作者及发刊详情
@inproceedings{haq,
author = {Wang, Kuan and Liu, Zhijian and Lin, Yujun and Lin, Ji and Han, Song},
title = {HAQ: Hardware-Aware Automated Quantization With Mixed Precision},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
摘要
Motivation
- DNN硬件加速器开始支持混合精度(1-8位)进一步提高计算效率,这对找到每一层的最佳位宽提出了一个巨大的挑战:它需要领域专家探索巨大的设计空间,在精度,延迟,能耗和模型大小之间权衡。
- 当前有很多专用的神经网络专用加速器,但没有为这些加速器设计专用的神经网络优化方法。传统的量化算法忽视了不同的硬件架构,网络所有层都采用一种量化方式。
Contribution
1)自动化
提出了自动量化框架,无需领域专家或基于规则的启发式方法,将人力从探索位宽选择中解放出来
2)硬件感知
该框架在循环指令流中考虑了硬件架构,不依赖中间信号(proxy signal),可以直接减少延迟、能耗和存储
3)专用化
为不同的硬件架构都提出专门的量化策略,完全为目标硬件架构定制,以优化延迟和能耗。
4)设计视角
将计算和访存都考虑在内,为不同的硬件架构提供了不同的量化策略解释
Approach
引入了基于硬件感知的自动量化(HAQ)框架,该框架利用强化学习来自动确定量化策略,并在设计回路中获取硬件加速器的反馈。而不是依赖于代理信号,如FLOPS和模型大小,该文使用一个硬件模拟器来生成直接的反馈信号(延迟和能耗)到RL代理。
Experiment
实验验证平台:
选用模型:
训练数据集:
推理任务
工具:
实验评估
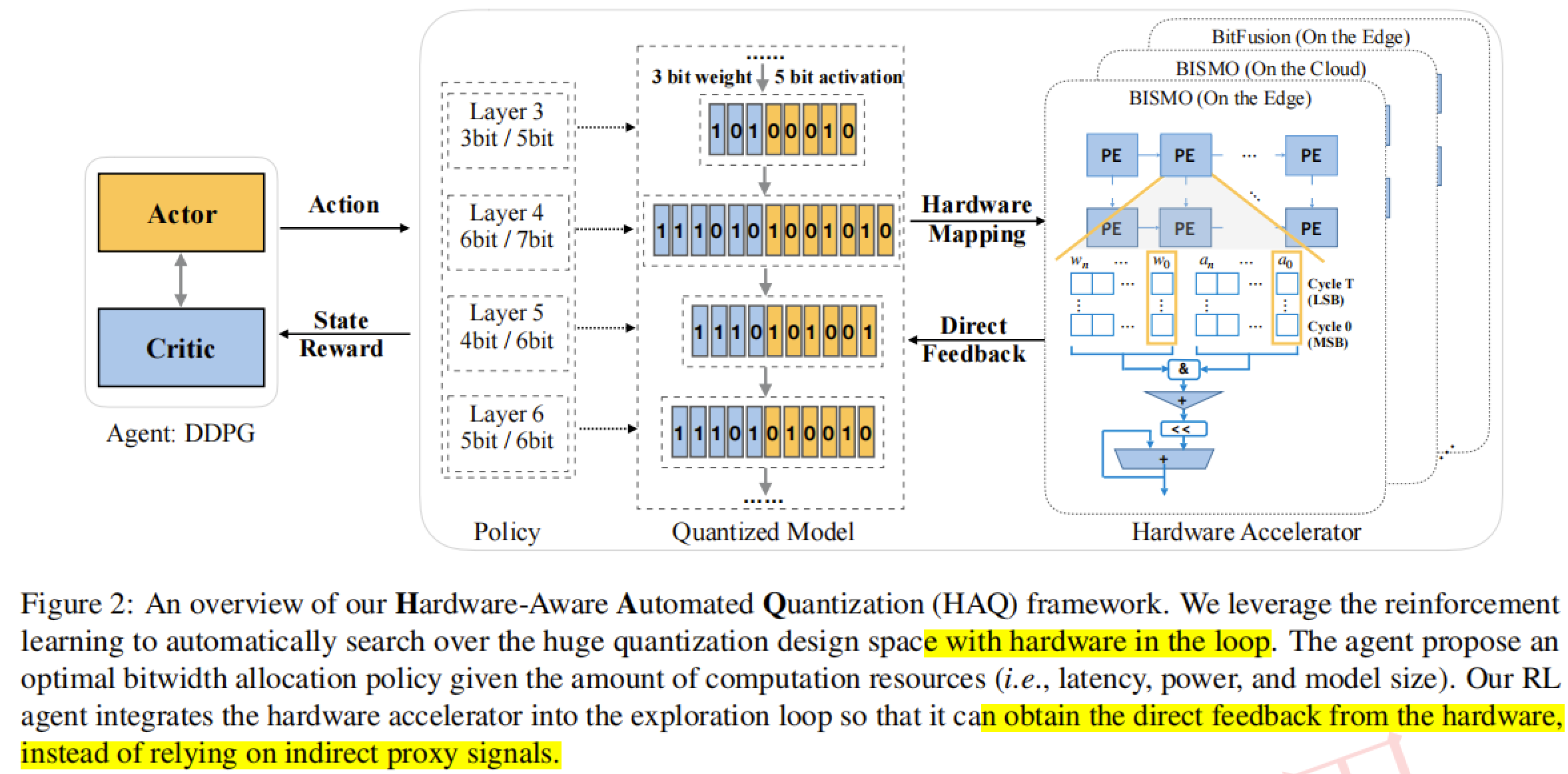
结论
框架有效地减少了1.4-1.95×的延迟和1.9×的能耗,而accu的损失可以忽略不计