视觉语言导航任务
-
任务提出:CVPR2018,在Matterport3D simulator仿真环境中,从随机初始化位置到目标位置的最佳路径的轨迹搜索任务。
-
任务描述:这是一个偏向落地型的研究方向:该任务要求智能体,在环境中,按照自然语言指令进行导航,移动,最终到达指定目的地,所以这是一个涉及到计算机视觉和自然语言处理的多模态任务。
-
学科定位:目前,在这两个领域的多模态任务主要有image captioning,VQA,image Generation等。通过对这些视觉语言综合任务的分类和比较,明确navigation任务在学科体系中的位置。
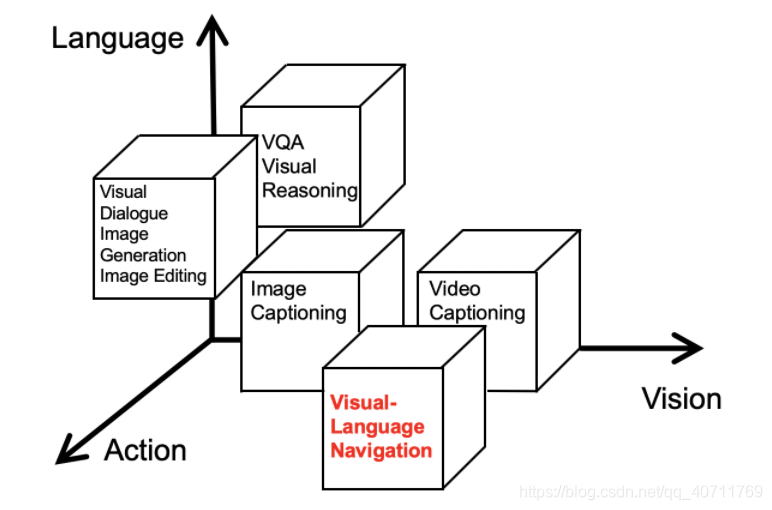
弱耦合任务
-
图像描述
encoder-decoder的show and tell 和 neural talk(CNN+RNN)
-
VQA视觉问答
联合嵌入模型:图像和文字在公共特征空间学习
注意力机制模型:局部图像特征对不同区域特征加权解决噪声问题
模块化组合模型:引入不同功能的神经网络模块
知识库增强模型:引入外部知识库解决先验知识问题
-
文本图像生成
变分子编码器、基于流的生成模型、近似PixelCNN、GAN
基于GAN的优化方向:增加网络深度、引入多个判别起、注意力机制、增加额外约束、分阶段生成(场景图、语义中间层)
-
视觉对话
多次问答,基于深度强化学习的模型、注意力机制、条件变分自编码器
-
多模态机器翻译
给定源语言+图片,输出目标语言
研究方向:分解任务目标、充分发掘图片的视觉特征、强化学习方法的使用、无监督学习方法的拓展