2′(2)=flaplace′(2)(28)
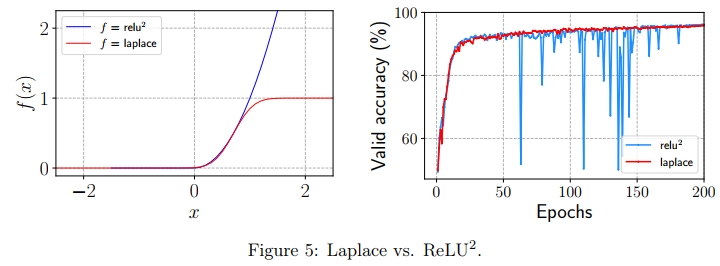
公式(27)得出 μ = 1 / 2 \mu=\sqrt{1/2} μ=1/2,随后公式(28)给出 σ = 1 / 4 π \sigma=\sqrt{1/4\pi} σ=1/4π。图5展示了这两个函数的可视化结果。
C.1 稳定性:拉普拉斯 vs. 平方ReLU
除了性能改进之外,我们还研究了两种注意力函数的稳定性。我们在LRA Pathfinder任务上使用MEGA模型对这两种函数进行了实验。图5展示了训练过程中验证集上的准确率。我们观察到,拉普拉斯函数比ReLU 2 ^2 2函数稳定得多。
附录 D. 实验细节
D.1 长距离竞技场(LRA)
对于所有任务,我们严格遵循 Tay 等人(2020)的工作,包括数据预处理、数据划分等细节。Mega 模型在这些任务上的超参数列于表 8 中。
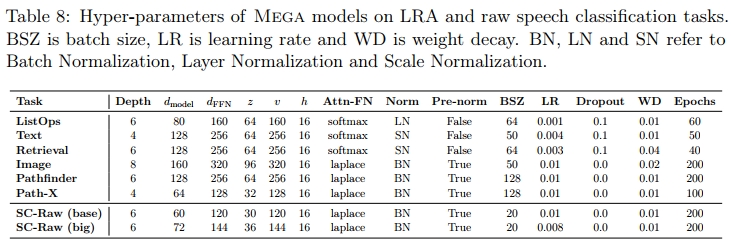
D.2 原始语音分类
按照 Gu 等人(2022a)的研究,我们在 Speech Commands 数据集(Warden, 2018)的 SC10 子集上进行语音分类任务,这是一个 10 类分类任务。Mega-chunk 的分块大小为 1000。其他超参数列于表 8 中。
D.3 语言建模
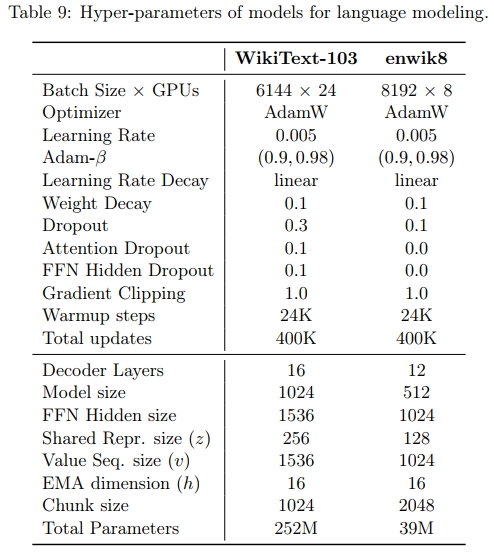
训练细节
我们使用 WikiText-103 和 enwik8 的数据及其划分(由 Dai 等人于 2019 年提供)。在训练时,我们将训练数据分割成若干段;每段包含 m 个连续的分块,其中分块大小是有效的注意力长度。m 是一个从 [cl; ch] 中均匀采样的随机整数变量。对于 WikiText-103,我们使用 [cl; ch] = [2; 6],而对于 enwik8,我们使用 [cl; ch] = [2; 4]。其他训练超参数(包括优化器、学习率调度器和架构)列于表 9 中。
推理时的长度外推
我们在训练时使用 Mega-chunk(§3.5),并将注意力分块大小分别设置为 1024(WikiText-103)和 2048(enwik8)。为了在推理时使用比训练时更长的 Mega 注意力长度(即 1024 或 2048),我们在注意力子层中应用了旋转位置嵌入(Su 等人,2021)。在测试时,我们将测试数据分割成 K 段,并依次处理每段的 m 个分块,即每段的最大上下文长度为
#
测试 token 数
K
\frac{\#\text{测试 token 数}}{K}
K#测试 token 数。在表 5 中,我们报告了使用更长分块大小(注意力长度)的测试结果,分别为 WikiText-103 的 2048 和 enwik8 的 4096。由于 EMA 层的循环设计,Mega 可以在推理时自然地外推到比训练时更长的序列。这种设计使得每个分块的输入可以通过 EMA 访问历史上下文,如图 3 所示。
另一方面,由于使用了旋转位置嵌入,注意力可以在测试时处理比训练时更长的分块大小。我们希望这两种长度外推方式对读者来说是清晰的。我们在下面提供了关于这两种长度外推方式的消融研究,即通过增加输入序列长度外推到更长的上下文,以及通过增加分块大小外推到更长的注意力长度。
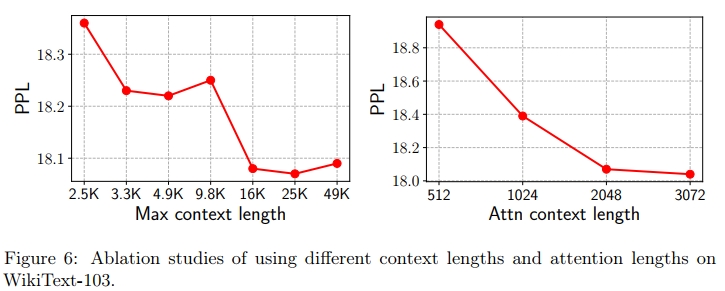
上下文长度的消融实验
首先,我们将分块大小固定为 2048,并在 [100; 75; 50; 25; 15; 10; 5] 范围内调整 K,对应的最大上下文 token 数分别为 [2.5K; 3.3K; 4.9K; 9.8K; 16K; 25K; 49K]。我们在图 6 的左侧绘制了随着上下文长度增加时的测试 PPL(困惑度)。尽管在训练时模型所见的最大上下文长度为 6144,但 Mega 能够外推到更长的上下文长度。图中显示,随着上下文长度的增加,PPL 逐渐下降,并且当上下文长度超过 25K 时,改进趋于饱和。这一结果与 Press 等人(2021)的观察一致。
注意力分块大小的消融实验
接下来,我们将上下文长度固定为 25K,并将分块大小从 512 增加到 3072。如图 6 右侧所示,尽管 Mega 在训练时仅使用了 1024 的注意力长度,但随着注意力长度的增加,其性能持续提升。这一发现与 Alibi(Press 等人,2021)的研究结果相矛盾,Alibi 发现旋转位置嵌入无法泛化到更长的长度,并会导致更高的 PPL。
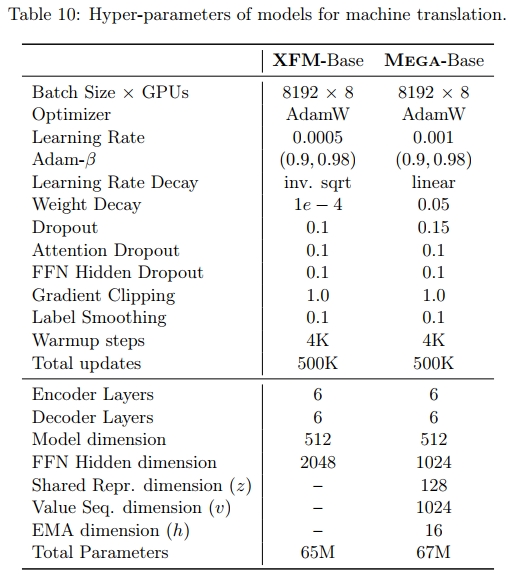
D.4 机器翻译
WMT 2016 英德数据集包含 450 万对平行句对用于训练。我们遵循标准设置(Ott 等人,2018),使用 Newstest2013 作为验证集,Newstest2014 作为测试集。数据集按照(Ma, 2020)的方法进行预处理,使用 FairSeq 包(Ott 等人,2019)中的脚本。我们在语言对内共享源语言和目标语言的词汇表,采用 32K 字节对编码(BPE)类型(Sennrich 等人,2016)。Transformer 和 Mega 模型的超参数列于表 10 中。
D.5 图像分类
超参数列于表 11 中。我们严格遵循 Touvron 等人(2021)的研究,复用了他们的大部分超参数。