1. GPT的概念
GPT 系列是 OpenAI 的一系列预训练模型,GPT 的全称是 Generative Pre-Trained Transformer,顾名思义,GPT 的目标是通过Transformer,使用预训练技术得到通用的语言模型。和BERT类似,GPT-1同样采取pre-train +fine-tune的思路:先基于大量未标注语料数据进行预训练,后基于少量标注数据进行微调。
2 实践
2.1 配置环境
安装`mindnlp 套件

2.2 任务训练
OpenAIGPTForSequenceClassification的一些权重没有从openai-gpt的模型检查点初始化,而是重新初始化。
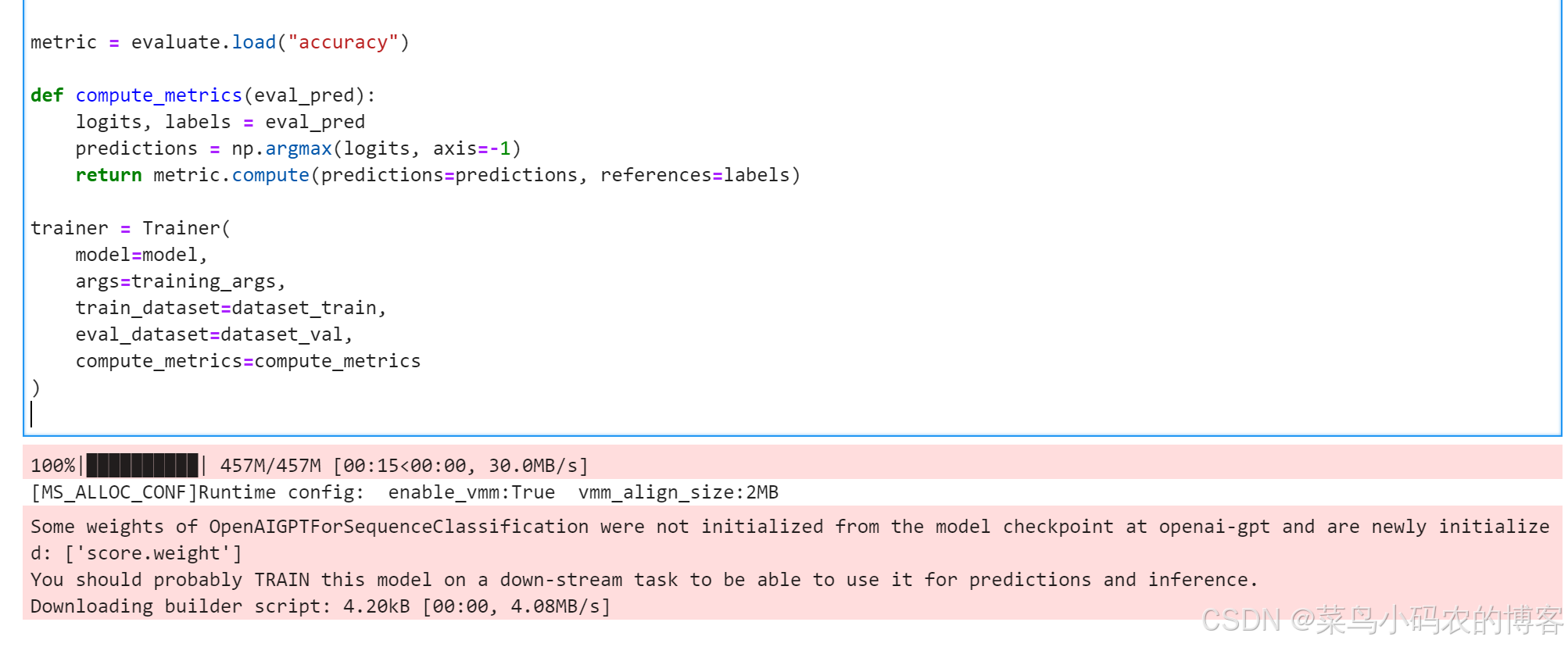
2.3 训练完成
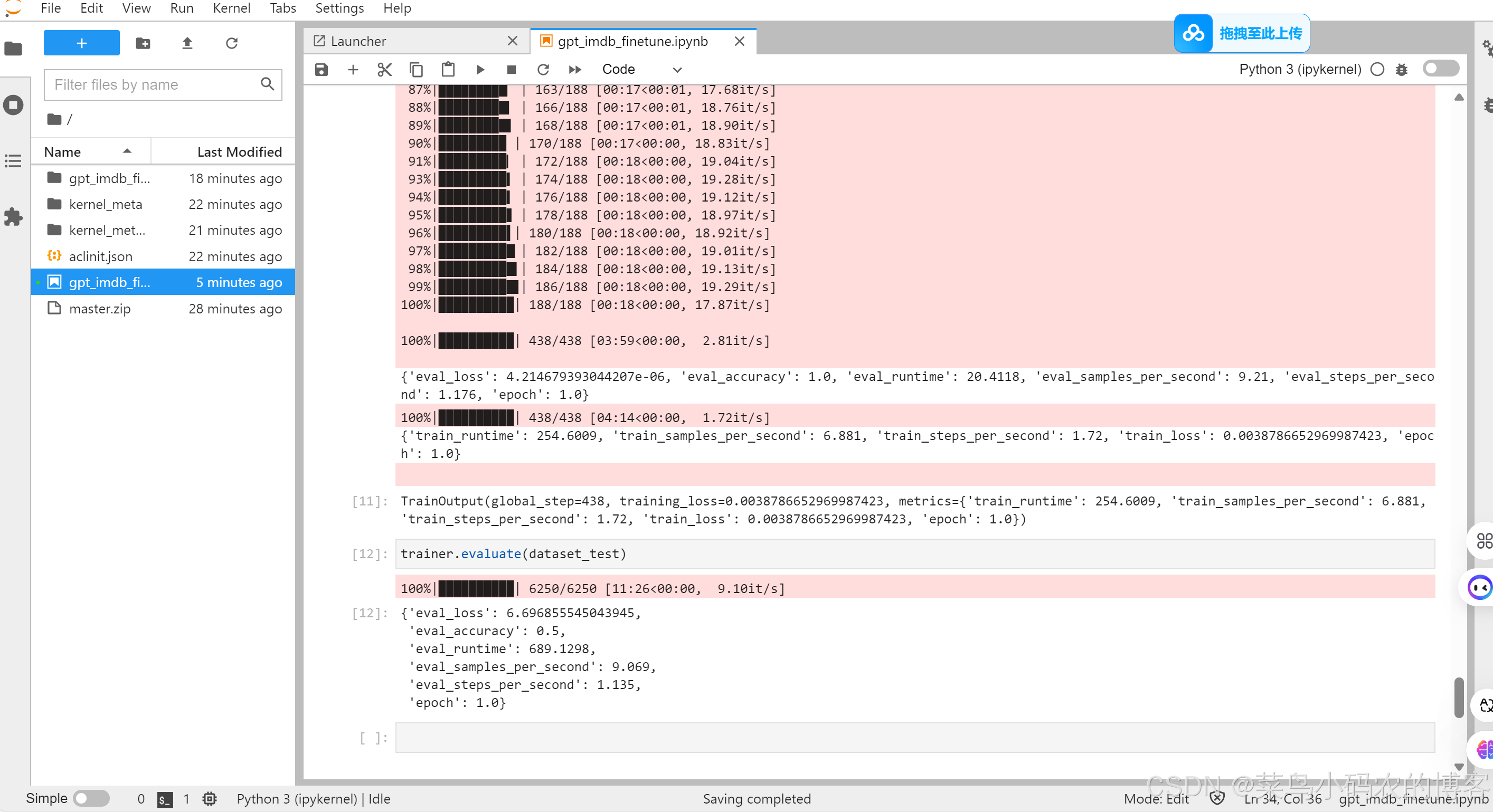
3. 感悟
GPT也是输入句子或者句子对的,并且GPT添加了special tokens。GPT是由Decoder Layer堆叠,Decoder Layer的组成与Transformer Decoder Layer是相似的,不过是没有计算Encode输出与Decoder输入之间的注意力分数multi-head attention的。
相对于BERT,GPT更加注重语句的生成,也就是根据签名的内容预测下一个词是什么。也就是说,GPT更适合生成式的下游任务。
经过这一节课,对于Transformer、BERT以及GPT的理解更加的深刻,对于生成式的大模型有了一个比较直观的认识,对于大模型是如何理解人类语言的方法有了一个初步的认识。而且对模型的微调等概念与方法也有了一个直观地认识。