Transformer
半年前刚开始踏入深度学习的时候,看李弘毅的视频了解了一点Transformer。这次的笔记也是基于李宏毅视频讲解的内容。
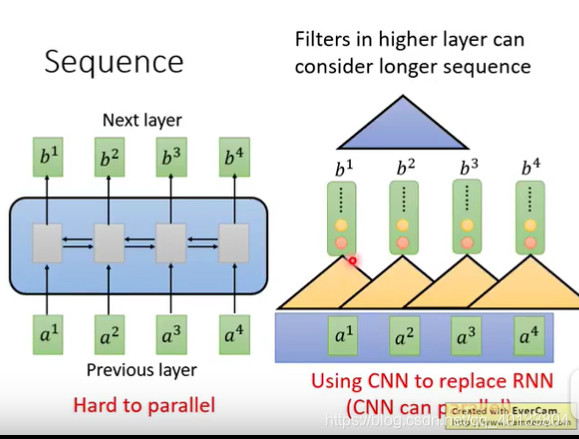
在处理seq2seq问题时,我们首先能想到的就时rnn,它的优势是能结合上下文把握全局,不足是,它的计算不能实现平行。如下图,要想得到b4,必须先计算出b1,b2,b3。但如果用cnn替换rnn那就可以实现并行了,只不过这样的cnn需要构建多层,如图右边(三角形就是cnn的结构)。
想结合上述rnn核cnn的优势,就有了self-Attention。
self-Attention
特点:能力和rnn一样,但优势在于可以同时计算b1-b4。
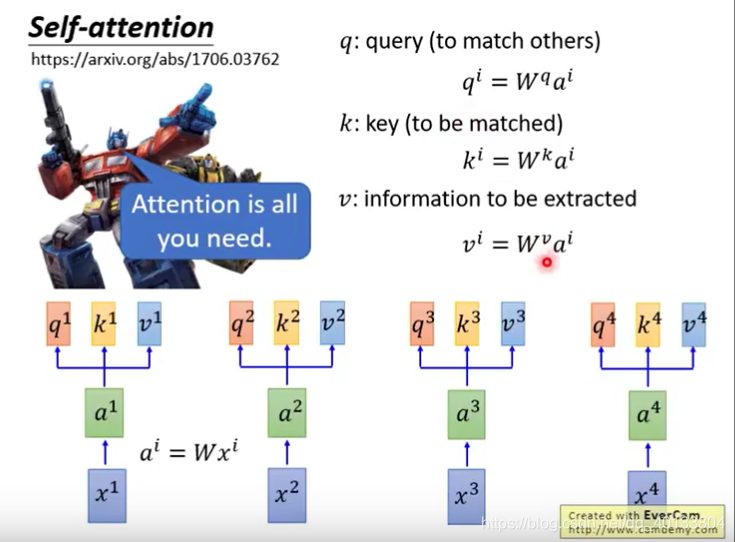
由a1,a2,a3,a4,乘以不同的w,得到相应的q,k,v。
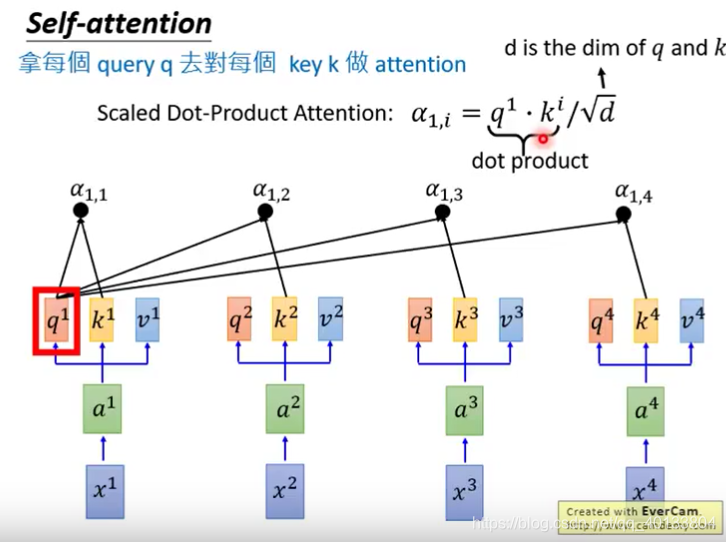
然后拿每个q对每个k做Attention。如下所示:
得到阿法1,i后,进行softmax,然后再乘上各自的v,相加起来就得到b1了