训练过程
通过gdb调试得到这个ivfsq的训练过程,我尝试对这个内容具体训练过程进行解析,对每个调用栈里面的逻辑和代码进行解读。
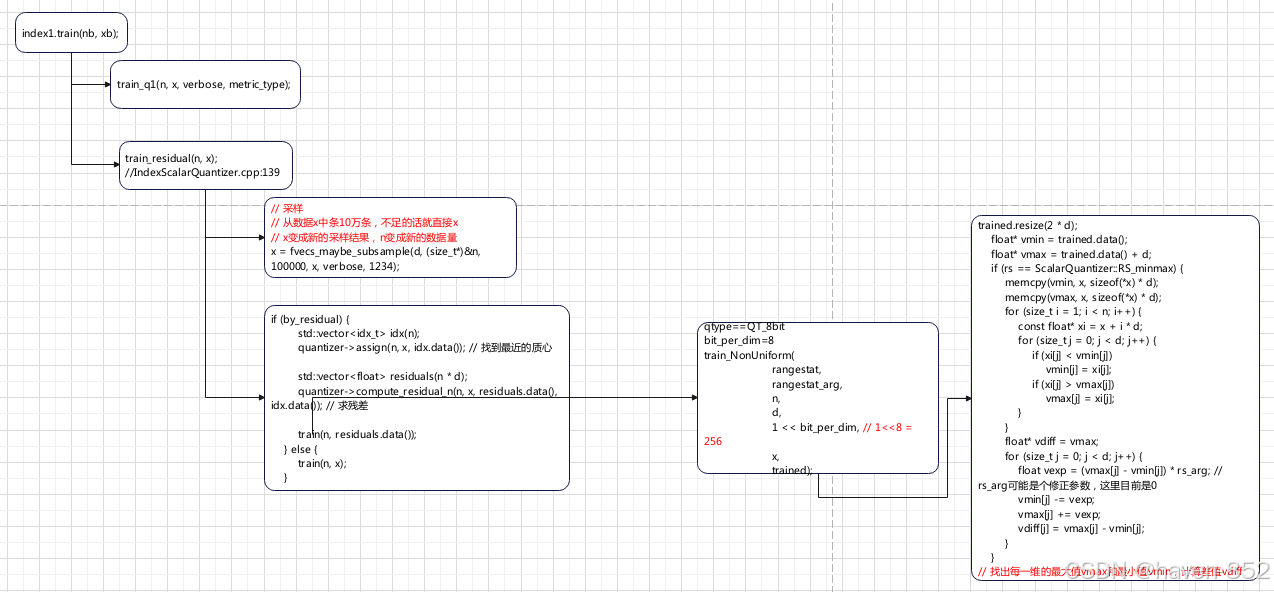
| 步骤 | 函数名称 | 调用位置 | 说明 |
|---|---|---|---|
| 1 | faiss::IndexIVF::train | /faiss/IndexIVF.cpp:1143 | 开始训练,判断是否需要训练第一级量化器,调用 train_q1。 |
| 2 | faiss::Level1Quantizer::train_q1 | /faiss/IndexIVF.cpp:56 | 训练第一级量化器,创建聚类器 Clustering,并调用其 train 方法进行训练。 |
| 3 | faiss::Clustering::train | /faiss/Clustering.cpp:81 | 使用输入数据 x 和聚类索引进行聚类训练,生成聚类中心。 |
| 4 | faiss::IndexIVF::train_residual | /faiss/IndexScalarQuantizer.cpp:139 | 训练残差部分,调用 ScalarQuantizer::train_residual 计算残差向量并训练标量量化器。 |
| 5 | faiss::ScalarQuantizer::train_residual | /faiss/impl/ScalarQuantizer.cpp:1124 | 对输入数据进行预处理(如采样),计算残差向量后调用 train 方法完成训练。 |
| 6 | faiss::ScalarQuantizer::train | /faiss/impl/ScalarQuantizer.cpp:1081 | 根据量化器类型调用 train_NonUniform 或其他方法,完成具体量化器的训练。 |
| 7 | train_NonUniform | /faiss/impl/ScalarQuantizer.cpp:572 | 为每个维度的量化器计算范围(如 vmin 和 vmax),根据指定的范围统计方法(如 RS_meanstd)完成训练。 |
| 8 | std::vector::resize | /usr/include/c++/14/bits/stl_vector.h:1015 | 为量化器的训练结果分配内存,调整 std::vector 的大小以容纳训练结果。 |
| 9 | train_NonUniform | /faiss/impl/ScalarQuantizer.cpp:1097 | 计算每个维度的最小值 vmin 和最大值 vmax,并将训练结果存储在 trained 向量中。 |
具体的流程如下:
解析IndexIVF.cpp:1143文件中的train函数
作为IndexIVFScalarQuantizer数据结构的第一个变脸index1所调用的函数train,需要去了解其如何去训练所存在的数据,查看具体的流程是什么样子的:
faiss::IndexFlatL2 quantizer1(d); // the other index
faiss::IndexIVFScalarQuantizer index1(
&quantizer1, d, nlist, faiss::ScalarQuantizer::QT_8bit);
index1.sq.rangestat = faiss::ScalarQuantizer::RS_meanstd;
index1.train(nb, xb); //调用的第一个函数
从gdb的调用栈里面发现,其首先调用的就是IndexIVF.cpp文件里面的第1143行的train函数,代码如下:
void IndexIVF::train(idx_t n, const float* x) {
if (verbose) {
printf("Training level-1 quantizer\n");
}
train_q1(n, x, verbose, metric_type);
if (verbose) {
printf("Training IVF residual\n");
}
// optional subsampling
idx_t max_nt = train_encoder_num_vectors();
if (max_nt <= 0) {
max_nt = (size_t)1 << 35;
}
TransformedVectors tv(
x, fvecs_maybe_subsample(d, (size_t*)&n, max_nt, x, verbose));
if (by_residual) {
std::vector<idx_t> assign(n);
quantizer->assign(n, tv.x, assign.data());
std::vector<float> residuals(n * d);
quantizer->compute_residual_n(n, tv.x, residuals.data(), assign.data());
train_encoder(n, residuals.data(), assign.data());
} else {
train_encoder(n, tv.x, nullptr);
}
is_trained = true;
}
现在对这里面的内容进行解读:
- 打印训练状态
if (verbose) {
printf("Training level-1 quantizer\n");
}
train_q1(n, x, verbose, metric_type);
- 作用:检查是否开启 verbose(调试输出),如果是,打印量化器训练的信息。verbose的来自于Index数据结构,然后IndexIVF继承了Index,IndexIVFInterface两个类(
IndexIVF : Index, IndexIVFInterface) - 核心函数:train_q1,训练一级量化器。
- n:训练数据的数量。
- x:训练数据(float 指针,表示数据的起始地址)。
- verbose:控制是否输出详细信息。
- metric_type:度量类型(可能决定了用什么距离计算方法,比如欧几里得或余弦距离)。
- 训练 IVF 残差
if (verbose) {
printf("Training IVF residual\n");
}
- 作用:如果启用了调试模式,打印残差训练的日志信息。
- 可选的下采样
idx_t max_nt = train_encoder_num_vectors();
if (max_nt <= 0) {
max_nt = (size_t)1 << 35;
}
TransformedVectors tv(
x, fvecs_maybe_subsample(d, (size_t*)&n, max_nt, x, verbose));
- train_encoder_num_vectors:获取训练数据的最大数量 max_nt。如果返回值小于等于 0,则默认设置为一个非常大的值(2^35,也就是34,359,738,368)。
- fvecs_maybe_subsample:对输入数据 x 进行采样,可能会减少训练数据的数量(根据 max_nt)。
- 参数 d:特征的维度。
- 参数 (size_t*)&n:更新后的训练样本数量指针。
- 参数 verbose:控制是否输出调试信息。
- TransformedVectors: 是一个简单的 RAII 类型资源管理器,专注于浮点数组的管理。它通过成员变量
own_x确定是否需要释放 x 的内存,构造函数和析构函数一起保证资源管理的安全性。适合用于数据变换或动态内存场景,帮助减少显式的delete[]调用,降低内存管理的复杂性。如果这里面fvecs_maybe_subsample返回的结果和TransformedVectors数据结构上的x相同,那么就会释放原来多余的内存;如果构建采取的数据样本大于max_nt,那么就会选择里面的随机采样的数据。fvecs_maybe_subsample:对输入数据集进行可选的下采样,并返回下采样后的数据。如果输入数据集的大小超过了指定的最大数量 (nmax),它会随机选择一部分数据(nmax个样本)进行下采样;如果数据集大小在范围内,则直接返回原始数据。- size_t d, // 数据的维度(每个样本的特征数)
- size_t* n, // 输入数据的样本数量(指针,函数可能会修改该值)
- size_t nmax, // 数据集允许的最大样本数量
- const float* x, // 输入数据(样本集,每个样本有 d 个 float 特征)
- bool verbose, // 是否打印详细信息
- int64_t seed // 随机数种子(用于确保采样结果可重复)
- 根据模式处理残差或原始数据
if (by_residual) {
std::vector<idx_t> assign(n);
quantizer->assign(n, tv.x, assign.data());
- by_residual:一个布尔值,表示是否使用残差训练。如果为 true,执行残差计算流程:
1. assign里面就是按照n的大小进行分配,大概分配的大小就是k*n,k为邻居的数量。quantizer->assign:为每个训练样本分配一个量化器中心点(即将每个点分配到一个簇)。
- n:训练样本数量(10w个)。
- tv.x:训练数据。
- assign.data():分配结果的存储位置(一个大小为 n 的向量)。assign 向量存储每个输入向量的分配结果(例如所属簇的索引)。
std::vector<float> residuals(n * d);
quantizer->compute_residual_n(n, tv.x, residuals.data(), assign.data());
2. quantizer->compute_residual_n:计算残差。
- 残差是样本和分配中心点之间的差值。
- 存储在 residuals 数组中。
train_encoder(n, residuals.data(), assign.data());
3. train_encoder:使用残差数据和分配结果训练编码器。
- 原始数据训练
} else {
train_encoder(n, tv.x, nullptr);
}
- 如果 by_residual 为 false,直接用原始数据进行编码器训练,不使用分配结果。
- 标记训练完成
is_trained = true;
- 将 is_trained 标记为 true,表示训练已经完成。
核心逻辑总结
- 函数接收高维训练数据 x,并根据配置(by_residual)选择:
- 使用残差方法,训练量化器和编码器。
- 或直接对原始数据进行训练。
- 支持下采样、量化器分配、残差计算等多种预处理。
- 用途广泛,适用于构建高效的倒排文件索引以加速高维数据的检索。
函数调用流程图
train
├── train_q1
├── fvecs_maybe_subsample
│ └── TransformedVectors
├── by_residual ?
│ ├── quantizer->assign
│ ├── quantizer->compute_residual_n
│ └── train_encoder (using residuals)
└── train_encoder (using original data)