论文地址:https://openaccess.thecvf.com/content/CVPR2021/html/Zhu_Prototype_Augmentation_and_Self-Supervision_for_Incremental_Learning_CVPR_2021_paper.html
代码:https://github.com/Impression2805/CVPR21_PASS
发表于:CVPR 21
Abstract
尽管深层神经网络在许多单个任务中的表现令人印象深刻,但在增量学习新任务时,深层神经网络会遭受灾难性的遗忘。最近,人们提出了各种增量学习方法,一些方法依靠存储数据或复杂的生成模型取得了可接受的性能。然而,存储以前任务的数据受到内存或隐私问题的限制,而生成模型在训练中通常是不稳定和低效的。在本文中,我们提出了一个简单的基于非示范的方法,名为PASS,以解决增量学习中的灾难性遗忘问题。一方面,我们提出为每个旧类记忆一个代表类的原型,并在深度特征空间中采用原型增强(protoAug)来保持以前任务的决策边界。另一方面,我们采用自监督学习(SSL)来为其他任务学习更多的通用和可转移的特征,这表明SSL在增量学习中的有效性。在基准数据集上的实验结果表明,我们的方法明显优于基于非示范的方法,并且与基于示范的方法相比取得了相当的性能。
I. Motivation
本文的方法包含两个部分:Prototype Augmentation与Self-Supervision。对于PA,其解决的是决策边界在训练新任务后发生漂移,从而导致灾难性遗忘的问题,属于比较经典的motivation,没有什么好说的;而这里的自监督SS就比较有意思了,文中指出对于旧任务最优的参数可能对于新任务而言是一种糟糕的参数初始化,因此使用自监督学习来学习更具有可转移性的特征,这样既能使新任务的特征更容易被学习,同时也能尽可能去保证旧任务的特征不被破坏。
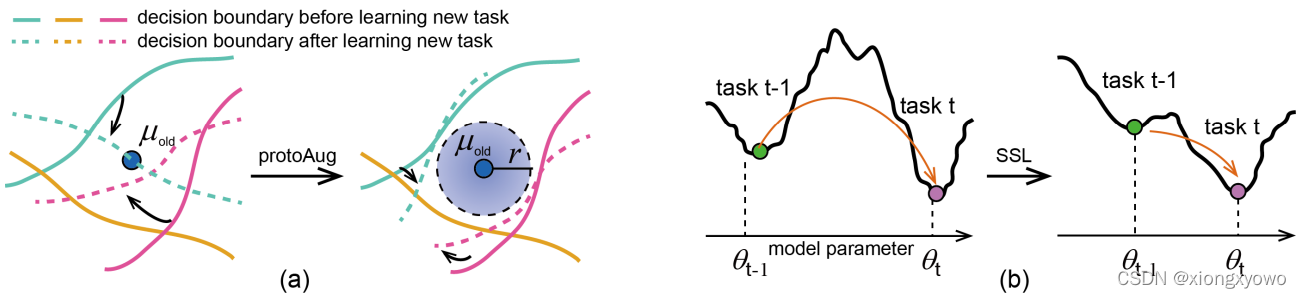
II. Method
图中的左右两部分分别展示了SS与PA的步骤。对于自监督,具体做法是对输入新类样本进行旋转,从而制造"伪"新类,通过让分类头尝试去区分新类与伪新类从而达到更自然特征过渡的目的;对于原型扩充,其实就是给原型向量添加高斯噪声。
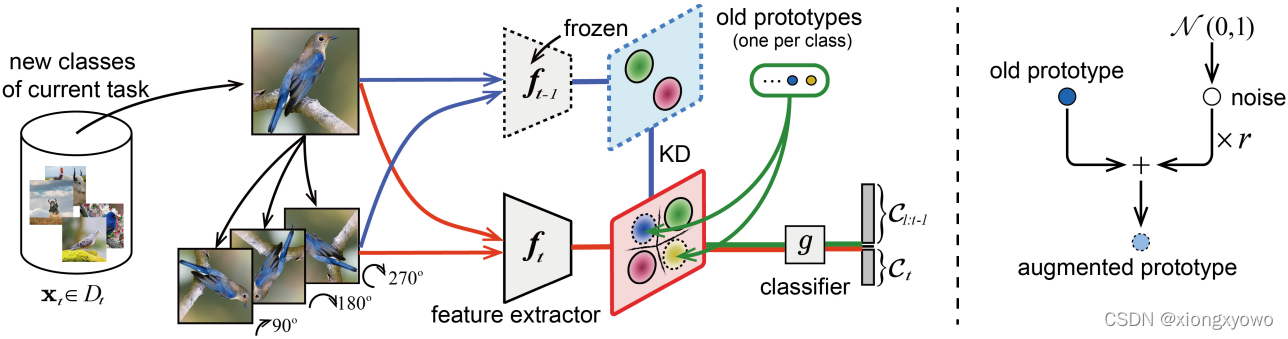
III. Prototype Augmentation
本文没有显式的去存储旧类的原始图像,所以可以认为是一种无示范的方法。不过,对于现在大多数的无示范方法,虽然没有去存储旧类样本本身,取而代之的值存储旧类的原型向量(即该类所有样本的特征平均)。而对该原型向量的扩充方式也很简单,就是加个高斯噪声: F t o l d , k o l d = μ t o l d , k o l d + e ∗ r F_{t_{o l d}, k_{o l d}}=\mu_{t_{o l d}, k_{o l d}}+e * r Ftold,kold=μtold,kold+e∗r
IV. SSL based Label Augmentation
本文的自监督思想主要来源于此文[1]。具体做法是,对于 K K K个新类的所有任务样本,对其进行数据扩充,也就是旋转90,180,270度: X t ′ = rotate ( X t , θ ) , θ ∈ { 90 , 180 , 270 } \mathbf{X}_{t}^{\prime}=\operatorname{rotate}\left(\mathbf{X}_{t}, \theta\right), \theta \in\{90,180,270\} Xt′=rotate(Xt,θ),θ∈{90,180,270} 。按照我们以往的认知,将一个样本旋转后,其类别是保持不变的。但是这里将经过三种不同旋转方式处理后的样本视为了三种"新类",并赋予相应的新类标签 Y t ′ \mathbf{Y}_{t}^{\prime} Yt′(而非 Y t \mathbf{Y}_{t} Yt)。文中指出这一做法可以放松学习过程中的不变约束,从而提升任务的性能。这种解释相当于也是加入自监督提升性能的"套路"。