在项目中遇到一块关于es的多条件聚合的代码,如下:
AggregationBuilders
.terms(“agg_name”)
.field(“name”)
.size(Integer.MAX_VALUE)
.subAggregation(AggregationBuilders
.topHits(“top”)
.sort(“time”,SortOrade.DESC)
.from(0).size())
读的时候不是很理解,因此对多条件聚合进行一下系统学习。
聚合的分类
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
* TermAggregation: 按照文档字段分组
* Date Histogram: 按照日期阶梯分组,例如一周为一组,或者一个月为一组。 - 度量(Metric)聚合:用以计算一些值,比如:最大、最小、平均值等。
* Avg:求平均值
* Max:求最大值
* Min:求最小值
* Stats: 同时求max、min、avg、sum等 - 管道(pipeline)聚合:其他聚合的结果为基础再对其进行聚合
DSL语言实现Bucket聚合
在es中的一个索引中,存储着各种酒店信息。现在需要统计所有数据中的酒店品牌有几种。酒店部分数据如下:
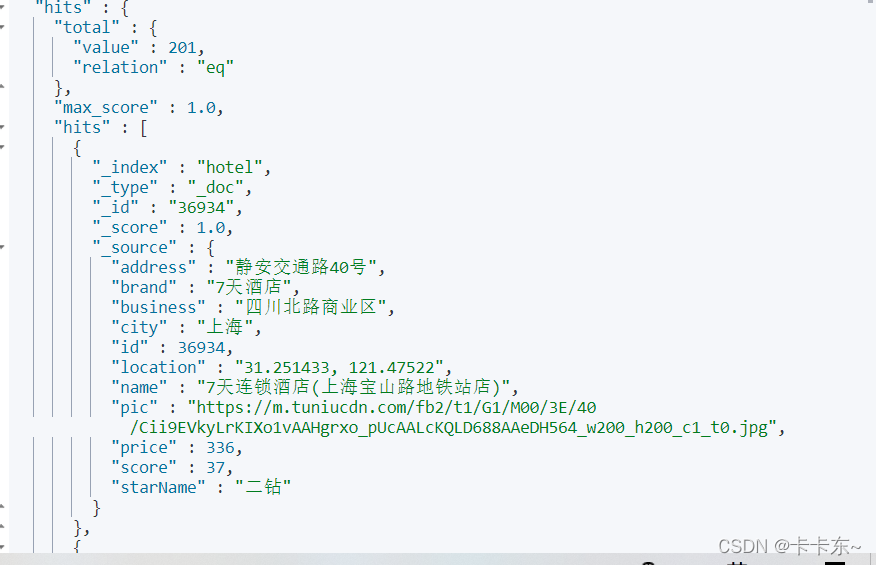
此时可以根据酒店品牌的名称做聚合:可以看出类型为term类型,DSL示例如下:
其中的主要字段是brandAgg、terms,field,指定了聚合名称、聚合类型和聚合字段。
查询的结果如下:
结果中可以看到,一般查询的hits数组为空,因为上面的size指定为0了。聚合查询的结果在aggregations下:其中的"brandAgg"字段为聚合名称,"buckets"为聚合结果。
这样就使用DSL完成了一次简单的聚合查询,但是这样的简单聚合每次都是对所有数据全部聚合,如果索引库中的数据量太大,效率也会降低。通常会对聚合的文档限定范围,可以在query中限定范围,比如查询价格200元以下的酒店名称:DSL如下:



从上面的DSL中可以看出,"query"和"aggs"字段同级,"query"的主要作用是限定聚合的文档范围。并且可以总结出聚合配置的属性有:

- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
DSL实现Metrics聚合(结合Bucket)
还是在上述的例子下,要求获取每个品牌的用户评分的min、mix、avg等数据,可以使用"stats"
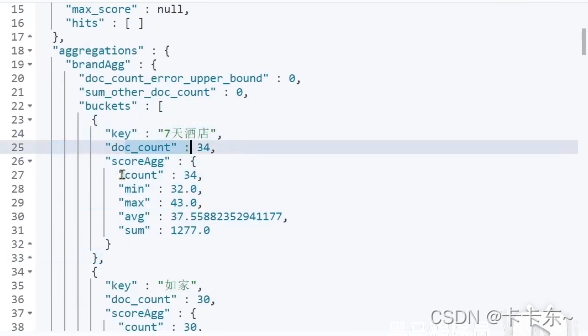
上面的DSL就是一个简单的多条件聚合了,可以看到是对品牌进行聚合后,再对其进行操作,形成一个新的聚合"score_stats",下面是操作的结果。
在buckets下,“key"为第一步聚合的结果,它的下面是第二步聚合生成的"scoreAgg”,内容是对score的计算。

接下来我们使用java中的restClient对上面的查询操作一下:
@SpringBootTest
public class HotelDocumentTest {
private RestHighLevelClient client;
@Test
void aggTest() throws IOException{
SearchRequest request = new SearchRequest("hotel");
//es聚合测试
//构建bool查询
BoolQueryBuilder bool = QueryBuilders.boolQuery().must(QueryBuilders.rangeQuery("price").lte(200));
System.out.println(bool.toString());
SearchSourceBuilder query = request.source().query(bool);
//构建聚合查询
TermsAggregationBuilder agg = AggregationBuilders.terms("by_brand").field("brand")
.subAggregation(AggregationBuilders.stats("res_score").field("score"));
System.out.println(agg);
query.aggregation(agg.size(100));
//解析返回值
SearchResponse searchResponse = client.search(request, RequestOptions.DEFAULT);
//取出第一次聚合的terms
Terms terms = searchResponse.getAggregations().get("by_brand");
Map<String,Object> resultMap = new HashMap<>();
//在terms的buckets下,取出stats结果
terms.getBuckets().forEach(item -> {
Stats stats = item.getAggregations().get("res_score");
resultMap.put(item.getKeyAsString(),stats);
System.out.println(item.getKeyAsString()+"的平均值:"+stats.getAvg());
System.out.println(item.getKeyAsString()+"的最大值:"+stats.getMax());
System.out.println(item.getKeyAsString()+"的最小值:"+stats.getMin());
});
System.out.println(resultMap.toString());
}
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.190.137:9200")
));
}
@AfterEach
void tearDown() {
try {
this.client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果如下:
如家的平均值:44.30769230769231
如家的最大值:46.0
如家的最小值:43.0
速8的平均值:40.0
速8的最大值:41.0
速8的最小值:39.0
7天酒店的平均值:39.0
7天酒店的最大值:39.0
7天酒店的最小值:39.0
汉庭的平均值:47.0
汉庭的最大值:47.0
汉庭的最小值:47.0
打印的DSL语句(boolQuery):
{
"bool" : {
"must" : [
{
"range" : {
"price" : {
"from" : null,
"to" : 200,
"include_lower" : true,
"include_upper" : true,
"boost" : 1.0
}
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
打印的DSL语句(aggregation):
{
"by_brand": {
"terms": {
"field": "brand",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [{
"_count": "desc"
}, {
"_key": "asc"
}]
},
"aggregations": {
"res_score": {
"stats": {
"field": "score"
}
}
}
}
}
可以看到使用JAVA的RestHighLevelClient与自己写的DSL查询逻辑完全相同,之后是对结果的解析,如下:
Terms terms = searchResponse.getAggregations().get(“by_brand”);
Stats stats = item.getAggregations().get(“res_score”);
因为前面的是对term聚合,因此返回结果必须指定类型为Terms,同理Stats也如此。因为这两个的父接口都为Aggregation(多态设计)。