数据流风格
数据流风格是软件架构中的一种风格,主要是面向数据,用于进行流式的数据处理;数据流风格的代表有管道-过滤器风格和批处理序列风格,这里主要是指管道-过滤器风格。
管道-过滤器风格就像其名字一样,是以一个个的组件连接,数据像水一样,顺序的流向到管道中,然后逐一被组件处理,最终达到目标形式。此种风格是比较适合数据治理或者进行简单的数据接入的。
场景引入
假设需要从一个topic中实时接入数据,其中的每条数据都有五个属性,分别是data_type,source_from,source_to,detail,op_time;
下面是数据处理流程的规则:
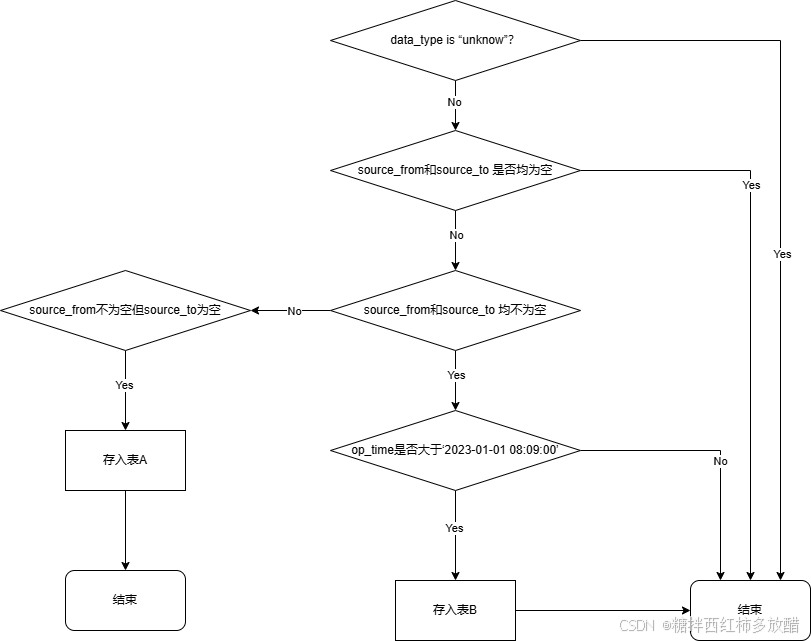
- 如果data_type等于“unknow”,则该条数据丢弃,流程结束,否则,继续处理;
- 判断source_from和source_to 是否均为空,如果是,则数据丢弃,结束流程,否则继续处理;
- 如果source_from和source_to 均不为空,则判断op_time是否大于‘2023-01-01 08:09:00’,若大于,则存储到表B,流程结束;
- 如果source_from不为空但source_to为空,则数据存储到表A,流程结束;
该场景是典型的基于规则,对数据进行处理与处置,换算为逻辑流程应该是:
Kafka 作为一个分布式流处理平台,广泛用于构建实时数据管道和流应用。它能够处理大量的数据流,具有高吞吐量、可持久化存储、容错性和扩展性等特性。这里我们以Kafka作为流数据的开始,也就是系统的输入。SpringBoot的应用也就是消费者的角色,去接入、处理kafka中的数据。
具体关于SpringBoot集成Kafka的基础,可以参考我之前的文章👇
关于SpringBoot集成Kafka-CSDN博客
https://blog.csdn.net/qq_40690073/article/details/143960276
我们直接基于SpringBoot和Kafka进行基本实现:
基于@KafkaListener注解进行消息监听,定义消息处理接口及其实现类,然后进行数据处理
定义数据类:
@Data
public class MyData {
@JsonProperty("data_type")
private String dataType;
@JsonProperty("source_from")
private String sourceFrom;
@JsonProperty("source_to")
private String sourceTo;
@JsonProperty("detail")
private String detail;
@JsonProperty("op_time")
private String opTime;
}定义数据处理Service及其实现类:
public interface MessageDealService {
void process(MyData data);
}
@Service
public class MessageDealServiceImpl implements MessageDealService {
@Autowired
private TableARepository tableARepository;
@Autowired
private TableBRepository tableBRepository;
@Override
public void process(MyData data) {
if ("unknow".equals(data.getDataType())) {
return;
}
if (data.getSourceFrom() == null && data.getSourceTo() == null) {
return;
}
if (data.getSourceFrom() != null && data.getSourceTo() != null) {
if (isAfter(data.getOpTime(), "2023-01-01 08:09:00")) {
TableB tableB = new TableB();
tableB.setDataType(data.getDataType());
tableB.setSourceFrom(data.getSourceFrom());
tableB.setSourceTo(data.getSourceTo());
tableB.setDetail(data.getDetail());
tableB.setOpTime(data.getOpTime());
tableBRepository.save(tableB);
}
} else if (data.getSourceFrom() != null && data.getSourceTo() == null) {
TableA tableA = new TableA();
tableA.setDataType(data.getDataType());
tableA.setSourceFrom(data.getSourceFrom());
tableA.setDetail(data.getDetail());
tableA.setOpTime(data.getOpTime());
tableARepository.save(tableA);
}
}
private boolean isAfter(String opTime, String threshold) throws ParseException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return sdf.parse(opTime).after(sdf.parse(threshold));
}
}kafka中进行监听并调用
@Component
public class KafkaConsumer {
@Autowired
private MessageDeal messageDeal;
@KafkaListener(topics = "your-topic", groupId = "group-id")
public void consume(String message) {
try {
// 解析消息
ObjectMapper objectMapper = new ObjectMapper();
MyData data = objectMapper.readValue(message, MyData.class);
// 调用消息处理器
messageDeal.process(data);
} catch (Exception e) {
e.printStackTrace();
}
}
}模式改造
责任链设计模式
责任链的设计源于数据结构中的链表,从模式的定义中就能看出,它需要一串走下去,而每一个处理请求的对象,都需要记录下一个处理请求的对象,即标准的数据链表方式。
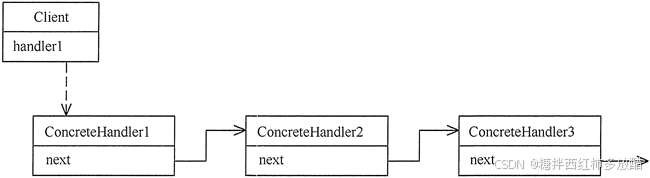
职责链模式的实现主要包含以下角色。
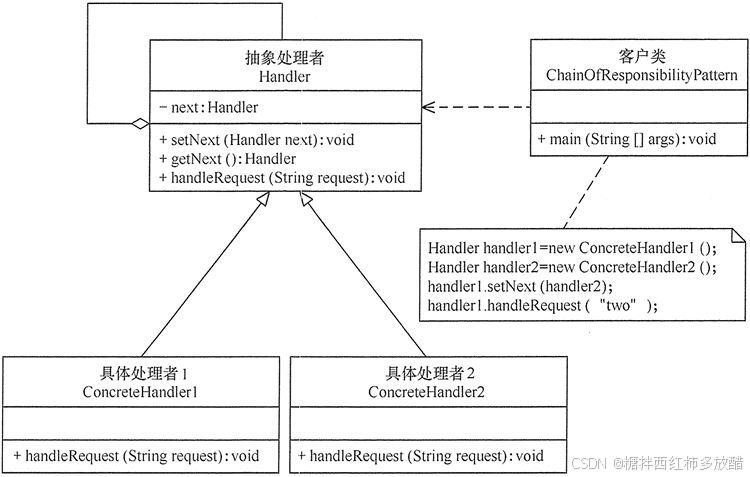
- 抽象处理者(Handler)角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接。
- 具体处理者(Concrete Handler)角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
- 客户类(Client)角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
责任链模式的本质是解耦请求与处理,让请求在处理链中能进行传递与被处理;理解责任链模式应当理解其模式,而不是其具体实现。责任链模式的独到之处是将其节点处理者组合成了链式结构,并允许节点自身决定是否进行请求处理或跳跃,相当于让请求流动起来。
UML类图如下:
管道过滤器风格与责任链的结合的思路
基于责任链的模式与数据流的概念图对比:
and

我们可以得出,责任链中的具体处理者(Concrete Handler)角色恰好可以充当数据流风格中的过滤器,然后基于此,我们将繁琐的if else逻辑抽象到一个个的过滤器中,然后让这些过滤器链成数据处理链,让接入的数据走入到对应的数据处理链中即可。
SpringBoot中重新实现
定义数据处理组件框架
首先,基于责任链模式进行数据处理器框架的定义:
/**
* 定义数据处理器接口
**/
interface DataStreamProcessor {
void setNext(DataStreamProcessor nextProcessor);
void handle(Object data);
}
/**
* 定义数据处理器抽象类,完成基本的责任链注册机制
* 以及预留业务扩展口
**/
public abstract class AbstractDataStreamProcessor implements DataStreamProcessor {
private DataStreamProcessor nextProcessor;
@Override
public void setNext(DataStreamProcessor nextProcessor) {
this.nextProcessor = nextProcessor;
}
@Override
public void handle(Object data) {
AtomicBoolean flag = disposeData(data);
if(flag.get() && null != nextProcessor){
nextProcessor.handle(data);
}
}
/**
* 处理数据
* @param data 数据
* @return AtomicBoolean 如果返回为true,则代表继续向下处理,否则,则终止
*/
abstract AtomicBoolean disposeData(Object data);
}
使用时,则根据要处理的逻辑,继承 AbstractDataStreamProcessor 类即可,我们以data_type判断为例:
public class DataTypeFilterProcessor extends AbstractDataStreamProcessor {
private boolean flag;
@Override
void disposeData(Object data) {
Map<String, Object> record = (Map<String, Object>) data;
if ("unknow".equals(record.get("data_type"))) {
//结束处理,后续不做处理
return new AtomicBoolean(false);
}
return new AtomicBoolean(false);
}
}除DataTypeFilterProcessor外,还需要根据其他的逻辑,新建其他的处理器类A、B、C,才能完成一个完整的链式。
public class DataStreamProcessorTest {
public static void main(String[] args) {
// 创建处理器实例
UnknownTypeProcessor unknownTypeProcessor = new UnknownTypeProcessor();
XXXXProcessorA emptySourceProcessor = new XXXXProcessorA();
XXXXProcessorB sourceToProcessor = new XXXXProcessorB ();
XXXXProcessorC sourceFromProcessor = new XXXXProcessorC ();
// 构建责任链
unknownTypeProcessor.setNext(emptySourceProcessor);
emptySourceProcessor.setNext(sourceToProcessor);
sourceToProcessor.setNext(sourceFromProcessor);
// 测试数据
MyData data1 = new MyData();
data1.setDataType("unknow");
data1.setSourceFrom("source1");
data1.setSourceTo("source2");
data1.setDetail("detail1");
data1.setOpTime("2023-01-02 09:10:00");
//处理流程
unknownTypeProcessor.handle(data1);
}
基于SpringBoot进行处理器自动化注册
如果单纯的使用main函数调用,则是根据逻辑流程图进行一个个的链式注入,这显然无法在SpringBoot中使用,如果想在SpringBoot中使用,我们需要解决两个问题:
- 第一,要保证我们的处理器是Spring的Bean,受Spring的上下文管理,这样才可以自由的使用@Autowired等注解完美的进行其他Service的使用;
- 第二,最好是摒弃手动逐一注入的情况,对于所处的数据流,最好在处理器类编写的时候就可以指定。
针对以上两点需求,解决方案如下:
- 对新建的处理器类上使用@Compoent注解即可使其成为Spring上下文管理的Bean,且可以随意依赖Spring环境中其他的Bean
- 进行自动注入需要两个参数,一个是这个处理器需要到哪个数据处理流中,另一个是在所处的数据流中的位置,基于这两个参数就可以实现自动注册,所有需要一个注解来额外标明这两个参数
定义注解
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface DataStream {
String dataStreamName();
int order() default 0;
}自动化注册
private final Map<String, List<AbstractDataStreamProcessor>> dataStreamChains = new ConcurrentHashMap<>();
@Autowired
public void setDataStreamProcessors(Map<String, AbstractDataStreamProcessor> processors) {
processors.forEach((beanName, processor) -> {
DataStream annotation = processor.getClass().getAnnotation(DataStream.class);
if (annotation != null) {
String dataStreamName = annotation.dataStreamName();
int order = annotation.order();
dataStreamChains.computeIfAbsent(dataStreamName, k -> new ArrayList<>()).add(processor);
}
});
dataStreamChains.forEach((dataStreamName, processorsList) -> {
Collections.sort(processorsList, (p1, p2) -> {
DataStream a1 = p1.getClass().getAnnotation(DataStream.class);
DataStream a2 = p2.getClass().getAnnotation(DataStream.class);
return Integer.compare(a1.order(), a2.order());
});
// 构建责任链
AbstractDataStreamProcessor current = null;
for (AbstractDataStreamProcessor processor : processorsList) {
if (current == null) {
current = processor;
} else {
current.setNext(processor);
current = processor;
}
}
});
}
@Bean
public BeanPostProcessor beanPostProcessor() {
return new BeanPostProcessor() {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof AbstractDataStreamProcessor) {
Field field = ReflectionUtils.findField(bean.getClass(), "nextProcessor");
if (field != null) {
ReflectionUtils.makeAccessible(field);
ReflectionUtils.setField(field, bean, getNextHandler((AbstractDataStreamProcessor) bean));
}
}
return bean;
}
private AbstractDataStreamProcessor getNextHandler(AbstractDataStreamProcessor processor) {
DataStream annotation = processor.getClass().getAnnotation(DataStream.class);
if (annotation != null) {
String dataStreamName = annotation.dataStreamName();
List<AbstractDataStreamProcessor> processorsList = dataStreamChains.get(dataStreamName);
if (processorsList != null) {
int currentIndex = processorsList.indexOf(processor);
if (currentIndex < processorsList.size() - 1) {
return processorsList.get(currentIndex + 1);
}
}
}
return null;
}
};
}
@Bean
public Map<String, AbstractDataStreamProcessor> dataStreamProcessorMap() {
return dataStreamChains.entrySet().stream()
.collect(Collectors.toMap(Map.Entry::getKey, entry -> entry.getValue().get(0)));
}改造后场景复现
基于以上设计,规避掉繁琐的if else嵌套,以Java类作为基础单元,进行数据组件化的思路去再次实现场景。
基于之前的封装,此处直接进行数据处理器的实现即可,我们先创建四个具体的处理器来处理这些规则:
- DataTypeFilterProcessor:过滤掉 data_type 为 "unknow" 的数据。
- SourceCheckProcessor:检查 source_from 和 source_to 是否均为空,如果是,则丢弃数据。
- OpTimeFilterAndStoreBProcessor:如果 op_time 大于 '2023-01-01 08:09:00',则存储到表 B。
- StoreAProcessor:如果 source_from 不为空但 source_to 为空,则存储到表 A。
以下为具体代码:
@Component
//在SpringBoot中只需要DataStream注解就可以自动地注册成为某条数据流地处理
@DataStream(dataStreamName = "default", order = 1)
public class DataTypeFilterProcessor extends AbstractDataStreamProcessor {
@Override
AtomicBoolean disposeData(Object data) {
Map<String, Object> record = (Map<String, Object>) data;
if ("unknow".equals(record.get("data_type"))) {
//结束处理,后续不做处理
return new AtomicBoolean(false);
}
return new AtomicBoolean(false);
}
}
@Component
@DataStream(dataStreamName = "default", order = 2)
public class SourceCheckProcessor extends AbstractDataStreamProcessor {
@Override
AtomicBoolean disposeData(Object data) {
MyData record = (Mydata) data;
if (record.get("source_from") == null && record.get("source_to") == null) {
//相关逻辑处理
return new AtomicBoolean(false);
}
}
}
@Component
@DataStream(dataStreamName = "default", order = 3)
class OpTimeFilterAndStoreBProcessor extends AbstractDataStreamProcessor {
private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Autowired
TableBRepository repository;
@Override
AtomicBoolean disposeData(Object data) {
//相关逻辑处理
}
private void storeToTableB(Map<String, Object> record) {
// 实现存储到表B的逻辑
}
}
@Component
@DataStream(dataStreamName = "default", order = 4)
class StoreAProcessor extends AbstractDataStreamProcessor {
@Override
AtomicBoolean disposeData(Object data) {
//相关逻辑处理
}
}该数据流使用:
@Component
public class KafkaMessageConsumer {
@Autowired
private Map<String, AbstractDataStreamProcessor> dataStreamProcessorMap;
@KafkaListener(topics = "default", groupId = "my-group")
public void listen(@Payload String message) {
AbstractDataStreamProcessor processor = dataStreamProcessorMap.get("default");
processor.handle(data);
}
}